基于DEtection TRansformer的DETR框架https://github.com/facebookresearch/detr因为end-to-end,无需后处理等优点,逐渐得到青睐。DINO方法https://github.com/IDEA-Research/DINO更是取得了在COCO2017的SOTA结果。
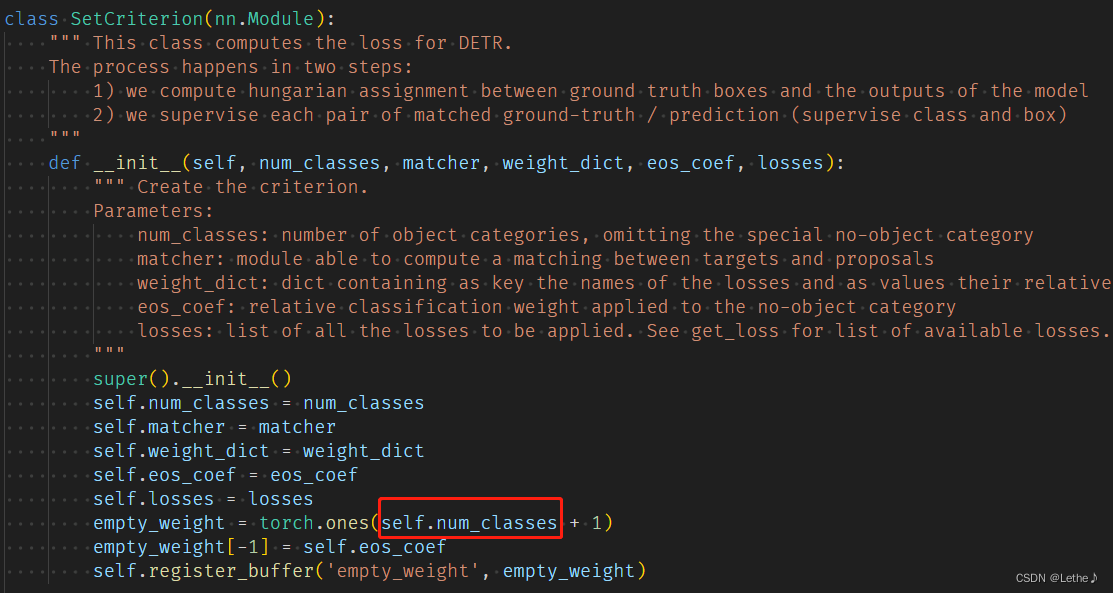
其中,在DETR方法中,class被设置为了91+1:
# the `num_classes` naming here is somewhat misleading.
# it indeed corresponds to `max_obj_id + 1`, where max_obj_id
# is the maximum id for a class in your dataset. For example,
# COCO has a max_obj_id of 90, so we pass `num_classes` to be 91.
# As another example, for a dataset that has a single class with id 1,
# you should pass `num_classes` to be 2 (max_obj_id + 1).
# For more details on this, check the following discussion
# https://github.com/facebookresearch/detr/issues/108#issuecomment-650269223
num_classes = 20 if args.dataset_file != 'coco' else 91
if args.dataset_file == "coco_panoptic":
# for panoptic, we just add a num_classes that is large enough to hold
# max_obj_id + 1, but the exact value doesn't really matter
num_classes = 250
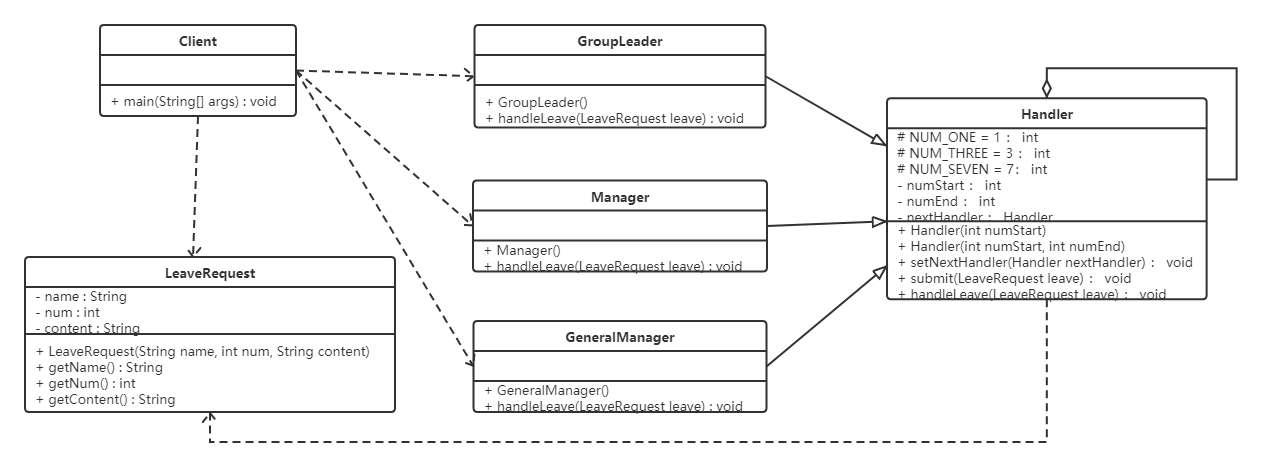
device = torch.device(args.device)在类初始化时:

计算class loss时:
而在DINO中,class number被设置为91.
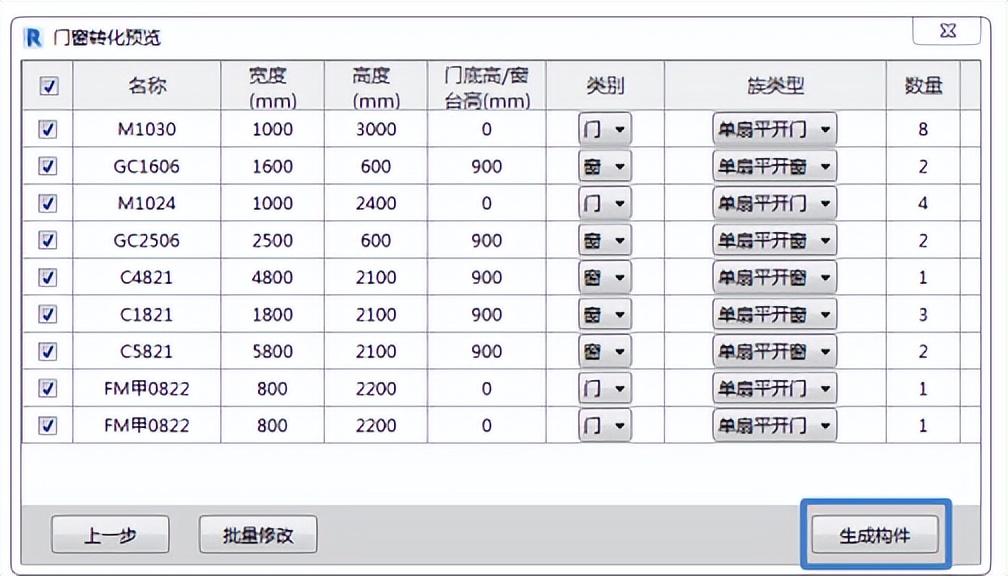
coco2017共有80个子类别,由于该类别是原始数据的子集(原91类别,可参阅原文https://arxiv.org/pdf/1405.0312.pdf%090.949.pdf),其各类别物体的原始ID是从1~90,共90个,中间有断层:
{"1": "person", "2": "bicycle", "3": "car", "4": "motorcycle", "5": "airplane", "6": "bus",
"7": "train", "8": "truck", "9": "boat", "10": "traffic light", "11": "fire hydrant", "13":
"stop sign", "14": "parking meter", "15": "bench", "16": "bird", "17": "cat", "18": "dog",
"19": "horse", "20": "sheep", "21": "cow", "22": "elephant", "23": "bear", "24": "zebra",
"25": "giraffe", "27": "backpack", "28": "umbrella", "31": "handbag", "32": "tie", "33":
"suitcase", "34": "frisbee", "35": "skis", "36": "snowboard", "37": "sports ball", "38":
"kite", "39": "baseball bat", "40": "baseball glove", "41": "skateboard", "42":
"surfboard", "43": "tennis racket", "44": "bottle", "46": "wine glass", "47": "cup", "48":
"fork", "49": "knife", "50": "spoon", "51": "bowl", "52": "banana", "53": "apple", "54":
"sandwich", "55": "orange", "56": "broccoli", "57": "carrot", "58": "hot dog", "59":
"pizza", "60": "donut", "61": "cake", "62": "chair", "63": "couch", "64": "potted plant",
"65": "bed", "67": "dining table", "70": "toilet", "72": "tv", "73": "laptop", "74":
"mouse", "75": "remote", "76": "keyboard", "77": "cell phone", "78": "microwave", "79":
"oven", "80": "toaster", "81": "sink", "82": "refrigerator", "84": "book", "85": "clock",
"86": "vase", "87": "scissors", "88": "teddy bear", "89": "hair drier", "90": "toothbrush"}
那我们就知道,coco在DETR和DINO中,有效的类别任然是从1~90,共80个具体类别(忽略断层ID)。而在原始的DETR中,计算class loss时,采用的是交叉熵:
src_logits = outputs['pred_logits']
idx = self._get_src_permutation_idx(indices)
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)])
target_classes = torch.full(src_logits.shape[:2], self.num_classes,
dtype=torch.int64, device=src_logits.device)
target_classes[idx] = target_classes_o
if torch.min(target_classes_o) < 1 or torch.max(target_classes_o) > 90:
print(target_classes_o)
loss_ce = F.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight)cross_entropy不要求输入为one-hot形式,只要求为整数ID即可。所以,在DETR中,理论上只需要1~90 + 1(no object)=91个维度就够了,那为何是92呢?
这是因为作者初始化的no object为ID “91”(不使用“0”的原因应该只是为了矩阵的操作方便),index 0不使用的情况下,91维进能够表示到ID 90, 故需要设置为91+1=92。
那为何在DINO中是91呢?
DINO中实际也需要用到92。同样的,初始化no object为ID "91", 但由于作者用sigmoid函数来计算loss,即coco的类别之间不产生竞争,每个框预测属于该类还是no object,无需显式的定义一个维度来预测no object。所以,我们初始化时候,看到类别是91.
然而,我们看到,在计算class loss时,多了一个维度,即92:
target_classes = torch.full(src_logits.shape[:2], self.num_classes,
dtype=torch.int64, device=src_logits.device)
target_classes[idx] = target_classes_o
target_classes_onehot = torch.zeros([src_logits.shape[0], src_logits.shape[1], src_logits.shape[2]+1],
dtype=src_logits.dtype, layout=src_logits.layout, device=src_logits.device)
target_classes_onehot.scatter_(2, target_classes.unsqueeze(-1), 1)
target_classes_onehot = target_classes_onehot[:,:,:-1]
loss_ce = sigmoid_focal_loss(src_logits, target_classes_onehot, num_boxes, alpha=self.focal_alpha, gamma=2) * src_logits.shape[1]
losses = {'loss_ce': loss_ce}target_classes_onehot = torch.zeros([src_logits.shape[0], src_logits.shape[1], src_logits.shape[2]+1], dtype=src_logits.dtype, layout=src_logits.layout, device=src_logits.device)
仔细看就会发现,这里shape[2]+1是为了下一步scatter_时使用的,便于能够处理ID“91”,否则会出错。
之后,使用的时候,也是直接忽略了这个临时增加的维度:
target_classes_onehot = target_classes_onehot[:,:,:-1]