文章目录
- 1.划分val数据集
- 2. xml to json
- 3. coco格式json文件
- 4. 生成coco格式json文件
- 5.使用pycocotools计算map
- 6. 讨论
在目标检测任务中,需要通过Map指标判断模型的精度。为了测试engine文件推理结果的精度,本文介绍了如何使用pycocotools库计算Map,在此之前需要根据coco格式生成json文件。
必须按照coco格式生成json,顺序都要保持一致才行,否则报错不通过。
1.划分val数据集
在做验证时,需要提前划分好val数据集。本文采用labelimg工具画框,因此需要对xml和image文件进行划分。
# coding:utf-8
import os
import random
import argparse
from pathlib import Path
import shutil
def move_xml_img(save_path, xml_path, img_path, percent):
total_img = os.listdir(img_path)
num = len(total_img)
percen_img = int(num * percent)
print("Image Num: ", percen_img)
train_lists = random.sample(total_img, percen_img)
save_img_path = save_path + '/' + "images"
save_xml_path = save_path + '/' + "xml"
if not os.path.exists(save_img_path):
os.makedirs(save_img_path)
if not os.path.exists(save_xml_path):
os.makedirs(save_xml_path)
for list in train_lists:
name = Path(list).stem
save_img_path = save_path + '/' + "images" + '/'
save_xml_path = save_path + '/' + "xml" + '/'
img = img_path + name + ".bmp"
xml = xml_path + name + ".xml"
# print(img)
shutil.copy(img, save_img_path)
shutil.copy(xml, save_xml_path)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--xml_path', default='E:/datasets/titanium/xml/', type=str, help='input xml label path')
parser.add_argument('--img_path', default='E:/datasets/titanium/img/', type=str, help='input image label path')
parser.add_argument('--save_path', default='E:/datasets/val_titanium/', type=str, help='output txt label path')
opt = parser.parse_args()
val_percent = 0.2 # 训练集所占比例,可自己进行调整
xml_path = opt.xml_path
img_path = opt.img_path
save_path = opt.save_path
val_path = save_path + '/' + "val"
print("Val datasets start")
move_xml_img(val_path, xml_path, img_path, val_percent)
print("Val datasets end")
print("End split train and val datasets")
- xml_path:表示全部数据集xml的路径
- img_path:表示全部数据集image的路径
- save_path:表示划分之后val验证数据集存放的路径,会在save_path目录下生成image和xml路径
- val_percent :调节验证集的数据,0.2表示比例
运行完上述代码会在save_path目录下生成val验证数据集。
2. xml to json
本文将val GT 数据集转cooc格式json文件都采用的txt转json的方式,因此需要将val数据集的xml文件转换为txt文件,提供代码如下:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from pathlib import Path
class_name = ['normal', 'iron', 'crystal', 'impurity']
get_name = {}
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(xml_file, save_txt_file):
in_file = open(xml_file, encoding='UTF-8')
out_file = open(save_txt_file, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
if root:
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in get_name:
get_name[cls] = 1
else:
get_name[cls] += 1
if cls not in class_name:
continue
cls_id = class_name.index(cls)
xml_box = obj.find('bndbox')
b = (float(xml_box.find('xmin').text), float(xml_box.find('xmax').text), float(xml_box.find('ymin').text),
float(xml_box.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == '__main__':
xml_path = "E:/datasets/val_titanium/xml/"
save_txt_path = "E:/datasets/val_titanium/labels/"
if not os.path.exists(save_txt_path):
os.makedirs(save_txt_path)
xml_lists = os.listdir(xml_path)
for xml in xml_lists:
# print("Do XML File:" + xml)
name = Path(xml).stem
xml_file = xml_path + xml
txt_path = save_txt_path + name + ".txt"
convert_annotation(xml_file, txt_path)
print("XML File End:" + xml_path)
print("Txt File Save On:" + save_txt_path)
print("class name: ", class_name)
print("get class name: ", get_name)
1. class_name:类别名称,需要将类别名称转换为int类型,根据自己的数据集进行排列
2. xml_path :xml文件路径
3. save_txt_path :保存txt文件路径
执行完上述代码之后,会在验证数据集目录下生成如下文件夹:
下面就可以将txt格式转化为cooc json格式了。
3. coco格式json文件
pycocotools对json文件必须严格要求coco格式,因此生成的json文件必须按照如下格式进行编写:
1. GT json(val验证数据集的参考数据)
{
"info": ["none"],
"license": ["none"],
"images":
[{"file_name": ,
"width": ,
"height": ,
"id":
}],
"annotations":
[{"area": 2860,
"iscrowd": 0,
"image_id": ,
"bbox": [536, 29, 52, 55],
"category_id": 2,
"id": ,
"ignore": 1,
"segmentation": []},
"categories":
[{"id": ,
"name": ,
"supercategory":
}]
其中:images内的id要和annotations中的id保持一致,categories内的id非0即可。area为目标面积
2.需要参考的数据格式(也就是待测试的json文件)
[{
"score": 0.0,
"bbox": [536.0, 29.0, 52.0, 55.0],
"image_id": ,
"category_id": 2},
4. 生成coco格式json文件
在执行下述代码时,还需要在val验证数据集目录下建立classes.txt文件,里面存放目标类别名称。
类别A
类别B
类别C
类别D
import os
import cv2
import json
from tqdm import tqdm
import argparse
def val2coco(arg):
root_path = arg.root_dir
print("Loading data from ", root_path)
assert os.path.exists(root_path)
labels_path = os.path.join(root_path, 'labels')
img_path = os.path.join(root_path, 'images')
with open(os.path.join(root_path, 'classes.txt')) as f:
classes = f.read().strip().split()
print(classes)
# images dir name
indexes = os.listdir(img_path)
# 用于保存所有数据的图片信息和标注信息
val_dataset = {'info': ['none'], 'license': ['none'], 'images': [], 'annotations': [], 'categories': []}
# 建立类别标签和数字id的对应关系, 类别id从0开始。
for i, cls in enumerate(classes, 0):
val_dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'cow'})
# 标注的id
for k, index in enumerate(tqdm(indexes)):
# 支持 png jpg 格式的图片。
txtFile = index.replace('images', 'labels').replace('.bmp', '.txt')
im = cv2.imread(os.path.join(root_path, 'images/') + index)
height, width, _ = im.shape
# 添加图像的信息
object_id = "".join(filter(str.isdigit, index))
val_dataset['images'].append({'file_name': index,
'width': width,
'height': height,
'id': int(object_id)})
if not os.path.exists(os.path.join(labels_path, txtFile)):
# 如没标签,跳过,只保留图片信息。
continue
with open(os.path.join(labels_path, txtFile), 'r') as fr:
labelList = fr.readlines()
for label in labelList:
label = label.strip().split()
# print(label)
x = float(label[1])
y = float(label[2])
w = float(label[3])
h = float(label[4])
# convert x,y,w,h to x1,y1,x2,y2
H, W, _ = im.shape
x1 = int((x - w / 2) * W)
y1 = int((y - h / 2) * H)
x2 = int((x + w / 2) * W)
y2 = int((y + h / 2) * H)
x1 = max(0, x1)
y1 = max(0, y1)
x2 = min(W, x2)
y2 = min(H, y2)
cls_id = int(label[0])
width = max(x1 - x2, x2 - x1)
height = max(y1 - y2, y2 - y1)
# print(width)
val_dataset['annotations'].append({
'area': width * height,
'iscrowd': 0,
'image_id': int(object_id),
'bbox': [x1, y1, width, height],
'category_id': cls_id,
'id': int(object_id),
"ignore": 1,
'segmentation': []
})
# 保存结果
with open(arg.save_val_path, 'w') as f:
json.dump(val_dataset, f)
print('Save annotation to {}'.format(arg.save_val_path))
def engine_result2coco(arg):
txt_path = arg.result_txt_path
txt_files = os.listdir(txt_path)
results_list = []
for txt_file in tqdm(txt_files):
txt = os.path.join(txt_path, txt_file)
res_dict = dict()
with open(txt, 'r') as tf:
labellists = tf.readlines()
for labellist in labellists:
label = labellist.strip().split()
x = float(label[1])
y = float(label[2])
w = float(label[3])
h = float(label[4])
cls_id = int(label[0])
image_id = "".join(filter(str.isdigit, txt_file))
conf = label[5]
res_dict['score'] = float(conf)
res_dict['bbox'] = [float(x), float(y), float(round(w)), float(h)]
res_dict['image_id'] = int(image_id)
res_dict['category_id'] = int(cls_id)
results_list.append(res_dict)
with open(arg.save_result_path, 'w') as f:
json.dump(results_list, f)
print('Save annotation to {}'.format(arg.save_result_path))
def pt_result2coco(arg):
pt_txt_path = arg.pt_txt_path
img_path = str(pt_txt_path).replace('pt_labels', 'images')
txt_files = os.listdir(pt_txt_path)
results_list = []
for txt_file in tqdm(txt_files):
img_file = txt_file.replace('txt', 'bmp')
img = cv2.imread(os.path.join(img_path, img_file))
H, W, _ = img.shape
txt = os.path.join(pt_txt_path, txt_file)
res_dict = dict()
with open(txt, 'r') as tf:
labellists = tf.readlines()
for labellist in labellists:
label = labellist.strip().split()
cls_id = int(label[0])
cx, cy, w, h = float(label[1]) * W, float(label[2]) * H, float(label[3]) * W, float(label[4]) * H
x1 = max(0, float(cx - w / 2.0))
y1 = max(0, float(cy - h / 2.0))
image_id = "".join(filter(str.isdigit, txt_file))
res_dict['score'] = float(0.00)
res_dict['bbox'] = [round(float(x1), 3), round(float(y1), 3), round(float(w), 3),
round(float(h), 3)]
res_dict['image_id'] = int(image_id)
res_dict['category_id'] = int(cls_id)
results_list.append(res_dict)
with open(arg.save_pt_path, 'w') as f:
json.dump(results_list, f)
print('Save annotation to {}'.format(arg.save_pt_path))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--root_dir', default='E:/datasets/val_titanium/', type=str,
help="root path of images and labels, include ./images and ./labels and classes.txt")
parser.add_argument('--save_val_path', type=str, default='E:/datasets/val_titanium/annotations.json',
help="GT json path")
parser.add_argument('--result_txt_path', type=str, default='E:/datasets/val_titanium/nvidia_1b_labels_1/',
help="engine txt path")
parser.add_argument('--save_result_path', type=str, default='E:/datasets/val_titanium/nvidia_fp32_1b_2.json',
help="engine json path")
parser.add_argument('--pt_txt_path', type=str, default='E:/datasets/val_titanium/pt_labels/',
help="pt txt path")
parser.add_argument('--save_pt_path', type=str, default='E:/datasets/val_titanium/pt.json',
help="pt json path")
arg = parser.parse_args()
val2coco(arg)
engine_result2coco(arg)
pt_result2coco(arg)
1. val2coco函数生成GT val的json文件
2. engine_result2coco函数,是将yolov5 engine模型测试输出的txt文件转换为json格式
3. pt_result2coco函数将yolov5 pt文件通过detect.py生成的txt文件转换为json格式
4. image_id:代码中提取文件名中的int数字作为image_id,也可以将文件名转为str类型,但是需要所有的json都保持一致。
每个函数对应两个路径,修改好路径,根据自己的需求使用相应的函数。
engine_result2coco和pt_result2coco区别在与保存的txt文件是否归一化。
执行完上述代码之后,会在验证数据集目录下生成如下文件:
至此,满足pycocotools库的json文件已经生成,下一步介绍如何使用pycocotools工具测试json文件计算map。
5.使用pycocotools计算map
首先需要安装pycocotools库,推荐下列博主的方法:
https://blog.csdn.net/weixin_42715977/article/details/127727247
安装完毕即可使用pycocotools工具计算map值。
import os
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
from collections import OrderedDict
import argparse
class COCOResults(object):
METRICS = {
"bbox": ["AP", "AP50", "AP75", "APs", "APm", "APl"],
"segm": ["AP", "AP50", "AP75", "APs", "APm", "APl"],
"box_proposal": [
"AR@100",
"ARs@100",
"ARm@100",
"ARl@100",
"AR@1000",
"ARs@1000",
"ARm@1000",
"ARl@1000",
],
"keypoints": ["AP", "AP50", "AP75", "APm", "APl"],
}
def __init__(self, *iou_types):
allowed_types = ("box_proposal", "bbox", "segm", "keypoints")
assert all(iou_type in allowed_types for iou_type in iou_types)
results = OrderedDict()
for iou_type in iou_types:
results[iou_type] = OrderedDict(
[(metric, -1) for metric in COCOResults.METRICS[iou_type]]
)
self.results = results
def update(self, coco_eval):
if coco_eval is None:
return
from pycocotools.cocoeval import COCOeval
assert isinstance(coco_eval, COCOeval)
s = coco_eval.stats
iou_type = coco_eval.params.iouType
res = self.results[iou_type]
metrics = COCOResults.METRICS[iou_type]
for idx, metric in enumerate(metrics):
res[metric] = s[idx]
def __repr__(self):
results = '\n'
for task, metrics in self.results.items():
results += 'Task: {}\n'.format(task)
metric_names = metrics.keys()
metric_vals = ['{:.4f}'.format(v) for v in metrics.values()]
results += (', '.join(metric_names) + '\n')
results += (', '.join(metric_vals) + '\n')
return results
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--log', default='E:/datasets/val_titanium/annotations.json',
help='GT path(s)')
parser.add_argument('--anno', default='E:/datasets/val_titanium/pt.json',
help='anno path(s)')
parser.add_argument('--image-dir', default='E:/datasets/val_titanium/images/',
help='image path(s)')
args = parser.parse_args()
coco = COCO(args.anno)
results = COCOResults('bbox')
coco_dt = coco.loadRes(args.log)
coco_eval = COCOeval(coco, coco_dt, 'bbox')
imagelist = os.listdir(args.image_dir)
# coco_eval.params.imgIds = [int(Path(x).stem) for x in imagelist if x.endswith('jpg')]
coco_eval.evaluate()
coco_eval.accumulate()
coco_eval.summarize()
results.update(coco_eval)
print(results)
1. log路径为GT 目标的json文件
2. anno路径为待测试结果的json文件
3. image-dir为测试图片的路径
运行完上述代码会打印计算的map值:
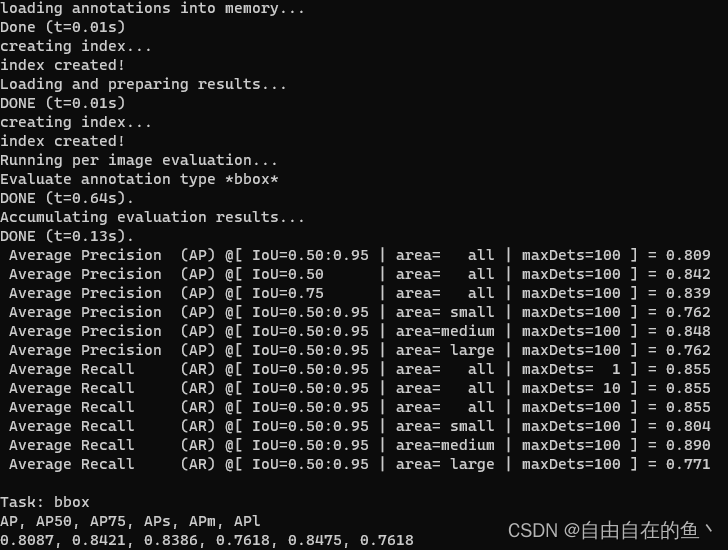
6. 讨论
在测试中发现pycocotools库计算出来的map值比yolov5 val.py计算出来的map值低,具体原因不清楚。
下列博客提供了一种讨论。
https://blog.csdn.net/qq_34062683/article/details/128907714