Docker搭建ELK步骤详解
文章目录
- 一.安装前须知
- 二.安装 Docker
- 三.Docker 安装 ElasticSearch
- 四.Docker 安装 ElasticSearch-head(可选)
- 五.Docker 安装 Kibana
- 六.Docker 安装 LogStash
- 七.创建springboot应用
- 七.后记
一.安装前须知
以下步骤在 VMware 中的 centos 7 中操作,ip 地址为:192.168.161.128;
注意安装的时候最好统一版本,否则后面会出现许多问题,进官网搜索对应镜像,查看 Tags 标签下的版本,目前我这最新的 Tags 是 7.12.1,所以拉取镜像时统一加上该版本号。官网镜像地址
Docker 搭建 ELK 之前需熟悉 Docker 的相关指令,如:拷贝容器文件docker cp、强制删除容器: docker rm -f 容器id、创建网络: docker network create elk、查看日志:docker logs container 等等。
为了方便后续文件的挂载,先创建如下目录 /usr/local/elk ,再执行 mkdir /usr/local/elk/{elasticsearch,kibana,logstash} 创建3个对应的目录,所以以下操作如无特别说明,均在 /usr/local/elk下执行。
为了容器间的通信,需要先用 docker 创建一个网络: docker network create elk。
二.安装 Docker
安装 docker 可以照着官网步骤一步一步来,挺简单的。
Install Docker Engine on CentOS
安装完后可以看下版本:docker -v
查看 docker 详细信息:docker info
三.Docker 安装 ElasticSearch
1.搜索、下载并查看镜像
# 搜索镜像
docker search elasticsearch
# 拉取 7.12.1 版本镜像
docker pull elasticsearch:7.12.1
# 查看所有镜像
docker images
2.拷贝配置文件
# 运行 elasticsearch
docker run -d --name es --net elk -P -e "discovery.type=single-node" elasticsearch:7.12.1
# 进入容器查看配置文件路径
docker exec -it es /bin/bash
cd config
在 config 中可看到 elasticsearch.yml 配置文件,再执行 pwd 可以看到当前目录为: /usr/share/elasticsearch/config,所以退出容器,执行文件的拷贝:
# 将容器内的配置文件拷贝到 /usr/local/elk/elasticsearch/ 中
docker cp es:/usr/share/elasticsearch/config/elasticsearch.yml elasticsearch/
# 修改文件权限
chmod 666 elasticsearch/elasticsearch.yml
# 在elasticsearch 目录下再创建data目录,同时修改权限
chmod -R 777 elasticsearch/data
注意:这里要修改文件的权限为可写,否则,进行挂载后,在外部修改配置文件,容器内部的配置文件不会更改。同时,创建 data 目录进行挂载。
3.重新运行容器并挂载:
# 先删除旧的容器
docker rm -f es
# 运行新的容器
docker run -d --name es \
--net elk \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
--privileged=true \
-v $PWD/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v $PWD/elasticsearch/data/:/usr/share/elasticsearch/data \
elasticsearch:7.12.1
说明:
-p (小写)映射端口号,主机端口:容器端口
-P(大写)随机为容器指定端口号
-v 进行容器的挂载
–name 指定容器别名
–net 连接指定网络
-e 指定启动容器时的环境变量
-d 后台运行容器
–privileged=true 使容器有权限挂载目录
4.查看容器
# 查看运行中的容器
docker ps
# 查看容器日志
docker logs es
curl localhost:9200
如果日志无误,可以用 curl ip:9200 查看结果,也可用浏览器输入 http://ip:9200 查看。至此,elasticsearch 安装完成。
同时,我们可以在 data 目录下看到容器内的数据,并且在宿主机修改也会同步到容器的内部。
四.Docker 安装 ElasticSearch-head(可选)
说明:这是 ES 的可视化界面,是为了方便后面调试时看日志有没成功输入到 ES 用的,非必须安装的项目,也可跳过此步。
1.拉取镜像
docker pull mobz/elasticsearch-head:5
2.运行容器
docker run -d --name es_admin --net elk -p 9100:9100 mobz/elasticsearch-head:5
注意:这里使用到了 --net elk,即我们之间创建的网络;
如果没有创建,则需要进行下一步修改配置配件,如果前面照着创建了,则可以直接跳过。
3.编辑配置文件(可选)
#将配置文件拷贝到当前目录下
docker cp es_admin:/usr/src/app/Gruntfile.js ./
编辑该配置文件,在 connect -> server -> options 下添加: hostname: ‘0.0.0.0’

#将文件拷贝回去
docker cp Gruntfile.js es_admin:/usr/src/app/
# 重启容器
docker restart es_admin
因为该镜像内部没有安装 vi 和 vim,所以无法直接在容器内部编辑,需要我们拷贝出来,修改后再进行覆盖。
重启容器后,通过 http://ip:9100 访问即可查询 ES 中的数据。
4.页面无数据问题
如果打开页面之后节点、索引等显示完全,但是数据浏览中无数据显示,那么我们还需要改一个配置文件,这是因为 ES 6 之后增加了请求头严格校验的原因(我们装的是 7.12.1 版本):
docker cp es_admin:/usr/src/app/_site/vendor.js ./
vi vendor.js
docker cp vendor.js es_admin:/usr/src/app/_site/
这个配置文件内容有点多,这里需要了解 vim 的部分操作:
按 ESC 进入命令模式,接着 : set nu 显示行号,接着 : 行号 跳转到对应的行。
在这里我们需要修改:(注意不是把整行替换掉)
6886 行:contentType: “application/json;charset=UTF-8”
7573 行: contentType === “application/json;charset=UTF-8”
改完后再将配置文件 copy 回容器,不需重启,直接刷新页面即可。
五.Docker 安装 Kibana
步骤大致如同 elasticsearch:
1.拉取镜像
docekr search kibana
docker pull kibana:7.12.1
# 启动 kibana 容器并连接同一网络
docker run -d --name kibana --net elk -P -e "ELASTICSEARCH_HOSTS=http://es:9200" -e "I18N_LOCALE=zh-CN" kibana:7.12.1
注意: -e “ELASTICSEARCH_HOSTS=http://es:9200” 表示连接刚才启动的 elasticsearch 容器,因为在同一网络(elk)中,地址可直接填 容器名+端口,即 es:9200, 也可以填 http://192.168.161.128:9200,即 http://ip:端口。
2.拷贝文件
docker cp kibana:/usr/share/kibana/config/kibana.yml kibana/
chmod 666 kibana/kibana.yml
拷贝完成后,修改该配置文件,主要修改 elastissearch.hosts 并新增 i18n.locale 配置:
- es 地址改为刚才安装的 es 地址,因容器的隔离性,这里最好填写 http://ip:9200;
- kibana 界面默认是英文的,可以在配置文件中加上 i18n.locale: zh-CN(注意冒号后面有个空格)。
这样有了配置文件,在启动容器时就不用通过 -e 指定环境变量了。
#
# ** THIS IS AN AUTO-GENERATED FILE **
#
# Default Kibana configuration for docker target
server.name: kibana
server.host: "0"
# elasticsearch 地址
elasticsearch.hosts: [ "http://192.168.161.128:9200" ]
monitoring.ui.container.elasticsearch.enabled: true
# 开启 kibana 的汉化
i18n.locale: zh-CN
注意:如果使用挂载配置文件的方式启动的话,elasticsearch.hosts 这需填写 http://ip:9200,而不能使用容器名了,否则后面 kibana 连接 es 会失败。
3.重新开个容器
#删除原来未挂载的容器
docker rm -f kibana
# 启动容器并挂载
docker run -d --name kibana \
-p 5601:5601 \
-v $PWD/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml \
--net elk \
kibana:7.12.1
4.查看结果
打开浏览器,输入:http://ip:5601 打开 kibana 控制台,如果未能成功打开,可以使用: docker logs kibana 查看容器日志看是否运行有误等。
可参考官网:Install Kibana with Docker
六.Docker 安装 LogStash
安装 Logtash 继续同上:
1.拉取镜像并拷贝配置
docker pull logstash:7.12.1
docker run -d -P --name logstash --net elk logstash:7.12.1
# 拷贝数据
docker cp logstash:/usr/share/logstash/config logstash/
docker cp logstash:/usr/share/logstash/data logstash/
docker cp logstash:/usr/share/logstash/pipeline logstash/
#文件夹赋权
chmod -R 777 logstash/
2.修改相应配置文件
修改 logstash/config 下的 logstash.yml 文件,主要修改 es 的地址:
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://192.168.161.128:9200" ]
修改 logstash/pipeline 下的 logstash.conf 文件:
input {
tcp {
mode => "server"
host => "0.0.0.0" # 允许任意主机发送日志
port => 5044
codec => json_lines # 数据格式
}
}
output {
elasticsearch {
hosts => ["http://192.168.161.128:9200"] # ElasticSearch 的地址和端口
index => "elk" # 指定索引名
codec => "json"
}
stdout {
codec => rubydebug
}
}
3.启动容器并挂载
#注意先删除之前的容器
docker rm -f logstash
# 启动容器并挂载
docker run -d --name logstash --net elk \
--privileged=true \
-p 5044:5044 -p 9600:9600 \
-v $PWD/logstash/data/:/usr/share/logstash/data \
-v $PWD/logstash/config/:/usr/share/logstash/config \
-v $PWD/logstash/pipeline/:/usr/share/logstash/pipeline \
logstash:7.12.1
4.查看日志
docker logs -f logstash
每次启动完容器最好检查下日志,这样方便后续的步骤,如果出了问题,可以看到是哪的问题并方便解决。
七.创建springboot应用
这个比较简单,主要就是几个配置文件:
pom.xml 文件,引入 logstash 的依赖:
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.6</version>
</dependency>
在 resource 下创建 log/logback-springxml 文件,这里我们主要填写
ip:端口,关于 标签则看个人使用情况修改。
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/base.xml" />
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.161.128:5044</destination>
<!-- 日志输出编码 -->
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
<!--es索引名称 -->
"index":"elk",
<!--应用名称 -->
"appname":"${spring.application.name}",
<!--打印时间 -->
"timestamp": "%d{yyyy-MM-dd HH:mm:ss.SSS}",
<!--线程名称 -->
"thread": "%thread",
<!--日志级别 -->
"level": "%level",
<!--日志名称 -->
"logger_name": "%logger",
<!--日志信息 -->
"message": "%msg",
<!--日志堆栈 -->
"stack_trace": "%exception"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="LOGSTASH" />
<appender-ref ref="CONSOLE" />
</root>
</configuration>
最后修改 application.yml 文件:
logging:
config: classpath:log/logback-spring.xml
启动后在 elasticsearch-head 界面即可看到输出的日志:
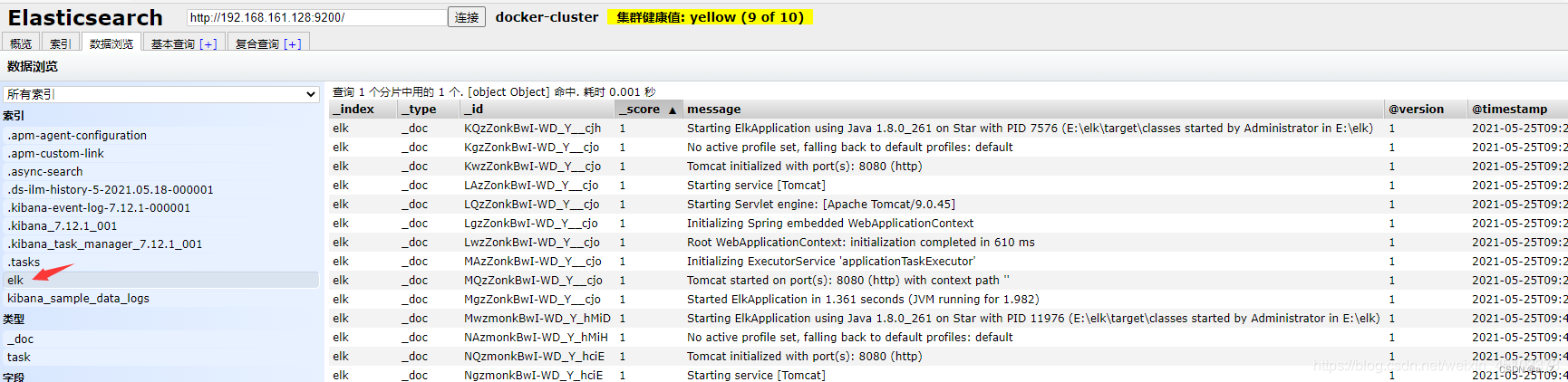
同时在 kibana 页面可以看到增加了索引 elk:
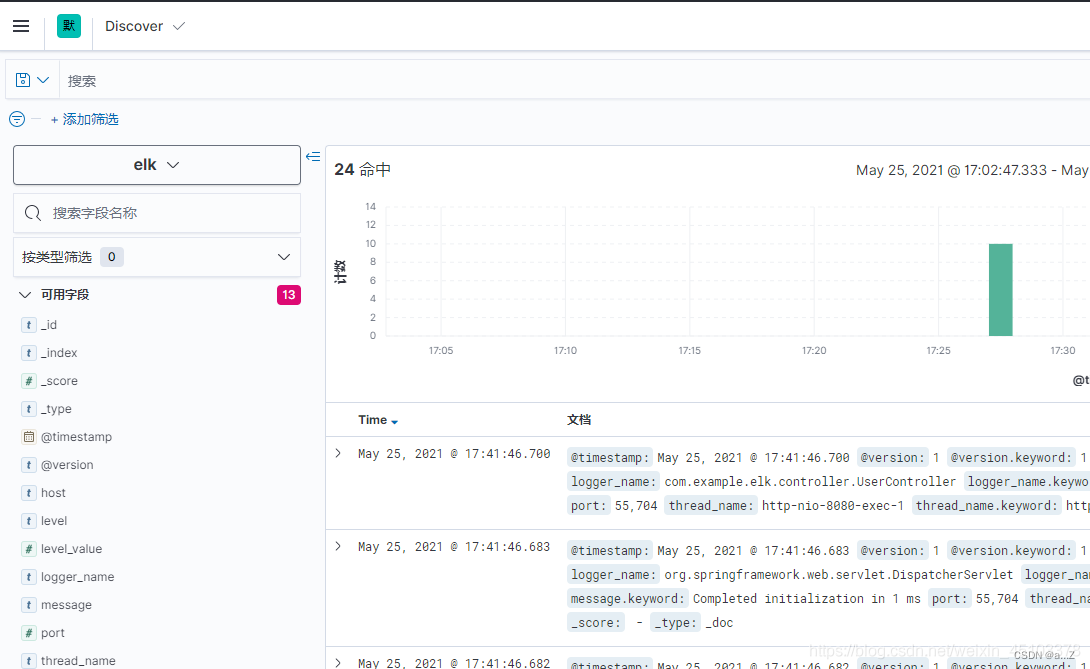
至此,完成了用 Docker 搭建 elk 的过程。
七.后记
在搭建 ELK 时有遇到如下几个问题,特此记录一下:
1.Docker 拉取内存不足
由于我是在 VMware 装的 centos 7 上搭建的,开始装系统时挂载到根目录下的内存较小,因此,docker 拉取镜像时,到了 Logstash 这一步就提示内存不足了,又不想重新装过系统,因此,可以通过编辑 docker 的配置文件,来改变默认的容器卷下载的目录。
# 查看 docker 默认下载地址
docker info | grep "Docker Root Dir"
# 创建目录
mkdir /home/docker-root
# 编辑配置文件
vi /usr/lib/systemd/system/docker.service
在编辑 docker.service 配置文件时,在 [Service] 节点下找到 ExecStart,在后面加上: --graph=/home/docker-root 即可,docker-root 即为刚才创建的目录:
[Service]
ExecStart=/usr/bin/dockerd --graph=/home/docker-root
最后重启 docker:
systemctl daemon-reload
systemctl restart docker
systemctl enable docker
2.Logstash端口映射
在编辑 logstash.conf 文件时,需要注意暴露出来的端口还需要容器映射才行,否则会导致 springboot 连接不上 logstash,如:
input {
tcp {
mode => "server"
host => "0.0.0.0" # 允许任意主机发送日志
port => 5044
codec => json_lines # 数据格式
}
}
这里允许任意主机通过 5044 端口发送日志,则在启动容器的时候,同时需要 -p 5044:5044 将端口映射出去,否则 springboot 在启动时会连接不到 logstash。
3.启动容器时内存不足
在启动 elasticsearch 或 logstash 容器时,可能会出现内存不足的情况,我们可以通过编辑修改指定文件来修改内存分配:
# 查找 jvm.options 文件
find / -name jvm.options
找到对应的 jvm.options 修改文件中的 -Xms(最小内存)和-Xmx(最大内存)。
或者在启动 elasticsearch 容器时,可直接加入环境变量如下所示,而 logstash 的目前没找到,可通过前面修改 jvm.options来修改。
-e "ES_JAVA_OPTS=-Xms1g -Xmx1g"
| 转载 https://blog.csdn.net/weixin_45103378/article/details/117032750