第一课
主要分为以下内容进行讲述

机器学习工业应用领域

机器学习常用算法

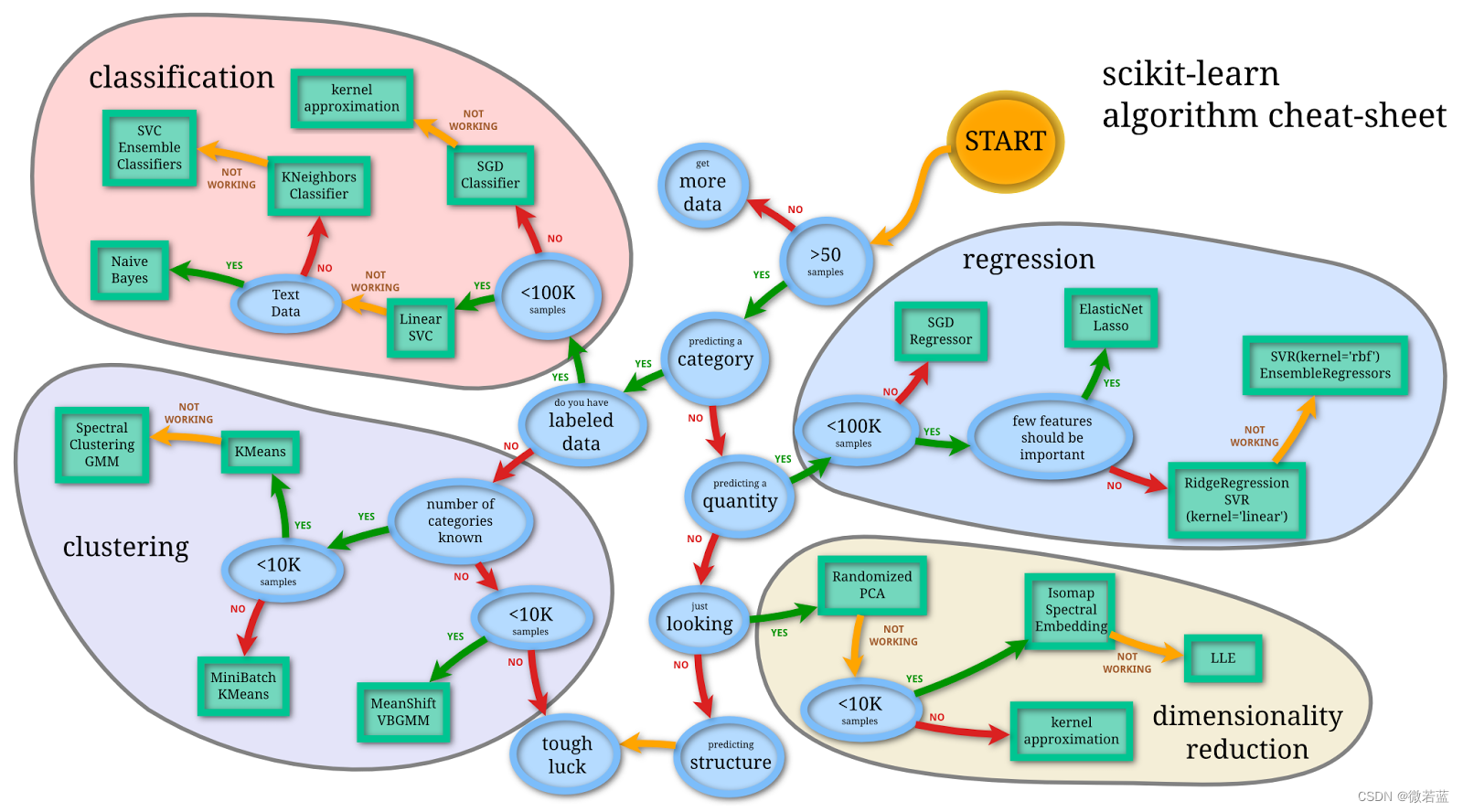
机器学习常用工具

解决问题流程
数据的处理比模型更为重要
老师的博客,内容很详细

数据预处理
有时候可以一个feature一个feature去做

特征工程


模型选择

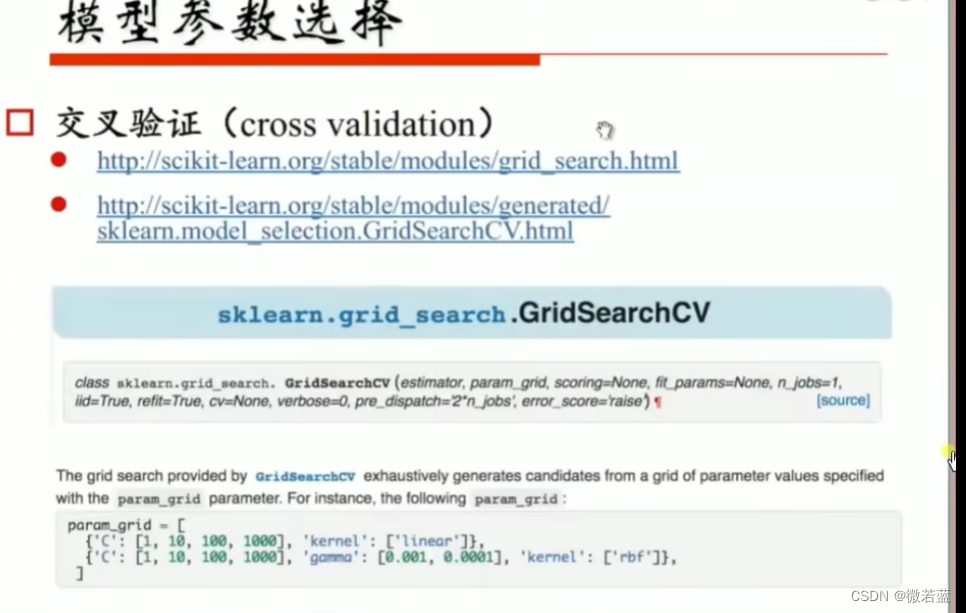
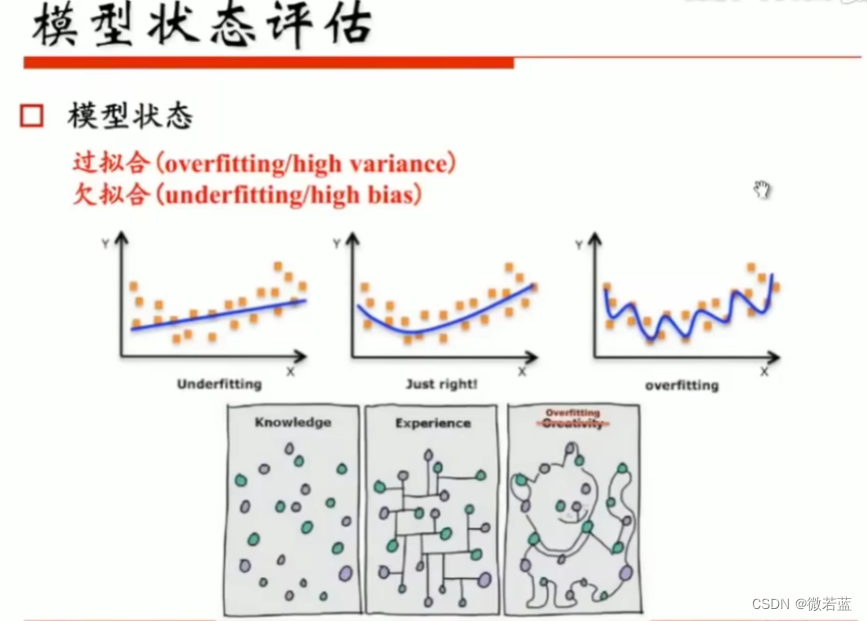
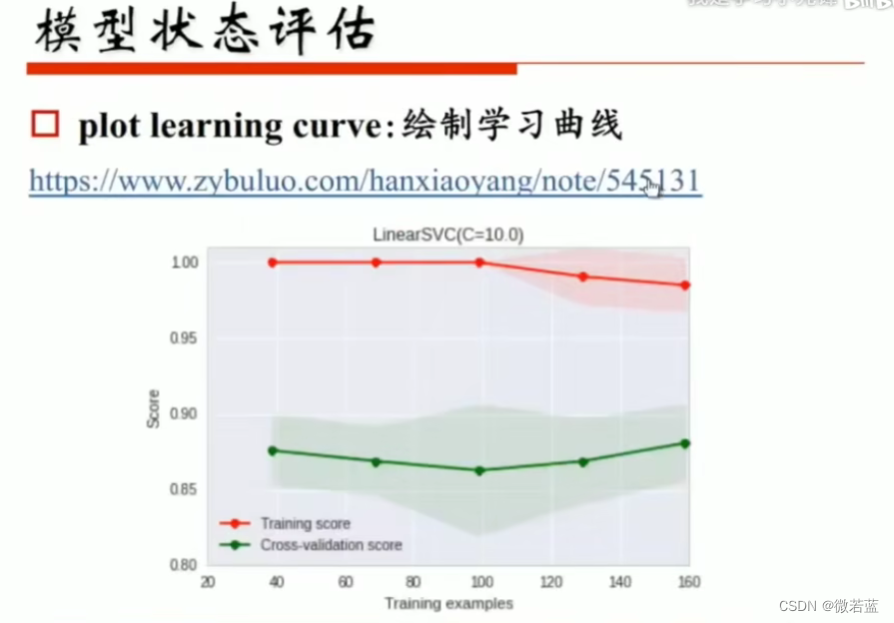
模型状态评估
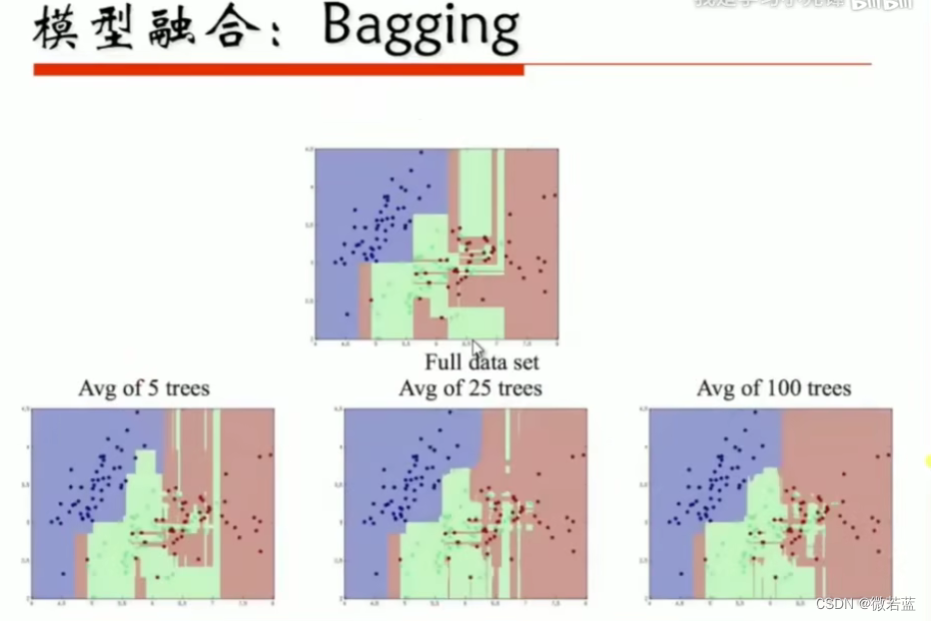
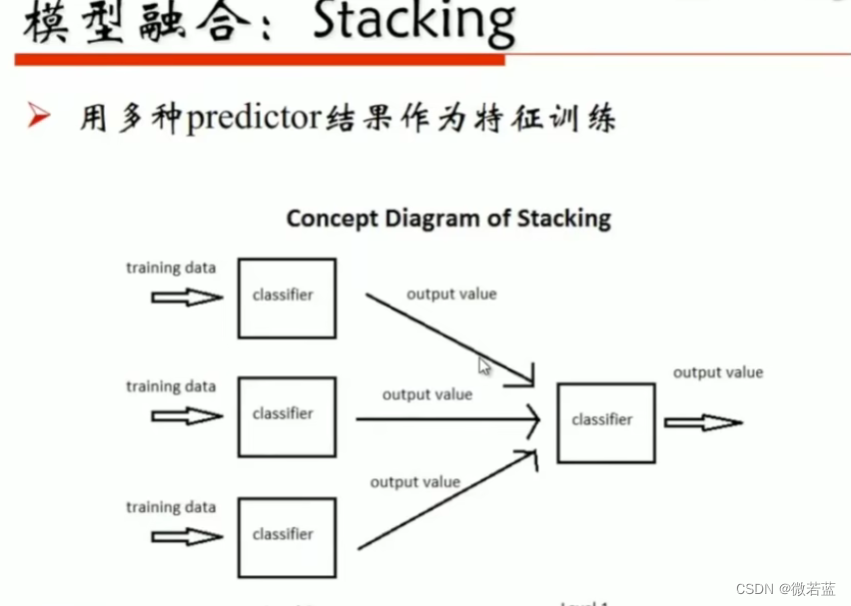
模型融合

Bagging是一种集成学习(Ensemble Learning)的技术,全称为“Bootstrap Aggregating”。它是通过构建多个相互独立的基本模型(通常是决策树或其他分类器),然后通过对基本模型的预测结果进行投票或平均来进行最终预测的技术。
在Bagging中,采用自助法(bootstrap)从原始训练集中有放回地随机抽取多个样本(可重复抽样),构建多个训练集,每个训练集与原始训练集的大小相同。然后,使用每个训练集独立训练一个基本模型。最后,将这些基本模型的预测结果进行组合,通常通过投票或平均来生成最终的预测结果。
Bagging的优点包括:
降低模型的方差:通过构建多个基本模型并进行组合,可以降低模型的方差,减少过拟合的风险。
提高模型的鲁棒性:由于基本模型是相互独立训练的,因此对于数据的扰动和噪声具有一定的鲁棒性。
增加预测的准确性:通过集成多个基本模型的预测结果,可以提高整体的预测准确性和稳定性。
可以并行化处理:由于基本模型相互独立,因此可以并行训练和预测,提高计算效率。
常见的Bagging算法包括随机森林(Random Forest)和袋装决策树(Bagged Decision Trees),它们基于决策树进行集成学习。Bagging在各种机器学习任务中被广泛应用,并取得了良好的效果。

Boosting是一种集成学习(Ensemble Learning)的技术,用于通过组合多个弱学习器来构建一个强大的学习器。与Bagging不同,Boosting是通过顺序训练一系列的基本模型(通常是决策树或其他分类器),每个基本模型都试图纠正前一个模型的错误。
Boosting的基本思想是通过迭代训练一系列的弱学习器,每次训练都会调整样本的权重,使得前一个模型预测错误的样本在下一轮中得到更多的关注。在每一轮训练中,基本模型都会根据前一轮的预测结果来调整样本的权重,并尽可能减少上一轮预测错误的样本的权重。
Boosting的主要过程如下:
初始化样本权重:开始时,将所有样本的权重初始化为相等值。
迭代训练基本模型:通过迭代训练一系列的基本模型,每个模型都根据当前样本权重进行训练。
调整样本权重:在每一轮训练后,根据前一轮的预测结果来调整样本的权重,使得前一轮预测错误的样本在下一轮中获得更高的权重。
组合基本模型:将所有基本模型的预测结果进行加权组合,通常采用加权投票或加权平均的方式得到最终的预测结果。
Boosting的优点包括:
提高模型的准确性:通过迭代训练一系列的基本模型,Boosting可以逐步减少预测错误,提高整体的预测准确性。
自适应学习:Boosting通过调整样本权重来关注前一轮预测错误的样本,从而使得模型能够适应数据的特点和难易程度。
可以处理高维度数据:Boosting能够有效地处理高维度数据,对于特征维度较高的问题具有较好的适应性。
常见的Boosting算法包括Adaboost(Adaptive Boosting)和梯度提升树(Gradient Boosting Tree),它们在各种机器学习任务中被广泛应用,并取得了良好的效果。Boosting在处理复杂任务和大规模数据集时具有很强的表现能力。