文章目录
- 一、NMS详解
- 二、NMS具体步骤与实现
- 1.步骤
- 2、代码(pytorch版本)
一、NMS详解
NMS即非极大值抑制,常被用于目标检测等,即只保留检测同一物体置信度最大的框。
具体作用可以看图:
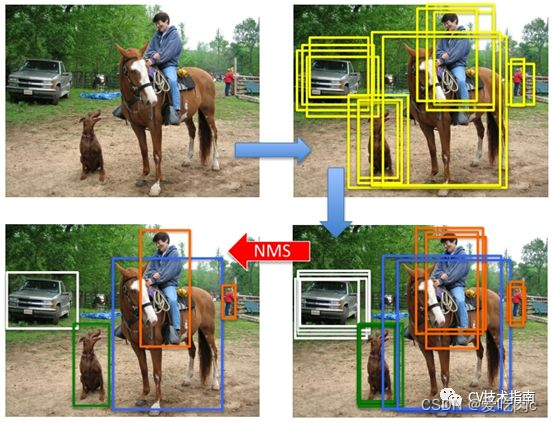
可以看出,未经过nms的图片,有很多指向同一物体的框。
二、NMS具体步骤与实现
1.步骤
这里是转发bubbliiiing博主的!
本博文实现的是多分类的非极大抑制:
输入shape为[ batch_size, all_anchors, 5+num_classes ]
第一个维度是图片的数量。
第二个维度是所有的预测框。
第三个维度是所有的预测框的预测结果。
这里的预测结果是(x,y,w,h,包含种类的概率,所有种类的概率),在这里我使用的种类为2分类。
非极大抑制的执行过程如下所示:
1、对所有图片进行循环。(循环1)
2、找出该图片中得分大于门限函数的框。在进行重合框筛选前就进行得分的筛选可以大幅度减少框的数量。
3、判断第2步中获得的框的种类与得分。即找出该图片中不同框所对应的最大种类的概率以及种类。取出预测结果中框的位置与之进行堆叠。此时最后一维度里面的内容由5+num_classes变成了4+1+2,四个参数代表框的位置,一个参数代表预测框是否包含物体,两个参数分别代表种类的置信度与种类。
4、对种类进行循环,(循环2)非极大抑制的作用是筛选出一定区域内属于同一种类得分最大的框,对种类进行循环可以帮助我们对每一个类分别进行非极大抑制。
5、根据得分对该种类进行从大到小排序。
6、每次取出得分最大的框(循环3),计算其与其它所有预测框的重合程度,重合程度过大的则剔除。
2、代码(pytorch版本)
def bbox_iou(self, box1, box2, x1y1x2y2=True):
"""
计算IOU
"""
if not x1y1x2y2:
b1_x1, b1_x2 = box1[:, 0] - box1[:, 2] / 2, box1[:, 0] + box1[:, 2] / 2
b1_y1, b1_y2 = box1[:, 1] - box1[:, 3] / 2, box1[:, 1] + box1[:, 3] / 2
b2_x1, b2_x2 = box2[:, 0] - box2[:, 2] / 2, box2[:, 0] + box2[:, 2] / 2
b2_y1, b2_y2 = box2[:, 1] - box2[:, 3] / 2, box2[:, 1] + box2[:, 3] / 2
else:
b1_x1, b1_y1, b1_x2, b1_y2 = box1[:, 0], box1[:, 1], box1[:, 2], box1[:, 3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[:, 0], box2[:, 1], box2[:, 2], box2[:, 3]
inter_rect_x1 = torch.max(b1_x1, b2_x1)
inter_rect_y1 = torch.max(b1_y1, b2_y1)
inter_rect_x2 = torch.min(b1_x2, b2_x2)
inter_rect_y2 = torch.min(b1_y2, b2_y2)
inter_area = torch.clamp(inter_rect_x2 - inter_rect_x1, min=0) * \
torch.clamp(inter_rect_y2 - inter_rect_y1, min=0)
b1_area = (b1_x2 - b1_x1) * (b1_y2 - b1_y1)
b2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1)
iou = inter_area / torch.clamp(b1_area + b2_area - inter_area, min = 1e-6)
return iou
def non_max_suppression(self, prediction, num_classes, input_shape, image_shape, letterbox_image, conf_thres=0.5, nms_thres=0.4):
#----------------------------------------------------------#
# 将预测结果的格式转换成左上角右下角的格式。
# prediction [batch_size, num_anchors, 85]
#----------------------------------------------------------#
box_corner = prediction.new(prediction.shape)
box_corner[:, :, 0] = prediction[:, :, 0] - prediction[:, :, 2] / 2
box_corner[:, :, 1] = prediction[:, :, 1] - prediction[:, :, 3] / 2
box_corner[:, :, 2] = prediction[:, :, 0] + prediction[:, :, 2] / 2
box_corner[:, :, 3] = prediction[:, :, 1] + prediction[:, :, 3] / 2
prediction[:, :, :4] = box_corner[:, :, :4]
output = [None for _ in range(len(prediction))]
for i, image_pred in enumerate(prediction):
#----------------------------------------------------------#
# 对种类预测部分取max。
# class_conf [num_anchors, 1] 种类置信度
# class_pred [num_anchors, 1] 种类
#----------------------------------------------------------#
class_conf, class_pred = torch.max(image_pred[:, 5:5 + num_classes], 1, keepdim=True)
#----------------------------------------------------------#
# 利用置信度进行第一轮筛选
#----------------------------------------------------------#
conf_mask = (image_pred[:, 4] * class_conf[:, 0] >= conf_thres).squeeze()
#----------------------------------------------------------#
# 根据置信度进行预测结果的筛选
#----------------------------------------------------------#
image_pred = image_pred[conf_mask]
class_conf = class_conf[conf_mask]
class_pred = class_pred[conf_mask]
if not image_pred.size(0):
continue
#-------------------------------------------------------------------------#
# detections [num_anchors, 7]
# 7的内容为:x1, y1, x2, y2, obj_conf, class_conf, class_pred
#-------------------------------------------------------------------------#
detections = torch.cat((image_pred[:, :5], class_conf.float(), class_pred.float()), 1)
#------------------------------------------#
# 获得预测结果中包含的所有种类
#------------------------------------------#
unique_labels = detections[:, -1].cpu().unique()
if prediction.is_cuda:
unique_labels = unique_labels.cuda()
detections = detections.cuda()
for c in unique_labels:
#------------------------------------------#
# 获得某一类得分筛选后全部的预测结果
#------------------------------------------#
detections_class = detections[detections[:, -1] == c]
# #------------------------------------------#
# # 使用官方自带的非极大抑制会速度更快一些!
# #------------------------------------------#
# keep = nms(
# detections_class[:, :4],
# detections_class[:, 4] * detections_class[:, 5],
# nms_thres
# )
# max_detections = detections_class[keep]
# 按照存在物体的置信度排序
_, conf_sort_index = torch.sort(detections_class[:, 4]*detections_class[:, 5], descending=True)
detections_class = detections_class[conf_sort_index]
# 进行非极大抑制
max_detections = []
while detections_class.size(0):
# 取出这一类置信度最高的,一步一步往下判断,判断重合程度是否大于nms_thres,如果是则去除掉
max_detections.append(detections_class[0].unsqueeze(0))
if len(detections_class) == 1:
break
ious = self.bbox_iou(max_detections[-1], detections_class[1:])
detections_class = detections_class[1:][ious < nms_thres]
# 堆叠
max_detections = torch.cat(max_detections).data
# Add max detections to outputs
output[i] = max_detections if output[i] is None else torch.cat((output[i], max_detections))
if output[i] is not None:
output[i] = output[i].cpu().numpy()
box_xy, box_wh = (output[i][:, 0:2] + output[i][:, 2:4])/2, output[i][:, 2:4] - output[i][:, 0:2]
output[i][:, :4] = self.yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape, letterbox_image)
return output