介绍
飞鱼(FlyFish)是云智慧开源的一款免费的数据可视化编排平台。通过简易的方式快速创建数据模型,通过拖拉拽的形式,快速生成一套数据可视化解决方案。在飞鱼产品中可以通过直接连接 MySQL 、 Oracle 等数据库直接从数据源中获取数据展示在可视化应用上,本文旨在为读者描述如何从数据源连接到数据展示在应用的步骤。
数据源类型
飞鱼(FlyFish)目前支持的数据源类型有如下几种。其中 MySQL、Postgres、ClickHouse、MariaDB、SqlServer、达梦、Oracle均为数据库,可以直接写sql获取数据。http数据源可以填写请求路径参数等信息,最终对返回的json结构做处理支持应用展示。

数据库类型数据
本篇文章以MySQL数据源为例,详细描述一下数据库类的数据源处理流程。
数据源创建
首先点击数据源管理页面的新建按钮,可以看到如下页面:
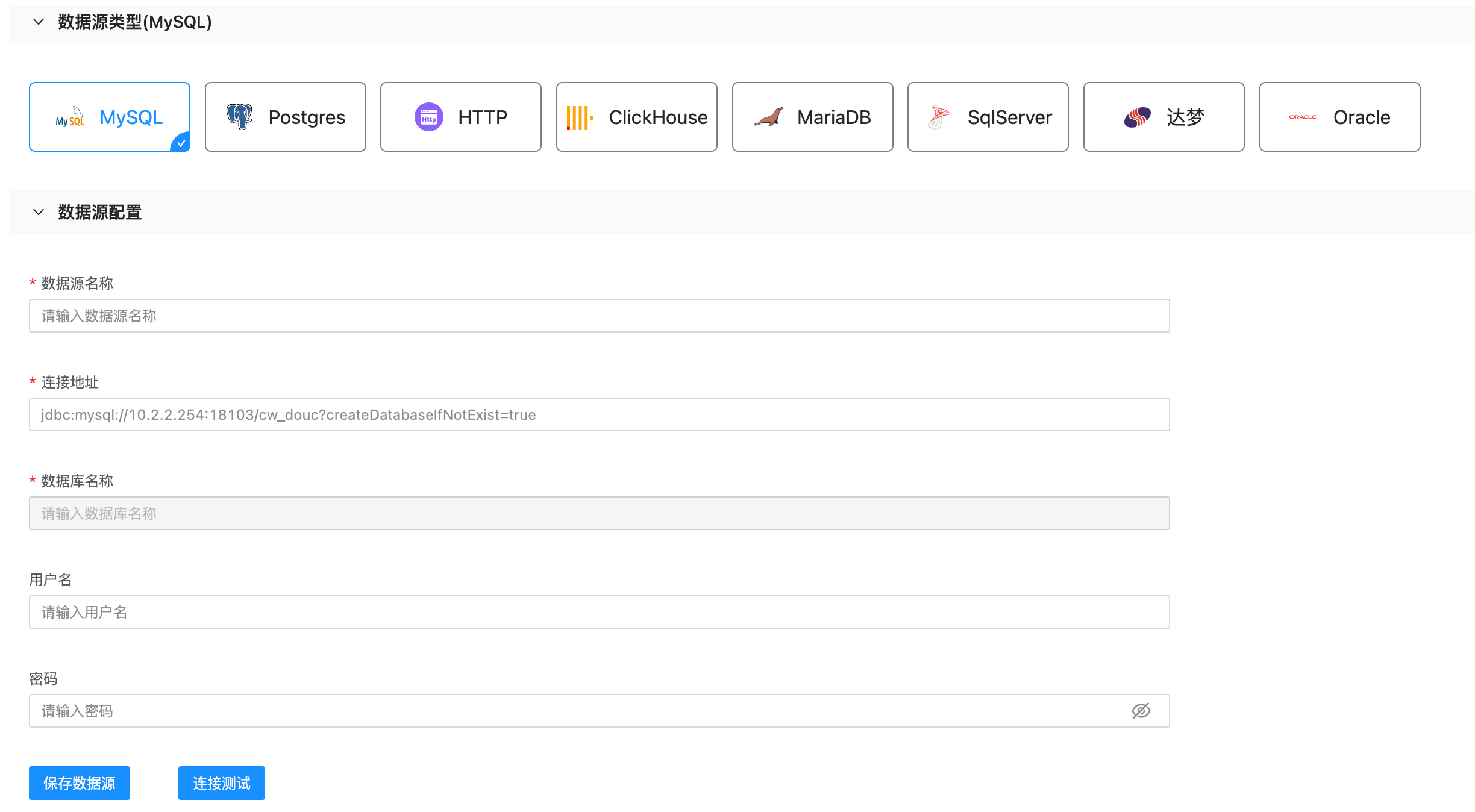
选中MySQL数据源类型,然后填写对应信息,其中具体信息含义如下:
- 数据源名称:为新创建的数据源命名以便创建成功后在列表中找到他。
- 连接地址:填写MySQL数据库的连接地址如图中示例,注意ip和端口号以及db名称的正确填写。
- 数据库名称:该值不需要填写,会从连接地址中自动解析。
- 用户名:连接MySQL数据库的用户名。
- 密码:连接MySQL数据库的用户名对应的用户密码。
需要注意的是,由于对于不同的数据库定位到一个db所需的配置不同,所以不同的数据库所要填写的值可能不同,例如Oracle数据库如果上述内容,还有Schema名称需要填写。
信息填写完成之后可以点击链接测试按钮,校验当前db是否可以成功链接。弹出如下图所示内容,则表示成功链接。

如果弹出如下图,说明当前db并没有连接成功,需要检查所填写的信息是否正确,以及是否是网络问题,比如部分用户的db只在自己的内网可以访问。

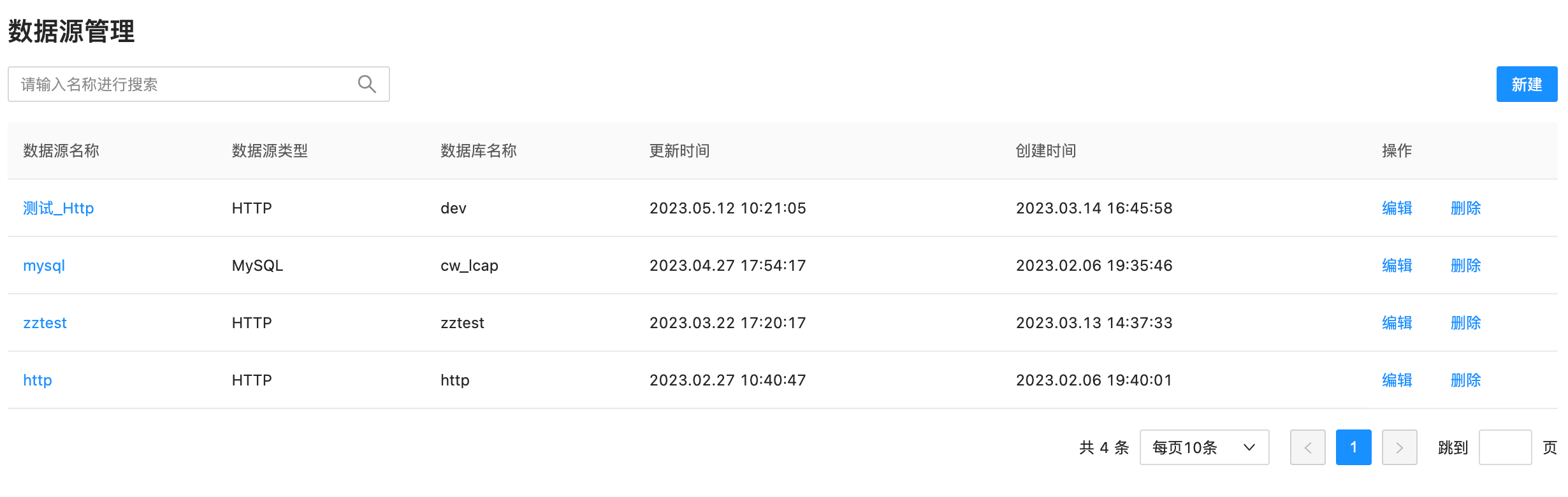
测试链接成功后,点击保存数据源按钮保存、设置好的数据源信息。可以点击编辑去更改数据源的信息,以及删除按钮去删除掉不想要的数据源。在列表上看到保存成功的数据源如下:
数据查询创建
创建好数据源只是、使用数据源的第一步,下一需要通过写SQL来获取所需内容。点击侧边栏的数据查询按钮来创建新的数据查询。点击新建基础查询按钮我们看到如下页面:

如果当前数据源过多,可以输入之前设置好的数据源名称来进行检索。选中之前添加好的数据源,可以看到所有的数据表信息会展示在页面上,如下图所示:

选中想要获取数据的表会跳转到书写SQL的页面,并且自动生成全表查询的SQL如下图所示:
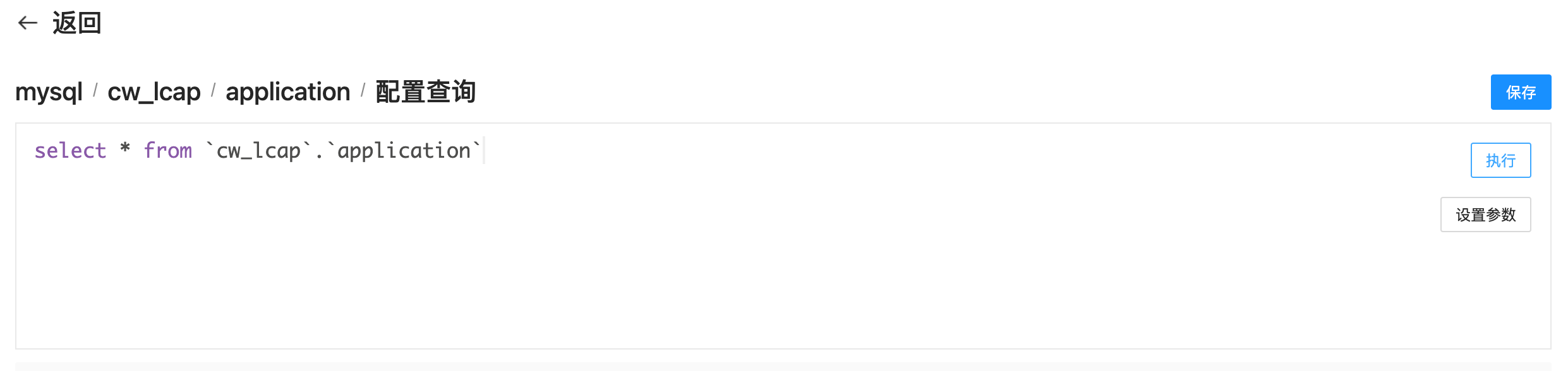
在这可以去书写想要实现的SQL语句,需要注意,这里并不是只限制查询当前选中的表,依然可以写其他的表名或者做关联查询。此外对于不同类型的数据源需要注意SQL语法,比如MySQL的语法和Oracle的语法就会有区别,需要根据数据源的类型书写可以识别的sql语句。写完SQL之后可以点击输入右上角的执行按钮,来执行编写的SQL语句,如下图所示:
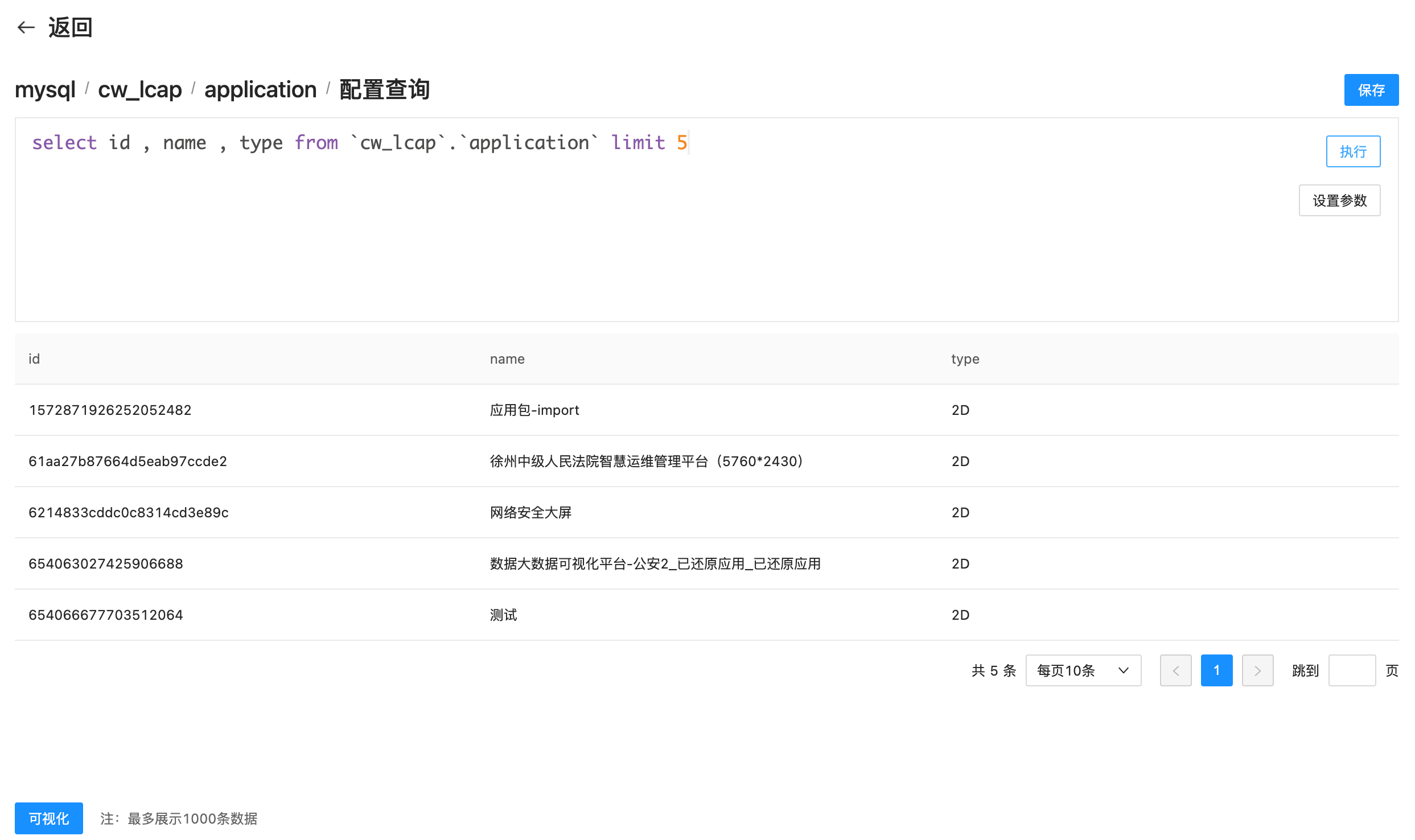
在输入框下面,可以看到当前SQL语句查询返回的数据信息,如果结果和预期不符可以继续更改SQL改成自己满意的效果。此外,输入框右上角还有一个设置参数的按钮。该按钮主要是为了解决SQL复用问题。举个例子,比如有两张大屏,一张需要id字段,另一张需要name字段,那么用户是不是需要写两句SQL呢?而设置参数就完美解决了这个问题,下面来看一下设置参数如何使用。
如下图可将我自己需要查询的字段设置为一个叫做param的参数,即使用{{}}将我想要设置的参数包裹起来:

然后点击设置参数按钮,系统会自动解析需要设置的参数如下图弹窗
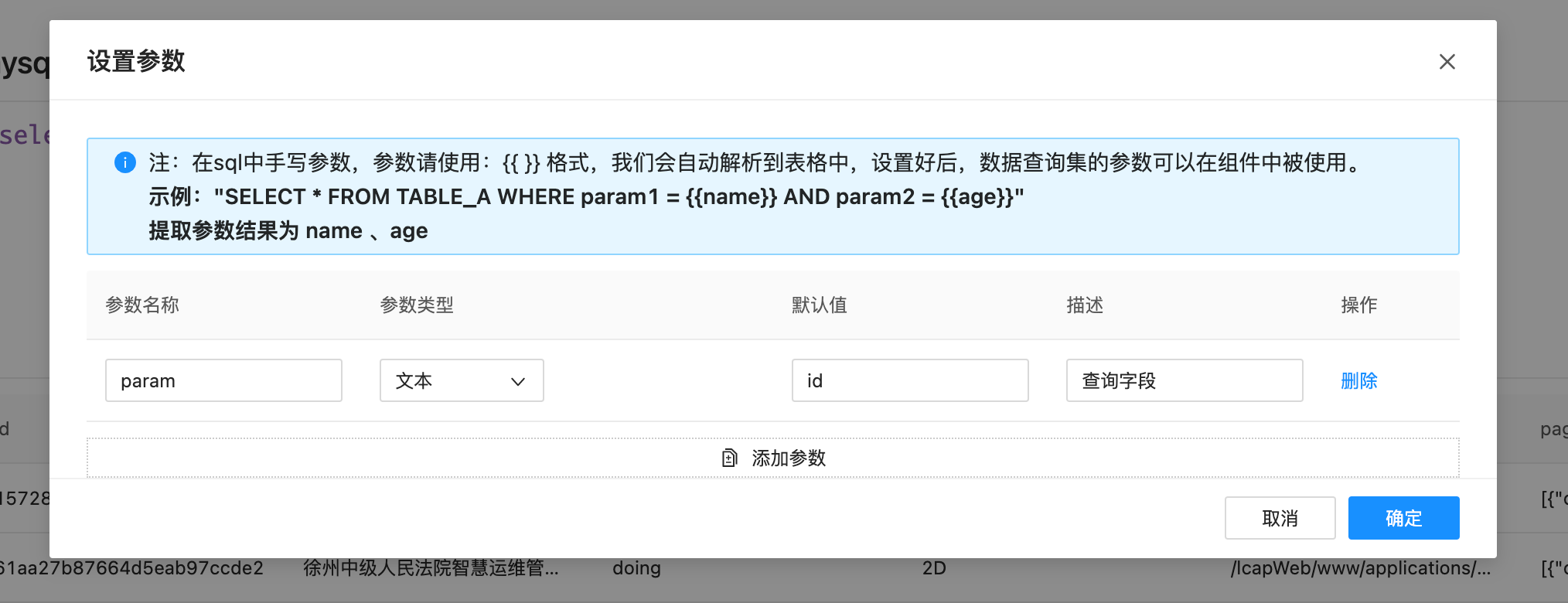
在这里设置这个参数的类型为:文本,然后默认值为:id,填写一个描述信息,然后点击确定。当再次点击执行按钮就会使用参数默认值,展示新的结果如下图:
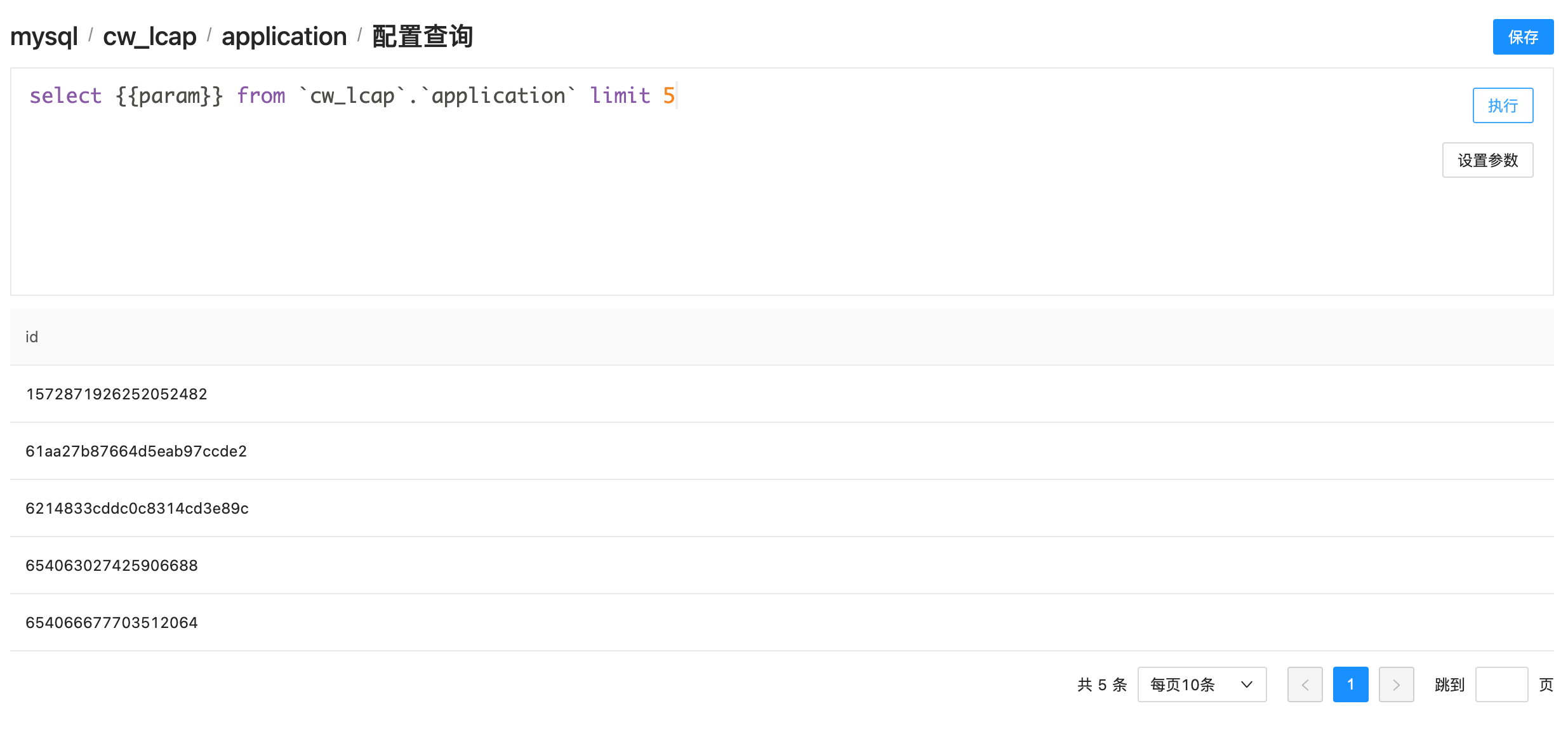
这个参数可以应用于语句的各个地方,查询字段、表名、查询条件等,开发者可以依据个人需求进行变量设置。后面会详细描述如何在大屏上怎么设置此类变量。
当调整好SQL语句点击页面右上角的保存,会出现如下弹窗:
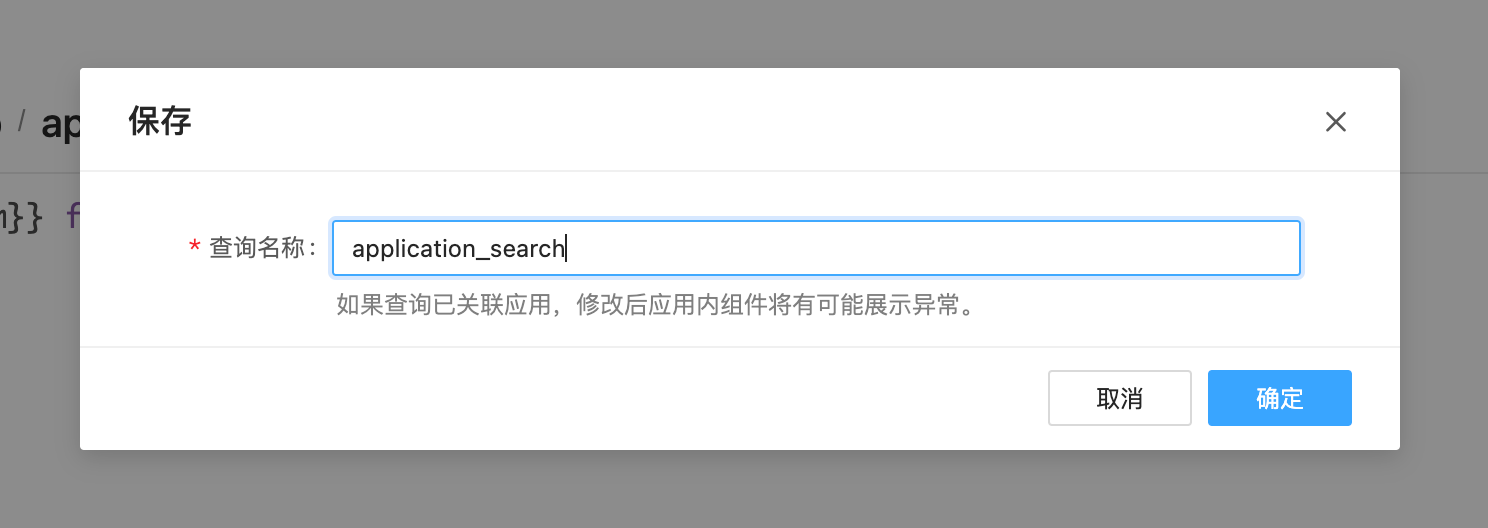
为查询起一个方便记忆的名字,是很好的选择,以便可以很快找到它。点击确定即保存成功。此时,在数据查询的列表页,便可以看到新建成功的数据查询,如下图所示。
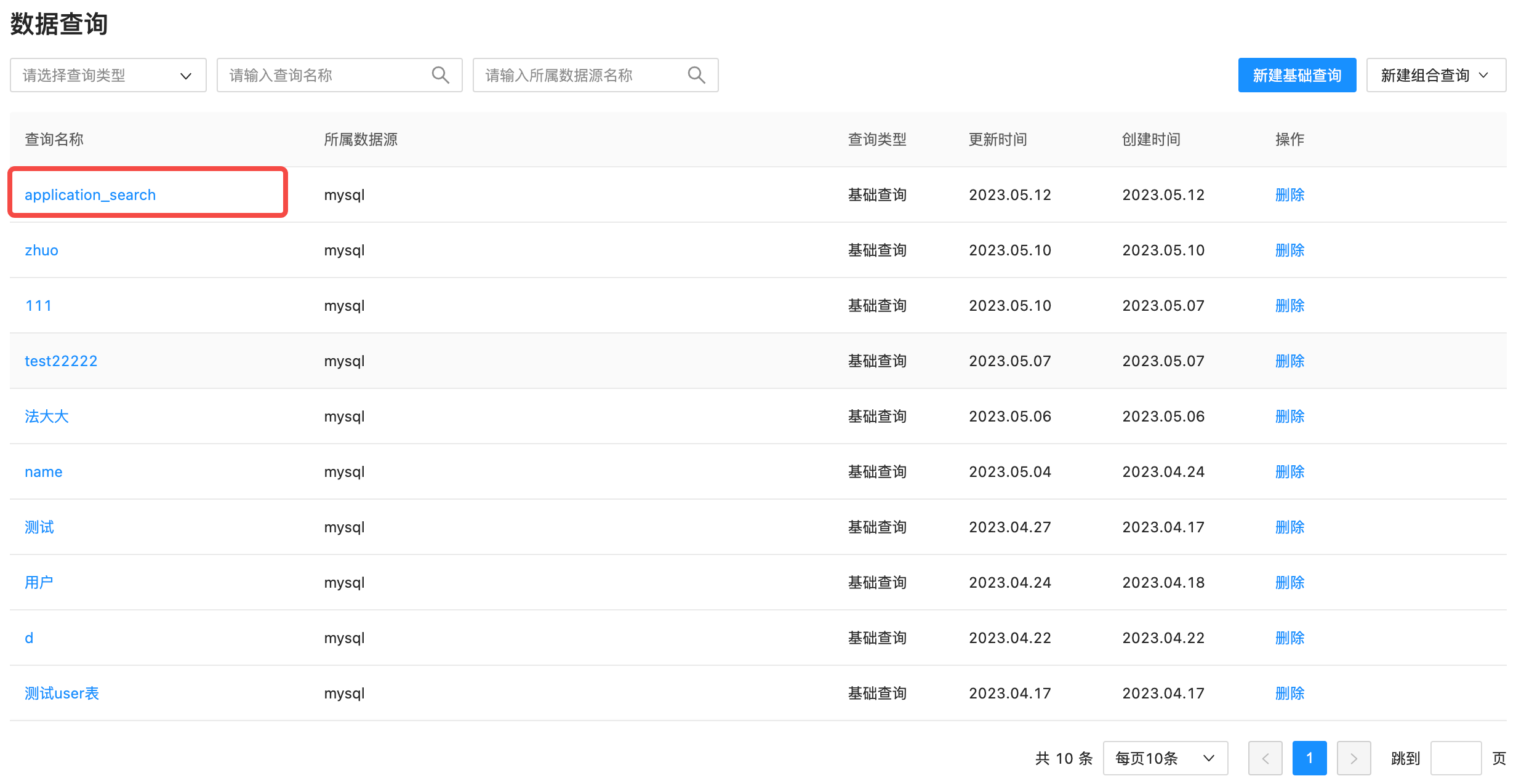
点击数据名称可以对数据查询进行编辑,需要注意的是,如果该数据查询已经应用于大屏组件,如果更改后返回结果与之前不一致,可能导致大屏展示异常。
数据查询的应用
接下来讲一下如何将已经配置好的数据查询应用于大屏。
从侧边栏点击到应用创建->应用开发,可以新创建一个应用或者在之前的应用中编辑,在应用上点击开发,进入如下开发页面:
以滚动列表图中组件为例。拖动一个滚动列表组件到编辑器然后选中该组件,在右侧边栏选中【数据】 ,然后在数据类型下拉选中选中【数据查询】,之后在数据查询输入框中输入之前命名好的数据【查询名称】,在搜索结果中选中它,可以发现之前设置的参数也会同时展示在下面,这个时候就可以去更改参数的值,如下图所示:

上图中可以看到当选中之前创建的数据查询,然后将参数值改为name,点击应用后就可以看到组件上展示的信息已经变更为name字段的信息。然后进行应用的保存即可。至此完成数据源从配置到应用的全部流程。
http类型数据
http数据源区分于数据库类的数据源添加的时候有自己单独的逻辑。
数据源创建
在数据源列表页面,点击新建按钮然后选中数据源类型为http看到如下界面:
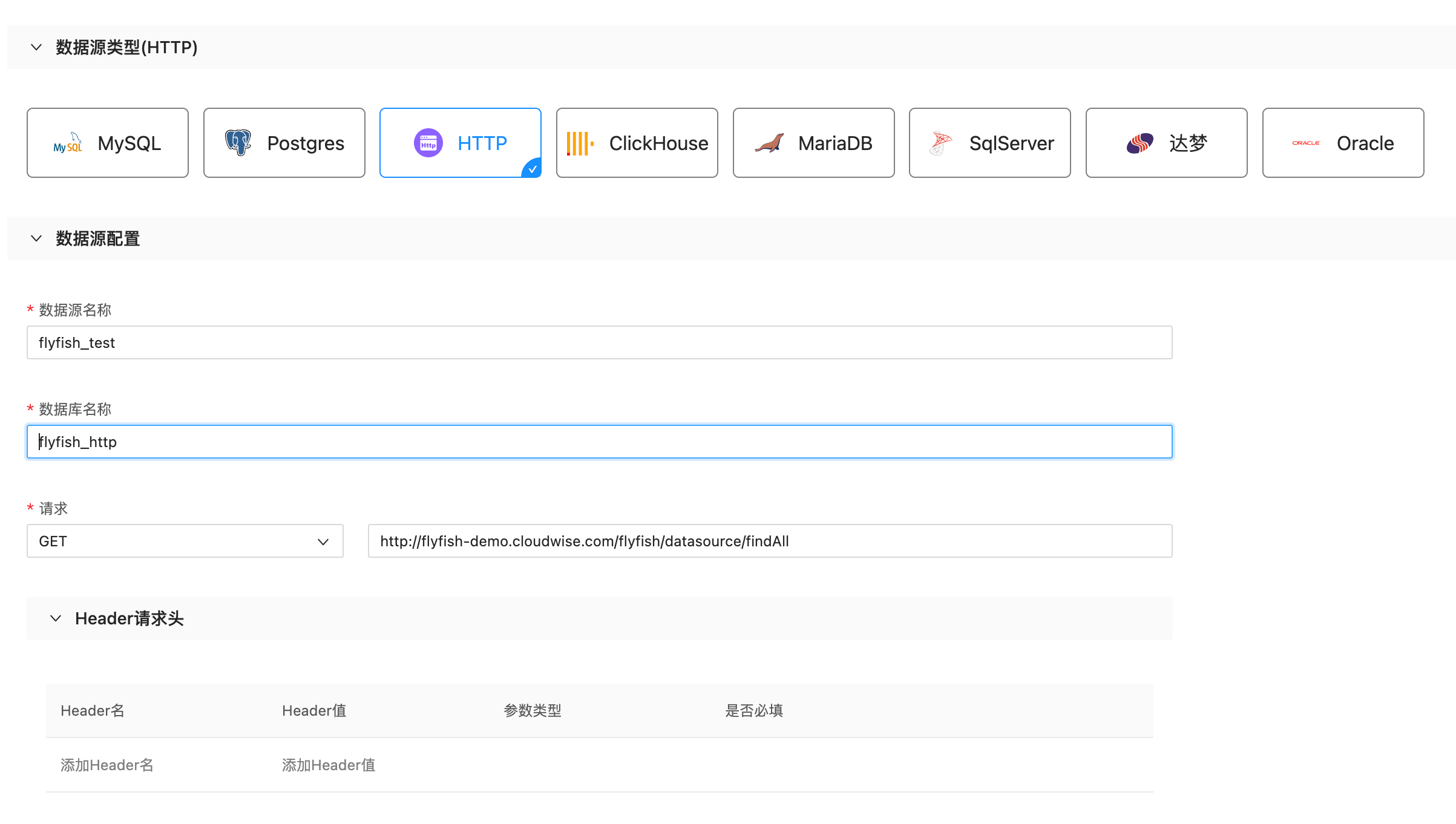
字段解释:
- 数据源名称:自定义新增数据源的名称,符合要求即可。
- 数据库名称:定义一个数据库的名称,用于后面的sql加工。
- 请求:下拉选选择请求类型,然后在后面的地址栏填写对应的路径。
- header请求头:填写该请求的header信息。
- 请求参数:填写该请求的参数信息。
- 请求体:填写请求体信息。
全部填写完成后点击保存数据源即可保存成功。需注意当前数据源在后面数据查询的创建时会被当做一个db处理,所以数据库名名称会出现在SQL的查询语句中,这里的命名需要符合对应的规则。
数据表创建
回到数据源列表页面,找到新建的数据源点击进入数据源详情页面,如下图所示:
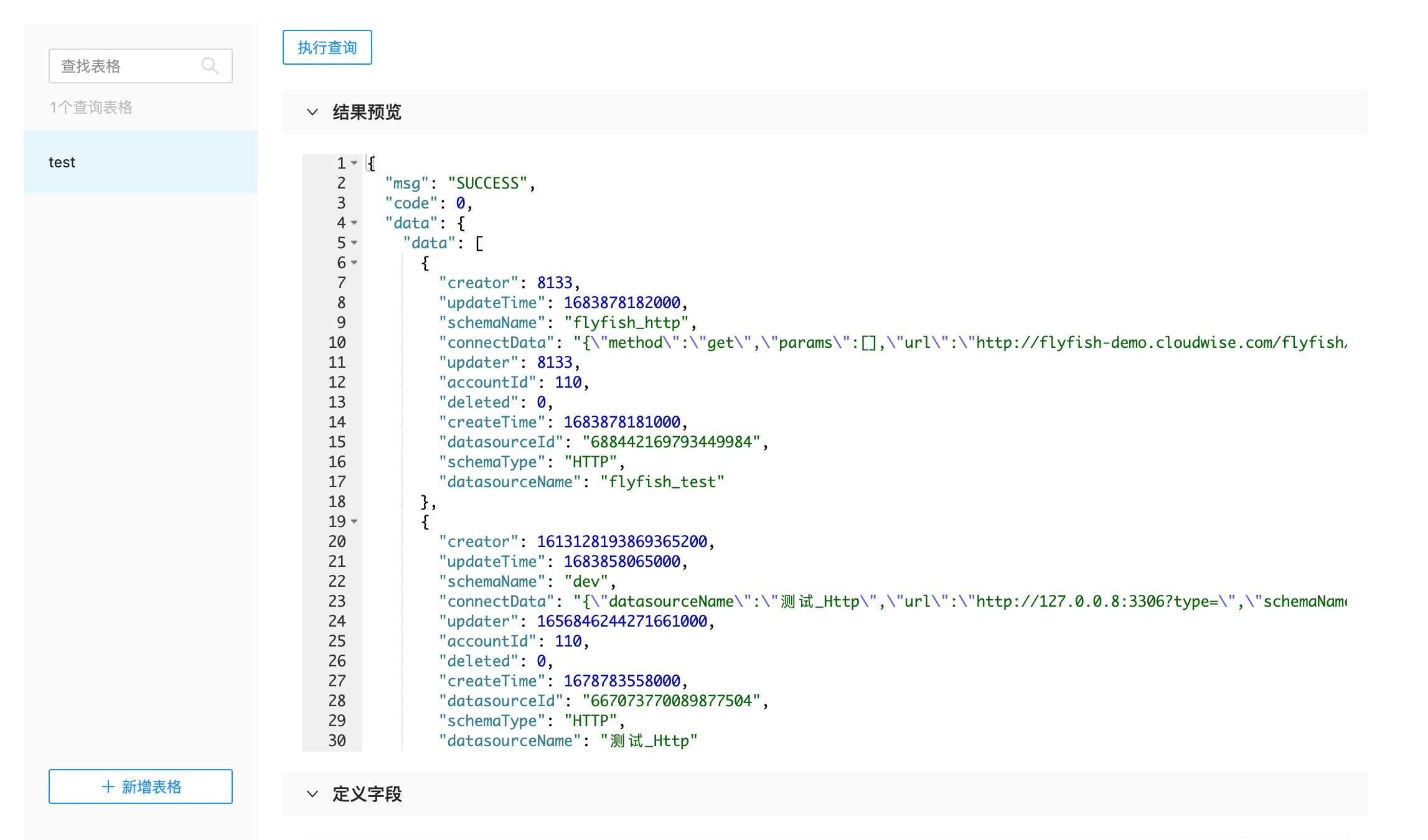
点击左下角的新增表格,然后输入自定义的数据表的名称,点击回车即可开始建表。这里可以理解为数据库的建表,便于后续做SQL加工建表过程中,会把数据源的header及参数信息回显在这里,然后点击执行查询按钮,可以在结果预览中看到请求返回的数据如上图所示。随后可以开始对返回的信息做字段定义来进行json抽取,点击定义字段下面的添加按钮,看到如下弹窗:
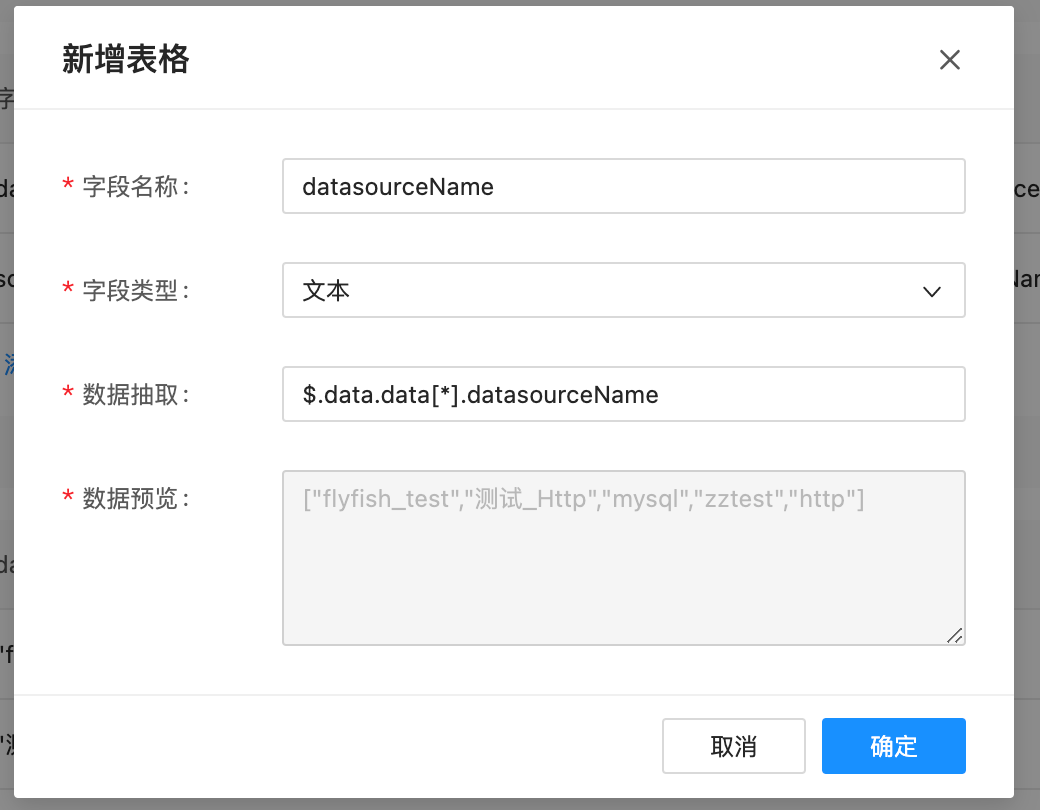
字段解释:
- 字段名称:定义一个字段名称,可以理解为数据库中的列名,用于后续sql加工
- 字段类型:下拉选选择字段的类型
- 数据抽取:填写jsonpath路径,用于提取json中的数据。
- 数据预览:在填写jsonpath的过程中会实时展示当前jsonpath提取到的信息
对于jsonpath的具体用法可参考:https://blog.csdn.net/software_test010/article/details/125427926,在数据预览中看到已提取到所需数据之后,点击确定来保存当前字段的设置。提取到所需字段会有类似数据库的行列展示如下图:
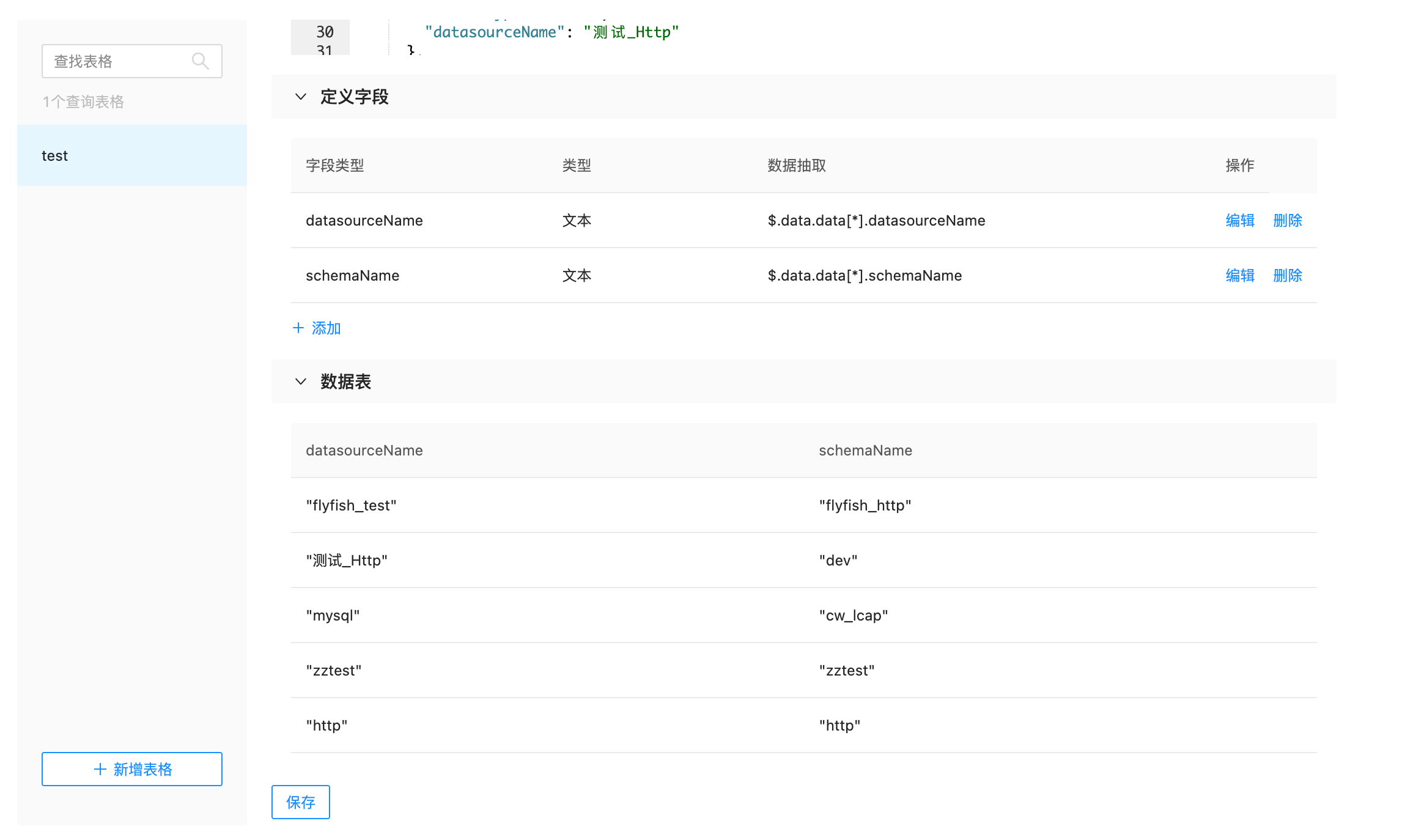
图中数据表的展示信息即当前数据表最终拿到的结果,点击保存即可。重复上面步骤可以对同一数据源创建多张数据表,即对返回的结果进行不一样的字段抽取来解决请求复用问题。
数据查询创建
创建数据查询的过程与数据库类似,可参考之前段落。
点击新建数据查询,选择已经创建的数据源,以及创建的数据表,然后编写SQL,如下图:
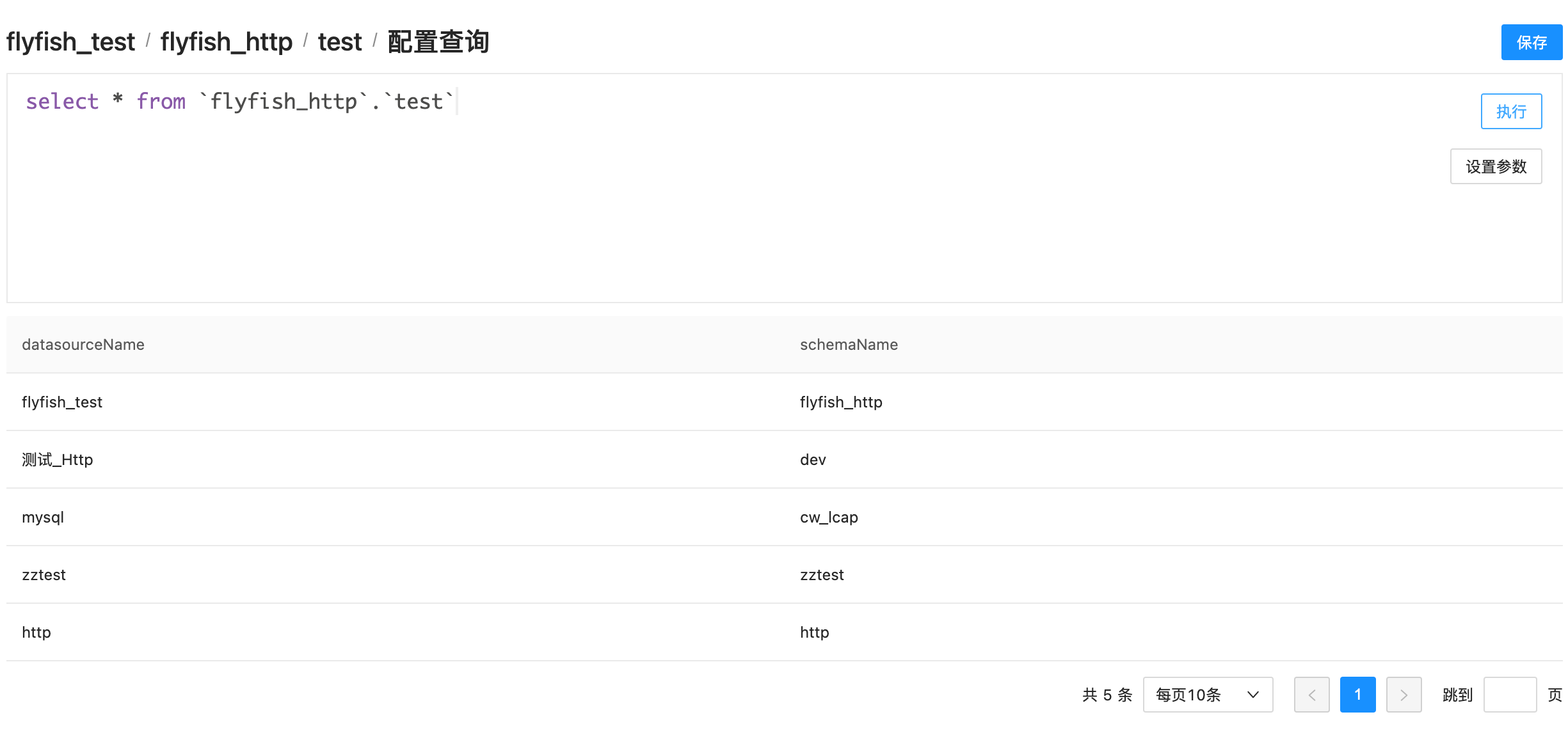
需要注意的是,这里是不支持连表查询,由Http数据源创建的数据表只能在单表中查询。此外,上述使用的是Spark的SQL语法,底层是使用Spark引擎进行SQL分析和处理的,书写SQL时需要注意。
设置参数的操作以及如何将数据查询应用在组件上进行展示在上文中已经描述过,此处不再赘述。
结语
开源数据可视化编排平台FlyFish是一款功能强大且易于使用的数据可视化工具,能够帮助用户将大量的数据转化为直观、易于理解的图表和图形。作为一个全面的数据可视化解决方案,该平台不仅提供了丰富的可视化选项,还支持多种数据源的应用技术。
至此,相信各位开发者对如何在FlyFish平台新增数据源,以及如何在数据源中获取自己想要的数据并应用于组件中,应该有了大致的了解。心动不如行动,点击下方链接,快来通过FlyFish搭建属于自己的一套数据可视化大屏吧!
GitHub 地址: https://github.com/CloudWise-OpenSource/FlyFish
Gitee 地址: https://gitee.com/CloudWise/fly-fish
FlyFish 贡献指南: http://bbs.aiops.cloudwise.com/d/717-flyfish
FlyFish 模版中心: https://www.cloudwise.ai/flyFishComponents.html