本章内容
- 文章概况
- 模型结构
- 主要方法
- 多尺度框架
- 跨尺度标准化
- 模型输入编码
- 损失函数
- 实验结果
- 消融实验
- 跨尺度标准化
- 自适应损失函数
- 总结
文章概况
《SCALEFORMER: ITERATIVE MULTI-SCALE REFINING TRANSFORMERS FOR TIME SERIES FORECASTING》是2023年发表于ICLR上的一篇论文。作者发现在对不同时间尺度预测的尝试下,逐渐细化预测颗粒有利于时序预测,因此在论文中提出了一种通用多尺度框架,实验表明显著提高前人Transformer系列模型的实验效果。

论文链接
代码链接
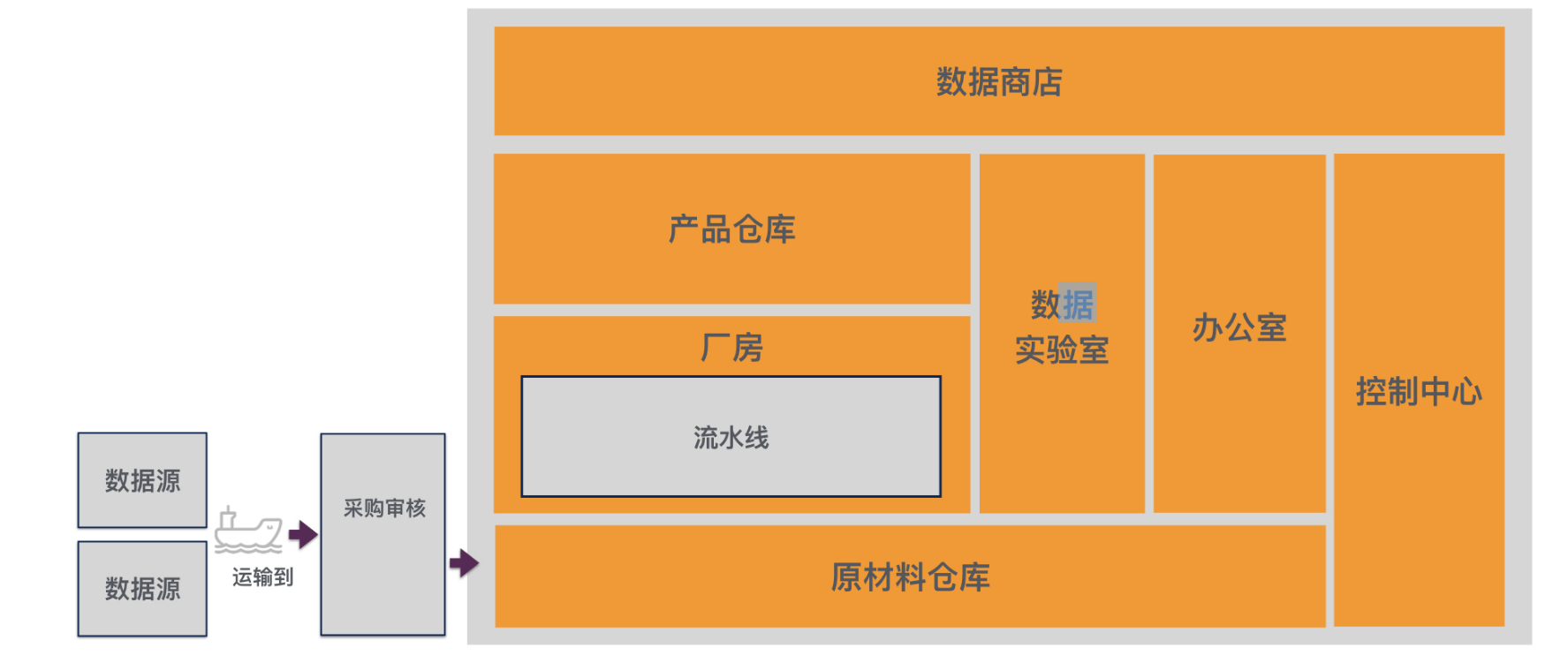
模型结构

X
e
n
c
X^{enc}
Xenc经过池化层下采样得到
X
i
e
n
c
X^{enc}_{i}
Xienc,
X
i
−
1
o
u
t
X^{out}_{i-1}
Xi−1out经过上采样得到
X
i
d
e
c
X^{dec}_{i}
Xidec,
X
i
e
n
c
X^{enc}_{i}
Xienc和
X
i
d
e
c
X^{dec}_{i}
Xidec经过Cross-Scale Normalization后得到标准化之后的两组数据,随后将这两组数据输入预测模型中。需要注意的是
X
i
−
1
o
u
t
X^{out}_{i-1}
Xi−1out是上一个
s
t
e
p
i
−
1
step_{i-1}
stepi−1步骤模型的输出,而当
i
=
1
i=1
i=1时,
X
0
o
u
t
X^{out}_{0}
X0out取0。
主要方法
多尺度框架

多尺度主要体现在两个地方,一个是模型中
s
t
e
p
step
step迭代
m
+
1
m+1
m+1次,遍历
S
S
S中所有尺度因子,另一个是每次
s
t
e
p
step
step包含一对上下采样AvgPool和Upsample。
跨尺度标准化

如上图所示,多尺度框架导致了数据分布将发生变化。因此为了缓解分布差距,作者将上下采样之后的数据进行联合标准化,换言之就是放一起算。

模型输入编码
常规三要素:数值编码、时间编码、位置编码
损失函数
使用MSE,对异常值敏感,MSELoss抛弃;
使用Huber,没异常值效果不佳,HuberLoss抛弃;
最后选择自适应损失函数

我还没看,有兴趣的可以去了解一下 论文链接
实验结果
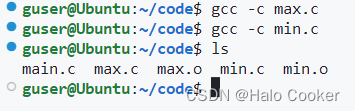
以上对比了作者所提框架+前人模型的效果变化情况,实验表明效果提升显著。
(更多实验结果见附录)
消融实验
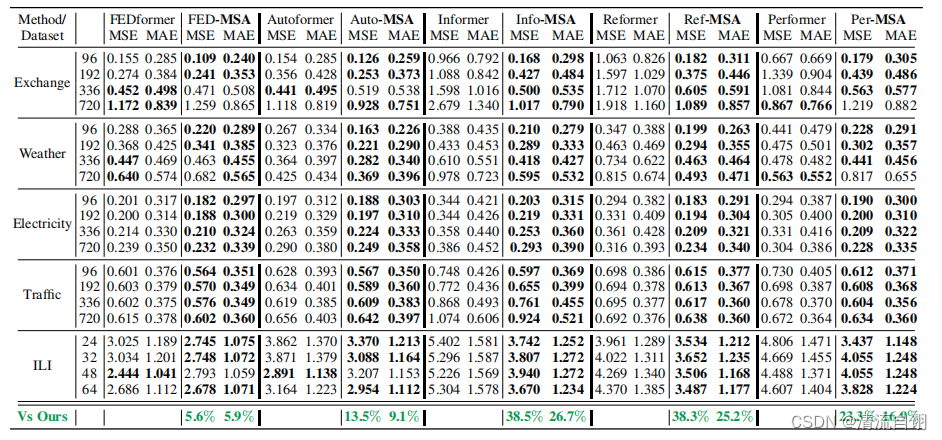
跨尺度标准化

有无标准化前后对比,可以看出确实标准化之后的曲线更加稳定,同时也更接近真实情况。
上表为无归一化和原始模型的实验对比,可以发现没有了跨尺度标准化操作,所提框架总体上并不如原始模型效果好。通过以上两种角度的对比,作者再一次确认了跨尺度标准化的重要性。
自适应损失函数

基准为前人原始结果,-A为使用自适应损失函数,-MS为使用多尺度框架和MSELoss,-MSA为本文所提方法。总体而言,红色竖条更短、MSE误差更小。由此可以一定程度上表明自适应损失函数和多尺度框架的的有效性。
总结
在文章的最后,作者还将所提方法应用于概率预测以及非Transformer系列的模型中,从实验结果看是可行的。这篇论文发现了多尺度采样在时序预测中的可探索性,刚好也印证了年初我写的一个时序模型的效果,同样也是类似多尺度采样建模,效果还不错,重要的是参数量很少、跑得很快。另外值得提出的是,作者没有按照以往构建新模型的方式进行创新探索,而是对前人模型的外围框架进行创新,在模型已经卷到现在的情况下,这无疑不是一个新的研究思路。