引言
用该文来讲解语音全流程涉及到的技术,整体语音涉及的交互流程如下图:
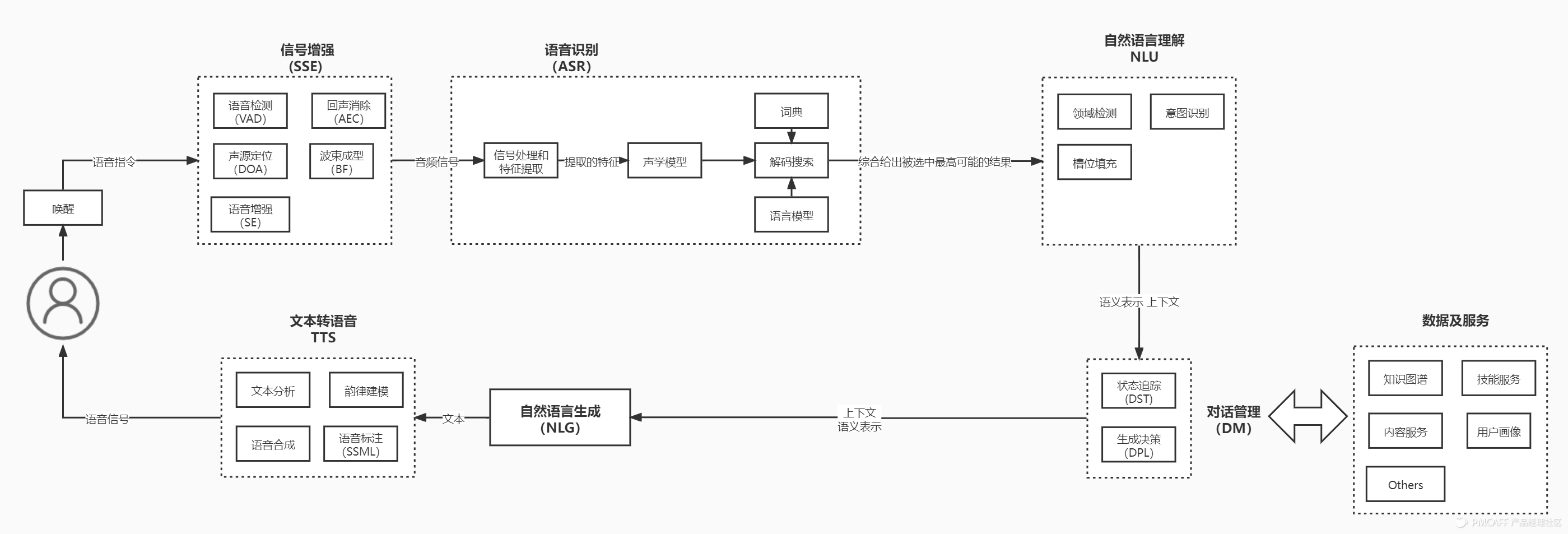
Part1 唤醒
语音唤醒指的是通过预设的关键词即可将智能硬件从休眠状态唤醒,来执行相应操作。
1.1 交互模式
传统模式
唤醒方式:先唤醒设备,等硬件设备反馈后(提示音或亮灯),用户认为设备被唤醒了,再发出语音控制命令,对应的缺点是交互时间过长,例:
- 用户说:小爱同学
- 小爱音箱:我在(无屏音箱外圈灯带亮起)
- 用户说响应的指令,比如:我要听晴天
One-shot
One-shot是直接将唤醒词和工作命令一同说出,例:小雅小雅,我想听周杰伦的歌
Zero-shot
Zero-shot是将常用用户指令设置为唤醒词,达到用户无感知唤醒,举例:直接对车机说“导航到XX大厦”。
自定义唤醒词唤醒
方式:通过自定义唤醒词来进行唤醒,满足用户的个性化需求。
全双工连续对话
全双工是通信领域的术语,它的通信术语定义的就是一个实时的、双向的语音信息的交互,就叫全双工。可以通过一次唤醒之后,和语音助手进行连续对话。

全双工连续对话两种模式
- 场景式的连续对话。场景式的连续对话,只会响应一个或者多个领域的指令,比如听音乐的场景,音箱会响应听歌、选歌、调音量的指令。不同设备可以设定不同的场景连续对话,同一个设备可以通过唤醒词去主动的切换不同场景的连续对话。
- 全领域连续对话。这种方式对用户的请求没有任何领域限制,是全领域的,同时允许用户与音箱聊天和问答,场景式的模式,实现起来会相对容易一点,但全领域对拒识要求比较严格。
Part2 信号增强(SSE)
语音信号增强(SSE)是一套信号处理技术,可以消除麦克风输入噪音,发出更清晰的信号,从而改善语音识别的效果。
2.1 语音检测(VAD)
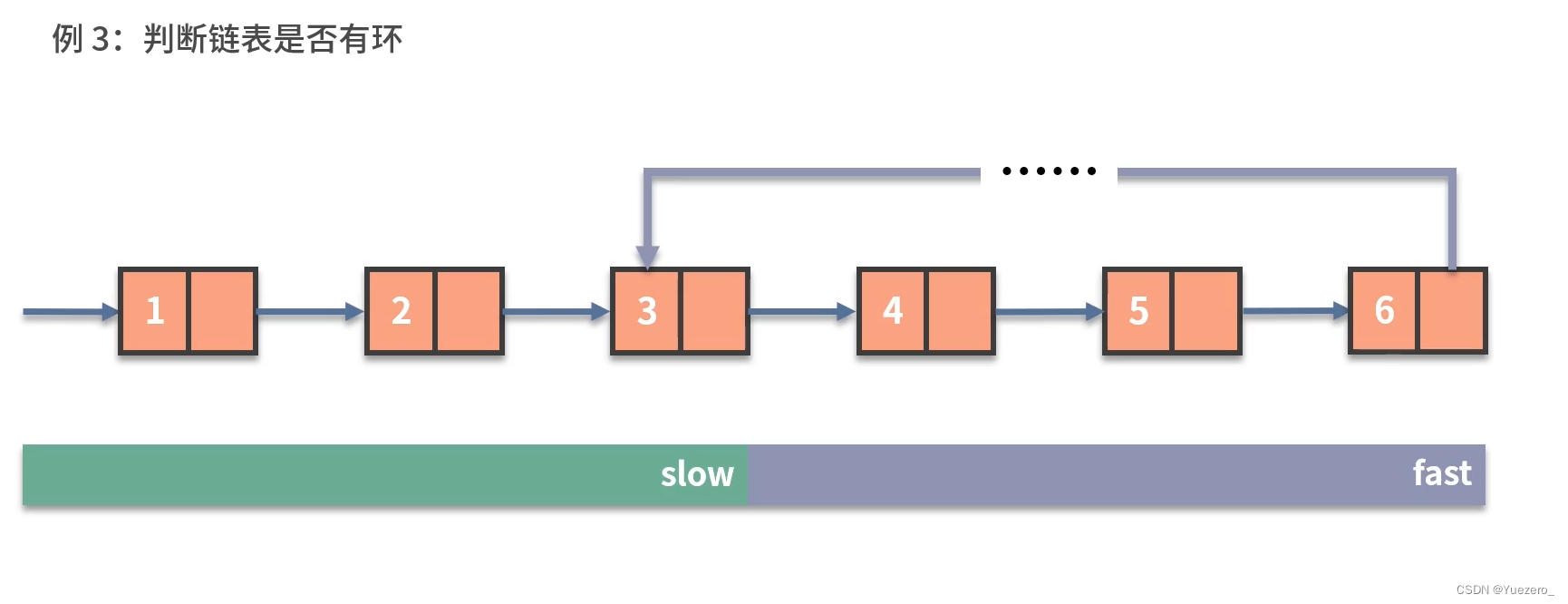
在介绍VAD之前,先介绍声音的定义。声音实际上是一种波。我们常见的音频格式mp3等都是压缩格式,必须转成非压缩的纯波形文件来处理,比如Windows PCM文件,也就是俗称的wav文件。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。下图是一个波形的示例。

语音活性检测 (Voice activity detection,VAD), 也称为 speech activity detection or speech detection, 是一项用于语音处理的技术,目的是检测语音信号是否存在。 VAD技术主要用于语音编码和语音识别。它可以简化语音处理,也可用于在音频会话期间去除非语音片段。
在开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成的干扰。这个静音切除的操作一般称为VAD,需要用到信号处理的一些技术。要对声音进行分析,需要对声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧。
VAD算法的经典设计如下:
- 首先是一个降噪过程,如通过spectral subtraction.
- 然后对输入信号的一个区块提取特征。
- 最后使用一个分类器对这个区块进行分类,确定是或不是语音信号。通常这个分类过程是将计算的值与一个阈值进行比较。
一般在产品设计的时候,会固定一个VAD截断的时间,但面对不同的应用场景,可能会要求这个时间是可以自定义的,主要是用来控制多长时间没有声音进行截断。
2.2 回声消除(AEC)
AEC(Acoustic Echo Cancellaction):回音消除,如果当前设备既在使用扬声器进行播放,同时又使用麦克风进行拾音,那么麦克风就会将自己播放出去的声音给重拾回来。这时为了避免影响算法识别结果,需要对回音进行消除。
2.3 声源定位(DOA)
DOA(direction of arrival),在三维空间中,除了时域,频域,还可以利用空域信息对信号进行处理,基于阵列麦克的远场语音识别场景,一些声源分离技术(beamforming, blind source seperation)会要使用到声源方位信息.声源定位技术并不仅限于单个目标源的定位,且对于ASR场景的声源目标是宽带信号。
DOA 至少有两个用途:
- 用于方位灯的展示,增强交互效果;
- 作为波束形成的前导任务,确定空间滤波的参数。
2.4 波束成型(BF)
波束形成是利用空间滤波的方法,将多路声音信号,整合为一路信号。通过波束形成,一方面可以增强原始的语音信号,另一方面抑制旁路信号,起到降噪和去混响的作用,如下图:

2.5 语音增强(SE)
语音增强SE,从含有噪音的的语音信号中提取纯净语音。
Part3 语音识别(ASR)
语音识别技术(Automatic Speech Recognition)是一种将人的语音转换为文本的技术。
在介绍ASR之前,得介绍一下两个概念:文本和音素。
- 文本的基本单元是字或者词;
- 发音的基本单元是音素;
- 单词的发音由音素构成。对英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的音素集。汉语一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调无调,不详述。
- 状态:这里理解成比音素更细致的语音单位。通常把一个音素划分成3个状态。
语音识别的步骤:
第一步,把帧识别成状态(难点)。
第二步,把状态组合成音素。
第三步,把音素组合成单词。
语音识别原理的4个基本流程:“输入——编码——解码——输出”
语音识别系统本质上是一种模式识别系统,主要包括信号处理和特征提取、声学模型(AM Acoustic Model)、语言模型(LM Language Model)和解码搜索四部分。
特征提取是语音识别关键的一步,解压完音频文件后,就要先进行特征提取,提取出来的特征作为参数,为模型计算做准备。简单理解就是语音信息的数字化,然后再通过后面的模型对这些数字化信息进行计算。
声学模型将声学和发音学的知识进行整合,以特征提取模块提取的特征为输入,计算音频对应音素之间的概率。简单理解就是把从声音中提取出来的特征,通过声学模型,计算出相应的音素。
语言模型是将语法和字词的知识进行整合,计算文字在这句话下出现的概率。一般自然语言的统计单位是句子,所以也可以看做句子的概率模型。简单理解就是给你几个字词,然后计算这几个字词组成句子的概率。
词典就是发音字典的意思,中文中就是拼音与汉字的对应,英文中就是音标与单词的对应。
其目的是根据声学模型识别出来的音素,来找到对应的汉字(词)或者单词,用来在声学模型和语言模型建立桥梁,将两者联系起来——简单理解词典是连接声学模型和语言模型的月老。
词典不涉及什么算法,一般的词典都是大而全的,尽可能地覆盖我们所有地字。词典这个命名很形象,就像一本“新华字典”,给声学模型计算出来的拼音配上所有可能的汉字。
整个这一套组成了一个完整的语音识别模型,其中声学模型和语言模型是整个语音识别的核心,各家识别效果的差异也是这两块内容的不同导致的。
Part4 自然语言理解(NLU)
4.1 NLU的核心任务
经过语音识别之后,将识别出来的文本给到NLU,NLU将用户的消息识别出来,转化为结构化的语义表述(一般slot‑value pairs 的方式表示),再把这个结构化语义传给DM。那NLU涉及到的核心任务主要包括3个:领域检测、意图识别、槽位填充。
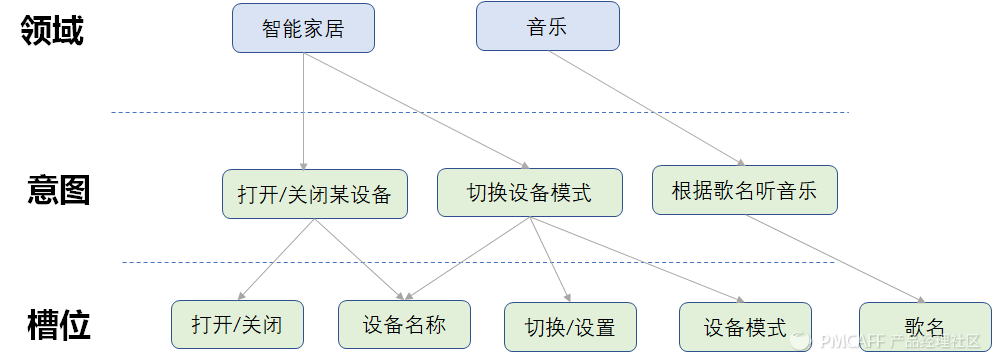
4.1.1 领域检测
领域(Domain),一些公司又称为垂域或者技能(skill)。领域的划分与实际的业务场景紧密相关,在音箱这个场景,划分到具体的领域包括:智能家居、音乐、天气等。ASR识别出来query之后,给到NLU模块,一般会把这个query同时下发给到各个领域。
query=用户说的话
4.1.2 意图识别
意图是承载具体领域下的各个功能点,每一个意图都有一个明确的功能,且两个意图不应该有相同的功能。例:
- 用户的query说"我要听晴天",对应的意图就是"根据歌名听音乐"
- 用户的query是"我听",此处明显无法确认用户的意图,用户是想听歌、还是想听新闻?
4.1.3 槽位填充
槽位填充可以理解成针对用户query中的关键字的提取。举例:
- 用户的query说"我要听晴天",对应的一个槽位就是 song="晴天"
- 用户的 query说"我要听周杰伦的晴天",对应可以提取出两个槽位:artist="周杰伦", song="晴天"
槽位是执行意图必要的前提条件,槽位需要关联一个实体作为参数的取值范围。例如:"根据歌名听音乐"意图中"歌名"是必要的条件,"歌名"就是一个实体。实体是某一类名词的集合,提供了一个有限定范围的词典。
4.2 NLU涉及的技术
4.2.1 文本分类
文本分类指的是在给定的分类体系中,将文本分到制定的某个或者某几个类别当中。前文提到NLU的核心任务领域检测、意图识别都涉及到文本分类。
文本分类对象包括:
| 分类对象 | 举例 |
| 短文本 | 标题、商品评论、短信、句子 |
| 长文本 | 文章、段落 |
文本分类的分类体系一般根据具体的业务场景由人工进行构造,以下为阿里云两种默认分类体系:新闻资讯领域类目体系、电商领域类目体系。
- 新闻资讯分为15个类目(健康、观点、旅游、经济、房产、文娱、社会、国际、消费、从政、数码、汽车、教育、体育、防腐前沿);
- 电商领域类目为17个分类,(数码/科技、游戏、汽车/摩托车/电动车、穿搭/时尚、美容/个人护理、摄影、动漫/二次元、园艺、萌宠、母婴、旅游、家居/生活百货、美食、运动/户外、文娱/影视、星座、其他)。
下图用阿里云提供的新闻模型分类示例来介绍如何进行文本分类。

具体实例:
确诊病例超1000例墨西哥宣布进入卫生紧急状态。中新网3月31日电综合报道,墨西哥新冠肺炎病例已超过1000例,墨西哥政府30日宣布进入卫生紧急状态,加强相关措施以遏制新冠肺炎疫情蔓延。30日,墨西哥卫生官员报告该国新冠肺炎病例累计达1094例,死亡28人。卫生官员说,墨西哥的非必要活动禁令将延长到4月30日,民众聚会人数限制减到只容许50人。墨西哥官方还表示,60岁以上和高风险人群应严格遵守居家建议。此前,墨西哥政府宣布,超过3000万名学生于3月21日至4月20日期间放假,学校将加强远程教育、校园消毒等措施。责任编辑:孔庆玲",
系统输出的结果分类如下:
{"id": "1662",
"output": [
{"pred": "国际", "prob": 0.99915063, "logit": 10.21936},
{"pred": "健康", "prob": 8.557205e-05, "logit": 0.8540586},
{"pred": "财经", "prob": 8.2030325e-05, "logit": 0.81178904},
{"pred": "科技", "prob": 8.076288e-05, "logit": 0.79621744},
{"pred": "体育", "prob": 7.966044e-05, "logit": 0.7824724},
......]}
4.2.2 词法分析
词法分析(lexical analysis)
词法分析包括分词(word segmentation 或 tokenization)和词性标注(part-of-speech tag)等。
分词:是将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列的过程 。
词性标注:词性标注(part-of-speech tagging),又称为词类标注或者简称标注,是指为分词结果中的每个单词标注一个正确的词性的程序,也即确定每个词是名词、动词、形容词或者其他词性的过程。其中汉语词性对照表如下:
| POSs | 词性 |
|---|---|
| 1 | 形容词 |
| 2 | 副形词 |
| 3 | 名形词 |
| 4 | 区别词 |
| 5 | 连词 |
| 6 | 副词 |
| 7 | 叹词 |
| 8 | 方位词 |
| 9 | 语素词 |
| 10 | 前接成分 |
| 11 | 成语 |
| 12 | 简称略语 |
| 13 | 后接成分 |
| 14 | 习用语 |
| 15 | 数词 |
| 16 | 名词 |
| 17 | 人名 |
| 18 | 姓 |
| 19 | 名 |
| 20 | 地名 |
| 21 | 机构团体 |
| 22 | 其他专[m |
| 23 | 非汉字串 |
| 24 | 拟声词 |
| 25 | 介词 |
| 26 | 量词 |
| 27 | 代词 |
| 28 | 处所词 |
| 29 | 时间词 |
| 30 | 助词 |
| 31 | 动词 |
| 32 | 副动词 |
| 33 | 名动词 |
| 34 | 标点符号 |
| 35 | 非语素字 |
| 36 | 语气词 |
| 37 | 状态词 |
| 38 | 形语素 |
| 39 | 区别语素 |
| 40 | 副语素 |
| 41 | 数词性语素 |
| 42 | 名语素 |
| 43 | 量语素 |
| 44 | 代语素 |
| 45 | 时语素 |
| 46 | 动语素 |
| 47 | 语气词语素 |
| 48 | 状态词语素 |
| 49 | 开始词 |
| 55 | 结束词 |
| 0 | 未知词性 |
| 50 | URL |
| 51 | 电话号码 |
| 52 |
以上分词逻辑来源于微信的词法分类逻辑。
4.2.3 实体命名识别
前文在NLU的核心任务之一"槽位提取"中,提到了槽位需要关联一个实体作为参数的取值范围。例如:"根据歌名听音乐"意图中"歌名"是必要的条件,"歌名"就是一个实体。实体是某一类名词的集合,提供了一个有限定范围的词典。
下图的示例解释了一段文本,如何通过词性分析、实体命名来完成槽位的提取以及映射到对应的实体。
- 通过词性分析的分词、词性标注先将一段文字进行拆分和标注,如下图中的词汇"1996年"对应到词性“时间”
- 再通过实体命名来将对应的词组映射到对应的实体,如下图中的词汇"1996年"对应到实体“时间”

可以通过百度AI开放平台的链接,体验一下词性分析,以及对应的实体命名。
实体的具体分类需要根据具体的业务场景进行划分,下文是微信的实体分类逻辑:
| entity_types | 短语类型标签 |
| 100000010 | 中国人名 |
| 100000011 | 外国人名 |
| 100000012 | 地名 |
| 100000013 | 机构名 |
| 100000014 | 影视,包括电影、电视剧、卡通动漫、节目 |
| 100000015 | 小说,包括书籍、漫画 |
| 100000016 | 软件 |
| 100000017 | 游戏,包括单机游戏、网络游戏、手机游戏、网页游戏 |
| 100000018 | 音乐,包括歌曲、专辑 |
| 100000019 | 菜谱 |
| 100000020 | 疾病 |
| 100000021 | 药品 |
| 100000022 | 汽车 |
| 100000023 | 时间节日 |
| 100000200 | |
| 100000201 | 未知类别的实体 |
| 100000202 | |
| 100000301 | 音乐:下载地址 |
| 100000302 | 音乐:乐器 |
| 100000303 | 音乐:风格 |
| 100000304 | 音乐:歌曲 |
| 100000305 | 音乐:歌词 |
| 100000306 | 音乐:专辑 |
| 100000307 | 人名:乐队 |
| 100000308 | 地名:景点 |
| 100000309 | 地名:山 |
| 100000310 | 地名:湖 |
| 100000311 | 影视:电影 |
| 100000312 | 影视:电视剧 |
| 100000313 | 影视:综艺节目 |
| 100000314 | 数字 |
| 100000315 | 序数 |
| 100000316 | 民族 |
| 100000317 | 百科通用类别 |
Part5 对话管理(DM)
对话管理(Dialogue Management)接收并做推理理解NLU的输出及其他信息(如上下文),来决定多轮会话的下一步动作。
5.1 核心任务
5.1.1 状态追踪(DST)
根据用户的对话历史,以及当前轮领域、意图槽位识别结果,以槽值对的形式,计算用户当前轮的对话状态,为后续的对话策略模块提供输入。对话状态是对整个对话历史的累积语义表示,一般就是槽值对(slot‑value pairs)。
对话状态维护输入的信息:
- 用户当前的动作:此刻用户说了啥
- 之前的对话状态(填槽状态):前面用户都说了啥
- 之前的系统动作:前面机器人是如何回应的
5.1.2 生成决策(DPL)
生成决策系统(dialog policy)即按照对话状态决定如何继续和用户交流。DPL是接DST的输出(对话状态)作为输入,当知道了当前对话到哪里了,就得想法子回复用户,这时候就靠DPL中预设的对话策略,选择响应系统动作作为输出。
系统动作一般有问询、确认和回复三种。
第一种,问询:了解必要槽位确认信息,例:
用户:我想要设定一个闹钟
语音助手:您想要设定几点的闹钟(明确时间的槽位)
第二种,确认:是为了解决容错性问题,填槽之前向用户再次确认,分为隐式确认和显式确认;
| 确认方式 | 定义 | 示例 |
| 显式确认 | 显式确认通常要与用户核实其提供的输入是否被正确地处理,或者请求用户允许操作。智能助手在得到用户确认之前不会执行后续操作。对于某些难以撤销的操作,采用显式确认方式征得用户口头同意是较为合适的 | 语音购物的支付确认 |
| 隐式确认 | 意味着VUI在回复中融入了用户话语中的关键信息,以便表明VUI理解的内容。对于识别准确性为中到高,并且潜在的负面影响较低时,采用隐式确认的方式是较为适合的。 | 语音助手已经定好闹钟,给到用户的语音提示,”您早上7点的闹钟已为您完成设置“ |
第三种,回复:最终给到用户的结果。
其中针对上文提到的任务型对话,对应的对话管理实际就是一个决策过程。系统在对话过程中不断根据当前状态决定下一步应该采取的最优动作(如:提供结果,询问特定限制条件,澄清或确认需求…)从而最有效的辅助用户完成信息或服务获取的任务。
5.2 DM类型
系统主导
系统主导:由DM在每轮向用户询问相关信息,用户必须按顺序填充系统的要求。
语音助手:感谢您预定高铁票,您的出发地是?
用户:深圳
语音助手:您的目的地是?
用户:上海
用户主导
用户主导:同系统主导相反,DM必须对用户的每次指令进行响应,以用户的输入作为主导,比如:闲聊。
混合主导
混合主导:以上两者的结合,用户可以打断并变更对话的指令,即使系统没有提问,用户的额外描述也能够被系统理解。
5.3 对话类型
5.3.1 按照功能特点划分
按照功能特点划分可以分为:任务型、问答型、闲聊型。
任务型
任务型对话是为了完成某个特定场景下的具体任务,举例:设置闹钟、播放音乐、查询天气。针对任务型对话的NLU实现,一般是通过把用户的自然语言映射到计算机能够理解的结构化数据,比如:领域、意图、槽位。即通过文本分类来实现领域和意图的识别,通过实体识别来实现槽位提取。
问答型
问答型对话以获取相关知识为目的的对话,通常通过解析用户意图、问题预处理,再经过相关检索、知识库匹配及推理得到最终的答案。问答型的实现方式有以下3种:
1.基于文档的问答,例如:搜索引擎、阅读理解;

2.问答对的问答,关键是根据语义相似度来匹配对应的问答。也就是给定一个query和一些候选的documents,从documents中找出与query最匹配的一个或者按照匹配程度排序;

3.基于知识图谱的对话,下图是基于知识图谱的知识库框架图。采用知识图谱的方式来建立可以深化事物规则联系,建立结构化知识库,但是需要一线行业的数据进行喂养。
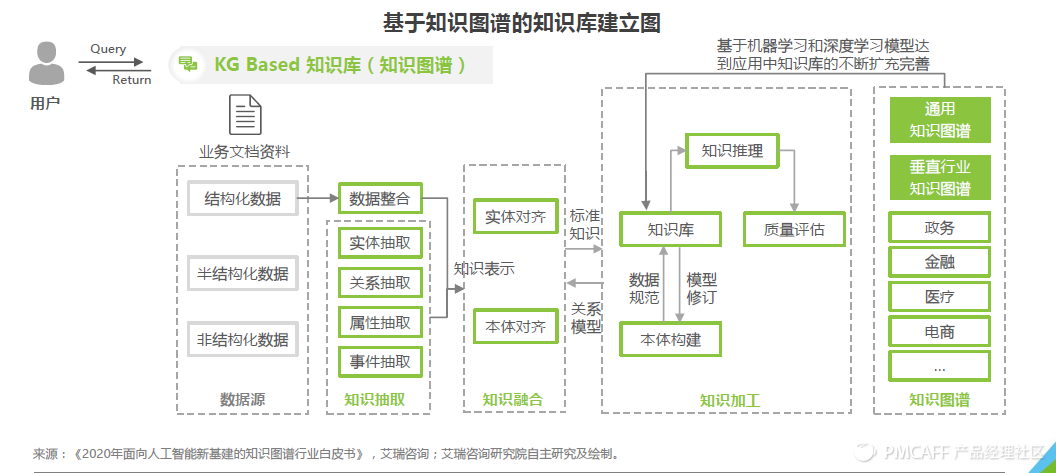
闲聊型
闲聊型对话大多为开放域的对话,主要以满足用户的情感需求为主,通过产生有趣、富有个性化的答复内容,与用户进行互动。闲聊对话的实现方式主要有以下两种:
- 基于生成的方法:在每轮的对话过程中,系统生成适当的回复;
- 基于检索的方法:学习从数据库中选择当前最合适的回复。
5.3.2 按照交互特点划分
按照交互特点划分为单轮对话和多轮对话。
单轮对话
单轮对话一般表现为一问一答的形式,用户提出问题或前发出请求,系统识别用户意图,做出回答或执行特定操作。单轮对话也强调自然语言理解,但一般不涉及上下文、指代、省略或隐藏信息。
多轮对话
多轮对话一般是任务驱动的多轮对话,用户是带着明确的目的的,如订餐,订票,叫车,寻找音乐、电影或某种商品等比较复杂的需求来,而这中间有很多限制条件,用户并不能一次将任务所需的关键信息一次性说完,说清楚,因此就要分多轮进行QA问答一方面,用户在对话过程中,可以不断修正和完善自己的需求;另一方方面,当用户在陈述需求不够具体和明确时,机器人可以通过询问,澄清和确认来帮助用户寻找满意的结果,并且在任务的驱动下与用户完成日常的交互,以此不断完善对于用户需求的满足。
因此,任务驱动的多轮对话不是一个简单的自然语言理解加信息检索的过程,而是一个决策过程,需要机器在对话过程中不断根据当前的状态决策下一步应该采取的最优动作(如:提供结果,询问特定限制条件,澄清或确认需求,等等)从而最有效的辅助用户完成信息或服务获取的任务。
Part6 自然语言处理(NLG)
自然语言生成(NLG)是自然语言处理的一部分,从知识库或逻辑形式等等机器表述系统去生成自然语言。
6.1 NLG的实现方式
6.1.1 基于模板的NLG
这种形式的NLG使用模板驱动模式来显示输出。数据动态地保持更改,并由预定义的业务规则集(如if / else循环语句)生成。
对应的判断条件包括NLU的结构化数据(领域、意图、槽位),以及DST、DPL,基于判断条件,来生成对应的模板回复。例:
- 用户query"我要听晴天"举例,NLU已经提取了对应的domain、intent、槽位等信息。可以将正则表达式抽象成:
- if domain="music"& intent="根据歌名听音乐"& song="晴天",对应回复的话术"好的,一首晴天送给你,祝你有一天好心情"
6.1.2 知识问答型对话的NLG
知识问答型对话中的NLG就是根据问句类型识别与分类、信息检索或文本匹配而生成用户需要的知识(知识、实体、片段等),这类回复相比单纯的信息检索一般用户体验会更好,因为一般信息检索还需要用户根据搜索结果自己找所需信息。
息。
6.1.3 闲聊型对话的NLG
闲聊型对话中的NLG就是根据上下文进行意图识别、情感分析等,然后生成开放性回复;
6.1.4 推荐型对话系统的NLG
推荐型对话系统中的NLG就是根据用户的爱好来进行兴趣匹配以及候选推荐内容排序,然后生成给用户推荐的内容。
Part7 文本转语音(TTS)
文字转语音(Text-To-Speech,TTS)则是将一般语言的文字转换为语音,以音频的方式播放给到用户。
本文涉及到引用其他作者的文章均汇总在"关联&引用阅读"部分。