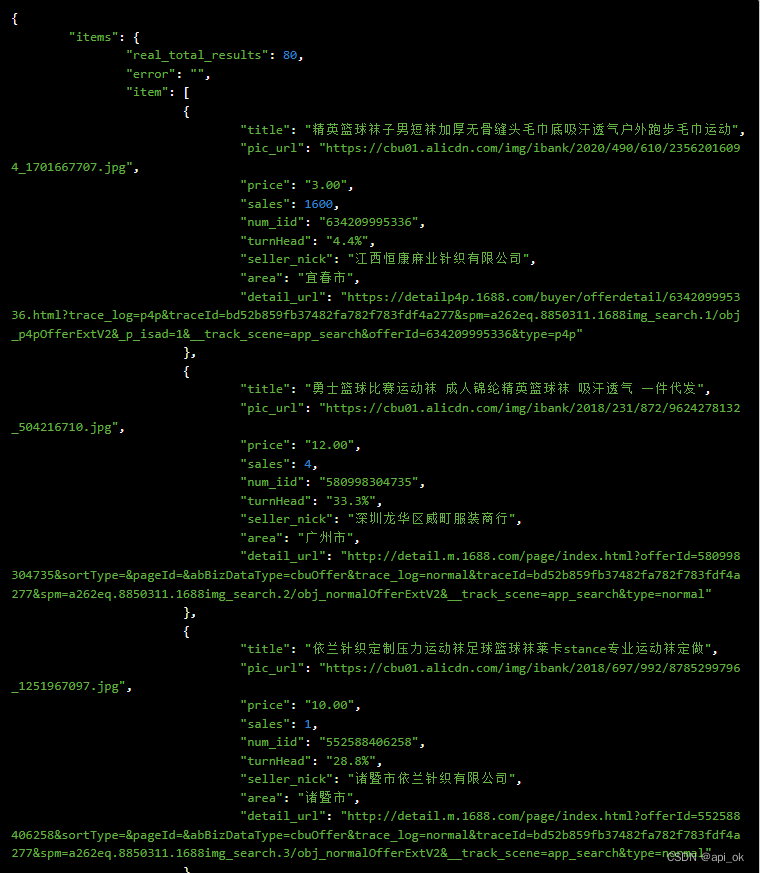
在Arcgis中可以通过属性表中字段的【统计】功能或使用统计相关的工具对属性表进行数据统计。
在Arcgis工具箱中有一组【统计分析】工具集,不仅包含对属性数据执行标准统计分析(例如平均值、最小值、最大值和标准差)的工具,也包含对重叠和相邻要素计算面积、长度和计数统计的工具。

这里以统计分析工具集为基础,聊聊Arcgis中的数据统计工具。
一、属性表中字段的【统计】功能
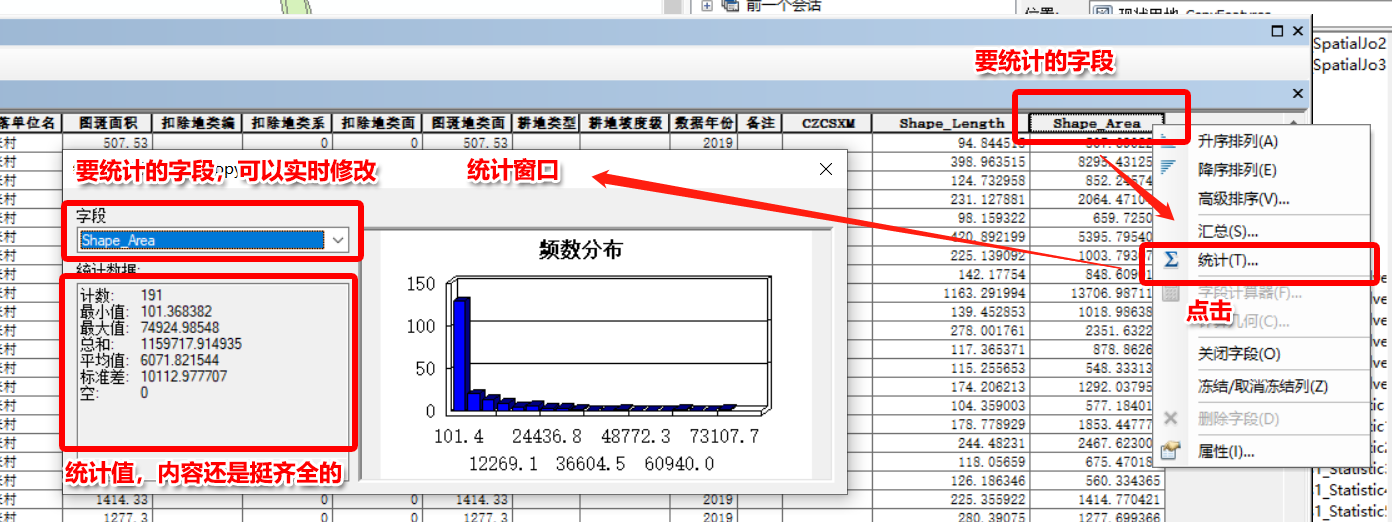
属性表中字段的【统计】功能是最简单的数据统计方式,虽然功能简单,但胜在方便,所以使用率算是挺高的。
打开属性表,在需要统计的字段上右击,即可选择【统计】功能:
二、【汇总统计数据】工具(Statistics)
【汇总统计数据】工具是最常用的一个统计工具,通常用于按字段统计面积等。
下图就是一个典型的按【JQDLBM】字段来统计用地面积的例子:
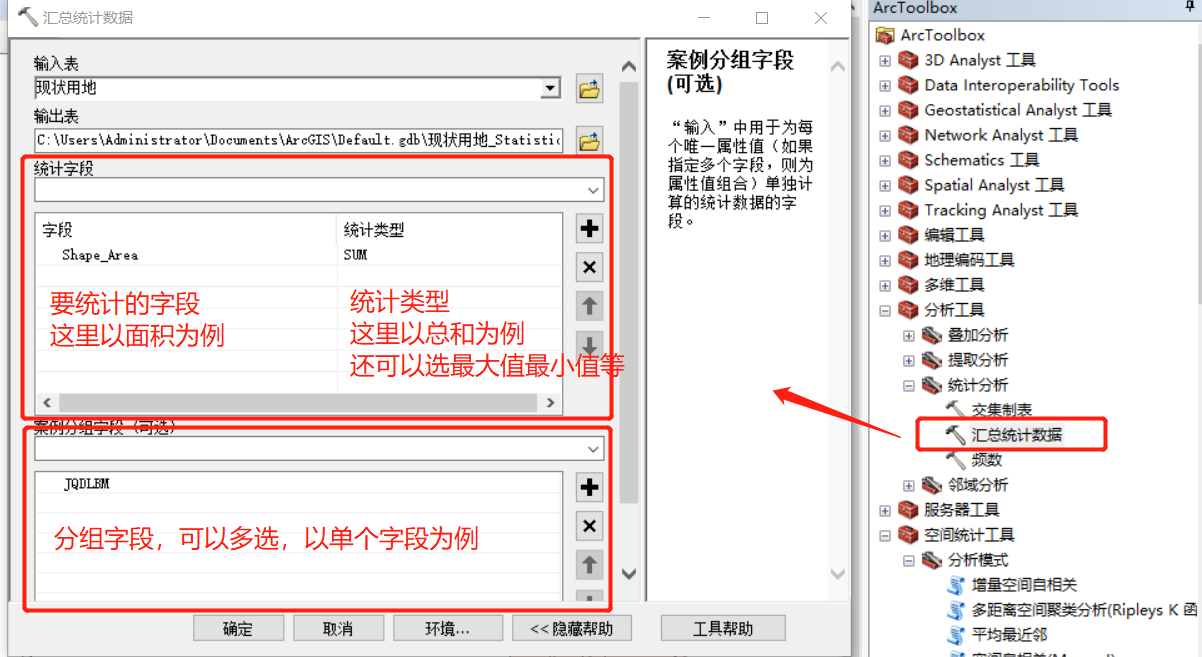
生成的结果简单明了:
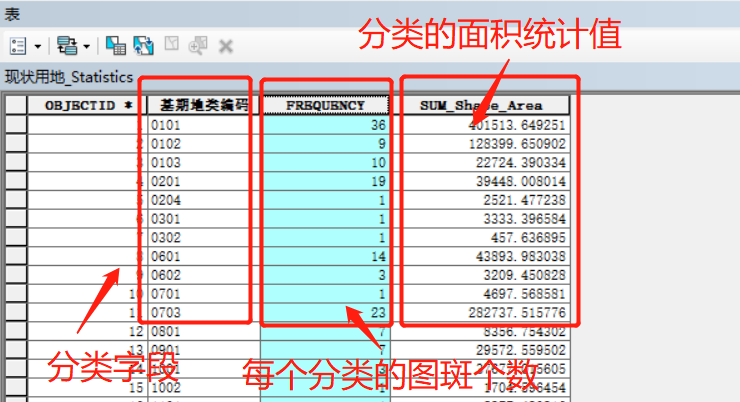
生成表中的【FREQUENCY】是按分类统计的图斑个数,第一行的【36】即【JQDLBM】值为【0101】的图斑有36个的意思。
实际上【统计分析】工具集里的另一个【频数】工具,就是实现这么个功能……,而且在统计类型里也有这么一个选项【COUNT】可以得到同样的结果。其它选项如下:
另一个参数【案例分组字段】就按某组字段来分组的意思,上面的例子以单个字段【JQDLBM】来分。
如果你的图斑是包括多个村庄,你想统计不同村庄的不同用地类型,就可以用2个字段作为分组字段:
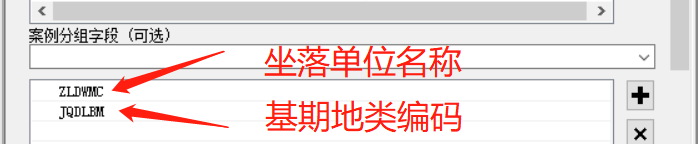
工具运行结果如下:
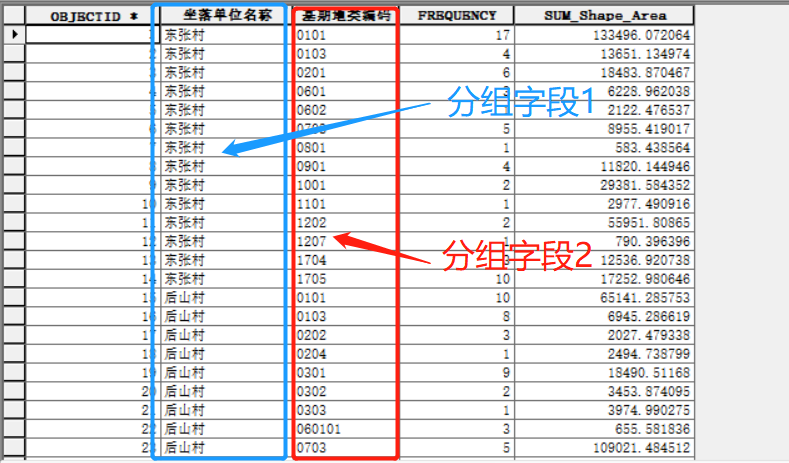
三、【交集制表】工具(TabulateIntersection)
【交集制表】工具和上面的【汇总统计数据】工具有点类似,但应用场景有点不一样。
例如一个村庄可以分为几个片区,但这个分区并不在村庄用地的相关字段里,而是在另一个要素类中定义。
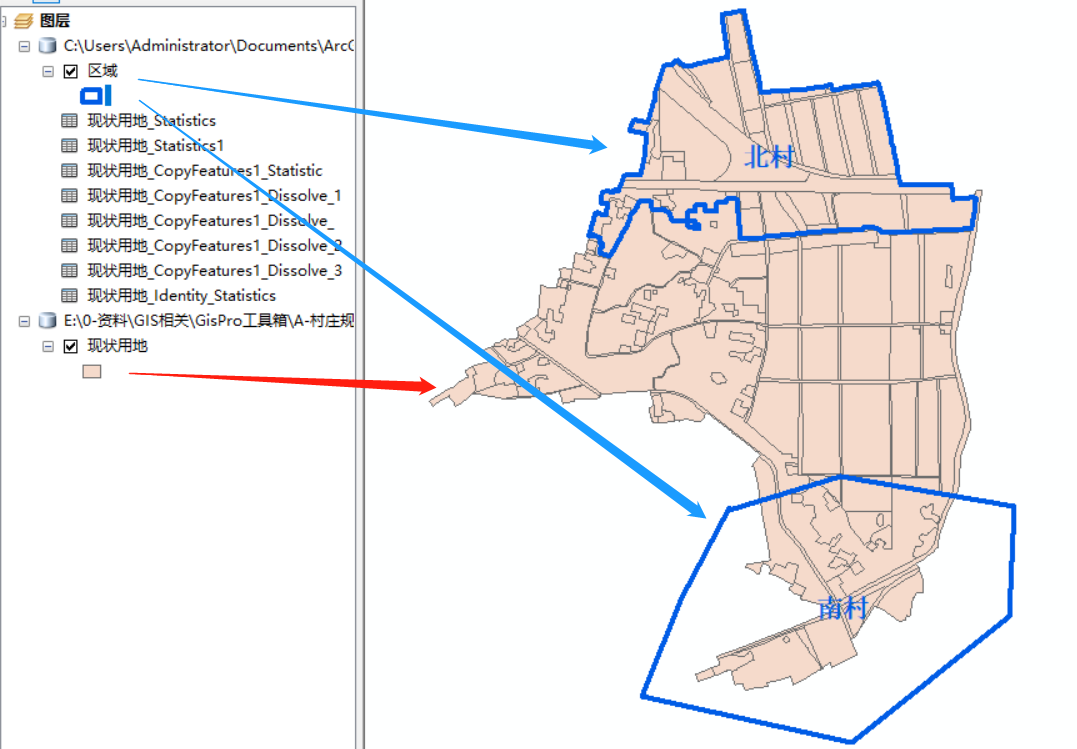
你想统计上图中这两个片区的用地面积,就可以使用【交集制表】工具。需要注意的是,这个分区要素并不一定要和统计要素完全重叠,工具运行的时候只会统计两个要素之间完全重叠的区域。
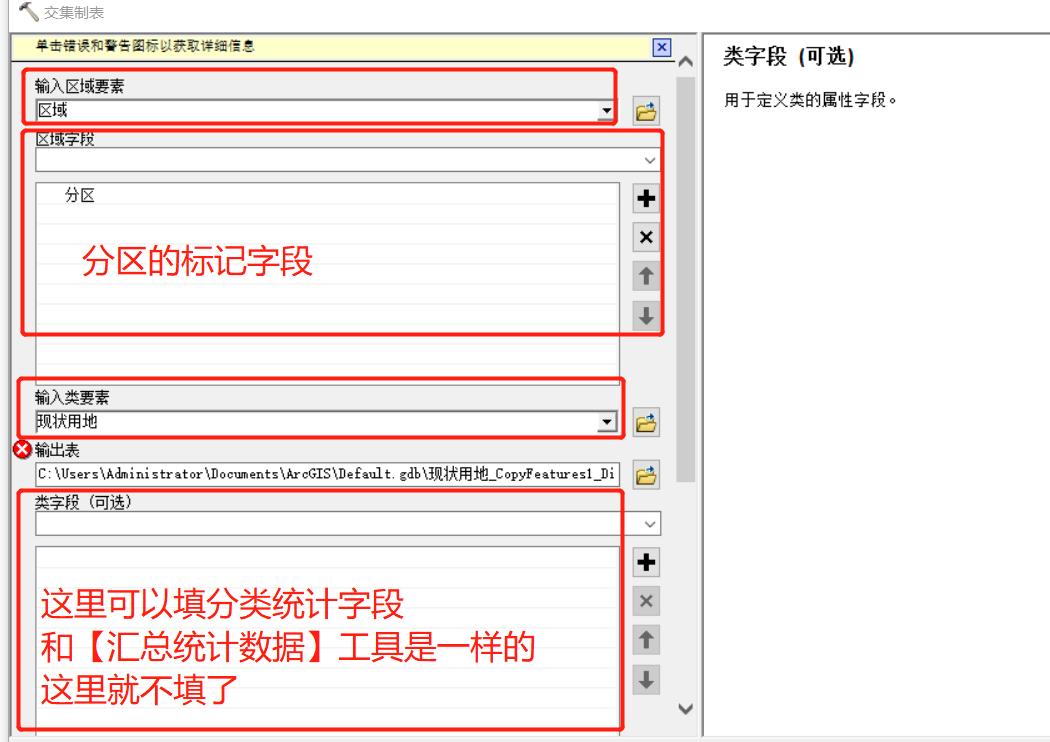
工具运行结果如下:
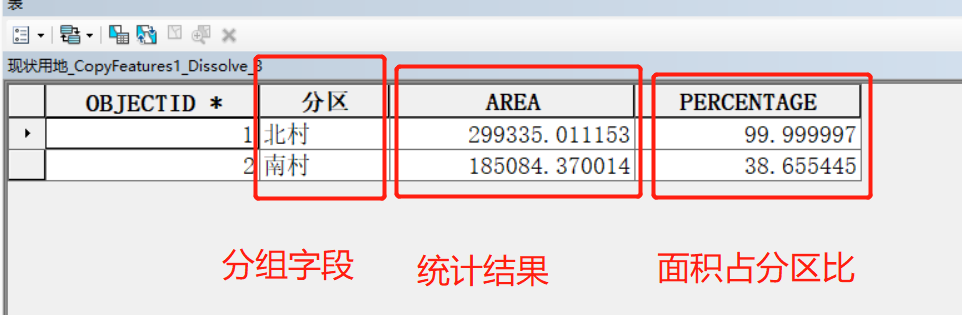
这里也会生成一个额外的【PERCENTAGE】字段,意思是该分区统计的面积占分区面积之比。例如南村的用地并没有布满区域,所以这个比值就只有38%。
四、【范围内汇总】工具(SummarizeWithin)
需要说明的是,【范围内汇总】工具是ArcGIS Pro中独有的,从功能上看,相当于【交集制表】工具的加强版,不仅能生成汇总表,还能复制一个分区范围的要素,并且将汇总数据添加到分区范围要素上。
工具位置也在【统计分析】工具集下。
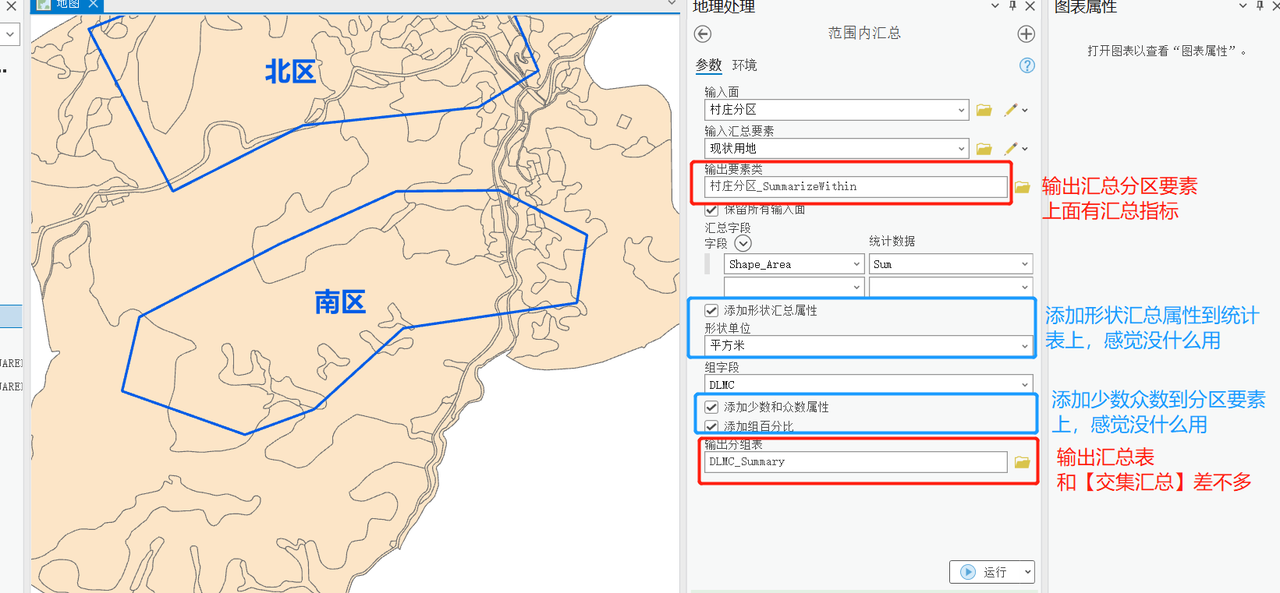
从工具参数可以看出,有2个输出,一个是汇总表,还有一个是输出的分区要素,上面有添加的汇总信息。还有一些汇总参数,像少数、众数什么的,不过感觉用处不大。
【范围内汇总】工具生成的汇总表和【交集制表】工具差不多:
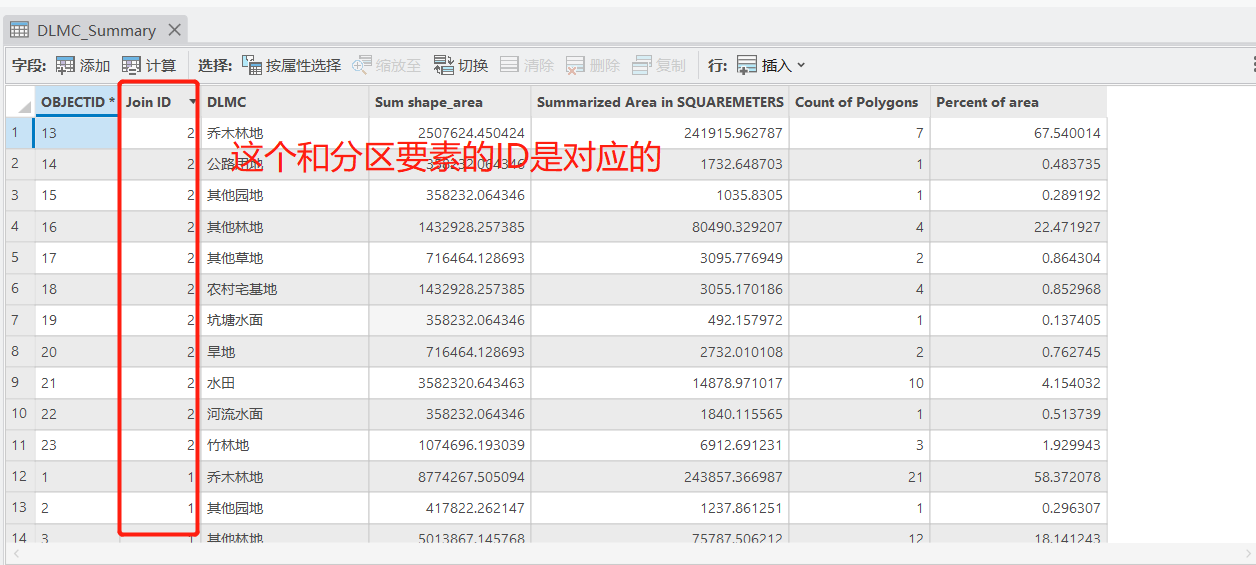
输出的分区要素:

和【交集制表】工具相比,感觉也就是锦上添花吧,说不上有什么特别优秀的地方,可以看情况选用。
五、【数据透视表】工具(PivotTable)
此工具通过在“输入表”中减少记录中的冗余并简化一对多关系来创建表。可以对生成的汇总表进一步处理,特别是用多个分组字段生成的汇总表。
工具位置在【数据管理工具】的【表】工具集下。
以下图的汇总表为例:
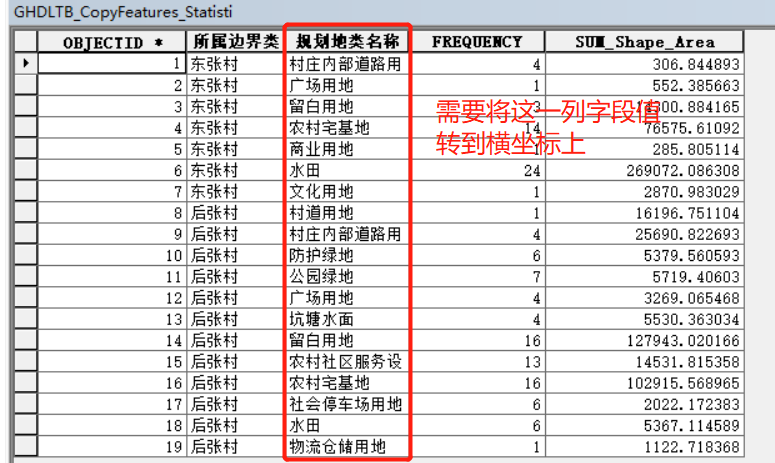
这张表的表达不够直观,特别是2个村庄之间的数据对比比较差,我们需要将【所属边界】放到横坐标(字段名)上(相当于Excel里的列)。
工具参数如下:
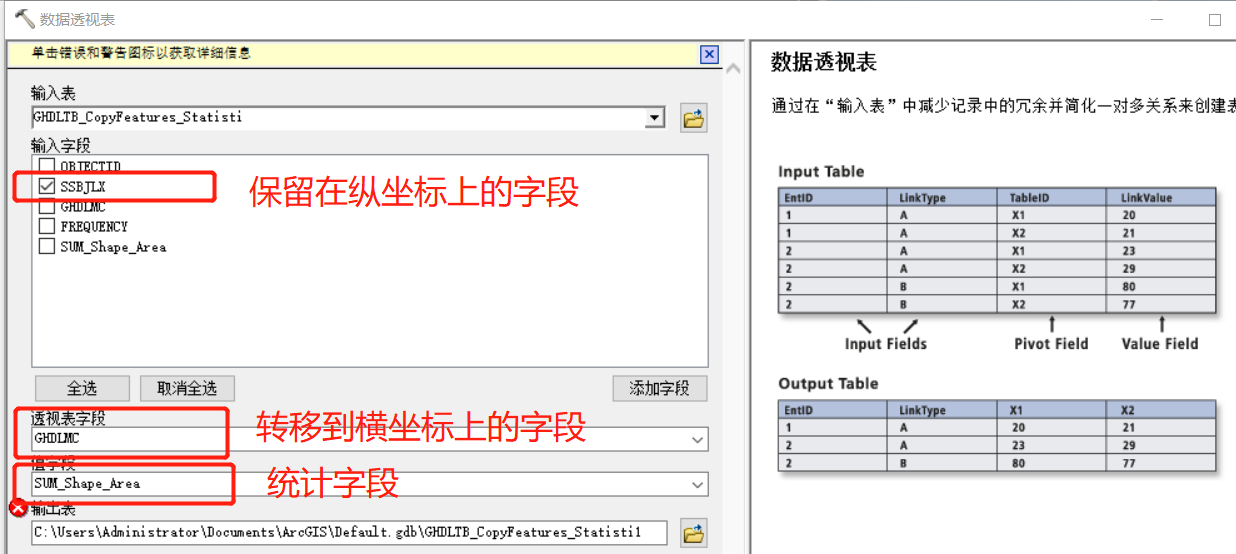
这几个参数经常搞混,多用几次,熟悉就好了。生成结果如下:

转换后的数据透视表就直观多了,导出Excel后也便于后续处理。
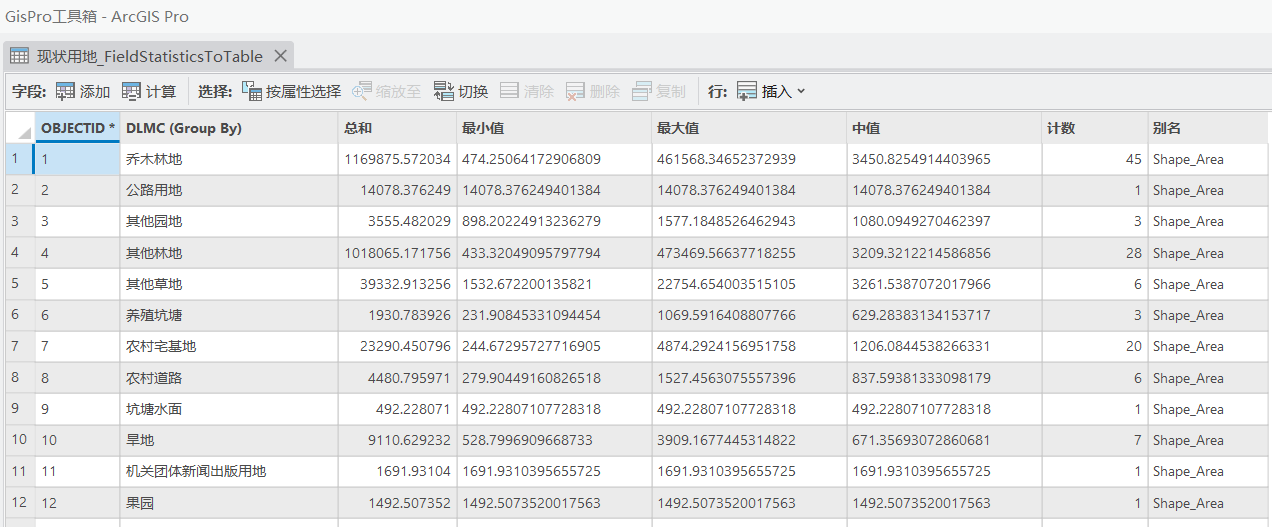
六、【字段统计数据转表】工具(FieldStatisticsToTable)
【字段统计数据转表】工具也是ArcGIS Pro独有的,工具位置在【数据管理工具】的【字段】工具集下。
这个工具怎么说呢,就是花里胡哨……。基本功能也就是【汇总统计数据】工具做的事,只是它能汇总的内容更多更花哨(无聊?)。
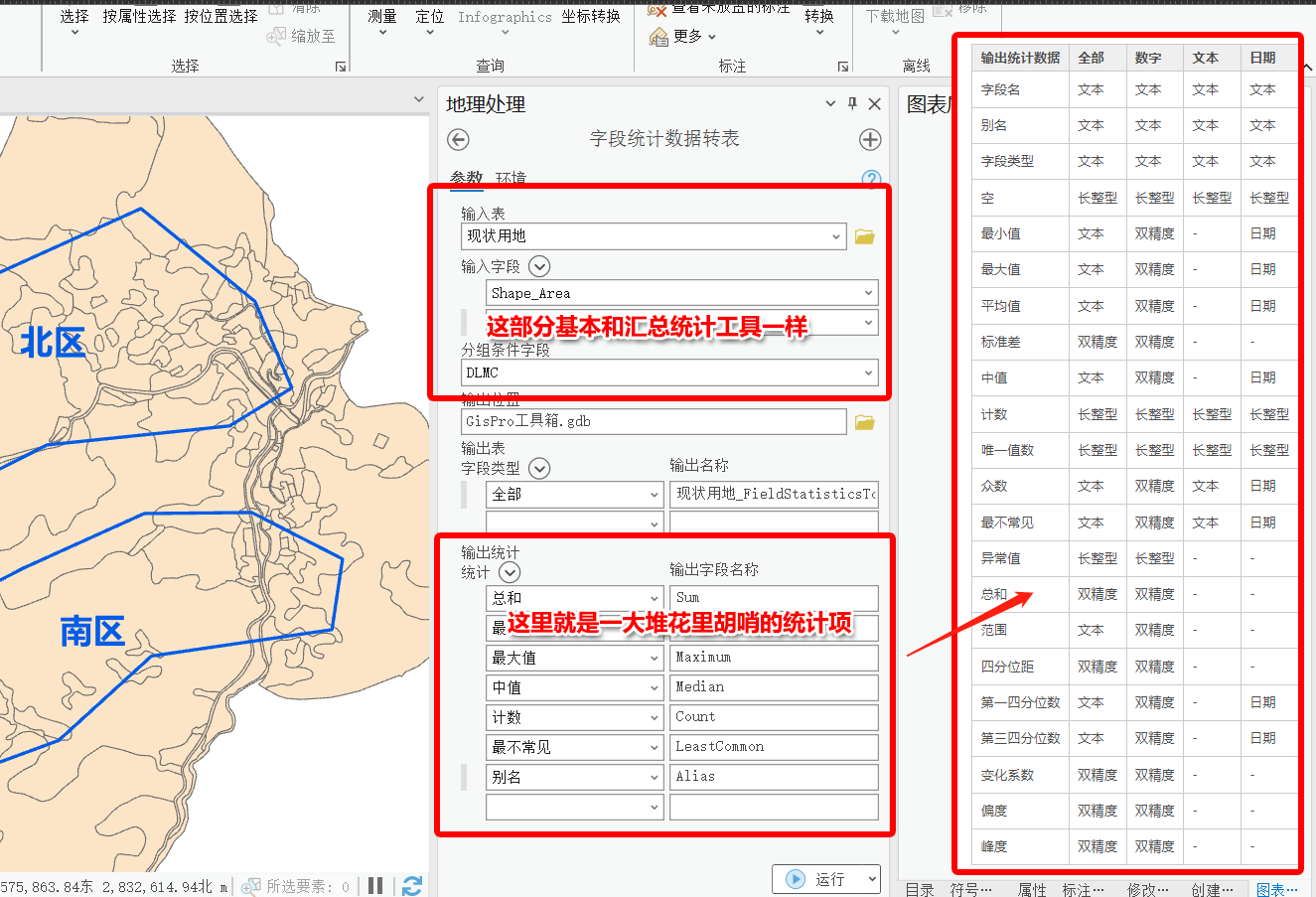
统计结果如下:
以上就是ArcGIS中和数据统计相关的内容,最常用的实际上也就是属性表字段的【统计】功能和【汇总统计数据】工具,其它工具也就是在特定场景下才用得上。不过可以看出ArcGIS给我们准备的功能或工具是很齐全的,也可见是个很有深度的软件。
七、自制脚本工具汇总
如果上面的工具都不能满足你的要求,还可以尝试用脚本来实现。
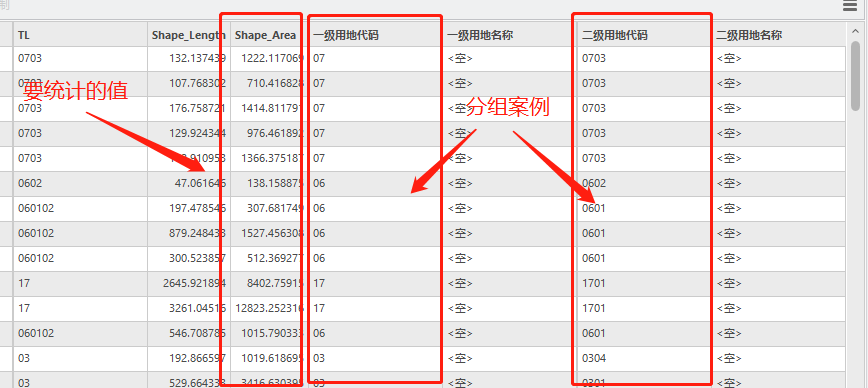
如上图所示,要分组统计的字段有2个,但和汇总工具不同的是,汇总结果并非同时满足2个字段值,而是分开统计,即按字段1、字段2分别统计,再将表合并起来。在实际工作中,你可以得到一级地类和二级地类的统计表格。
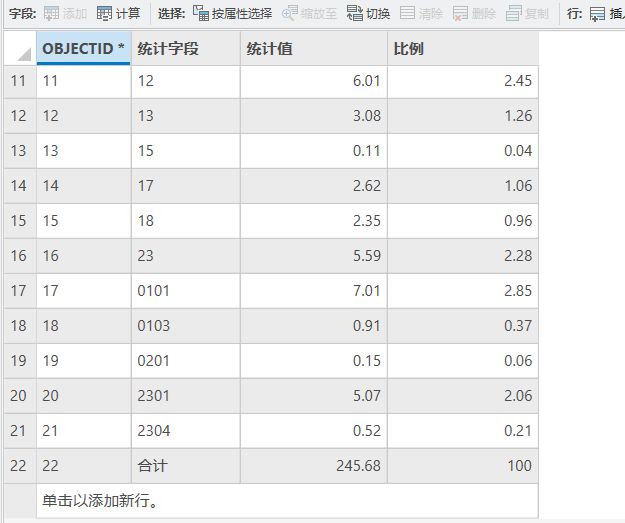
用脚本工具是很自由的,你可以再增加一点其它功能,比如说,生成一个【合计值】,即所有地块的总面积,再增加一个字段,统计各类用地占总用地面积的【比例】。
甚至还可以对【面积单位进行转换】,如转成公顷、平方公里等,以及保留【固定的小数位数】。
生成的示例结果如下:
脚本工具参数设置如下:
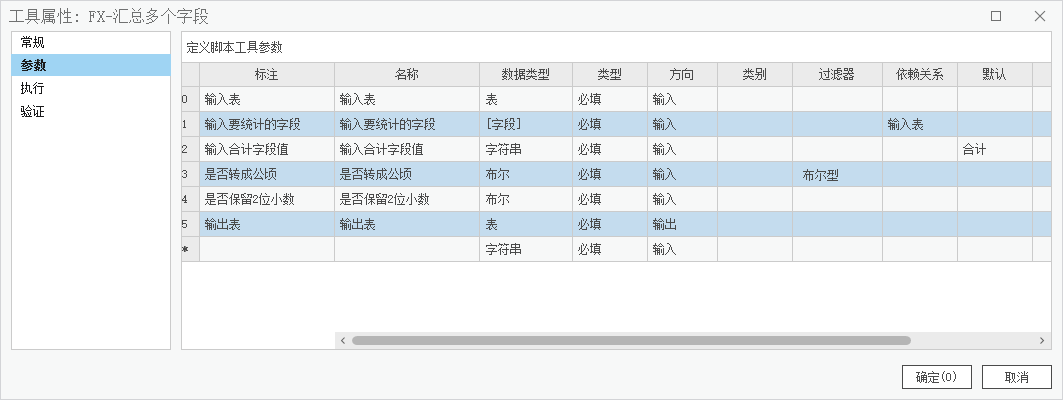
限于篇幅,具体代码不详细说了,直接贴上:
# -*- coding: utf-8 -*-
import arcpy
import os
input_table = arcpy.GetParameterAsText(0) # 输入表
input_field = arcpy.GetParameterAsText(1) # 输入要统计的字段
input_sta = arcpy.GetParameterAsText(2) # 输入合计字段值(可选)
is_ha = arcpy.GetParameter(3) # 是否转成公顷
is_round = arcpy.GetParameter(4) # 是否保留2位小数
output_table = arcpy.GetParameterAsText(5) # 输出表
# 获取文档位置
default_path = os.path.dirname(os.path.dirname(os.path.dirname(__file__))) # D:\【软件资料】\GIS相关\GisPro工具箱
tem_gdb = default_path + r'\3-默认数据库\GisPro工具箱.gdb' # 临时数据库
# 汇总多个字段
def MultyStatic():
# 解析字段列表
list_field = input_field.split(';')
# 汇总多个字段
list_table = []
for i in range(len(list_field)):
area_static = arcpy.Statistics_analysis(input_table, tem_gdb + r'\area_static_' + str(i), [['Shape_Area', "SUM"]], [list_field[i]])
arcpy.AddField_management(area_static, '统计字段', "TEXT") # 添加公共字段
arcpy.CalculateField_management(area_static, '统计字段',expression='!' + list_field[i] + '!') # 计算公共字段
list_table.append(area_static)
# 汇总总量
area_total = arcpy.Statistics_analysis(input_table, tem_gdb + r'\area_static_total', [['Shape_Area', "SUM"]])
arcpy.AddField_management(area_total, '统计字段', "TEXT") # 添加公共字段
arcpy.CalculateField_management(area_total, '统计字段', expression='\'' + input_sta + '\'') # 计算公共字段
list_table.append(area_total)
# 合并表格
area_all = arcpy.Merge_management(list_table, tem_gdb + r'\yd_all')
# 去除空值,输出table
arcpy.TableSelect_analysis(area_all, output_table, where_clause="统计字段 IS NOT NULL")
# 添加统计值和比例字段
arcpy.AddField_management(output_table, '统计值', 'FLOAT')
arcpy.AddField_management(output_table, '比例', 'FLOAT')
# 计算统计值和比例字段
arcpy.CalculateField_management(output_table, '统计值', expression='!SUM_SHAPE_Area!')
total = float(str(GetFieldValue(output_table, '统计值', "统计字段 = '" + input_sta + "'")))
fields = ['统计值', '比例']
with arcpy.da.UpdateCursor(output_table, fields) as cursor:
for row in cursor:
row[1] = row[0]/total*100
if is_ha is True: # 转换成公顷
row[0] = row[0]/10000
cursor.updateRow(row)
# 判断是否保留2位小数
with arcpy.da.UpdateCursor(output_table, fields) as cursor:
for row in cursor:
if is_round is True:
row[0] = round(row[0], 2)
row[1] = round(row[1], 2)
cursor.updateRow(row)
# 删除中间字段
arcpy.DeleteField_management(output_table, list_field)
arcpy.DeleteField_management(output_table, ['FREQUENCY', 'SUM_SHAPE_Area'])
# 删除中间要素
arcpy.Delete_management(area_static)
arcpy.Delete_management(area_total)
arcpy.Delete_management(area_all)
# 获取要素或表的某一个字段的第一个值,默认字段为Shape_Area。筛选表达式为:keyField=key
def GetFieldValue(input_table, value_field, sql):
# 按sql语句筛选出所要的表格
table = arcpy.TableSelect_analysis(input_table, r'memory\table_sel', sql)
# 定义一个空值,用于储存返回的结果
filedValue = '0'
# 读取值【如果筛选值有多个,只取第一个值】
with arcpy.da.SearchCursor(table, [value_field]) as cursor:
for row in cursor:
filedValue = row[0]
break
arcpy.SetParameterAsText(3, str(filedValue))
if __name__ == '__main__':
MultyStatic()