文章目录
- Deep Reinforcement Learning for Small Bowel Path Tracking Using Different Types of Annotations
- 摘要
- 本文方法
- 环境
- state
- Action
- reward
- 实验结果
Deep Reinforcement Learning for Small Bowel Path Tracking Using Different Types of Annotations
摘要
小肠路径跟踪是一个具有挑战性的问题,考虑到其沿途有许多褶皱和接触。出于同样的原因,在3D中实现小肠的标签(GT)路径是非常昂贵的。
本文方法
- 使用具有不同类型注释的数据集来训练深度强化学习跟踪器
- 使用只有GT小肠分割的CT扫描以及具有GT路径的CT扫描。它是通过设计一个兼容两者的独特环境来实现的,包括即使没有GT路径也可以定义的奖励。
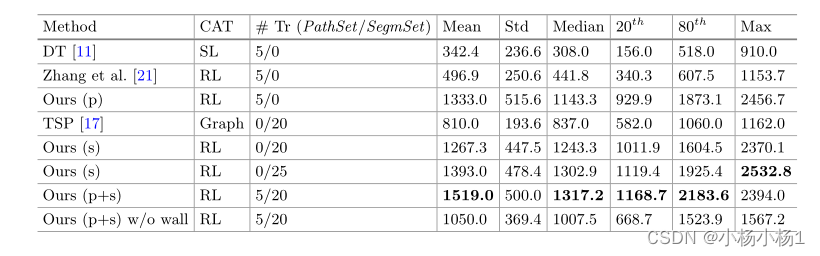
- 实验证明了该方法的有效性。所提出的方法在这个问题上具有高度的可用性,因为它能够利用具有弱注释的扫描,从而可能降低所需的注释成本
本文方法
利用分割标签和路径标签来作为数据的标签
环境
在RL中,代理从与环境交互生成的事件中学习策略π。我们每集使用一张图片。代理(跟踪器)在小肠内的某个位置初始化,并在图像内移动,直到满足某些条件。条件是:1)找到小肠的一端,2)离开图像,或3)处于最大时间步长T。在测试时间中使用了零移动的另一个终止条件。在每个时间步骤t,代理执行由我们的行动者网络预测的动作At(movement),并且作为结果接收奖励rt和新状态st+1。一个事件,它是(st,at,rt)的序列,通过迭代生成。状态空间、动作空间和奖励中的每一个都将在以下部分中进行解释
state
在每个时间步长t,使用以当前位置pt为中心的大小为603mm3的局部图像块来表示代理的状态。
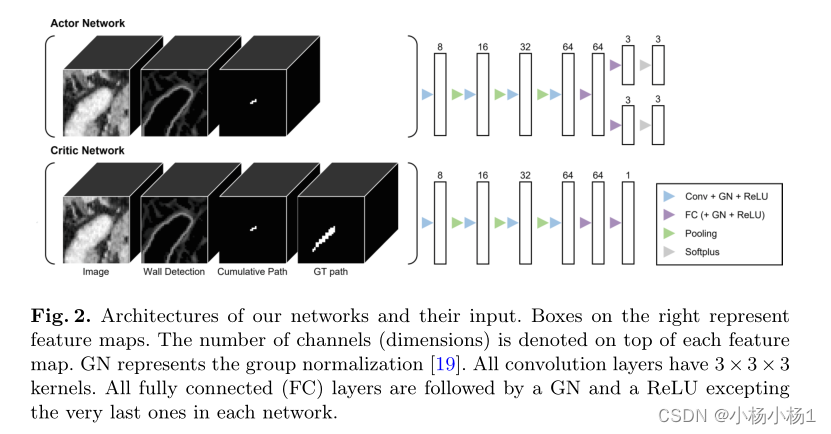
由于接触问题,防止跟踪器穿透肠壁在这个问题上至关重要。为了更好地向代理提供这种意识,除了“普通”图像补丁外,我们还使用墙壁检测作为输入。在我们的数据集中,由于口腔对比,管腔看起来比壁更亮。我们通过使用Meijing滤波器在输入体积中找到低谷来检测壁。我们还提供了代理在当前事件中的累积路径的局部补丁。它表示当前位置周围先前访问的体素,是二进制的
使用了一个演员-评论家算法。演员决定采取哪种行动(政策),评论家判断演员的行动有多好(价值函数)。它们是同时学习的,批评者有助于减少政策更新的差异。评论家只在训练期间使用。在DRL中,策略和值函数由神经网络近似。为此,我们使用独立的网络,即演员网络和评论家网络。特别是,我们使用了非对称行动者-批评家算法。GT路径的附加信息仅被提供给评论家网络。它有助于训练评论家网络,从而为演员提供更好的更新。所有解释的输入补丁被连接并馈送到网络中。对于SegmSet,GT路径不可用,而是使用零张量
Action
动作是根据行动者网络的输出来选择的,行动者网络是贝塔分布的三对参数(α,β)。β分布具有有限的支持[0,1],因此可以比使用高斯更容易地约束作用空间。每对负责沿着每个轴的运动。将软加运算应用于最后一个完全连接层的输出,然后添加1以确保每个α和β都大于1
当满足这个条件时,β分布是单峰的。在训练中从每个贝塔分布中对值进行采样。这种概率采样允许对代理进行探索。
reward

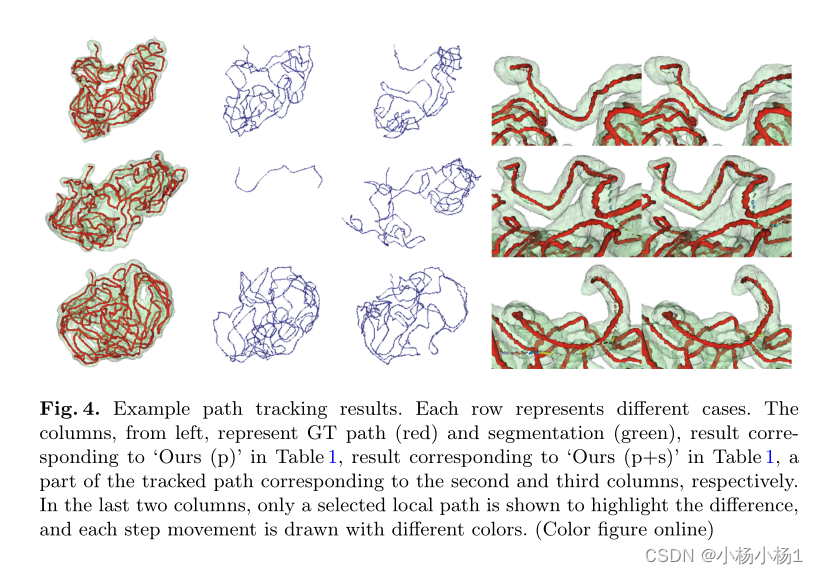
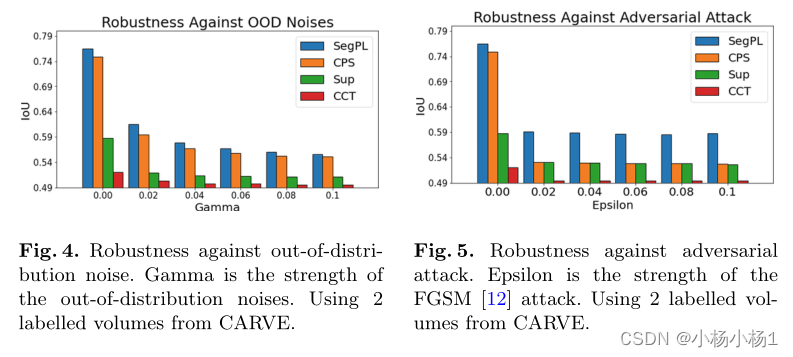
实验结果