目录
- Linux安装
- 索引
- 索引的概述
- 索引的结构
- 索引结构的介绍
- Btree
- B+tree
- Hash
- 索引的分类
- 索引的语法(创建,查看,删除等)
- SQL性能分析
- SQL的执行频率(查看SQL的执行频率)
- 慢查询日志
- show profiles
- explain执行计划
- 索引的使用原则
- 最左前缀法则(联合索引)
- 范围查询
- 索引失效的情况
- SQL提示
- 覆盖索引
- 前缀索引
- 单列索引与联合索引
- 索引的设计原则
- 小结
Linux安装
搭建虚拟机服务器Linux环境,在虚拟机上下载MySQL,
-
虚拟机的配置:
最开始配置网络时使用NAT模式,然后在网络上搜索相关内容:
例如:配置固定ip等:https://blog.csdn.net/cuixianheng/article/details/107726996
如何连接finalshall:https://zhuanlan.zhihu.com/p/338224327
注意一点:https://zhuanlan.zhihu.com/p/338224327这篇文章中BOOTPROTO=static不行,BOOTROTO还是默认的dhcp,这样就可以使虚拟机连接上网络,从而为下面再linux上下载mysql的依赖打基础
-
在Linux上启动MySQL:
这里启动之前需要注意,在linux中全局变量lower_case_table_names 的默认值为0,这样就不能远程连接window系统,所以要在初始化mysql之前把lower_case_table_names改为1systemctl start mysqld --启动mysql systemctl restart mysqld --重启mysql systemctl stop mysqld --关闭mysql 在mysql中可以直接使用exit退出mysqlmysql在finalshall启动完成后,就可以使用
mysql -u root -p去连接mysql,连接后会要求输入密码,但是由于下载使用的使npm,密码是随机生成的,此时使用密码就需要一个指令
grep 'temporary password' /var/log/mysqld.log
当然,也可以直接打开/var/log/mysqld.log文件夹,在里面找到临时密码粘贴复制
使用cat /var/log/mysqld.log可以查看/var/log/mysqld.log文件夹的内容
下面一段就是临时密码2023-05-27T08:20:16.473537Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: #U+y&nqhr1rV --这一段就是密码 -
登录成功
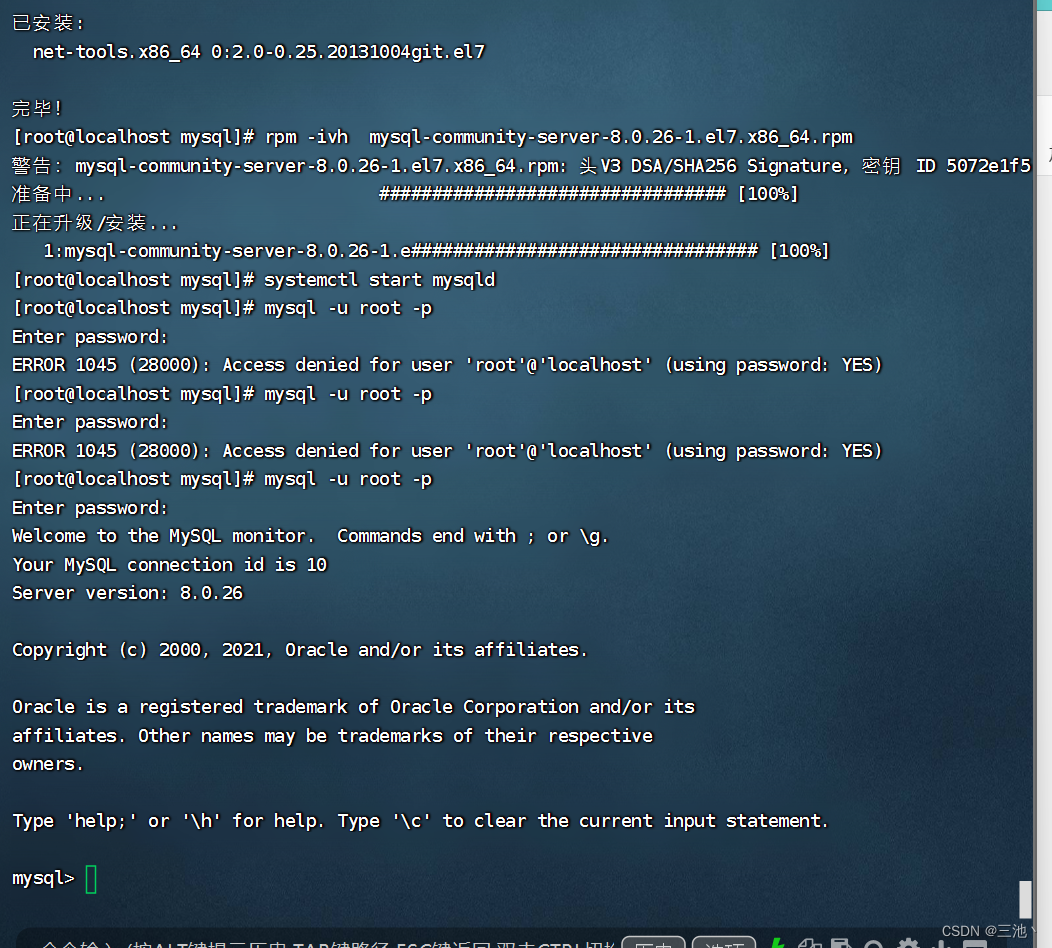
注意:linux中密码不显示,连*也没有 -
修改root用户密码:
ALTER USER 'root'@'localhost' IDENTIFIED BY '1234';
-- 现在设置会报错,因为在linux中,
-- root密码的设置有限制,默认是中等密码难度,
可以通过下面的两条指令来修改密码难度
-- 设置密码的复杂度为简单类型,只要求长度
set global validate_password.policy=0;
-- 设置密码的长度为4
set global validate_password.length=4;
- 创建用户(这个用户用于远程访问)
语法:
create user 'root'@'%' IDENTIFIED WITH mysql_native_password BY '1234';
- 给新创建的root用户分配权限
grant all on *.* to 'root'@'%';
索引
索引的概述
索引(index)是帮助MySQL高效获取数据的数据结构(有序),在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引
一个字段可以建立多个索引
- 有索引和没有索引的对比
select *from user where age=45;
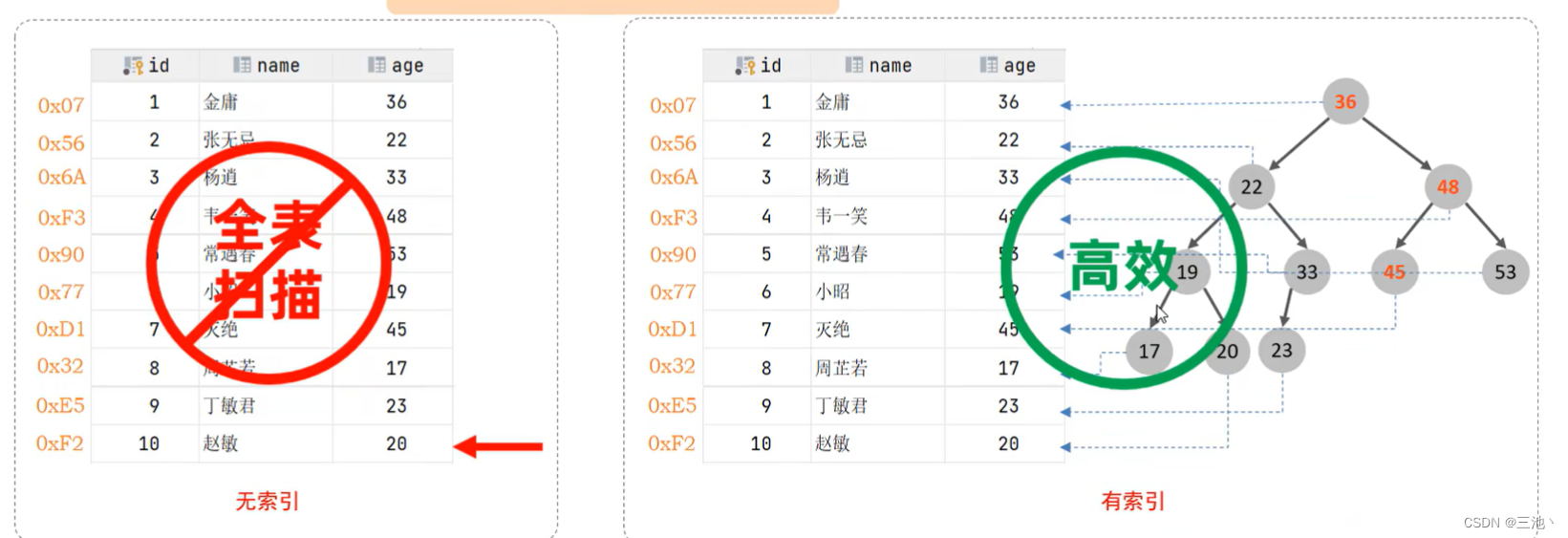
注意:上图的二叉树并不是真实的数据结构,只是一个比喻
没有索引会对表中的数据挨个扫描,直到找出所有结果,效率很低,有索引时就会使用数据结构,查找效率大幅提高
- 索引的优缺点

优点:提高数据检索效率,降低数据库的io成本,减低排序成本,减低cpu的消耗
缺点:索引列也会占用空间,索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行INSERT,UPDATE,DELETE时效率降低
索引的结构
索引结构的介绍
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的结构,主要包含以下几种

B+Tree索引:最常见的索引类型,大部分引擎都支持B+树索引
Hash索引:底层数据结构是用哈希表实现的,只有精确匹配索引列的查询才有效,不支持范围查询
R-tree(空间索引)空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少
Full-text(全文索引)是一种通过建立倒排索引,快速匹配文档的方式,类似于Lucene,Solr,ES
上述索引结构在不同存储引擎中的支持情况
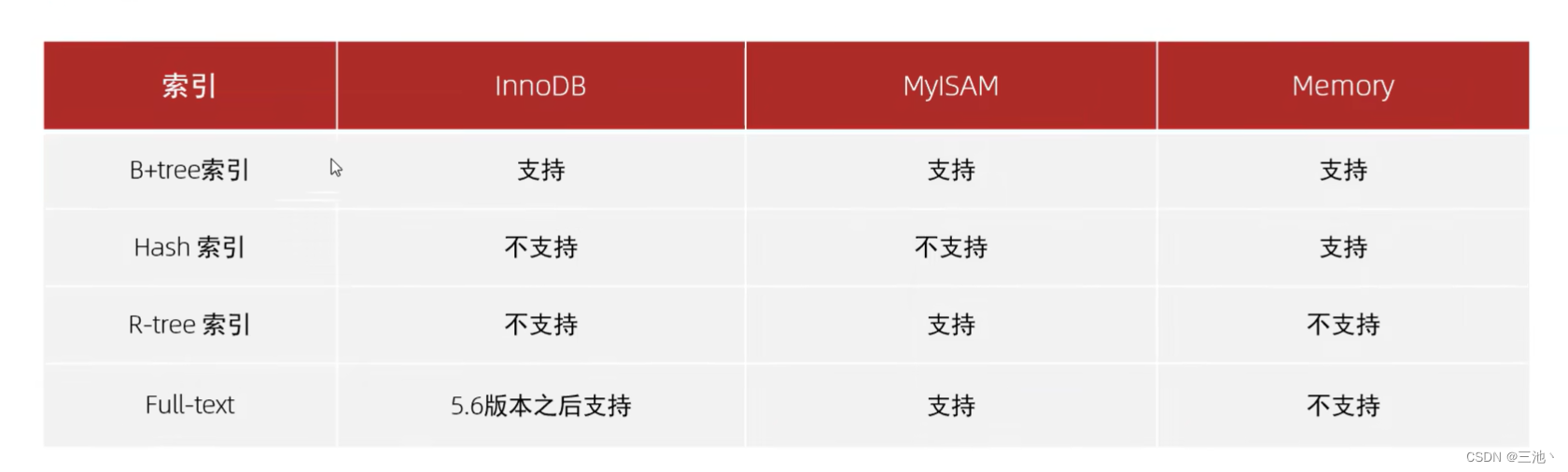
平时用的最多的索引就是B+tree索引,如果平时用的索引没有特别指明,那就是值B+tree索引
Btree
二叉树缺点:顺序插入时,会形成一个链表,查询性能大大降低,大数据量的情况下,层级较深,检索速度慢
红黑树缺点:大数据量的情况下,层级较深,检索速度慢
-
B-Tree(多路平衡查找树)
树的度数:一个节点的字节点个数一颗最大度数为5的b-tree树为例(每个节点最多存储4个key,可以有五个指针)
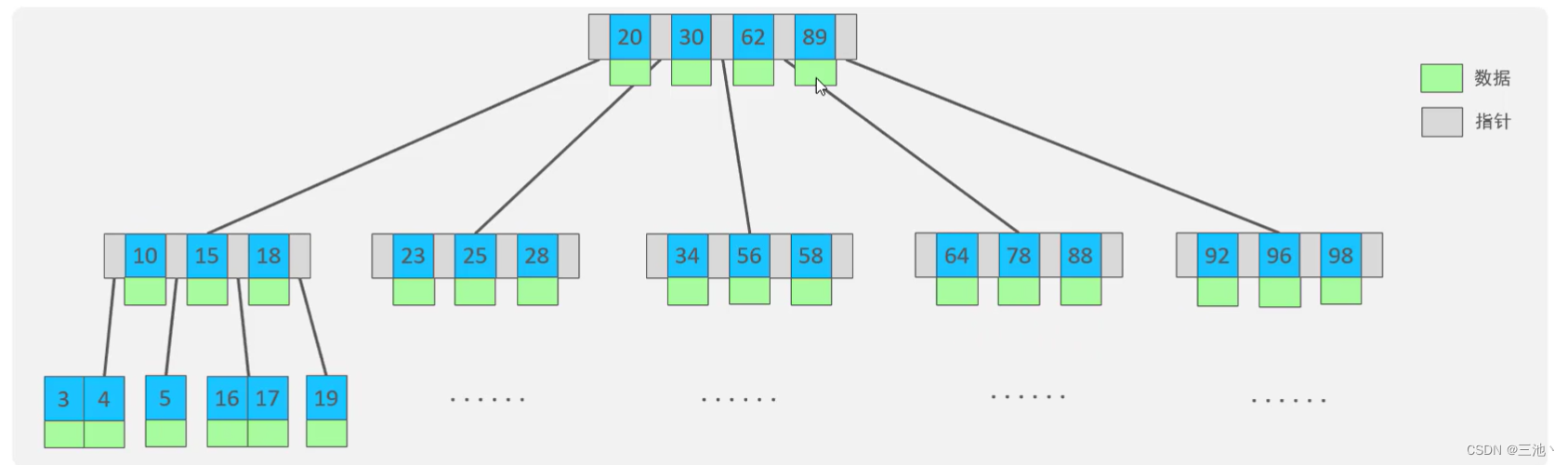
例如:这里树的根节点有4个key,分别是20,30,62,89,那么,小于20的数据就会指向一个子节点,同理,20-30,30-62,62-89,大于89也都会分别指向不同的子节点 -
b-tree的生成:
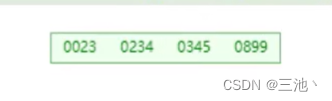
先往树里插入数据,例如上面的最大度数为5的b-tree树,当往一个节点插入4个数据(key)时,此时这个节点就已经满了,再插入数据就会进行裂变,会进行一个中间元素向上裂变的过程
例如:
四个key
再往里插入1200
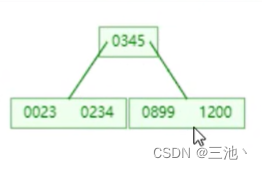
0345就会变成中间元素,向上分裂
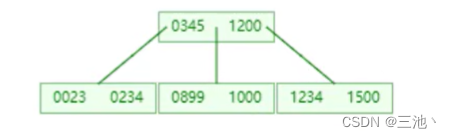
插入元素超过最大度数的限制时会再次向上分裂,会把中间元素放到最上面的节点中
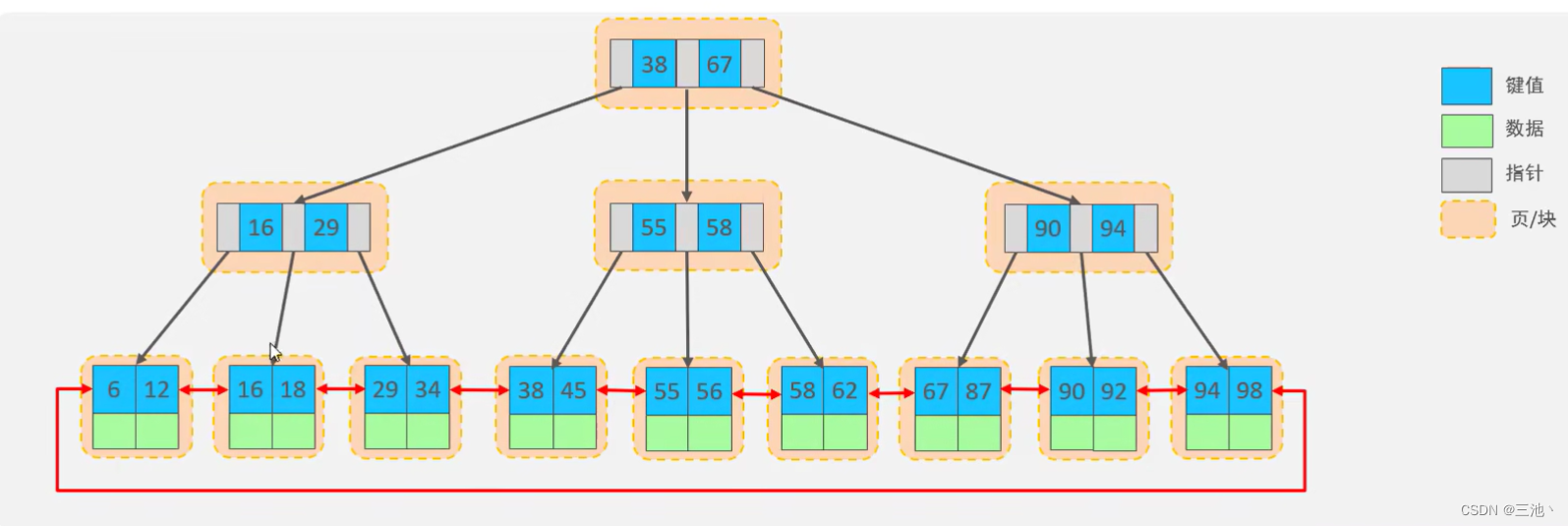
B+tree
B+tree是B树的变种
以一个最大度数为3的B+tree为例
- B+tree的特点
1.所有的元素都会出现在叶子节点
2.在B+tree中,所有的叶子节点形成了一张单向链表
3.数据都存放在叶子节点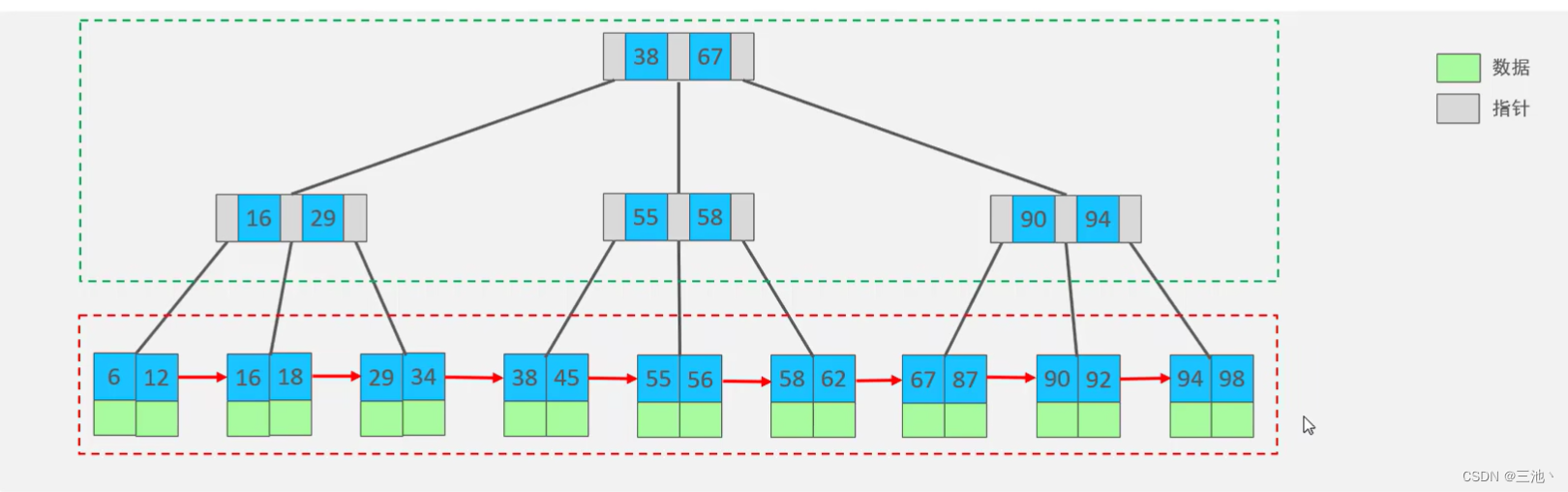
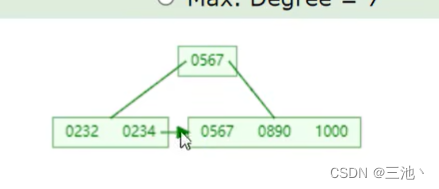
- B+tree的生成
和btree类似,也是超出范围(最大度数)后中间元素向上分裂,但是,不同的地方在于,B+tree向上分裂的同时,会把中间元素留在下面(留在叶子节点),同时叶子节点形成链表,向上分裂时,叶子节点以向上的元素为分裂点进行分裂
以一颗最大度数为5的B+tree为例:
当key=4时

当key>4时
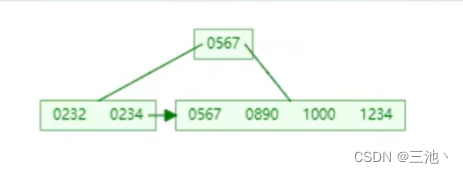
在上面的图中插入2345,就会变成下面的样子
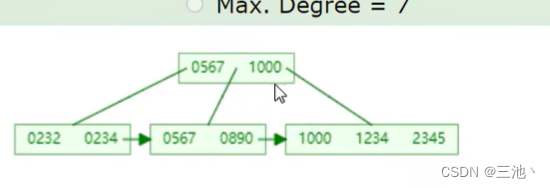
MySQL索引数据结构对经典的B+tree进行了优化,在原B+tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+tree,提高区间访问
的性能
MySQL中的B+tree
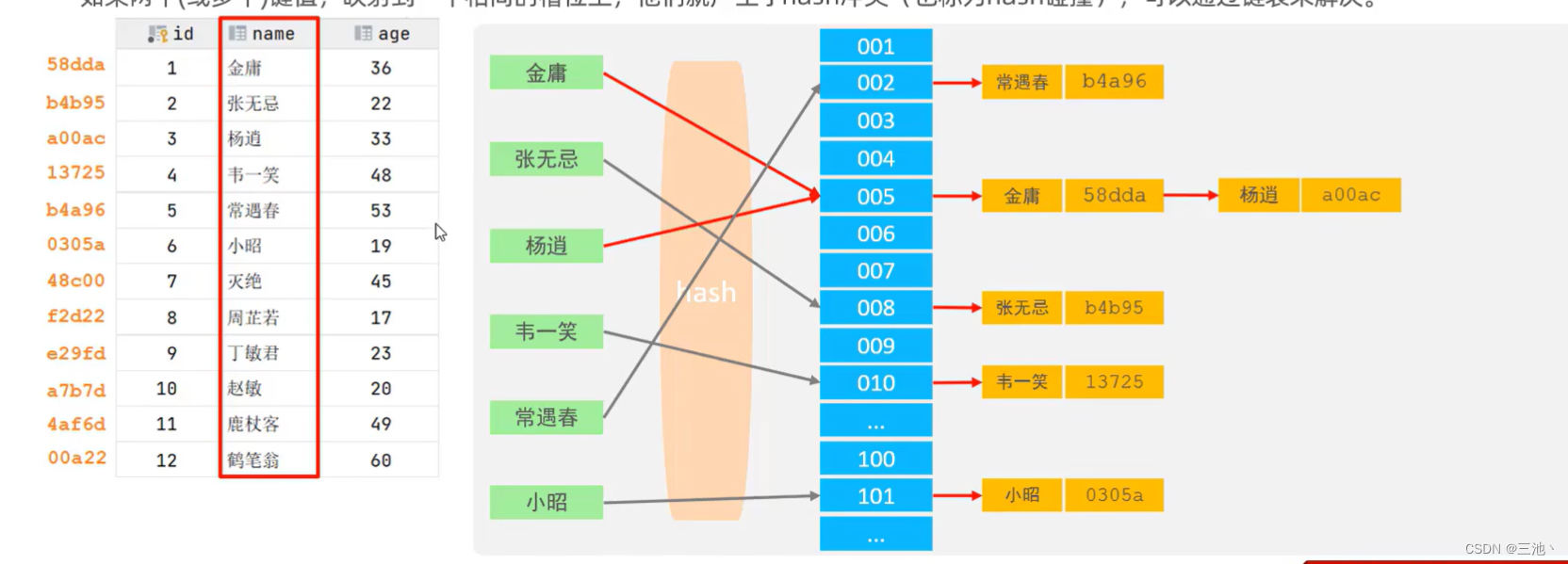
Hash
哈希索引就是采用一定的哈希算法,将键值换算成新的hash值,映射到对应的键位上,然后存储在hash表中
如果两个(或多个)键值,映射到一个相同的槽位上,他们就形成了hash冲突(也成为hash碰撞),可以通过链表来解决
-
Hash索引的特点:
1.Hash索引只能用于对等比较(=,in),不支持范围查询(between,<,>,…)2.无法利用索引完成排序操作
3.查询效率高,通常只需要一次检索就可以了(不出现hash碰撞的情况下),效率通常要高于B+tree索引
在MySQL中支持hash索引的是Memory引擎,而InnoDB中有自适应hash功能,hash索引是存储引擎根据B+tree索引在指定条件下自动构建的,即在InnoDB中,MySQL会根据查询条件自适应的将B+tree转为hash

1.相对于二叉树,红黑树,层级更少,搜索效率高
2.对于Btree来说,Btree中无论叶子节点还是非叶子节点,都会保存数据,这样导致一页(一页就是一个节点,一页在之前的笔记中有,固定16kb)中能存储的键值减少,指针也就会随之减少,这样在相同的层级下存储的数据就不如B+tree,同理,存储相同数据时,Btree的层数会比B+tree多,性能也就随之减低
3.相对于Hash索引,B+tree支持范围匹配和排序操作
索引的分类
索引主要分为四类:
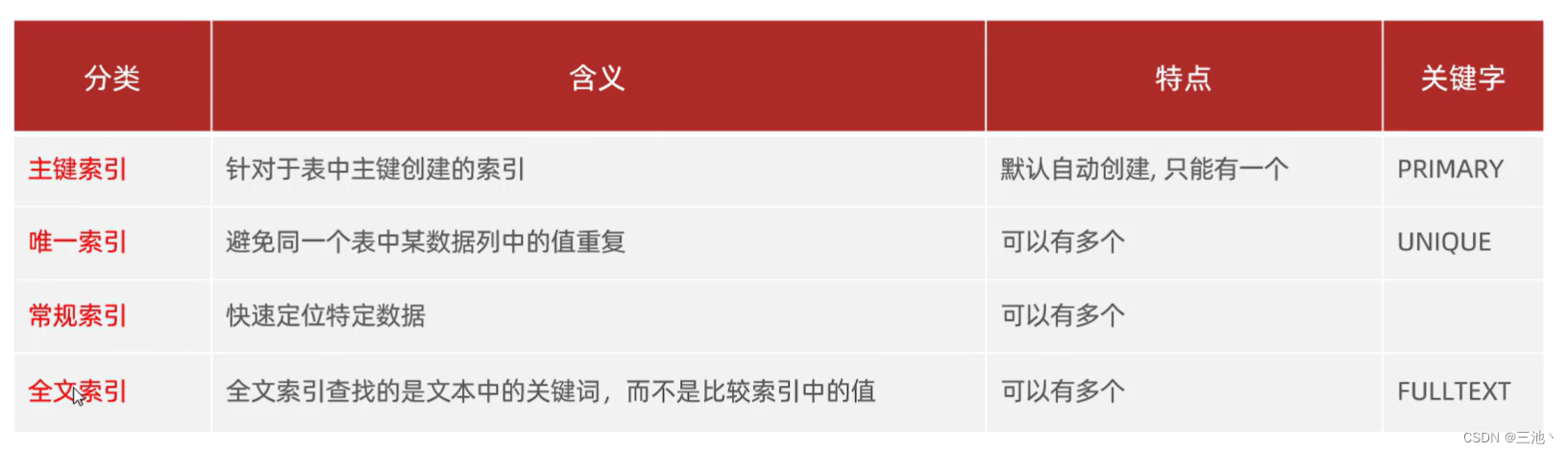
主键索引PRIMARY--primary:针对于表中主键的索引,默认自动创建,只能有一个,
唯一索引UNIQUE--unique:避免同一个表中某数据列中的值重复,可以有多个
常规索引:快速定位特定数据,可以有多个
全文索引FULLTEXT--fulltext:全文索引查找的是文本中的关键词,而不是比较索引中的值,可以有多个
- 在InnoDB中,根据索引的存储形式,又可以分为以下两种

聚集索引(Clustered Index):将数据与索引放在一起,索引结构的叶子节点保存了行数据,必须有,而且只有一个
二级索引(Secondary Index):将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键,可以存在多个
-
聚集索引的选取规则
1.默认主键索引就是聚集索引2.如果没有主键,使用第一个唯一(unique)索引作为聚集索引
3.如果没有主键也没有唯一索引,innoDB会自动生成一个rowid作为隐藏的聚集索引
例子:
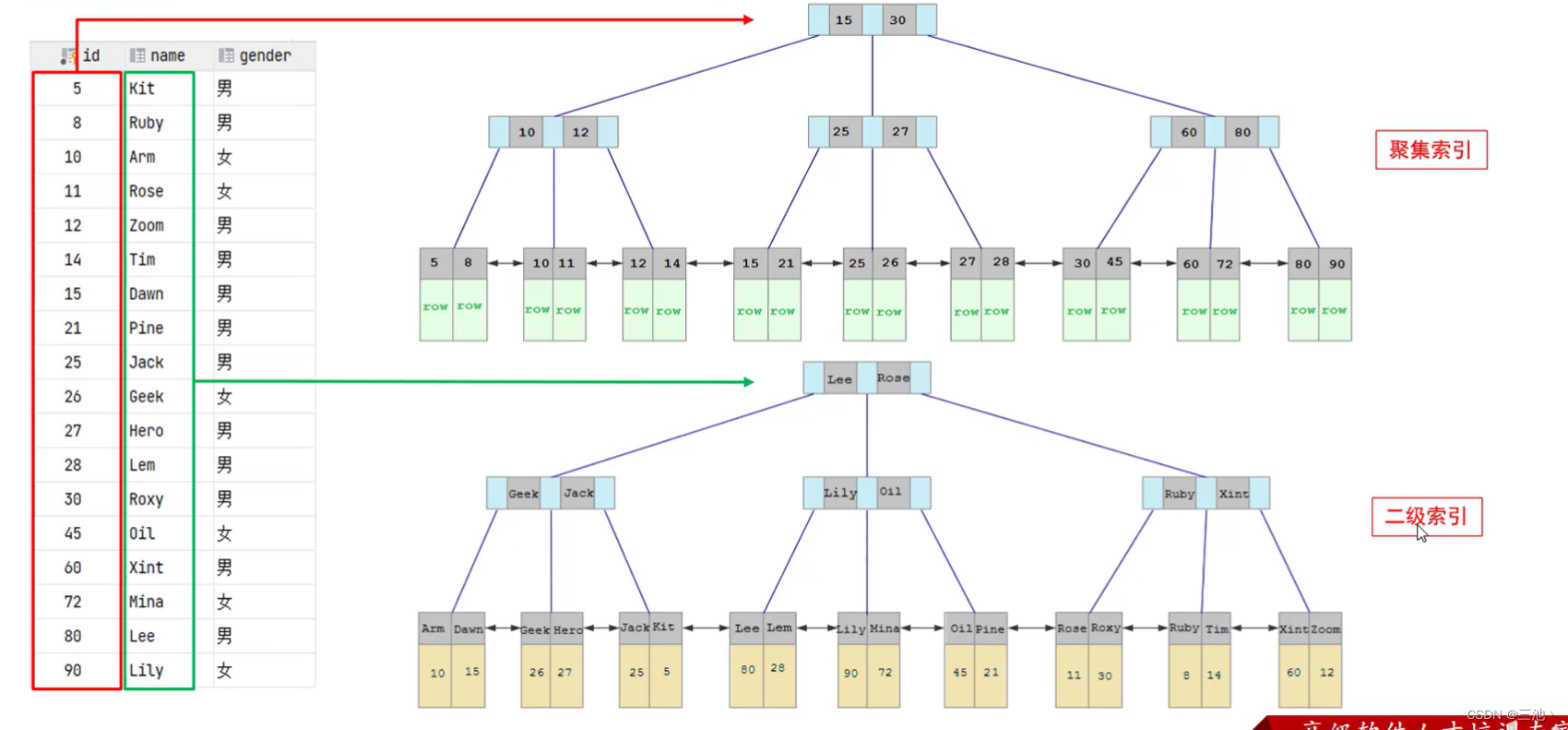
这里id为主键,所以id就是聚集索引,id形成的聚集索引就是上图的第一个B+tree结构,叶子节点存储的就是id所对应的那一行的数据,例如,id=5的叶子节点对应的就是第一行的数据,
第二个B+tree结构对应的就是二级索引,二级索引的叶子节点所对应的数据就是主键值,
如果查询时不是通过主键查询,那么就会先走二级索引查到对应的主键值,再通过对应的主键值在聚集索引中查找到对应的行元素
这个过程就叫作回标查询

第一个执行效率高,因为他直接通过主键查找元素, 直接使用聚集索引查找数据,而第二条要先在二级索引找到对应的id值,再通过id值在聚集索引中查找对应的数据(回表查询)


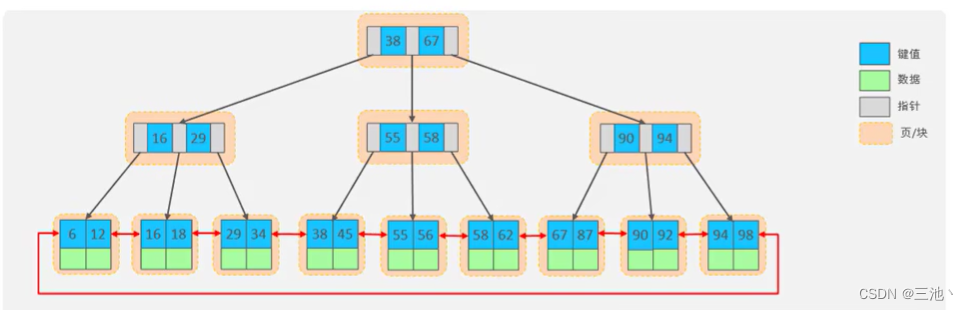
在高度为2的情况下,设主键为n,那么就有
n8+(n+1)6=161024;
因为一个节点就是一页,一页的大小时16kb,也就是161024个字节
解出n=1170,所以有1171个键,那么两层就能有117116kb=18736kb的存储空间
同理,三层就会有11711171*16kb=21939856kb的存储空间
索引的语法(创建,查看,删除等)
– table_name:表名 index_col_name:字段名
- 创建索引
CREATE [UNIQUE | FULLTEXT]
INDEX index_name ON table_name(index_col_name,...);
create [unique | fulltext] -- 不加这两个参数就代表常规索引
index index_name on table_name(index_col_name,...);-- 括号里是字段名
-- 这三个点表示一个索引可以关联多个字段
-- 一个索引只关联一个字段就叫作单列索引
-- 一个索引关联多个字段那么就叫作联合索引
-- table_name:表名 index_col_name:字段名
- 查看索引
SHOW INDEX FROM table_name;
show index from table_name;
-- 查看指定表中的所有索引
- 删除索引
DROP INDEX index_name ON table_name;
drop index index_name on table_name

表的详细情况
mysql> select *from tb_user_s1;
+----+-----------+-------------+---------------+-----------------+------+--------+--------+---------------------+
| id | name | phone | email | profession | age | gender | status | createtime |
+----+-----------+-------------+---------------+-----------------+------+--------+--------+---------------------+
| 1 | 鲁班 | 12345678910 | 123@qq.com | 软件工程 | 22 | 1 | 3 | 2012-02-01 00:00:00 |
| 2 | 华佗 | 12645678910 | 12@qq.com | 互联网工程 | 22 | 1 | 3 | 2012-02-02 00:00:00 |
| 3 | 张飞 | 12343678910 | 1@qq.com | 土木工程 | 22 | 1 | 3 | 2012-02-03 00:00:00 |
| 4 | 关羽 | 12345678910 | 13@qq.com | 计算机 | 22 | 1 | 3 | 2012-02-04 00:00:00 |
| 5 | 刘备 | 12315678910 | 23@qq.com | 软件工程 | 22 | 1 | 3 | 2012-02-11 00:00:00 |
| 6 | 猴子 | 12342678910 | 1234@qq.com | 化学工程 | 22 | 1 | 3 | 2012-02-21 00:00:00 |
| 7 | 压缩 | 12345678910 | 1223@qq.com | 通讯工程 | 22 | 1 | 3 | 2012-02-06 00:00:00 |
| 8 | 剑圣 | 12345678610 | 1123@qq.com | 软件工程 | 22 | 1 | 3 | 2012-02-12 00:00:00 |
| 9 | 刀妹 | 12345698910 | 12344@qq.com | 国际贸易 | 22 | 1 | 3 | 2012-02-15 00:00:00 |
| 10 | 小法师 | 12245678910 | 13235@qq.com | 软件工程 | 22 | 1 | 3 | 2012-02-09 00:00:00 |
| 11 | 佐伊 | 12345678910 | 12213@qq.com | 园林工程 | 22 | 1 | 3 | 2012-02-11 00:00:00 |
| 12 | 狼人 | 12345658910 | 124653@qq.com | 软件工程 | 22 | 1 | 3 | 2012-02-21 00:00:00 |
| 13 | 男刀 | 12385678910 | 12203@qq.com | 软件工程 | 22 | 1 | 3 | 2012-02-11 00:00:00 |
| 14 | vn | 32345678910 | 12398@qq.com | 人工智能 | 22 | 1 | 3 | 2012-02-21 00:00:00 |
| 15 | 卡沙 | 12325678910 | 12013@qq.com | 应用数学 | 22 | 1 | 3 | 2012-02-21 00:00:00 |
| 16 | 烬 | 12345378910 | 12023@qq.com | 物理 | 22 | 1 | 3 | 2012-02-19 00:00:00 |
+----+-----------+-------------+---------------+-----------------+------+--------+--------+---------------------+
16 rows in set (0.00 sec)
索引的名称:一般为idx_表名_字段名
-- 1.
create index idx_user_name on tb_user_s1(name);
-- 2.
create unique index idx_user_phone on tb_user_s1(phone);
-- 3.在联合索引中,字段的顺序是有讲究的
create unique index idx_user_pro_age_status on tb_user_s1(profession,age,status);
SQL性能分析
SQL性能分析就是为了SQL优化。在SQL优化时主要优化的是查询语句(select)
SQL的执行频率(查看SQL的执行频率)
以SQL的执行频率来判断当前数据库是以什么操作为主,例如:以增删为主,以更新为主,以查询为主等
MySQL客户端连接成功后,通过
show [session | global] status
命令可以提供服务器状态信息,通过一些指令,可以查看当前数据库的INSERT,UPDATE,DELETE,SELECT的访问频次
-- 查看全局的状态信息,
SHOW GLOBAL STATUS LIKE 'Com_ _ _'; -- 一个下划线就代表一个字符的信息,
-- 实际写的时候下划线中间没有空格
SHOW SESSION STATUS LIKE 'Com_ _ _'; -- 查看当前会话的状态信息
例子:
mysql> show global status like 'Com_______';-- 这里有7个下划线
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_binlog | 0 |
| Com_commit | 0 |
| Com_delete | 0 |-- 删除
| Com_import | 0 |
| Com_insert | 1 |-- 插入的频率
| Com_repair | 0 |
| Com_revoke | 0 |
| Com_select | 7 |-- 查询,当查询占据频率的大部分时,此时就需要进行优化
| Com_signal | 0 |
| Com_update | 0 |-- 修改
| Com_xa_end | 0 |
+---------------+-------+
11 rows in set (0.03 sec)
慢查询日志
慢查询日志是MySQL提供的,它会记录所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的SQL语句,MySQL的慢查询日志默认关闭,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息
# 这里修改配置文件需要vi编辑器
# 开启慢查询日志的开关
slow_query_log=1-- 开启
slow_query_log=0-- 关闭
# 设置慢查询日志的时间
long_query_time=秒数;
# 例如设置慢查询日志的时间为2秒,当SQL语句执行时间超过2秒,
# 就会视为慢查询,记录到慢查询日志中
long_query_time=2
# 具体修改配置文件的代码
vi /etc/my.cnf
打开之后点击i进入修改模式
在最底下加上
slow_query_log=1
long_query_time=2
之后点击esc退出,然后点击shift+:输入x保存
再然后输入systemctl restart mysqld
重启mysql
之后就开启了慢查询日志
查看慢查询日志的开关状态的语句:
show variables like 'slow_query_log';
-- 查询结果
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| slow_query_log | OFF |
+----------------+-------+
1 row in set (0.02 sec)
实时查看慢查询日志的代码
-- 先用cd切换到这个目录下
cd /var/lib/mysql
-- 然后执行下面这条语句就可以实时查看慢查询日志,
-- 只要有执行时间超过指定时间的,都会被慢查询日志记录
tail -f localhost-slow.log
show profiles
profile详情
show profiles能够在做SQL优化时帮助我们了解每一条SQL语句耗时多少和时间耗费到哪里去了,通过have_profiling参数,能够看到当前MySQL是否支持profile操作,如果为yes就是支持,如果为no就是不行
select @@have_profiling
默认profiling是关闭的,可以通过set语句在session/global级别开启profiling
set profiling=1;-- 开启profiling
- profilie的指令
# 查看每一条SQL的耗时基本情况 show profiles; # 查看指定query_id的SQL语句各个阶段的耗时情况 show profile for query query_id; # 查看指定query_id的SQL语句的CPU的使用情况 show profile cpu for query query_id;
explain执行计划
通过explain或者desc命令可以获取mysql如何执行select语句的信息,包括select语句执行过程中表如何连接和连接的顺序
语法:
# 直接在要查询的select语句之前加上关键字explain/desc
explain select 字段列表 from 表名 where 条件;
desc select 字段列表 from 表名 where 条件;
mysql> explain select *from tb_user_s1 where id=10;
+----+-------------+------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | tb_user_s1 | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)

-
explain中各个字段的含义(每一列的含义)
1.id
select查询的序列号,表示查询中执行select子句或者是操做表的顺序(id相同,执行顺序从上到下,id不同,值越大,越先执行)上图id只有一个,这是由于单表查询,对于多表查询来说,这里的id就会有多个
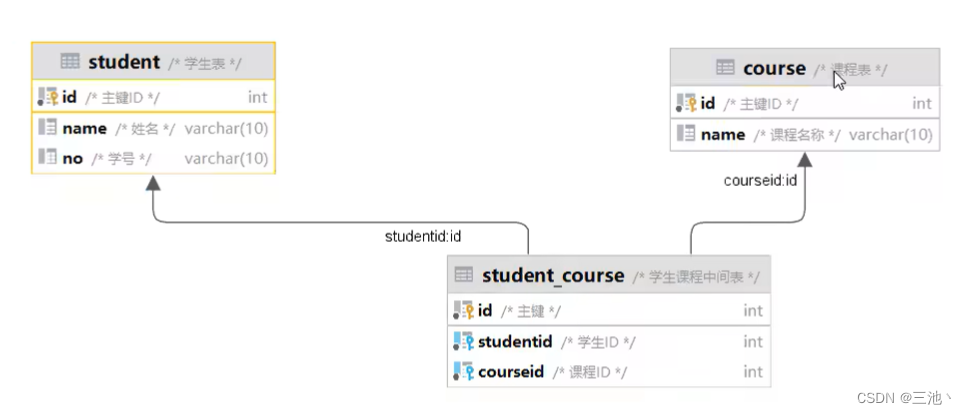
课程表
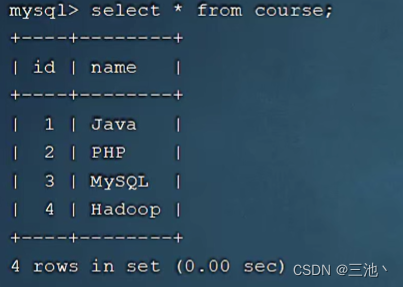
学生表
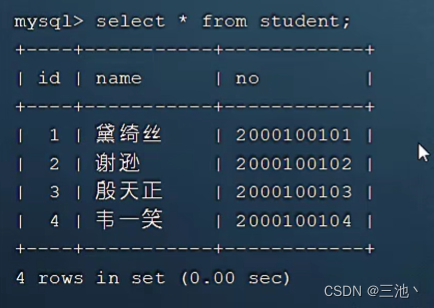
课程与学生之间的关系
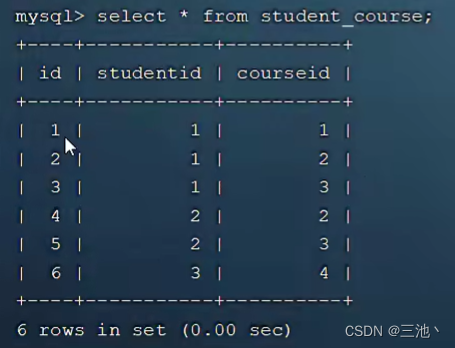
下图中sql的执行顺序就是c-》sc-》< subquery2 >-》s
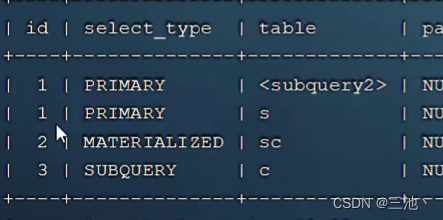
2.select_type
表示select的类型,常见的取值有SIMPLE(简单表,既不使用表连接或子查询),PRIMARY(主查询,即外层的查询),UNION(UNION中的第二个或者后面的查询语句),SUBQUERY(SELECT/WHERE之后包含了子查询)等3.type(主要关注的字段)
表示连接类型,性能由好到差的连接类型为NULL,system,eq_ref,ref,range,index,all,在优化时尽量把性能往前优化4.possible_key(主要关注的字段)
显示可能应用于这张表上的索引,一个或多个5.Key(主要关注的字段)
实际用到的索引,如果为NULL,则就没有使用索引6.Key_len(主要关注的字段)
表示索引使用的字节数,该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好7.rows
MySQL认为必须要执行查询的行数,在InnoDB中,是一个估计值,可能并不总是准确的8.filtered
表示返回结果的行数占需读取行数的百分比,filtered的值越大越好9.Extra(主要关注的字段)
额外信息
索引的使用原则
最左前缀法则(联合索引)
如果一个索引关联了多个字段(联合索引),在使用时就要遵循最左前缀法则,
最左前缀法则:查询从索引的最左列开始,如果没有最左边的列,那么就不能使用索引查询,如果存在最左边的列,但是查询时查询条件跳过了索引中的某一列,那么索引将部分失效(最左边列之后的索引都会失效)
-- 可以使用索引查询,因为最左边的索引存在且没有跳过任何一个列
-- 这里这三个条件的位置可以改变,不会影响,但是最左的字段必须存在
explain select *from tb_user_s1
where profession='软件工程' and age=22 and status='3';
+----+-------------+------------+------------+------+-------------------------+-------------------------+---------+-------------------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+-------------------------+-------------------------+---------+-------------------+------+----------+-----------------------+
| 1 | SIMPLE | tb_user_s1 | NULL | ref | idx_user_pro_age_status | idx_user_pro_age_status | 73 | const,const,const | 6 | 100.00 | Using index condition |
+----+-------------+------------+------------+------+-------------------------+-------------------------+---------+-------------------+------+----------+-----------------------+
1 row in set, 1 warning (0.01 sec)
-- possible_keys显示可能使用的索引
-- key显示实际使用的索引
-- key_len 显示索引使用的字节数
-- 不能使用索引查询,因为在联合索引中间age没有查询,所以查询时不能使用索引
mysql> explain select *from tb_user_s1 where age=22 and status='3'
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | tb_user_s1 | NULL | ALL | NULL | NULL | NULL | NULL | 16 | 6.25 | Using where |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
-- 使用的查询方式是全部遍历
mysql> explain select *from tb_user_s1 where profession='软件工程' and status='3';
+----+-------------+------------+------------+------+-------------------------+-------------------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+-------------------------+-------------------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | tb_user_s1 | NULL | ref | idx_user_pro_age_status | idx_user_pro_age_status | 63 | const | 6 | 10.00 | Using index condition |
+----+-------------+------------+------------+------+-------------------------+-------------------------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
-- 这里最左边列之后的索引就全部失效了
范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效
-- 这里age后的status索引会失效
-- 使用>=不会失效,只有使用>或<时才会失效
mysql> explain select *from tb_user_s1 where profession='软件工程' and age>20 and status='3';
+----+-------------+------------+------------+-------+-------------------------+-------------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+-------------------------+-------------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | tb_user_s1 | NULL | range | idx_user_pro_age_status | idx_user_pro_age_status | 68 | NULL | 6 | 10.00 | Using index condition |
+----+-------------+------------+------------+-------+-------------------------+-------------------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
索引失效的情况
表数据查询在使用索引时,每个字段的索引是单独生效的
- 索引列运算
不要在索引列上进行运算操作,否则索引将会失效(例如在查询某一列数据时使用函数运算等)
select *from tb_user_s1 where substring(phone,10,2);
-- 这里就使用了substring进行函数运算,
-- 在查询时就没有使用索引,而是全表扫描,性能降低
- 字符串不加引号
在查询字符串类型的数据时,sql语句where后的字符串在查询时没有加单引号,那么索引就会失效,在查询时就没有使用索引,而是全表扫描,性能降低。
;-- 字符串加了单引号
mysql> explain select *from tb_user_s1 where phone='12385678910'
-- type是ref,代表使用索引查询
+----+-------------+------------+------------+------+----------------+----------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+----------------+----------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | tb_user_s1 | NULL | ref | idx_user_phone | idx_user_phone | 45 | const | 1 | 100.00 | Using index condition |
+----+-------------+------------+------------+------+----------------+----------------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
-- 字符串没加单引号
mysql> explain select *from tb_user_s1 where phone=12385678910;
-- type是all,代表没有使用索引查询
+----+-------------+------------+------------+------+----------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+----------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | tb_user_s1 | NULL | ALL | idx_user_phone | NULL | NULL | NULL | 16 | 10.00 | Using where |
+----+-------------+------------+------------+------+----------------+------+---------+------+------+----------+-------------+
1 row in set, 3 warnings (0.00 sec)
- 模糊查询
使用like进行模糊查询时,如果仅仅是尾部模糊查询,索引不会失效,如果是头部模糊匹配,索引就会失效
mysql> ^C
-- 使用尾部模糊查询,索引生效
mysql> explain select *from tb_user_s1 where profession like '软件%';
+----+-------------+------------+------------+-------+-------------------------+-------------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+-------------------------+-------------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | tb_user_s1 | NULL | range | idx_user_pro_age_status | idx_user_pro_age_status | 63 | NULL | 6 | 100.00 | Using index condition |
+----+-------------+------------+------------+-------+-------------------------+-------------------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.02 sec)
-- 使用头部模糊查询,索引失效
mysql> explain select *from tb_user_s1 where profession like '%工程';
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | tb_user_s1 | NULL | ALL | NULL | NULL | NULL | NULL | 16 | 11.11 | Using where |
+----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
- or连接的条件
使用or进行条件的组装时,如果or的两侧一侧有索引,一侧没有索引,那么涉及的索引都会失效,只有两侧都有索引的时候,索引才会生效
注意:复合索引使用时如果没有使用最左侧的索引,那么索引就不会生效
-- 这里phone是普通索引,而age是联合索引,由于没有联合索引的最左列字段,所以age
-- 可以看作没有索引,此时在进行查询时,索引都没有生效
mysql> explain select *from tb_user_s1 where phone='12345698910' or age=22;
+----+-------------+------------+------------+------+----------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+----------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | tb_user_s1 | NULL | ALL | idx_user_phone | NULL | NULL | NULL | 16 | 16.92 | Using where |
+----+-------------+------------+------------+------+----------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
-- phone和name都是普通索引,or的两边都有索引,所以索引查询生效
mysql> explain select *from tb_user_s1 where phone='12345698910' or name='刀妹';
+----+-------------+------------+------------+-------------+------------------------------+------------------------------+---------+------+------+----------+--------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------------+------------------------------+------------------------------+---------+------+------+----------+--------------------------------------------------------+
| 1 | SIMPLE | tb_user_s1 | NULL | index_merge | idx_user_name,idx_user_phone | idx_user_phone,idx_user_name | 45,43 | NULL | 2 | 100.00 | Using union(idx_user_phone,idx_user_name); Using where |
+----+-------------+------------+------------+-------------+------------------------------+------------------------------+---------+------+------+----------+--------------------------------------------------------+
1 row in set, 1 warning (0.01 sec)
- 数据分布影响
如果MySQL评估使用索引查询数据比使用全表扫描更慢,则就不会使用索引
例如:在查询某些数据时,这个表中的大多数数据都符合要求,那么就不会使用索引,而是用全表扫描,因为MySQL认为全表扫描比索引更快
-- 这里is null就会使用索引,因为mysql认为表中的数据大多数都不是null,所以使用索引
mysql> explain select *from tb_user_s1 where profession is null;
+----+-------------+------------+------------+------+-------------------------+-------------------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+-------------------------+-------------------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | tb_user_s1 | NULL | ref | idx_user_pro_age_status | idx_user_pro_age_status | 63 | const | 1 | 100.00 | Using index condition |
+----+-------------+------------+------------+------+-------------------------+-------------------------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.01 sec)
-- 这里就不会使用索引,还是因为mysql认为表中的数据大多数都不是null,所以不走索引
mysql> explain select *from tb_user_s1 where profession is not null;
+----+-------------+------------+------------+------+-------------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+-------------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | tb_user_s1 | NULL | ALL | idx_user_pro_age_status | NULL | NULL | NULL | 16 | 100.00 | Using where |
+----+-------------+------------+------------+------+-------------------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
SQL提示
不用SQL提示时,当一个字段有多个索引,那么,MySQL会自动的选择一个索引使用,例如,profession有一个普通索引和联合索引,那么,在查询时MySQL会自动选择使用联合索引去查询。
而使用SQL提示就可以使SQL按照指定的索引去查询
SQL提示:是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的操作来达到优化操作的目的
常用的SQL提示:
- use index:(告诉SQL使用指定索引,给MySQL一个建议,MySQL也有可能不使用指定索引)
eplain select *from tb_user_s1 use index(指定索引名) where profession='软件工程';
- ignore index(告诉SQL不使用指定索引)
eplain select *from tb_user_s1 ignore index(指定索引名) where profession='软件工程';
- force index:(告诉SQL必须使用指定索引)
eplain select *from tb_user_s1 force index(指定索引名) where profession='软件工程';
覆盖索引
概念:在查询中尽量使用覆盖索引(查询时使用了一个索引,并且需要返回的列在该索引中都已经找到了相应的字段值),避免使用select*
上面的概念有点难懂,简单理解就是,在select之后的字段尽量都有索引,查询时就不会回表查询了,
覆盖查询在explain中只看Extra

mysql> explain select *from tb_user_s1 where profession='软件工程' and age=22 and status='3' ;
+-----------------------+
| Extra |
+-----------------------+
| Using index condition |
+-----------------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select id,profession,age,status from tb_user_s1 where profession='软件工程' and age=22 and status='3' ;
+--------------------------+
| Extra |
+--------------------------+
| Using where; Using index |
+--------------------------+
1 row in set, 1 warning (0.00 sec)
可以看到,使用select*查询时出现的是Using index condition,证明出现的回表查询,效率不是最高的,而查询时,select后是联合索引对应的字段时,出现的是 Using where; Using index证明是直接通过索引查询,效率较高
覆盖索引,不需要回表,查询两个字段,查询后直接就把数据返回,没有再进去表中查询,一次索引扫描就完成了

没有覆盖索引,要先扫描辅助索引(二级索引),获取id值后还要再去扫描聚集索引才能获取想要的数据,索引扫描了两次,效率自然就低了,回表查询
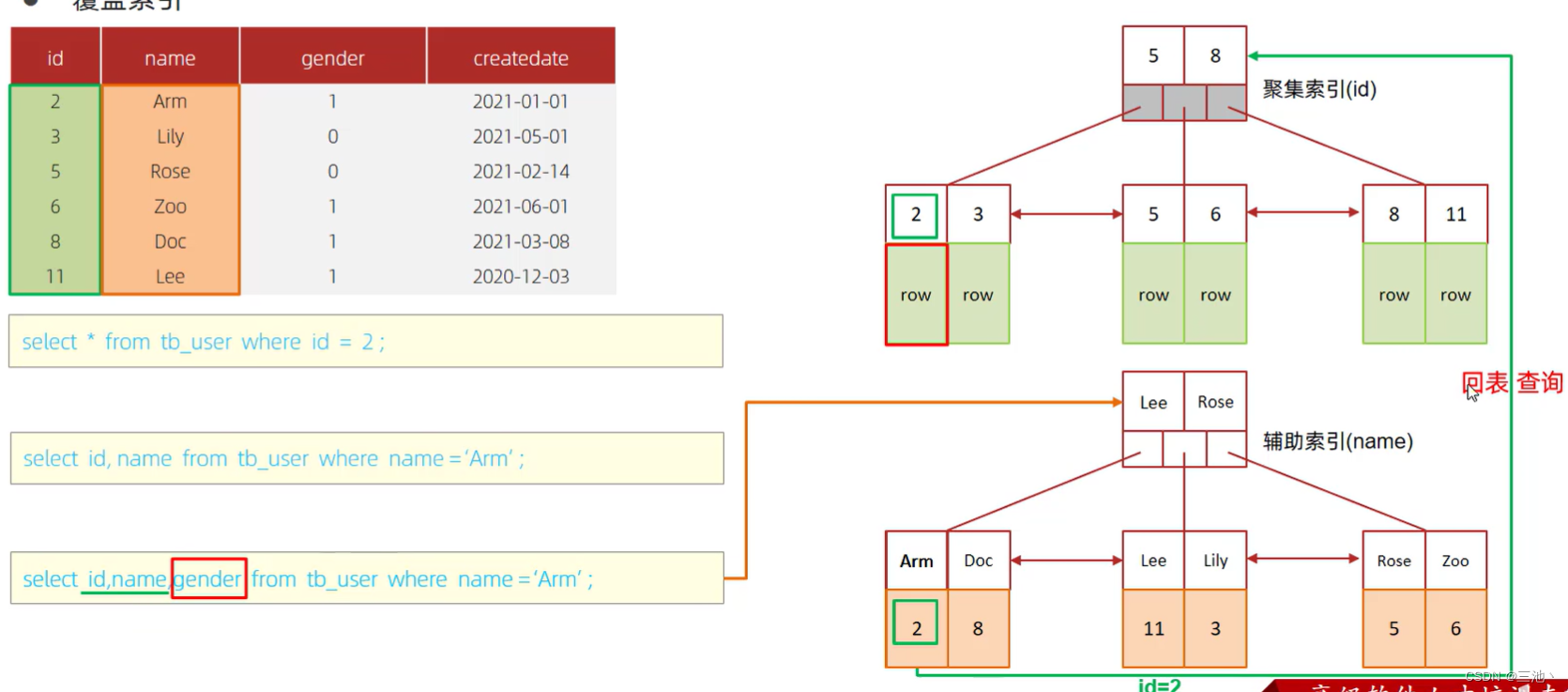
使用select就会很容易回表查询,所以要避免使用select
前缀索引
当字段类型为字符串(varchar,text)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,会浪费大量的磁盘IO,影响查询效率,此时可以只将字符串的一部分前缀建立索引,这样就可以大大节约索引空间,从而提高索引效率
- 创建前缀索引
-- idx_xxxx:索引名
-- table_name:表名
-- column(n)字段名,n代表提取前几个字符作为前缀索引,例如,n=5,
-- 那么就会使用字符串的前5个字符构建索引
create index idx_xxxx on table_name(column(n));
-
前缀的长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表记录总数的比值,索引选择性越高则查询效率越高,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的 -
求选择性的方法
select count(distinct email)/count(*) from tb_user;
-- 这里就是用substring来判断选择度,下面的代码就是截取前5个字符,来判断一个
-- 字段前5个字符的选择度
-- 用这段代码就可以获取选择性,进而判断选择前几个字符作为前缀来创建索引
select count(distinct substring(email,1,5))/count(*) from tb_user;
- 前缀索引的结构
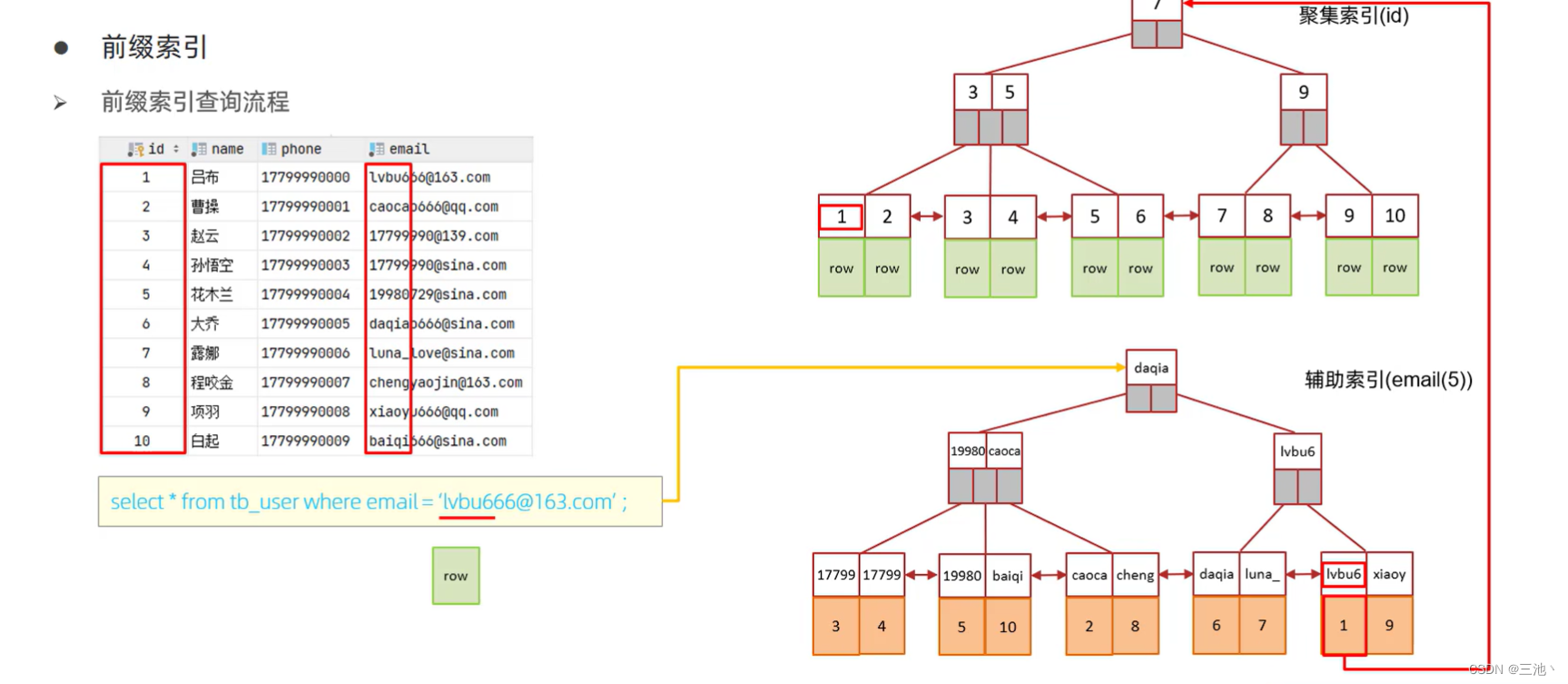
这里的辅助索引就是前缀索引
单列索引与联合索引
单列索引:一个索引只包含单个列
联合索引:一个索引包含多个列
一次查询使用多个单列索引时,只会使用一个单列索引,另外的单列索引不会使用
mysql> explain select name,phone from tb_user_s1 where phone='12345378910' and name='烬';
+----+-------------+------------+------------+------+------------------------------+---------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+------------------------------+---------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | tb_user_s1 | NULL | ref | idx_user_name,idx_user_phone | idx_user_name | 43 | const | 1 | 6.25 | Using where |
+----+-------------+------------+------------+------+------------------------------+---------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
在业务场景中,如果存在多个查询条件,针对多个字段建立索引时,建议使用联合索引,而不是单列索引
多条件联合查询时,MySQL优化器会评估哪个字段的索引效率更高,会选择该索引完成本次查询
- 联合索引的查询流程
phone和name有联合索引
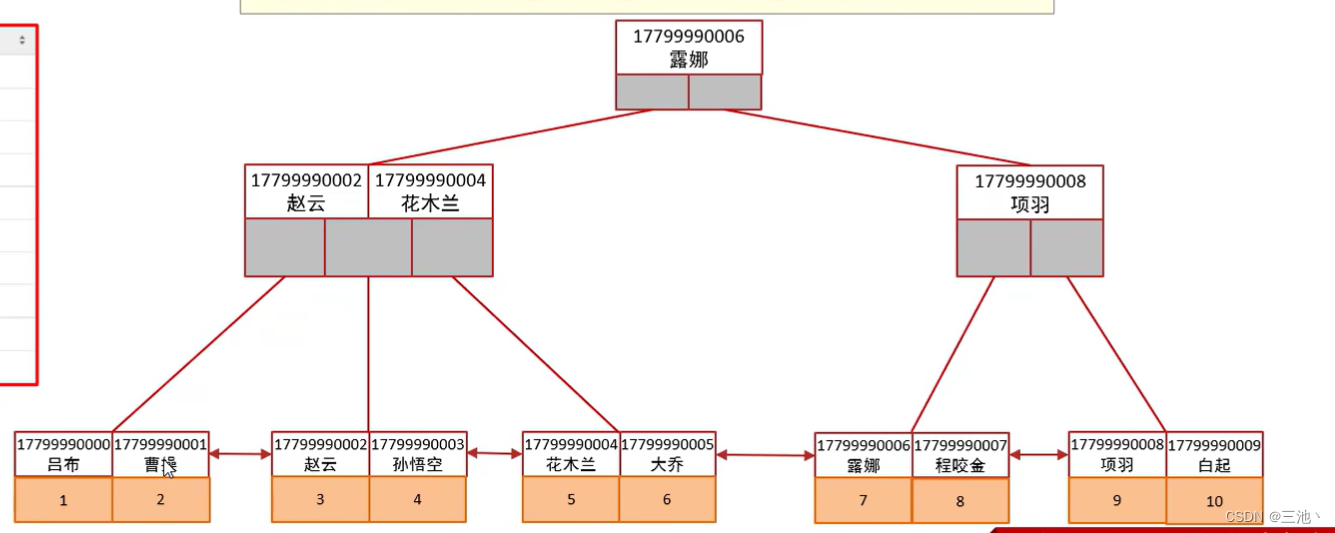
尽量使用联合索引,避免使用单列索引,创建联合索引时注意创建的字段顺序
索引的设计原则
1.针对数据量较大,且查询比较频繁的表建立索引
2.针对于常作为查询条件(where),排序(order by),分组(group by)操作的字段建立索引
3.尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高
4.如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引
5.尽量使用联合索引,减少单列索引的使用,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
6.要控制索引的数量,索引并不是越多越好,索引越多,维护索引的代价也就越大,会影响增删改的效率
7.如果索引列不能存储NULL值,在创建表时用NOT NULL约束它,当优化器知道每列是否包含NULL值时,它可以更好的确定哪个索引最有效的用于查询
小结