文章目录:
- c++11简介
- 统一的列表初始化
- {}初始化
- std::initializer_list
- 声明
- auto
- decltype
- nullptr
- 范围for循环
- STL中的一些变化
- array
- forward_list
- unordered_map和unordered_set
- 字符串转换函数
c++11简介
- 在2003年C++标准委员会曾经提交了一份技术勘误表(简称TC1),使得C++03这个名字已经取代了C++98称为C++11之前的最新C++标准名称。
- 不过由于C++03(TC1)主要是对C++98标准中的漏洞进行修复,语言的核心部分则没有改动,因此人们习惯性的把两个标准合并称为C++98/03标准。
- 从C++0x到C++11,C++标准10年磨一剑,第二个真正意义上的标准珊珊来迟。相比于C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。
- 相比较而言,C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率,公司实际项目开发中也用得比较多。
在这里只对部分c++11的语法进行讲解,若需要了解更多的语法,可以查看c++的官网:https://en.cppreference.com/w/cpp/11。
小故事:
1998年是C++标准委员会成立的第一年,本来计划以后每5年视实际需要更新一次标准,C++国际标准委员会在研究C++ 03的下一个版本的时候,一开始计划是2007年发布,所以最初这个标准叫C++ 07。但是到06年的时候,官方觉得2007年肯定完不成C++ 07,而且官方觉得2008年可能也完不成。最后干脆叫C++ 0x。x的意思是不知道到底能在07还是08还是09年完成。结果2010年的时候也没完成,最后在2011年终于完成了C++标准。所以最终定名为C++11。
统一的列表初始化
{}初始化
在 c++98 中,标准允许适用花括号 {} 对数组或者结构体元素进行统一的列表初始值设定。比如:
struct Point {
int _x;
int _y;
};
int main()
{
// 使用{}对数组进行初始化
int array1[] = { 1,2,3,4,5,6,7 };
int array2[7] = { 0 };
// 适用{}对结构体元素进行初始化
Point p = { 5,7 };
return 0;
}
在 c++11 中,扩大了用大括号 {} 括起的列表(初始化列表)的使用范围,使其可以用于所有的内置类型和用户自定义的类型。使用初始化列表时,可以选择添加等号(=),也可以选择省略。
struct Point {
int _x;
int _y;
};
int main()
{
// 自定义类型初始化
int x = { 10 };
double f = { 3.14 };
// 用户自定义初始化
Point p1 = { 3,5 };
// 使用等号的初始化列表
int y = { 5 }; // -> int y = 5
Point p2 = { x = 3,y = 7 }; // 可以使用等号指定成员变量的初始化
// 省略等号的初始化列表
int z{ 7 }; // -> int z = 7
Point p3{ (3,1),(5,8)};
// c++11中列表初始化也可以用于new表达式(c++98不可用)
int* p1 = new int[5]{ 0 };
int* p2 = new int[5]{ 1,2,3,4,5 };
return 0;
}
在 c++11 及之后的标准中,创建对象时也可以使用初始化列表的初始化方式调用构造函数进行初始化。
class Date
{
public:
Date(int year = 2025, int month = 1, int day = 1)
:_year(year)
, _month(month)
, _day(day)
{
cout << "Date(int year, int month, int day)" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
// c++11指出的列表初始化,这里会调用构造函数初始化
Date d1 = { 2023,5,10 };
Date d2{ 2023,5,11 };
Date d3{ (2023,5,13),(2023, 5, 12) };
// 更多的示例
std::vector<int> v = { 1,2,3,4,5,6,7 };
std::pair<int, std::string> myPair = { 1,"test" };
std::map<int, std::string> myMap = { {1,"onw"},{2,"two"} };
return 0;
}
注意:使用列表初始化方式调用构造函数时,如果构造函数参数列表与提供的初始化列表不匹配,会导致编译错误。因此,确保构造函数的参数与初始化列表的类型和数量相匹配非常重要。
std::initializer_list
c++11 中引入了 std::initializer_list ,它是一种特殊的模板类,用于表示初始化列表。它提供了一种便捷的方式来传递和处理任意数量的值。std::initializer_list 可以用于函数的参数和构造函数的参数,使得函数和构造函数能够接受任意数量的值作为初始化参数。
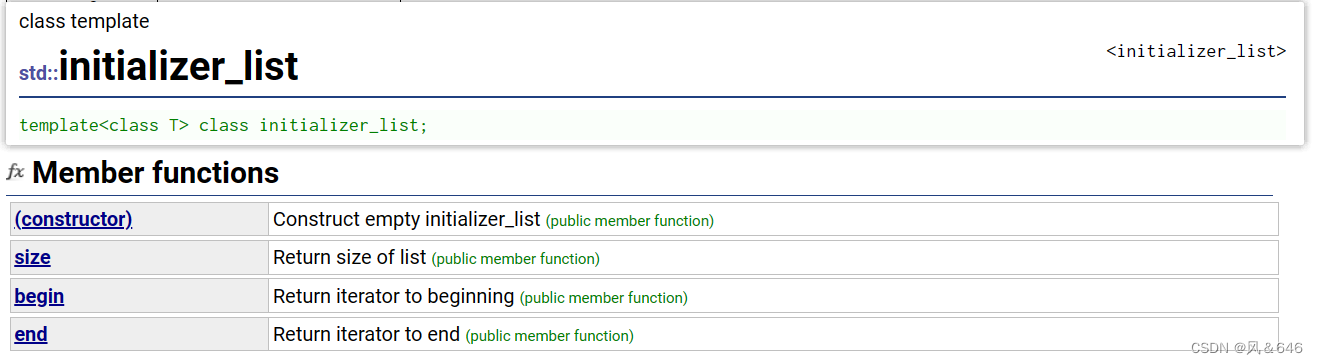
std::initializer_list 的成员函数如下:
begin():返回一个指向初始化列表第一个元素的迭代器。end():返回一个指向初始化列表最后一个元素的下一个位置的迭代器。size():返回初始化列表中的元素个数。
成员变量使用示例:
#include <initializer_list>
#include <iostream>
using namespace std;
int main()
{
initializer_list<int> nums = { 1,2,3,4,5,6,7 };
// 使用begin()和end()进行迭代器遍历
for (auto it = nums.begin();it != nums.end();++it)
cout << *it << " ";
cout << endl;
// 使用范围for进行遍历
for (const auto& num : nums)
cout << num << " ";
cout << endl;
// 使用size()获取元素个数
cout << "size:" << nums.size() << endl;
return 0;
}
使用 auto 关键字定义一个遍历变量来接收一个大括号括起来的列表时,变量的类型将被推导为 std::initializer_list:
#include<initializer_list>
#include<iostream>
#include<typeinfo>
int main()
{
auto il = { 10,20,30 };
std::cout << typeid(il).name() << std::endl;
return 0;
}
运行结果如下:

initializer_list 的使用:在以下代码中,PrintValues 函数和 Print 的构造函数都接受 std::initializer_list 作为参数。这使得我们可以通过 {} 将值传递给函数或构造函数,而不需要显示地创建和填充一个容器。
// 函数接受初始化列表作为参数
void PrintValues(initializer_list<int> values)
{
for (const auto& value : values)
cout << value << " ";
cout << endl;
}
// 类的构造函数接受初始化列表作为参数
class Print
{
public:
Print(initializer_list<int> values)
{
for (const auto& val : values)
cout << val << " ";
cout << endl;
}
};
int main()
{
// 使用初始化列表调用函数
PrintValues({ 1, 2, 3, 4, 5, 6, 7 });
// 使用初始化列表调用构造函数
Print p = { 5,4,3,2,1,0 };
return 0;
}
c++98 中不支持直接使用列表对容器进行初始化,在 c++11 后引入了 initializer_list 之后才支持的。
在 c++11 中,为了支持使用列表进行容器的初始化,相应的容器类型增加了构造函数,这些构造函数接受 std::initializer_list 作为参数。通过这个构造函数,容器便可以接受列表中的值进行初始化。
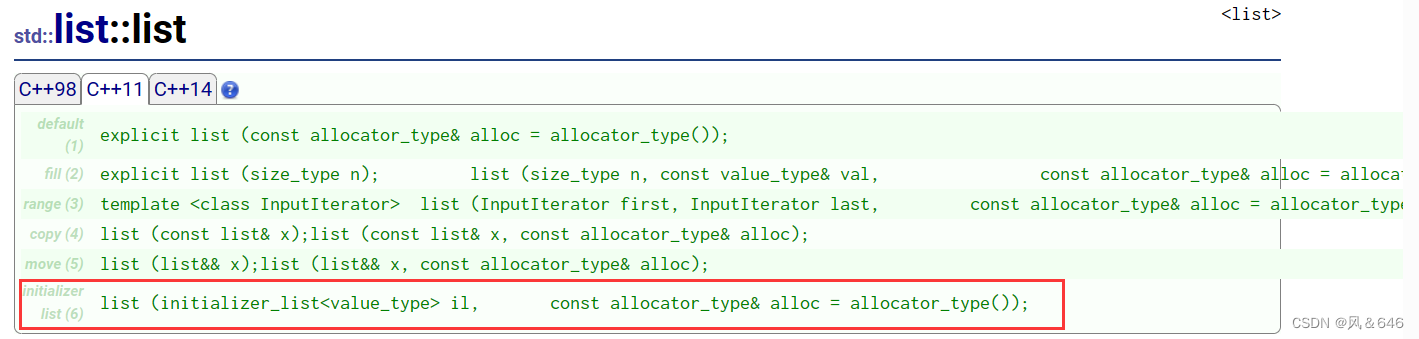
http://www.cplusplus.com/reference/vector/vector/vector/
http://www.cplusplus.com/reference/map/map/map/
http://www.cplusplus.com/reference/vector/vector/operator=/
当使用列表对容器进行初始化时,编译器会识别列表为 std::initializer_list 类型,并调用容器的相应构造函数来进行初始化。
在C++11中,容器类型(如std::vector、std::map等)为了支持使用列表进行初始化,添加了接受 std::initializer_list 作为参数的构造函数。这个构造函数的作用是遍历 std::initializer_list 中的元素,并将它们依次插入到要初始化的容器中。
使之前模拟显示的 vector 也支持 {} 初始化和赋值
namespace myVector
{
template<class T>
class vector {
public:
typedef T* iterator;
// 使用 initializer_list 进行初始化
vector(initializer_list<T> l)
{
_start = new T[l.size()];
_finish = _start + l.size();
_endofstorage = _start + l.size();
iterator vit = _start;
/*typename initializer_list<T>::iterator lit = l.begin();
while (lit != l.end()
{
*vit++ = *lit++;
}*/
for (auto e : l)
*vit++ = e;
}
// 使用 initializer_list 进行赋值操作
vector<T>& operator=(initializer_list<T> l)
{
// 创建临时 vector 对象进行初始化
vector<T> tmp(l);
// 交换当前 vector 和临时 vector 的资源
std::swap(_start, tmp._start);
std::swap(_finish = tmp._finish);
std::swap(_endofstorage, tmp._endofstorage);
return *this;
}
private:
iterator _start;
iterator _finish;
iterator _endofstorage;
};
}
- 构造函数通过遍历初始化列表,将列表中的元素逐个赋值给容器,完成了容器的初始化操作。
- 赋值操作符重载函数通过创建临时的
vector对象来进行赋值操作,通过交换资源的方式实现了赋值的语义,从而完成了容器的赋值操作。
声明
auto
在 c++98 中,auto 是一个存储类型的说明符,用于表示变量具有局部自动存储类型。然而,在局部作用域中定义局部的变量默认就是自动存储类型,所以 auto 就没有什么价值了。
在 c++11 中,auto 关键字的用法发生了变化,废除了 auto 原本的用法。auto 被重新定义为一个用于类型推导的关键字。现代的 c++ 开发中,auto 主要用于声明变量时推导其类型,而不是用于存储类型的说明。
使用 auto 进行类型推断时,要求进行显示初始化,让编译器根据初始值来确定变量的类型。并将其设置为相应的类型,这样可以简化代码的书写,减少类型重复,提高代码的可读性。
auto 使用示例:
class Print
{};
int main()
{
auto x = 7; // x的类型被推导为int
auto str = std::string("abc"); // str的类型被推到为std::string
auto ptr = new Print(); // ptr的类型被推导为Print
int i = 9;
auto p = &i;
auto pf = strcpy;
cout << typeid(p).name() << endl;
cout << typeid(pf).name() << endl;
map<string, string> dict = { {"sort","排序"},{"insert","插入"} };
auto it = dict.begin();
return 0;
}
自动类型推导可以减少代码中的重复和冗余,提高代码的可读性和可维护性。它还可以帮助我们避免手动指定类型可能导致的错误,提高代码的安全性和可靠性。
自动类型推导在某些场景下还是非常必要的,因为编译器要求在定义变量时必须先给出变量的实际类型,若我们自己指定,某些场景下可能会出现问题,如下:
int main()
{
short a = 32000;
short b = 32000;
short c = a + b;
return 0;
}
在上述示例中,由于 a 和 b 都是 short 类型,它们相加的结果可能会超出 short 类型的范围,导致数据丢失。若我们手动将 c 声明为 short 类型,就会发生截断错误。这时,使用自动类型推导就可以解决这个问题。可以将 short c = a + b 改为 auto c = a + b。编译器根据表达式的结果推导实际类型,以确保数据不会丢失。
注意:在一些情况下,显示指定类型是必要的,特别是当需要精确控制变量的类型或避免意外的类型转换时。在使用自动类型推导时,需要注意代码的清晰性和可读性。
decltype
关键字 decltype 将变量的类型声明为表达式指定的类型。
decltype 的语法形式为 decltype(expression),其中 expression 是要推断的类型的表达式。
template<class T1, class T2>
void func(T1 t1, T2 t2)
{
decltype(t1 * t2) ret;
cout << typeid(ret).name() << endl;
}
int main()
{
const int x = 1;
double y = 8.7;
decltype(x * y) ret;
decltype(&x) p;
cout << typeid(ret).name() << endl; // double
cout << typeid(p).name() << endl; // int const *
func(1, 'a'); // int
func(3, 5.5); // double
return 0;
}
decltype 除了能够推断表达式的类型,还能推断函数的返回值类型以及指定函数的返回类型。
template<class T1, class T2>
// 推导函数的返回值类型
auto foo(T1 x, T2 y)
{
return x + y;
}
template<class T1, class T2>
// 指定函数的返回类型
auto mul(T1 x, T2 y)
{
decltype(x * y) ret;
ret = x * y;
cout << typeid(ret).name() << endl;
return ret;
}
int main()
{
decltype(foo(1, 2)) ret1;
cout << typeid(ret1).name() << endl; // int
decltype(foo(1.1, 2.2)) ret2;
cout << typeid(ret2).name() << endl; // double
decltype(mul(4, 5)) ret3;
cout << typeid(ret3).name() << endl; // int
decltype(mul(4.4, 5.5)) ret4;
cout << typeid(ret4).name() << endl; // double
return 0;
}
decltype 在泛型编程和模板元编程中特别有用,它可以推断出表达式的准确类型,从而进行类型转换,类型推导和模板类型参数的推导。它使得代码更加灵活和通用,可以处理多种类型的表达式。
nullptr
由于 c++ 中 NULL 被定义成字面量 0,这样就可能带来一些问题,因为 0 既能表示指针常量,又能表示整形常量。出于清晰和安全的角度考虑,c++11 中新增了 nullptr,用于表示空指针。
/* Define NULL pointer value */
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else /* __cplusplus */
#define NULL ((void *)0)
#endif /* __cplusplus */
#endif /* NULL */
以下是使用 nullptr 的一些示例:
// 通过函数返回值表示失败
int* findElement(int element) {
// 模拟查找的过程,假设没有找到元素
return nullptr;
}
int main()
{
int* p1 = nullptr; // 指向整形的空指针
char* p2 = nullptr; // 指向字符的空指针
void* p3 = nullptr; // 指向void的空指针
if (p1 == nullptr) {
// 执行一些操作
}
int* result = findElement(78);
if (result == nullptr)
{
// 没有找到元素,执行对应操作
}
return 0;
}
大部分情况下使用 NULL 也不会出现什么问题,但是在一些特殊场景下用 NULL 来表示空指针就有可能会出现问题,如下:
void f(int elem)
{
cout << "void f(int elem)" << endl;
}
void f(int* p)
{
cout << "void f(int* p)" << endl;
}
int main()
{
f(NULL); // -> void f(int elem
f(nullptr); // -> void f(int* p)
return 0;
}
该例子说明了使用 NULL 可能会导致函数重载的匹配错误。因为 NULL 实际上是一个整数值,它可以匹配整数类型的重载函数,而不仅仅是指针类型的重载函数。这可能会导致意外的函数调用和行为。使用 nullptr 可以明确地选择匹配指针类型的重载函数,并避免潜在的匹配错误。
范围for循环
在 c++98 中要遍历一个数组,可以使用如下方式:
#include<iostream>
#include<vector>
using namespace std;
int main()
{
vector<int> nums = { 1,2,3,4,5,6,7 };
for (int i = 0;i < nums.size();i++)
cout << nums[i] << " ";
cout << endl;
return 0;
}
对于一个有范围的集合,基于范围 for 循环可以更简洁和直观地遍历元素,避免了手动管理索引或迭代器的复杂性。
范围 for 循环的语法形式如下:
for(element_declaration:sequence)
{
// 循环体
}
其中,element_declaration 是要在每次循环中声明的变量,用于存储序列中的元素值。sequenct 是要遍历的序列,可以是容器、数组或其它可迭代对象。
示例:使用范围 for 循环遍历容器的元素。
#include<iostream>
#include<vector>
using namespace std;
int main()
{
vector<int> nums = { 1,2,3,4,5,6,7 };
// 将nums中的每个元素值乘2
for (auto& e : nums)
e *= 2;
for (int num : nums)
cout << num << " ";
cout << endl;
return 0;
}
范围 for 的使用条件:
范围 for 的迭代器对象必须是一个序列容器或类,并且提供 begin() 和 end() 函数来返回迭代器的范围,迭代器类型需要支持后置递增、前置递增和解引用操作符。
STL中的一些变化
c++11 标准引入了四个新的容器,它们分别是:array、forward_list、unordered_map 和 unordered_set。这些容器提供了不同的功能和性能特点,丰富了 c++ 标准库的容器选项,使得开发人员能够实际的开发场景来选择合适的容器类型。
array
array 是一个固定大小的数组容器,提供了类似于原生数组的功能,但具有更多的优势和便利性。
std::array 容器的特点:
- 固定大小:创建
array时,需要指定容器的大小使其固定。这使得array具有确定的容量,并在内存中以连续的方式存储。 - 安全性:
array提供了边界检查,确保在访问元素时不会越界。它提供了at()成员函数和重载的operator[],可以安全的访问和修改元素。 - 接口与原生数组兼容:
array支持使用下标访问元素,提供了类似于原生数组的语法和功能。 - 支持迭代器:
array提供了迭代器,允许以迭代器的方式遍历容器中的元素。 - 内置函数和算法支持:
array支持标准库的算法和内置函数。

array 容器有两个模板参数,第一个模板参数表示存储类型,第二个模板参数是一个非类型模板参数,代表数组中存储元素的个数,即 array 数组的大小。
#include<iostream>
#include<array>
int main()
{
array<int, 20> a1; // 定义一个可存储20个整形元素的array容器
array<double, 10> a2; // 定义一个可存储10个浮点数元素的array容器
return 0;
}
使用 array 可以替代原生数组,并获得更好的安全性和性能。它在需要固定大小数组的场景中比较有用。但是,array 的大小是固定的,因此不适合定义过大的数组。
forward_list
c++11 中的 forward_list 实际上是单向链表(singly linked list)的一种实现。

std::forward_list 具有以下特点:
- 单向链表:它是由节点组成的单向链表,每个节点中包含一个元素和指向下一个节点的指针。
- 前向迭代器:forward_list 允许从链表的开头到末尾顺序遍历元素。但不支持反向迭代器。
- 节省内存:单向链表只需要一个指针来连接节点,forward_list 的内存消耗低于双向链表。
- 不支持随机访问:不支持随机访问元素,无法直接访问任意位置的元素。需要访问元素只能从头开始遍历。
总结:forward_list 在插入和删除操作频繁、不需要随机访问元素的场景下具有优势。但是在需要经常查找元素或访问元素的情况下,性能可能不如支持随机访问的容器。如:vector、list等。因此,需要根据具体的场景来选择合适的容器。
unordered_map和unordered_set
std::unordered_map 和 unordered_set 是 c++11 引入的无序关联容器,它们是基于哈希表实现的容器。
unordered_set文档介绍
unordered_map文档介绍
它们有以下特点:
- 无序性:因为它们的底层是使用哈希表实现,元素的存储和访问是无序的。这使得在无需保持元素有序的场景下,可以获得高效率的插入、查找和删除操作。
- 高效查找、插入和删除操作:unordered_map 和 unordered_set 中插入,查找和删除元素的时间复杂度接近于O(1)。具体性能取决于哈希函数的质量和哈希表的负载因子。
- 基于键值的存储和查找:unordered_map 是键值对的集合,每个元素包含一个键和一个关联的值;unordered_set 是值的集合。它们可以通过键或值进行快速存储和查找。
- 哈希冲突可能影响性能:由于哈希表的特性,不同的键可能映射到相同的哈希桶,这就是哈希冲突。当哈希冲突过多时,可能会导致性能下降,因为需要处理冲突。为了减少哈希冲突,可优化哈希函数的设计和调整容器的负载因此。
unordered_map 使用示例:
#include<iostream>
#include<string>
#include<unordered_map>
using namespace std;
int main()
{
unordered_map<string, string> dict;
dict.insert(make_pair("sort", "排序"));
dict.insert(make_pair("map", "地图"));
dict.insert(make_pair("right", "右,正确的"));
// 查找词库中某个单词含义
cout << "sort:" << dict["sort"] << endl;
// 遍历
for (const auto& e : dict)
cout << e.first << ":" << e.second << endl;
// 删除元素
dict.erase("right");
return 0;
}
unordered_set 使用示例:
#include<iostream>
#include<unordered_set>
#include<string>
using namespace std;
int main()
{
unordered_set<int> set;
set.insert(1);
set.insert(3);
set.insert(5);
// 查找元素
if (set.find(3) != set.end())
cout << "Element found" << endl;
// 遍历元素
for (const auto& e : set)
cout << e << " ";
cout << endl;
// 删除元素
set.erase(3);
return 0;
}
字符串转换函数
c++11 中提供了各种内置类型与 string 之间相互转换的函数,如:to_string、stoi、stod 等。
内置类型转换为 string
将内置类型转换为 string 类型可以调用 to_string 函数,to_string 函数为各种内置类型重载了对应的处理函数。

string类型转换为内置类型
若想要将 string 类型转换为其它的内置类型,可以调用以下函数: