- 线程池的理解
- 协程的理解
- 高并发服务器的考量
- 内存管理
- 函数调用与栈
- 影响多线程性能的缓存问题
线程池的理解
重复创建和销毁线程会存在开销,线程过多会消耗大量内存,较多线程之间的切换也存在开销
线程池用来复用线程,控制线程数量
线程池中线程数量的计算取决于程序的类型(cpu密集/io密集),按照以下公式计算,WT为io等待时间,CT为cpu计算时间
N × ( 1 + W T C T ) N\times \left ( 1+\frac{WT}{CT} \right ) N×(1+CTWT)
协程的理解
协程会在被按照你听运行时保存运行状态,让然后从保存的状态中回复并继续运行
os会定期产生定时器中断,对线程进行调度(暂停执行),用户不需要决定让出cpu的时机。但是用户态并不存在这种机制,因而协程需要手动控制线程,因而被称为用户态线程(os无法感知)。协程的调度权在用户手中
从这种角度来看,函数只是协程的特例(没有中断点)。协程的栈帧存储在堆区。
理论上内存足够,可以启动无数协程,协程的切换,调度发生在用户态,不需要os介入,上下文环境的保存和回复更加轻量,因此效率较高。
内核按照线程分配cpu的时间片,用户决定在分配的时间片内执行哪些协程,本质上就是对cpu时间片的二次分配
协程最重要的作用:以同步的方式进行异步编程
高并发服务器的考量
实现方式有
- 多进程
- 多线程
- 事件驱动
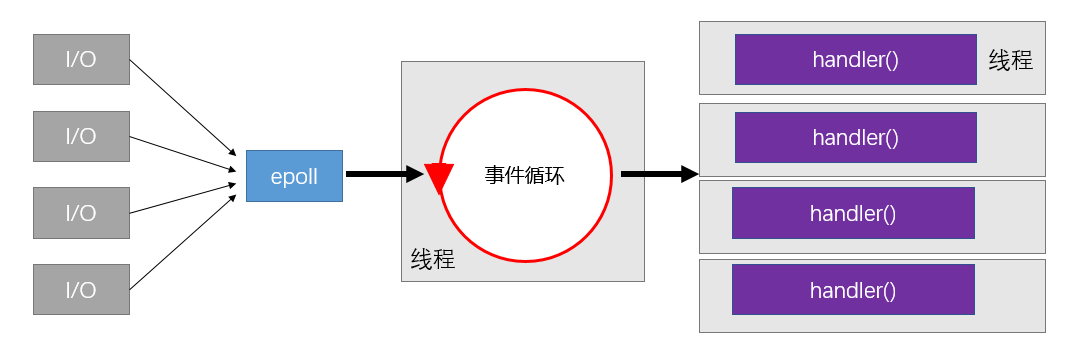
前两者存在性能问题,服务器使用事件驱动的逻辑有2点
-
事件的来源问题?Linux中的epoll轮询事件并通知
-
处理事件的函数和事件循环本身是否需要在同一线程?取决于处理函数的复杂度
-
不涉及IO,逻辑简单耗时少:单线程

-
否则放在独立线程中,即reactor模式
-
如果事件处理函数需要调用阻塞IO,则只能使用reactor模式(避免事件循环本身被阻塞)
在微服务场景下,服务器需要请求下游来获取信息(rpc调用),因此需要考虑rpc方法本身是否是阻塞的。如果将rpc方法实现为异步回调,则可能会由于下游请求的串联导致回调地狱。
此时可以通过协程,用同步的写法实现异步

内存管理
linux有malloc进行内存的分配,如果从头实现一个内存分配器,则需要考虑内存的管理的方式
空闲内存块的管理,使用链表(每个节点包括块大小,是否空间,实际的内存空间)
内存分配的策略(遍历链表找到合适的块)
-
first hit
-
next hit(从上一次的找到的地方开始查找)
-
best hit()
-
…
用户态使用malloc申请内存(虚拟内存),找不到空闲块则通过brk/mmap(内核态)扩大堆内存,返回后申请到内存并读写(用户态),触发缺页中断,虚拟内存和物理内存建立映射关系。
分配器包括,内核级分配器——slab 分配器和SLUB——以及用户级分配器——glibc,jemalloc和TCMalloc
glibc内存管理那些事儿

频繁通过malloc系统调用存在性能损耗,考虑内存池(在应用程序而非标准库中,高性能标配)
和内存相关的常见问题
- 返回局部变量指针
- 指针的计算(加减)
- 读取未初始化的内存
- 引用已经释放的内存
- 数组越界
- 栈溢出
- 内存泄漏
函数调用与栈
上下文环境(context)的保存和恢复是为了以下场景,保证cpu的状态和参数能够恢复
- 函数调用,cpu从函数A跳转到函数B
- 系统调用,cpu从用户态切换到内核态
- 线程切换
- 中断处理
只要是函数就需要运行时栈,每个用户台线程都有一个内核态栈用于执行系统调用。
中断处理函数的栈有两种实现
- 使用内核栈作为运行时栈
- ISR,中断处理函数栈,每个cpu都有一个
定时器中断处理函数会判断线程分配的时间片是否用完,如果用完则会发生线程切换
- 切换进程地址空间,从进程控制块(PCB)获取cpu的上下文信息
- 切换线程
影响多线程性能的缓存问题
- CPU 缓存一致性与 MESI 协议
- 缓存一致性协议硬核讲解
cache乒乓问题,缓存一致性导致多线程的性能弱于单线程
- 由于使用2核心,c1和c2之间由于需要维护缓存一致性,需要额外开销
- 尽量避免多线程之间共享数据
// function1
atomic<int> a
void threadf(){
for(int i = 0;i<50000000;i++)
++a;
}
void run(){
thread t1 = thread(threadf)
thread t2 = thread(threadf)
t1.join()
t2.join()
}
// function2
atomic<int> a
void run(){
for(int i = 0;i<100000000;i++)
++a;
}
伪共享问题,由于缓存的局部性原理导致false sharing
- global_data.a和global_data.a并非同一变量,因此线程之间并没有共享数据
- 但是两者可能会由于cache line(按行加载缓存),同时读到缓存中,导致多核之间仍旧存在乒乓问题
- 改良措施为,将两个变量分割(空白数据填充)
struct data{
int a;
int b;
}
struct data global_data
// function1
void add_a(){
for(int i = 0;i<50000000;i++)
++global_data.a;
}
void add_b(){
for(int i = 0;i<50000000;i++)
++global_data.b;
}
void run(){
thread t1 = thread(add_a)
thread t2 = thread(add_b)
t1.join()
t2.join()
}
// function2
atomic<int> a
void run(){
for(int i = 0;i<50000000;i++)
++global_data.a;
for(int i = 0;i<50000000;i++)
++global_data.b;
}