文章目录
- 一、环境
- 二、思路
- `第一步`:输入问句
- `第二步`:针对问句进行分析,包括意图识别和实体识别
- `第三步`:问句转化
- `第四步`:问题回答的模板设计
- 三、代码解读
- 1. 项目结构
- 2. 数据说明
- 3. 主文件`kbqa_test.py`解读
- 4. entity_extractor.py 实体抓取代码
- 主函数
- 1. `step-1 好来到entity_extractor.py主函数第一步:模式匹配,也即为实体识别,这里是优化点`
- 2. `step-2好来到entity_extractor.py主函数第二步,没有匹配实体则进行相似查找`
- 3. `step-3 好来到entity_extractor.py主函数第三步:意图识别`
- 4. `step-4 好来到entity_extractor.py主函数第四步:设计问题类别`
- 5. `search_answer.py` 问句语言转换,以及查询结果
- (1). `step-1 好来到 question_parser(self, data)函数,根据实体和意图进行问句转换`
- (2). `step-2 好来到 transfor_to_sql(self, label, entities, intent)函数,进行问句转换`
- (3). `step-3 好来到 answer_template(self, intent, answers)函数,回答模板的设计`
- 四、源码
- 五、参考文献
最近练习做对话系统,先拿一个简易项目进行练手,该项目虽然简易但是,涉及分类,图谱构建等技术点对于学习逻辑来说不错的入手习题。
一、环境
Ubuntu 16.0.4
(windows也行)
python 3.6.8
neo4j 完全基于这个版本
二、思路
架构图懒的画了,简单描述一下。
第一步:输入问句
第二步:针对问句进行分析,包括意图识别和实体识别
主要流程:
- 进行实体抽取,与neo4j数据匹配是否存在,存在则返回实体
- 若是不存在与neo4j数据进行相似度计算,返回相似度较高的实体
- 进行意图识别,这里基于文本分类技术。将问题类别作为标签
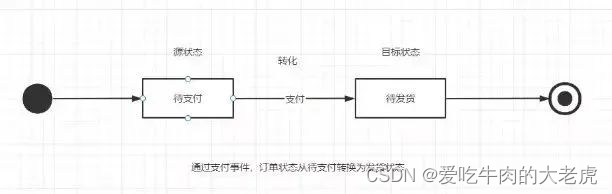
第三步:问句转化
针对第二步中的实体和意图,进行问句转化,
即: 转化为 neo4j 查询语法
第四步:问题回答的模板设计
三、代码解读
1. 项目结构
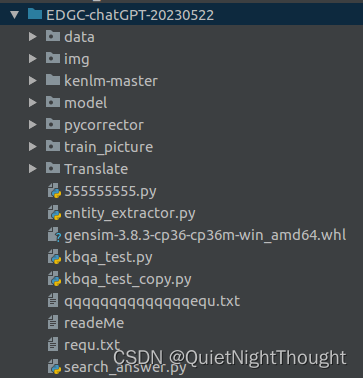
- 文件名字通俗易通
- pycorrector 是一个纠错项目
- kenlm-master 是一纠错的一个重要依赖项
- Translate 是一个中英翻译的小项目
主文件:kbqa_test.py 主文件
其他的看文件名字
2. 数据说明

每个txt文件为一个实体类别,这里可以根据我们的实际数据进行替换,
vocab.txt 文件是所有实体的一个集合,主要是用于后面我们分词时候使用
3. 主文件kbqa_test.py解读
启动该文件即可:
这里主要是对思路中的 第二步和第三步进行实例操作,进而实现问句分析和问题转换,图谱查询。
from entity_extractor import EntityExtractor #针对问句的 分析,包括实体抽取和意图识别
from search_answer import AnswerSearching # 问题转化,与图谱查询
class KBQA:
def __init__(self):
self.extractor = EntityExtractor()
self.searcher = AnswerSearching()
def qa_main(self, input_str):
answer = "对不起,您的问题我不知道"
entities = self.extractor.extractor(input_str) #抓取实体
if not entities:
return answer
sqls = self.searcher.question_parser(entities)
# 根据实体和意图构造 图谱查询语句
final_answer = self.searcher.searching(sqls)
#查询 返回结果
if not final_answer:
return answer
else:
return '\n'.join(final_answer)
4. entity_extractor.py 实体抓取代码
主函数
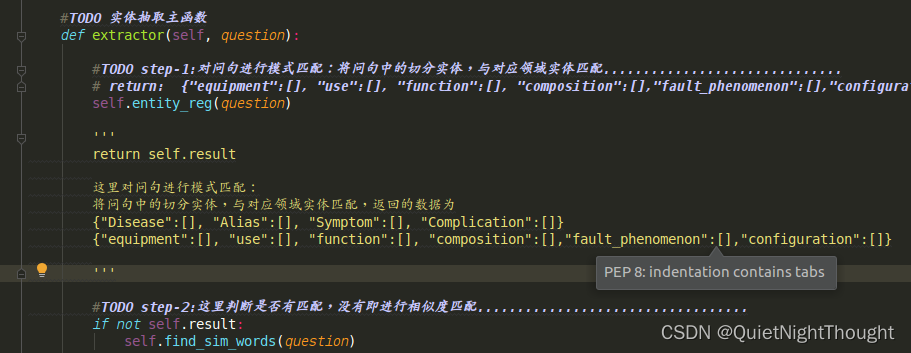 此函数为
此函数为主函数,咱们跟着主函数逐行代码一步一步走:
主函数的目的是进行实体识别和意图识别.
1. step-1 好来到entity_extractor.py主函数第一步:模式匹配,也即为实体识别,这里是优化点
TODO step-1:对问句进行模式匹配:将问句中的切分实体,与对应领域实体匹配…
return: {“equipment”:[], “use”:[], “function”:[], “composition”:[],“fault_phenomenon”:[],“configuration”:[]}
self.entity_reg(question) #此代码进行实体识别
'''
这里的实体识别,并非使用的是 深度技术,主要是利用进行模式匹配
return self.result
这里对问句进行模式匹配:
将问句中的切分实体,与对应领域实体匹配,返回的数据为
return self.result :{"equipment":[], "use":[], "function":[], "composition":[],"fault_phenomenon":[],"configuration":[]}
返回的结果,会用于后面的 neo4j查询问句转化
'''
2. step-2好来到entity_extractor.py主函数第二步,没有匹配实体则进行相似查找
这里判断是否有匹配,没有即进行相似度匹配…
 这一步重点看
这一步重点看 self.find_sim_words(question)函数
来看下该函数源码:
"""
当全匹配失败时,就采用相似度计算来找相似的词
:param question:
:return:
"""
jieba.load_userdict(self.vocab_path) #加载分词字典
self.model = KeyedVectors.load_word2vec_format(self.word2vec_path, binary=False)
sentence = re.sub("[{}]", re.escape(string.punctuation), question)
sentence = re.sub("[,。‘’;:?、!【】]", " ", sentence)
sentence = sentence.strip()
#TODO step-1:构建分词数据列表..................................................................
words = [w.strip() for w in jieba.cut(sentence) if w.strip() not in self.stopwords and len(w.strip()) >= 2]
#TODO step-2:将分词列表中的数据与各个实体库进行相似度计算..........................................
alist = [] #all 相似度
for word in words:
temp = [self.equipment_entities, self.use_entities, self.function_entities,
self.composition_entities,self.fault_phenomenon_entities,self.configuration_entities]
#这里temp对应的是 这几个实体的加载列表 temp: [[], [], [], []]
for i in range(len(temp)):
flag = ''
if i == 0:
flag = "equipment"
elif i == 1:
flag = "use"
elif i == 2:
flag = "function"
elif i == 3:
flag = "composition"
elif i == 4:
flag = "fault_phenomenon"
else:
flag = "configuration"
scores = self.simCal(word, temp[i], flag) #将分词列表中的数据与各个实体库进行相似度计算
alist.extend(scores)
temp1 = sorted(alist, key=lambda k: k[1], reverse=True)
if temp1:
self.result[temp1[0][2]] = [temp1[0][0]]
这便是相似词的查找步骤:
主要的计算是基于 scores = self.simCal(word, temp[i], flag)函数:
来看下该函数的逐行代码解读:
"""
计算词语和字典中的词的相似度
相同字符的个数/min(|A|,|B|) + 余弦相似度
:param word: str
:param entities:List
:return:
"""
a = len(word)
scores = []
for entity in entities:
sim_num = 0 #问句切分实体与 对比实体的相似字符数
b = len(entity)
c = len(set(entity+word))
temp = []
for w in word:
if w in entity:
sim_num += 1
if sim_num != 0:
score1 = sim_num / c # overlap score 相似字符数目占两者的总的字符数比例
temp.append(score1)
try:
score2 = self.model.similarity(word, entity) # 余弦相似度分数
temp.append(score2)
except:
pass
score3 = 1 - self.editDistanceDP(word, entity) / (a + b) # 编辑距离分数
if score3: #判断
temp.append(score3)
score = sum(temp) / len(temp) #计算的是三者分数的平均值
if score >= 0.7: #平均值大于0.7 即算为匹配到
scores.append((entity, score, flag))
scores.sort(key=lambda k: k[1], reverse=True)
#将结果中的信息基于 score 分数来进行降序排列
'''
返回的是一个基于分数排序的列表信息,
'''
return scores
3. step-3 好来到entity_extractor.py主函数第三步:意图识别
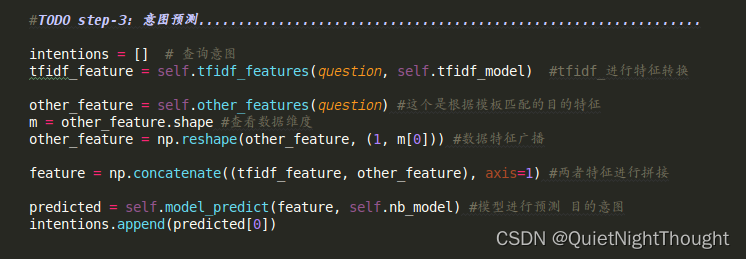 这一步没啥说的:主要就是将训练文本分类的
这一步没啥说的:主要就是将训练文本分类的 保存模型,使用模型的代码,面向对象实现即可。
这里的意图识别,利用的是 贝叶斯,当然这里 可以是任何多分类模型替代,前提是 不影响推理速度。
特别说明:预测的特征内容:
feature = np.concatenate((tfidf_feature, other_feature), axis=1) #两者特征进行拼接
这里是一个拼接特征,tfidf_feature这个没啥说的就是问句,进行词袋转化。优化点:就是这个词典模型,使用本领域数据操作,尽可能丰富
other_feature:这个提一下。
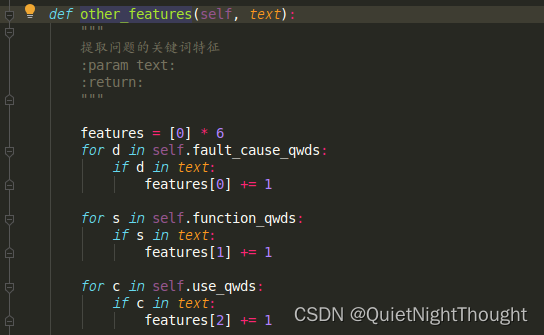
这里使用了辅助操作,来看下self.fault_cause_qwds
 看到了这里,进行辅助说明,即将各个
看到了这里,进行辅助说明,即将各个意图(这个意图是根据你的需要来设计的,包括后面的问题模板设计都是根据这个来的),尽可能丰富。
4. step-4 好来到entity_extractor.py主函数第四步:设计问题类别
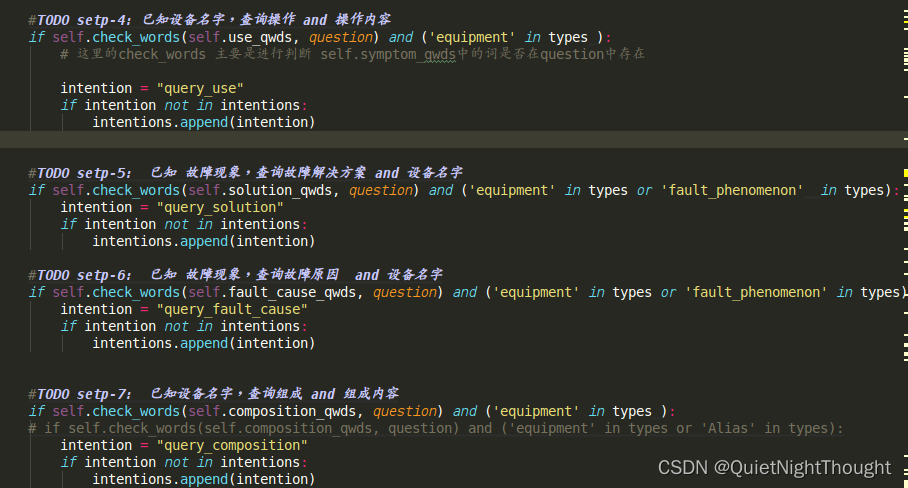
这里的,具体问题就要根据我们的实际需要来进行设计了
5. search_answer.py 问句语言转换,以及查询结果
(1). step-1 好来到 question_parser(self, data)函数,根据实体和意图进行问句转换
def question_parser(self, data):
"""
主要是根据不同的实体和意图构造cypher查询语句
data: {"equipment":[], "use":[], "function":[], "composition":[],"fault_phenomenon":[],"configuration":[],"intentions":[]}
:return:
data来源: 看我们的项目主函数,先进行实体抓取,之后根据抓取文件的返回结果。
"""
sqls = []
if data:
for intent in data["intentions"]:
sql_ = {}
sql_["intention"] = intent
sql = []
if data.get("equipment"):
sql = self.transfor_to_sql("equipment", data["equipment"], intent)
elif data.get("use"):
sql = self.transfor_to_sql("use", data["use"], intent)
elif data.get("function"):
sql = self.transfor_to_sql("function", data["function"], intent)
elif data.get("composition"):
sql = self.transfor_to_sql("composition", data["composition"], intent)
elif data.get("fault_phenomenon"):
sql = self.transfor_to_sql("fault_phenomenon", data["fault_phenomenon"], intent)
elif data.get("configuration"):
sql = self.transfor_to_sql("configuration", data["configuration"], intent)
if sql:
sql_['sql'] = sql
sqls.append(sql_)
return sqls
(2). step-2 好来到 transfor_to_sql(self, label, entities, intent)函数,进行问句转换
def transfor_to_sql(self, label, entities, intent):
'''
将问题转变为cypher查询语句
:param label:实体标签
:param entities:实体列表
:param intent:查询意图
:return:cypher查询语句
查询故障原因 query_fault_cause
查询功能 query_function
查询操作 query_use
查询组成 query_composition
查询解决方案 query_solution
查询配置 query_configuration
'''
if not entities:
return []
sql = []
这里是用一个例子说明,不同例如殊途同归:
 这里涉及的就是 查询语句了。
这里涉及的就是 查询语句了。
(3). step-3 好来到 answer_template(self, intent, answers)函数,回答模板的设计
def answer_template(self, intent, answers):
"""
根据不同意图,返回不同模板的答案
:param intent: 查询意图
:param answers: 知识图谱查询结果
:return: str
查询故障原因 query_fault_cause
查询功能 query_function
查询操作 query_use
查询组成 query_composition
查询解决方案 query_solution
查询配置 query_configuration
"""
以一个例子说明:
final_answer = ""
if not answers:
return ""
#TODO 查询操作...........................................................
if intent == "query_use":
equipment_use_dic = {}
for data in answers:
d = data['d.name'] #获取设备实体名字
s = data['s.name'] #获取我们的目标内容
if d not in equipment_use_dic:
equipment_use_dic[d] = [s]
else:
equipment_use_dic[d].append(s)
i = 0
for k, v in equipment_use_dic.items():
if i >= 10:
break
final_answer += "设备{0} 的操作有:{1}\n".format(k, ','.join(sorted(list(set(v)))))
i += 1
'''
其他的就可以根据这些如法炮制
'''
四、源码
项目地址
五、参考文献
[1] https://github.com/zhihao-chen/QASystemOnMedicalGraph
[2] https://github.com/zhihao-chen/QASystemOnMedicalKG