本文参考d2l,搭配知识点和代码,助力一口气搞懂Transformer,参考:
- chapter_attention-mechanisms-and-transformers
https://d2l.ai/chapter_attention-mechanisms-and-transformers/index.html
目录如下:
- x.1 Queries, Keys, and Values
- x.2 Attention Pooling by Similarity通过相似度进行注意力汇聚
- x.3 Attention Scoring Functions注意力评分函数
- x.4 The Bahdanau Attention Mechanism ,即RNN + Attention, (略)
- x.5 Multi-Head Attention 多头注意力(重点)
- x.6 Self-Attention and Positional Encoding 自注意力 + 位置编码
- x.7 The Transformer Architecture (Transformer的架构)(重点)
- x.8 ViT (重点)
- x.9 多尺度Transformer预训练模型
x.1 Queries, Keys, and Values
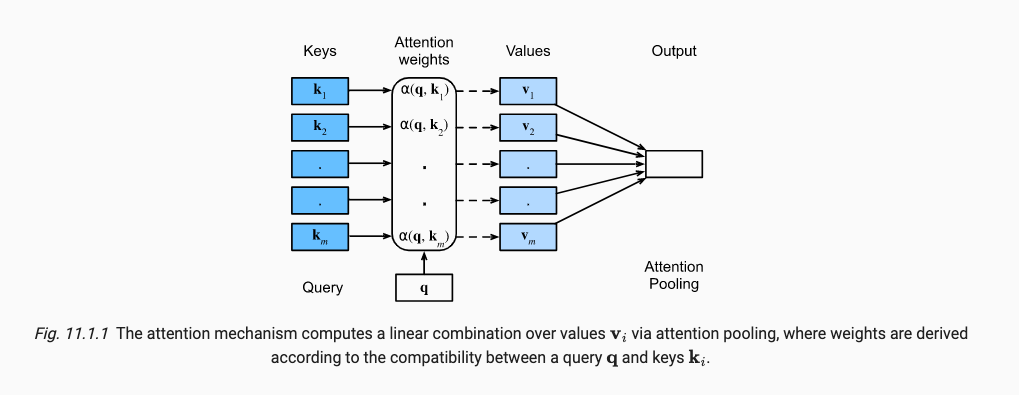
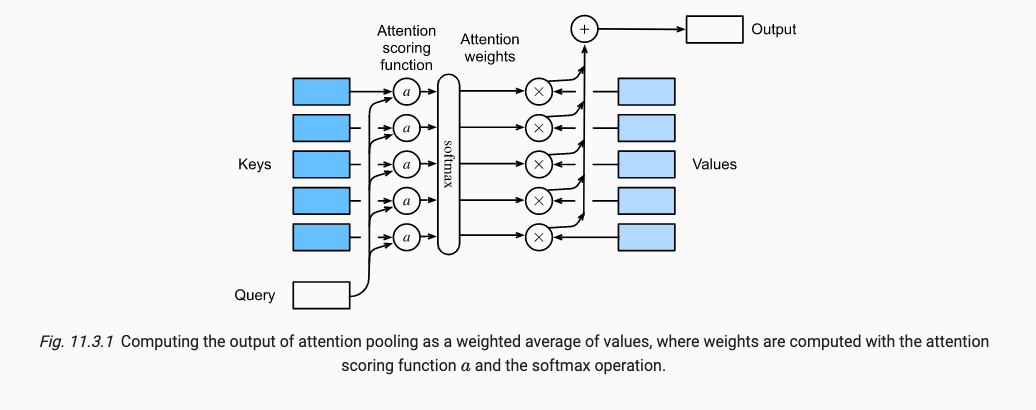
我们使用Queries和Keys来生成注意力权重,将权重值乘以我们现有的所有特征Values,来生成对单个特征Value的注意程度,将所有特征的注意程度加和得到了最终的该样本的attention pooling注意力汇聚分数。可以通过下式表达,
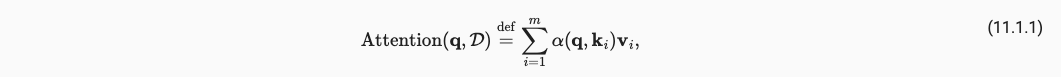
这样就形成了我们最简单的一个注意力,但作为一个概率模型(非负且加和为1),我们还需要进行下面的操作。其中(11.1.2)保证加权为1,操作(11.1.3)保证非负。
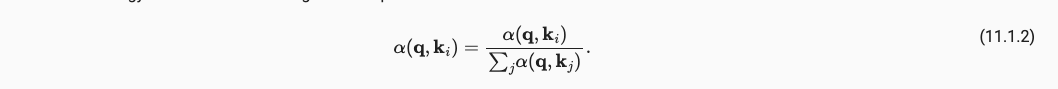
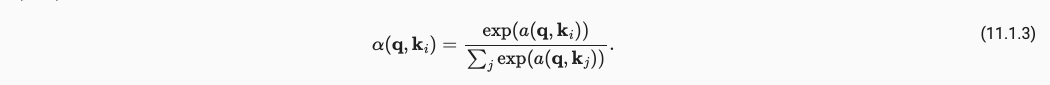
现代注意力的计算公式如下,并产生了最终的attention pooling注意力汇聚的值。
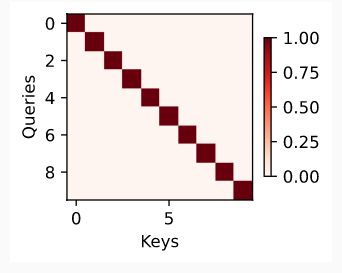
由于Q和K生成attention weight注意力权重可以用一个三维的图表达,所以我们这里可视化attention weight可以参考heatmap热力图,如下图表示的意思是:用颜色的深浅表示attention weight的大小,当且仅当key==value时,attention weight最大。也可以叫attention weight map注意力权重图.
如一个value_1对应的query_1为(2,1,3),key_1为(2,1,3)时,这个value_1的注意力权重 α ( q u e r y , v a l u e ) \alpha(query, value) α(query,value)很大,为一个小于1的很大的值。value_1的向量也占很大比重。
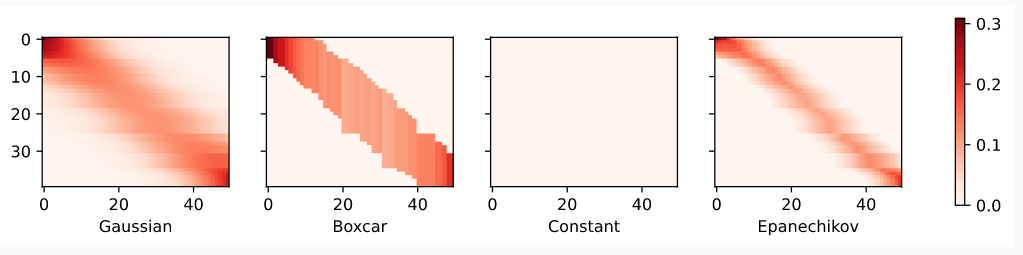
x.2 Attention Pooling by Similarity通过相似度进行注意力汇聚
即讨论 α ( q , k ) \alpha(q, k) α(q,k)中的 α \alpha α,常见的有很多,如下:
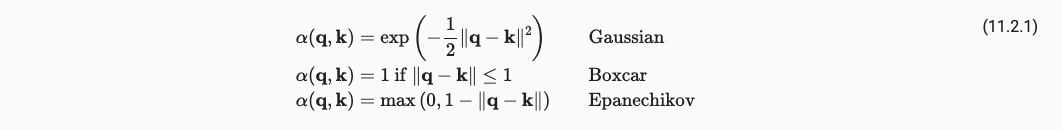
对应的注意力权重图。
x.3 Attention Scoring Functions注意力评分函数
上面中的Gaussian使用的是距离公式,但是距离公式的开销往往大于内积开销,所以我们接下来将使用点积表示注意力机制。
其中 α \alpha α就是所谓的attention scoring functions注意力评分函数。
现代attention计算如下,我们只用一个Query和多个Key-Value pairs来生成最终的ouput。
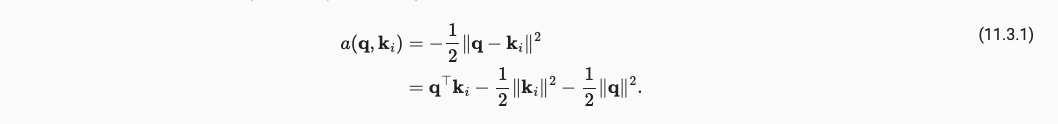
||q||一范数是确定的,由于LayerNorm的存在||K||是个确定的常数,所以只有Q点乘K的是不确定。所以我们最终计算公式如下:
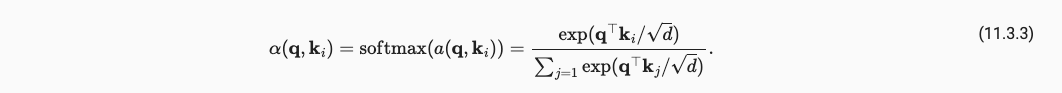
我们简化Q和K的二范数得到了点积注意力机制。用点积来表示注意力权重大大减小了乘方带来的计算开销。
x.3.2 mask
由于人在说一句话的时候,句子长度往往是不确定的,如下所示:

但是为了高效并行计算时,最好保证句子的长度相同,基于这种需求,我们引入了Mask操作,以保证NLP中的Sequence保持相同的长度。我们通过将注意力权重值在softmax前(即QK内积后)置为一个无穷小来实现,例如10的负六次方。这样是为了方便GPU并行计算快(if-else开销更大)。
x.3.3 Batch Matrix Multiplication 多样本计算
但是在并行计算中,我们往往是选取多个batch进行计算注意力(即多个sample样本),这个时候引入bmm进行batch个矩阵间内积操作:
Q = torch.ones((2, 3, 4))
K = torch.ones((2, 4, 6))
print(torch.bmm(Q, K).shape) # (2, 3, 6))

x.3.4 Scaled Dot-Product Attention
注意力权重的计算公式如下:
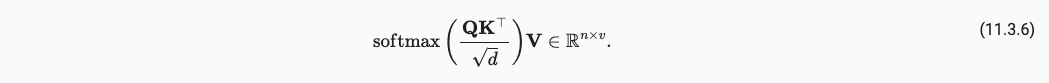
我们注意到注意到点积 QK 的结果的尺度随着 d 的增加而增加。为了抵消这种尺度变化,我们将点积除以 根号d 。这样做的目的是使点积的平均值保持在一个相对稳定的范围内,不受向量维度 d 的影响。这种缩放操作有助于使得注意力分数的大小保持在一个合适的范围,并更好地进行梯度传播。
至此,我们得到了点积注意力机制的计算公式,可以看到是一个很简单的Query和Key的BMM操作,做softmax后dropout后,再和Value做BMM的操作。如下:
class DotProductAttention(nn.Module):
"""Scaled dot product attention.
Defined in :numref:`subsec_additive-attention`"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# Shape of `queries`: (`batch_size`, no. of queries, `d`)
# Shape of `keys`: (`batch_size`, no. of key-value pairs, `d`)
# Shape of `values`: (`batch_size`, no. of key-value pairs, value
# dimension)
# Shape of `valid_lens`: (`batch_size`,) or (`batch_size`, no. of queries)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# Set `transpose_b=True` to swap the last two dimensions of `keys`
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
x.4 The Bahdanau Attention Mechanism ,即RNN + Attention, (略)
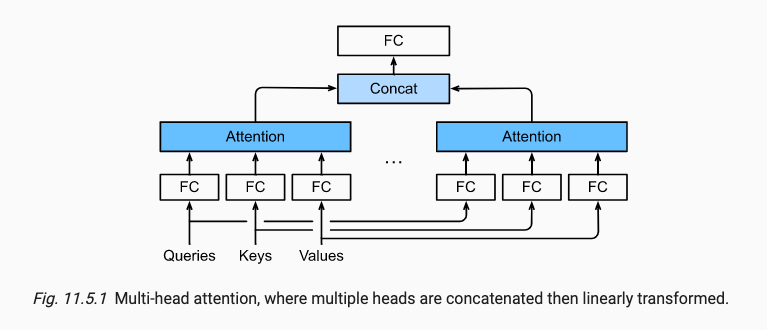
x.5 Multi-Head Attention 多头注意力(重点)
x.5.1 整体流程
说说是说,先将Q, K, V分裂成多头,对单头进行可学习参数调整后,再计算Attention。但实际代码实现过程中,先使用Linear层进行可学习参数调整,再使用transpose_qkv分裂成多头,但只不过是3个三维矩阵query,key,value。进行mask,再将这3个三维矩阵进行点积注意力机制计算。
计算完attention后,再通过transpose_output(即多头逆操作)将维度concat。concat后再经过一个可学习参数Linear层产生最终的输出。
我们能够注意到:
- 所有的可学习参数 W q , W k , W v , W o W_q, W_k, W_v, W_o Wq,Wk,Wv,Wo都是在原大小(即非分裂头)上进行学习的,且都是由线性层组成。
num_hiddens == Query dimension
# Shape of queries, keys, or values:
# (batch_size, no. of queries or key-value pairs, num_hiddens)
# Shape of valid_lens: (batch_size,) or (batch_size, no. of queries)
# After transposing, shape of output queries, keys, or values:
# (batch_size * num_heads, no. of queries or key-value pairs, num_hiddens / num_heads)
queries = self.transpose_qkv(self.W_q(queries))
keys = self.transpose_qkv(self.W_k(keys))
values = self.transpose_qkv(self.W_v(values))
# generate the mask of each Q, K, V
if valid_lens is not None:
# On axis 0, copy the first item (scalar or vector) for num_heads
# times, then copy the next item, and so on
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# Shape of output: (batch_size * num_heads, no. of queries, num_hiddens / num_heads)
output = self.attention(queries, keys, values, valid_lens)
# Shape of output_concat: (batch_size, no. of queries, num_hiddens)
output_concat = self.transpose_output(output)
return self.W_o(output_concat)
x.5.2 使用transpose_qkv分裂成多头
在实践中,给定相同的查询、键和值集,我们可能希望我们的模型将来自相同注意机制的不同行为的知识结合起来,例如在一个序列中捕获不同范围(例如,短范围和长范围)的依赖关系。即,将生成的token_query(batch, number of query, dimension)中的dimension均分成heads等分来达到多头的目的,以学到多尺度的特征向量(类比卷积学到的多尺度特征)。故引入Multi-Head Attention (MA)。
例如,你输入的query.shape==[2, 4, 100],经过多头分裂后就变成了query.shape==[10, 4, 20]均分成多头的代码:
def transpose_qkv(self, X):
"""Transposition for parallel computation of multiple attention heads."""
# Shape of input X: (batch_size, no. of queries or key-value pairs,
# num_hiddens). Shape of output X: (batch_size, no. of queries or
# key-value pairs, num_heads, num_hiddens / num_heads)
X = X.reshape(X.shape[0], X.shape[1], self.num_heads, -1)
# Shape of output X: (batch_size, num_heads, no. of queries or key-value
# pairs, num_hiddens / num_heads)
X = X.permute(0, 2, 1, 3)
# Shape of output: (batch_size * num_heads, no. of queries or key-value
# pairs, num_hiddens / num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
x.5.3 使用nn.LazyLinear进行单头可学习参数调整
对于单个head的计算,我们还会引入三个可学习参数用于分别和K,Q,V进行计算,是通过fully connection(FC/全连接层/线性层)实现的,式中的 f f f是Attention pooling如点积注意力机制等的方法。
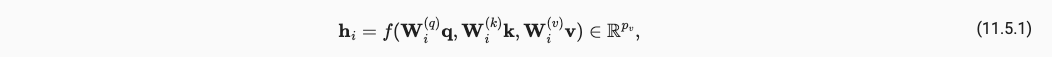
他的代码实现过程如下:
self.W_q = nn.LazyLinear(num_hiddens, bias=bias)
x.5.4 点积注意力
使用x.3.4的点积注意力对3个三维矩阵进行点积注意力操作。
# Shape of output: (batch_size * num_heads, no. of queries, # num_hiddens / num_heads)
output = self.attention(queries, keys, values, valid_lens)
x.5.5 concat拼接后进行Linear可学习参数
最终所有的heads输出都会进行concat拼接(维度方向上进行拼接),拼接完毕后,还会引入一个可学习参数用于和Output进行计算,也是通过线性层实现的。
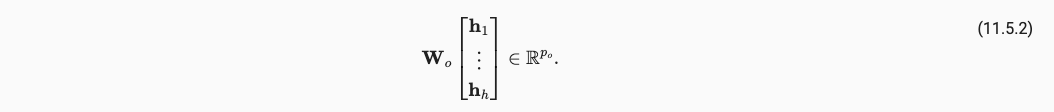
# Shape of output_concat: (batch_size, no. of queries, num_hiddens)
output_concat = self.transpose_output(output)
return self.W_o(output_concat)
x.6 Self-Attention and Positional Encoding 自注意力 + 位置编码
x.6.1 自注意力机制
借鉴点积注意力和多头注意力,产生了自注意机制。自注意力机制的输入输出token的长度相同。每一个token的向量长度为(batch size, number of time steps or sequence length in tokens, d)
这里的d比如说query为三维矩阵(mini-batch size, number of query, dimension), dimension = num_hiddens = length of token (= number of query-key pairs) != number of key-value pairs.
x.6.2 Position Encoding
与RNN一个一个处理token不同,Self-attention模块是并行处理很多,这导致了它会丢失掉先后顺序的位置信息。
我们可以通过position encoding添加位置信息。position encoding 的方式包括can either be learned or fixed a priori(被先前学习或者被固定在输入向量中)。We now describe a simple scheme for fixed positional encodings based on sine and cosine functions我们现在引入一种固定位置的方式在sin,cos中。我们通过X+P引入位置向量,其中P是 n x d 的矩阵,维度大小同Query,包含位置信息。
class PositionalEncoding(nn.Module): #@save
"""Positional encoding."""
def __init__(self, num_hiddens, dropout, max_len=1000):
super().__init__()
self.dropout = nn.Dropout(dropout)
# Create a long enough P
self.P = torch.zeros((1, max_len, num_hiddens))
X = torch.arange(max_len, dtype=torch.float32).reshape(
-1, 1) / torch.pow(10000, torch.arange(
0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)
self.P[:, :, 0::2] = torch.sin(X)
self.P[:, :, 1::2] = torch.cos(X)
def forward(self, X):
X = X + self.P[:, :X.shape[1], :].to(X.device)
return self.dropout(X)
x.7 The Transformer Architecture (Transformer的架构)(重点)
x.7.1 整体介绍
Transformer是一个Encoder-Decoder架构,由n摞encoder-decoder组成。
其中在一开始会有Embedding将句子中的每一个词转为token词向量,但是self-attention缺少上下文位置信息,所以经过Positional encoding来用加操作叠加位置信息。
Encoder模块有两个sub-layer组成:multi-head attention和positionwise FFN。
Decoder模块有三个sub-layer组成:masked multi-head attention,multi-head attention和positionwise FFN。
其中add是Residual残差模块,norm是Layer Norm用于归一化。
整体计算过程可以参考https://blog.csdn.net/qq_43369406/article/details/129306734。
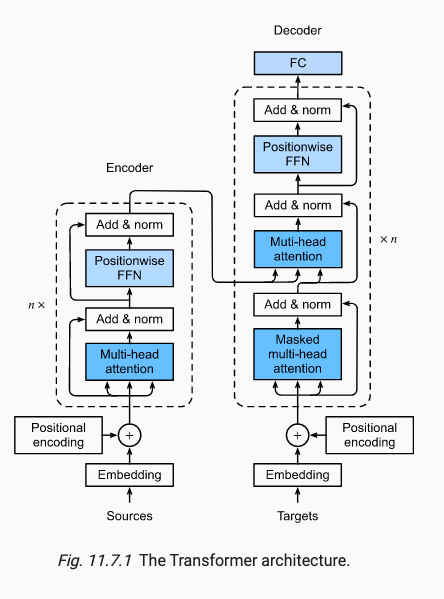
x.7.2 N摞什么意思
N摞指的是串行结构,提取了多次特征或者解码了多次。由于CV用不到decoder,便不讲述decoder部分,例如循环右移,每次蹦出一个词,下一层Decoder输入是上一层Decorder的输出,增加mask以保证只关注当前位置向量等。整体n摞架构如下:
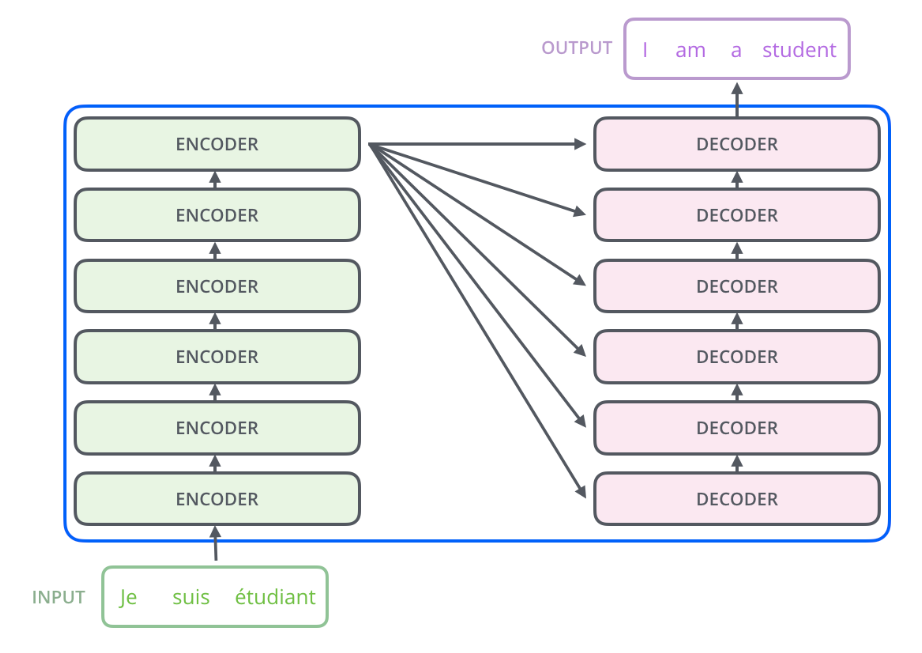
x.7.3 encoder模块
我们的特征经过n摞encoder进行特征提取。多头注意力机制内容一样,这里增加讲解一下positionwise FFN和layer norm。
Positionwise FFN主要用于增强模型在每个位置上的表示能力。每个位置上的表示能力指的是模型对输入序列中每个位置的理解和表达能力。在Transformer模型中,使用了自注意力机制(self-attention),用于对每个位置的表示进行建模,以捕捉与该位置相关的上下文信息。然而,自注意力机制本身并没有位置感知性,它对所有位置的表示都采取了相同的操作。因此,Positionwise FFN的作用就是在自注意力机制之后,通过非线性映射和变换,增强每个位置上的表示能力,使得模型可以更好地区分和编码不同位置的特征和语义信息。
位置编码前馈网络(positionwise feed-forward network)使用相同的多层感知机(MLP)来对序列中所有位置的表示进行转换,由两层Linear和一层ReLU组成,它的整体代码如下:
class PositionWiseFFN(nn.Module): #@save
"""The positionwise feed-forward network."""
def __init__(self, ffn_num_hiddens, ffn_num_outputs):
super().__init__()
self.dense1 = nn.LazyLinear(ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.LazyLinear(ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
layer norm指的是对每个样本进行归一化。
x.8 ViT (重点)
x.8.1 整体过程
首先我们拥有一个height为 h 和width为 w 的图片, 然后我们将图片分割为 p x p , 最终我们将原图变成了 m = h x w / ( p x p ) 个数量的patches, 然后每一个patch展平为 c x p x p 长度的vector.
我们将 m 个vectors的最开头 追加一个用于表示 cls 的vector, 最终我们有 m + 1 个vectors.
将m + 1个vecotrs添加 positional Embedding 位置编码,然后再传入Transformer中训练.
最终取出第一个vector,做Norm和MLP,生成了 class 类别标签.
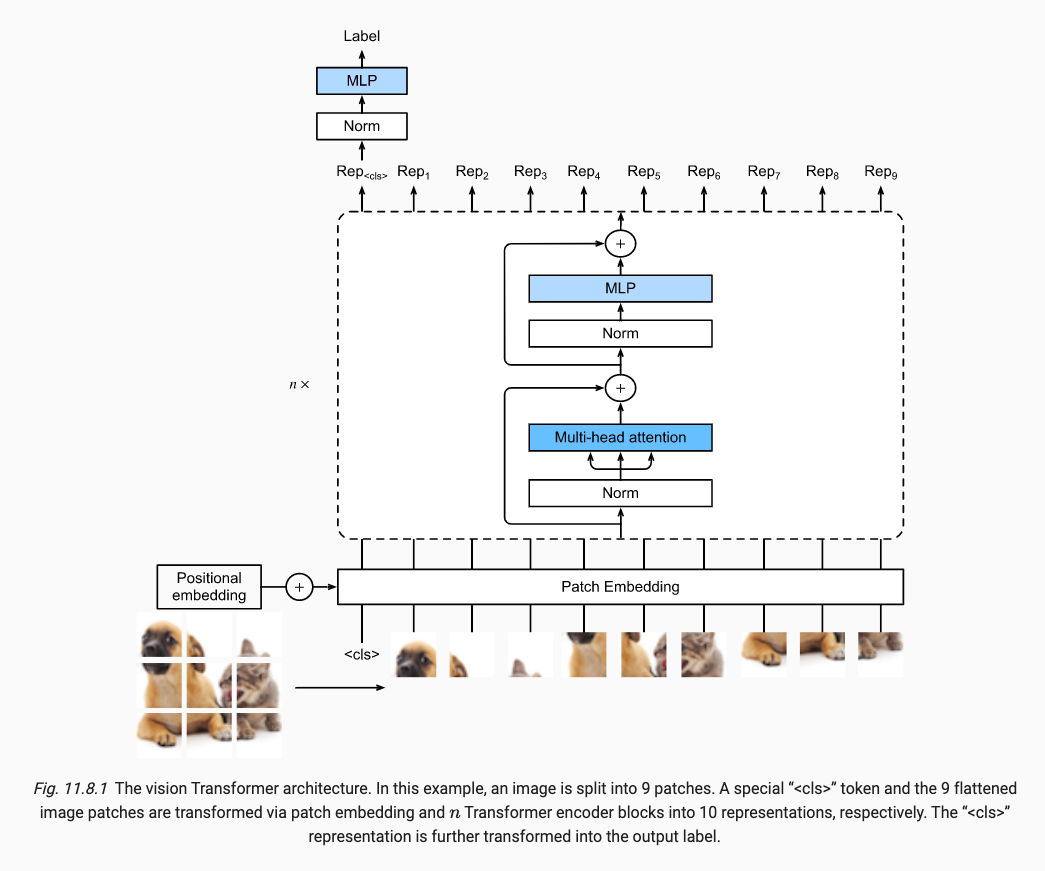
x.8.2 与Transformer中的encoder的不同之处
ViT的 MLP 和 Transformer的position-wise FFN 不同, 虽然其指代的是同一个。First, here the activation function uses the Gaussian error linear unit (GELU), which can be considered as a smoother version of the ReLU. Second, dropout is applied to the output of each fully connected layer in the MLP for regularization. 首先使用了 GELU 而不是 ReLU ( 虽然Transformer中有使用ReLU, 在FFN中 ), 接着引入了dropout( Trans 中只在 Position encoding 后有dropout, 而在FFN中是没有dropout ).
The vision Transformer encoder block implementation just follows the pre-normalization design in Fig. 11.8.1, where normalization is applied right before multi-head attention or the MLP. In contrast to post-normalization (“add & norm” in Fig. 11.7.1), where normalization is placed right after residual connections, pre-normalization leads to more effective or efficient training for Transformers. 使用了 pre-normalization 代替 post-normalization 即 “先 norm 再 MSA”, 这样更加快速和有效.