文章目录
- 1 描述统计
- 1.1 查看常见统计量 describe
- 1.2 一般对数值型数据统计
- 1.2.1 基于非空数值统计sum\mean\max\min\var\std
- 1.2.2 每一列中最大值的行索引 idxmax
- 1.2.3 每一行中最大值的列索引 idxmax(axis = 1)
- 1.2.4 非空的数量 count()
- 1.3 一般对字符型数据统计
- 1.3.1 序列有多少不同的取值
- 1.3.2 统计分类次数
1 描述统计
描述统计学(descriptive statistics)是一门统计学领域的学科,主要研究如何取得反映客观现象的数据,并以图表形式对所搜集的数据进行处理和显示,最终对数据的规律、特征做出综合性的描述分析。Pandas 库将“描述统计学”作为理论基奠,是对描述统计学知识完美应用的体现。下列表格对 Pandas 常用的统计学函数做了简单的总结:
| 函数名称 | 描述说明 |
|---|---|
| count() | 统计某个非空值的数量。 |
| sum() | 求和 |
| mean() | 均值 |
| median() | 中位数 |
| mode() | 众数 |
| std() | 标准差 |
| min() | 最小值 |
| max() | 最大值 |
| abs() | 绝对值 |
| describe() | 统计描述 |
| prod() | 所有数值的乘积。 |
| cumsum() | 计算累计和,axis=0,按照行累加;axis=1,按照列累加。 |
| cumprod() | 计算累计积,axis=0,按照行累积;axis=1,按照列累积。 |
| corr() | 计算数列或变量之间的相关系数,取值-1到1,值越大表示关联性越强。 |
数据集:鸢尾花数据集
链接:https://pan.baidu.com/s/1KXGcqRGkZ0etMach5sIRhg
提取码:2wfo
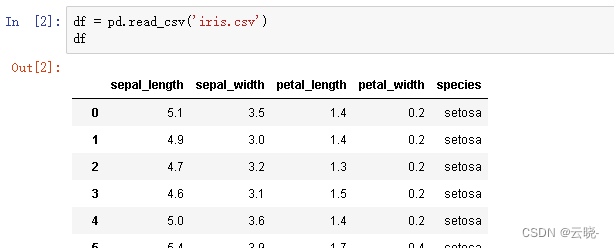
1.1 查看常见统计量 describe
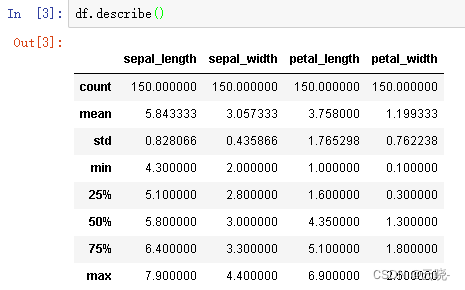
df.describe() #数值型统计描述,非空数值
df.describe(include = ['object']) #类别型统计描述
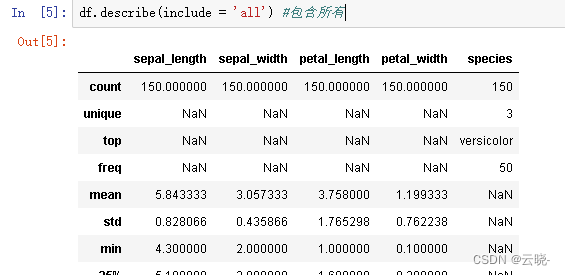
df.describe(include = 'all') #包含所有

1.2 一般对数值型数据统计
1.2.1 基于非空数值统计sum\mean\max\min\var\std
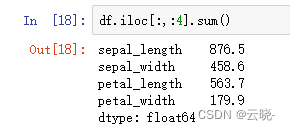
df.iloc[:,:4].sum() #默认按照列进行求和,添加参数axis = 1,可按行统计,可以同时处理数字和字符串数据,但是字符聚合通常不被使用
#sum\mean\max\min\var\std 基于非空的数
1.2.2 每一列中最大值的行索引 idxmax
df.iloc[:,:4].idxmax()

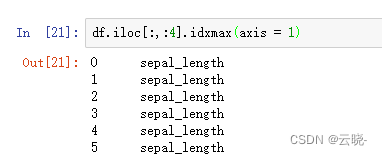
1.2.3 每一行中最大值的列索引 idxmax(axis = 1)
df.iloc[:,:4].idxmax(axis = 1)
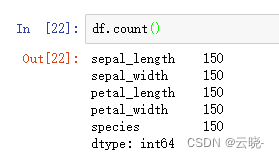
1.2.4 非空的数量 count()
df.count()
1.3 一般对字符型数据统计
1.3.1 序列有多少不同的取值
df[''].unique() #取值
df[''].nunique() #取值数量

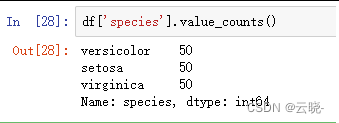
1.3.2 统计分类次数
df[''].value_counts() #统计分类变量每种分类出现次数