引言: 在当今复杂的分布式系统中,追踪用户请求的执行过程变得越来越重要。为了获得全面的系统可见性和更高效的故障排查能力,我们在Flipkart采用了分布式实体追踪的解决方案。本文将介绍我们的实施策略,以及如何使用结构化日志和集中式日志服务来生成和分析跟踪数据,从而提升系统的可靠性和性能。
生成和传播跟踪上下文
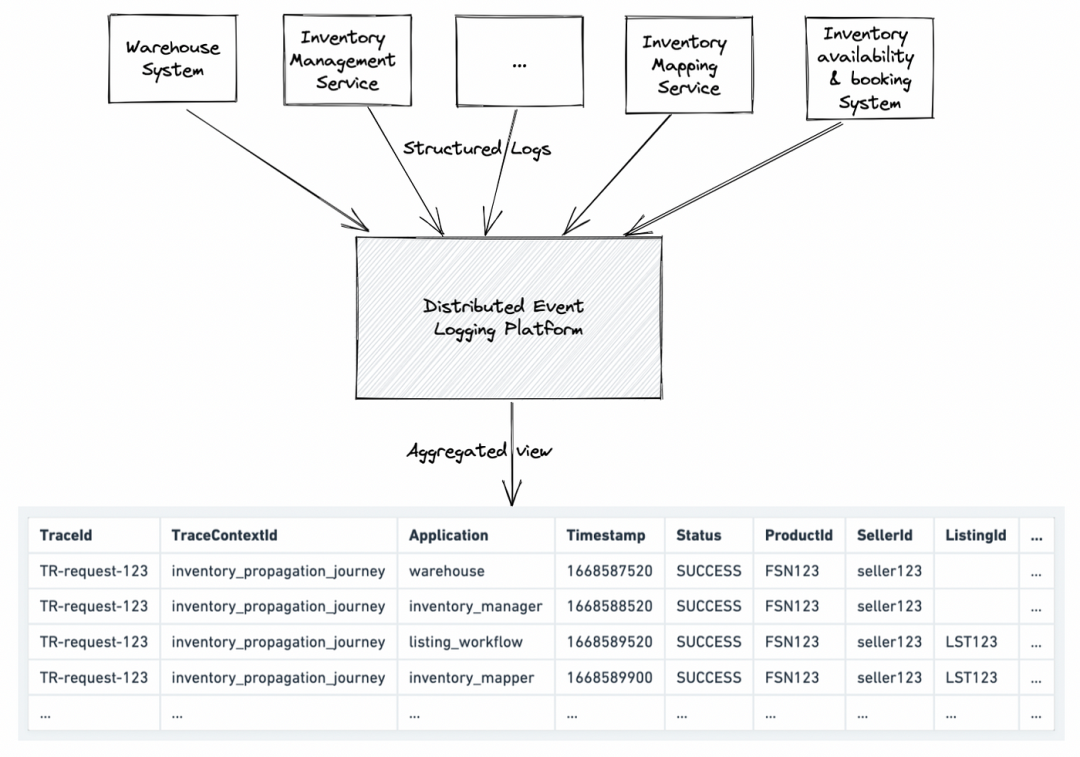
分布式实体追踪的过程始于系统第一次从最终用户那里接收到请求。我们使用唯一的标识符(traceID)来跟踪请求的流动,并确保它在整个调用链中传播。这个traceID可以作为HTTP标头或请求有效载荷的一部分添加到交互中。

使用跟踪上下文添加结构化日志
为了获得有用的跟踪数据,我们要求应用程序在日志中添加跟踪详细信息。结构化日志是一种以预定义格式(如JSON)记录消息的做法,使其适用于机器读取和易于解析。应用程序通过自定义的Appender将跟踪详细信息以JSON格式添加到Syslog中,也可以使用其他日志记录方式。

将日志发送到集中式日志服务
集中式日志服务器是非常重要的,它允许我们集中存储和查询所有日志消息。我们选择与RSyslog集成,通过TCP或UDP将日志发送到集中式日志服务。这样一来,我们可以在一个地方统一管理和分析日志数据,而不必在各个组件上查找。
使用索引查询和构建视图
将日志发送到集中式日志服务后,我们可以利用强大的查询语言(如ELK Stack或Graylog)来构建视图和解决问题。通过根据traceID查询所有相关日志消息,并将它们组合在一起,我们可以获得完整的请求执行图景。通过聚合和可视化日志数据,我们可以更好地理解请求的延迟和失败情况,以及系统中各个组件的行为。
我们的解决方案的优势
相比于开源的追踪解决方案,我们选择了使用我们自家的分布式实体追踪平台。这是因为我们不仅需要跟踪数据,还需要进行深入的日志分析,以获得丰富的洞察力。我们的平台能够解析结构化日志并根据定义的模式进行索引,从而支持有针对性的查询和高效的故障排查。
结论
通过采用分布式实体追踪的解决方案,我们在Flipkart成功提高了系统的可见性和故障排查能力。相比过去需要花费数周的故障排查时间,我们现在只需执行一次查询即可定位和解决问题。我们不仅能够进行趋势分析,还能够快速识别与延迟、错误和消息丢失相关的问题,减少了团队之间的协作需求。在未来,我们还计划通过设置基于索引日志的警报来实现主动故障监测。
通过分布式实体追踪,我们为分布式系统的监控和故障排查提供了一种新的解决方案。结合结构化日志和集中式日志服务,我们能够更全面地了解系统的执行流程,更快速地定位和解决故障,提供卓越的用户体验。