在当今数据爆炸的时代,时序数据已经成为企业和组织中不可或缺的一部分。它们包括了从传感器、监控设备、日志记录系统和金融交易等多种来源的大量数据,这些数据按照时间顺序排列,记录了各种事件和活动的发生和变化。时序数据的分析和处理对于企业的业务决策和运营效率至关重要。为了更好地管理和利用这些数据,人们发明了**时序数据库管理系统(Time Series Database System,TSDB)**。
在时序数据库系统中,时序数据通常被抽象和组织为**时间线(time series)**,时序数据库的设计与实现也是围绕着时间线进行的,因此理解时间线是深入理解时序数据库系统的前提。
在本文中,我将和大家一起学习一下时序数据库中时间线的概念,并以InfluxDB(2.x)为例探讨时间线在该数据库中的组织和呈现形式。
在学习时间线之前,我们先来重新认识一下时序数据。
1. 什么是时序数据
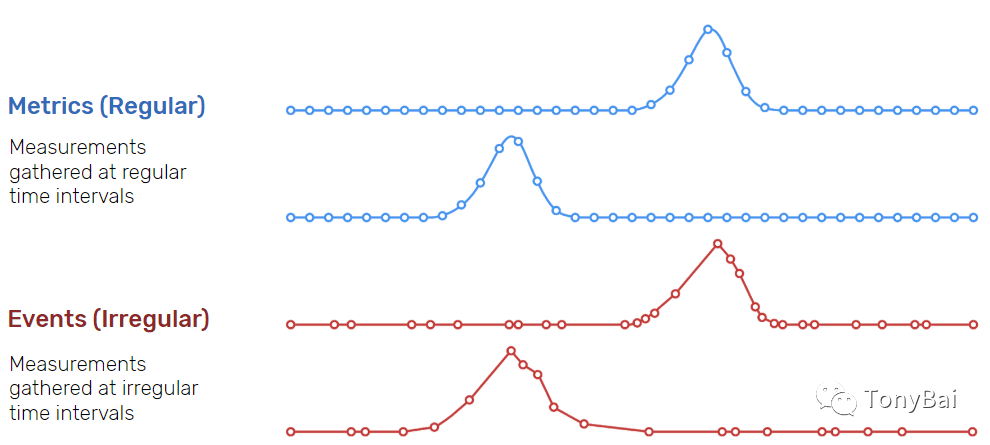
时序数据,亦称时间序列数据,是指按时间顺序记录的、具有时间戳的数据点。这些数据点可能是连续的(如下图上部的metrics),例如每秒记录一次;也可能是不规律的,例如在特定事件发生时的记录(如下图下部的events):
时序数据在多个领域具有广泛的应用,如金融市场的股票价格、气候科学的气象数据、工业设备的运行数据、物联网数据以及车联网数据等,如下图(此图来自网络):
时序数据有着几个鲜明的特点:
时间戳
时序数据是与时间相关的数据,每个数据点都有一个时间戳或时间范围来标识其产生或记录的时间。
大数据量
时序数据通常是大数据量的,需要处理大量的持续不断的数据点。
数据流
从源头流来的时序数据量往往是不间断的。
数据量是不可预测的
可能会在不规则的时间间隔内突然传来大量的数据。这在金融市场上非常常见,事件发生后交易量会出现峰值,而这是很难预测的。
实时性
时序数据常常需要实时处理分析,以便及时采取行动或在数据发生变化时发出警报。异常情况检测就是一个很好的例子。
追加写入
新的数据点会追加到已有数据的末尾,而不是或极少是修改或删除已有的数据。并且绝大多数情况下,时序数据是按照时间顺序排列的。
我们看到时序数据和传统的OLTP(联机事务处理)数据具有很多不同的特点,这些不同决定了基于时序数据的数据库管理系统所采用的数据模型、处理的数据规模、数据的访问方式、数据的处理频率、数据的处理方式都有很多不同。
那么当前主流时序数据库是如何存储、处理和管理时序数据的呢?我们继续向下看。
2. 时间线:时序数据库对时序数据的建模
初次了解和学习时序数据库(tsdb)的时候,你都会学到一个叫**时间线(Time Series)**的术语,无论你学习的是InfluxDB、Prometheus还是TDengine亦或其他。
Influxdb的联合创始人Paul Dix对tsdb中时间线的理解如下:

Paul认为时间线是解释和理解时序数据的一种方法。其实时间线就是时序数据库界对时序数据的一种建模,时序数据库就是围绕时间线这个模型进行设计和实现的,当然不同的时序数据库所建立的时间线模型略有差异,模型能力也有差别。
有了时间线这个模型后,我们可以将时序数据库重新定义为:用于存储时间线的系统。
下面我们就以Influxdb 2.x为例来看看一个真实的时序数据库中的时间线模型。
2.1 InfluxDB 2.x的Line Protocol
提到时间线,就不能不提到InfluxDB用于写入数据点(data point)的Line Protocol[1],这是目前时序数据库领域的一个流行的时序数据库ingest(数据摄取)协议。通过Line Protocol我们能直观地看到influxdb 2.x对时间线的建模形式。下面是Line Protocol手册中定义的语法和一个示例:
// Syntax
<measurement>[,<tag_key>=<tag_value>[,<tag_key>=<tag_value>]] <field_key>=<field_value>[,<field_key>=<field_value>] [<timestamp>]
// Example
myMeasurement,tag1=value1,tag2=value2 fieldKey="fieldValue" 1556813561098000000下面Paul Dix一个PPT中的例子的图以及Line Protocol手册中的图,都可以看的更直观一些:


我们看到:在InfluxDB中,通过Line Protocol插入的一条时序数据包含四个部分:
measurement
时序数据的类别,如温度、湿度等。measurement类似于关系数据库中的一个表名,每个时序数据点都归到一个measurement中。这个部分是必选的。
tag
时序数据点的标签集合。标签用于描述数据的属性或特征,比如产生的地点、设备的型号等。对每个时序数据点,InfluxDB支持为之打多个标签(tag),每个标签是一个键值对,多个标签用逗号分隔。不过,tag这部分是可选字段,并且tag的键值对都是string类型。
field
field部分是时序数据点的指标集合,即时序数据的有效载荷部分,这部分放置的是要得到的field,一个键值对,包括指标名和对应的值。如果要摄入的是某地的天气信息,这里就可以用temperature=35.3,humidity=0.7;如果采集的是某只股票的股价,那么这里可以用price=201。
field部分是必选字段,至少应该有一个键值对。和tag不同,field键值对的值部分支持数值、布尔值和字符串。
timestamp
顾名思义,这部分是时间戳,是数据点的收集时间。Line Protocol中这部分可空,一旦为空,那么数据点的时间戳就会被默认置为当前时间。
那么,InfluxDB基于Line Protocol定义的时间线究竟是什么呢?接下来我们就来看一下。
2.2 时间线与时间点
有了对Line Protocol各部分的认知,再来理解InfluxDB定义的时间线就容易多了。
InfluxDB定义的时间线由两部分组成,一部分是时间线key,另外一部分则是时间线的value集合。
时间线key(time series key):由measurement+tags+field_name构成。每个time series key唯一标识/索引一条时间线。
时间线的value集合(time series values):是一个(时间戳, field_value)的二元组的集合。
注:我们看到tag name 和tag value都是时间线key的一部分,但field仅name是,这也是tag和field的重要差别之一。
看一个Paul Dix的PPT中的例子,下面是用Line Protocol摄取的数据:
weather,city=Denver,state=CO,zip=80222 temp=62.3,humidity=32
weather,city=Bellevue,state=WA,zip=98007 temp=50.7,humidity=76
weather,city=Brooklyn,state=NY,zip=11249 temp=58.2,humidity=55我们来分析一下,这三条Line Protocol数据中究竟包含有几条时间线!根据时间线key唯一标识一条时间线以及时间线key的定义,我们能得到六种measurement+tags+field_name的组合,即六条时间线:
weather,city=Denver,state=CO,zip=80222#temp
weather,city=Denver,state=CO,zip=80222#humidity
weather,city=Bellevue,state=WA,zip=98007#temp
weather,city=Bellevue,state=WA,zip=98007#humidity
weather,city=Brooklyn,state=NY,zip=11249#temp
weather,city=Brooklyn,state=NY,zip=11249#humidity这样来看,之前摄取的数据在每条时间线上只录入了一个数据点(即时间点)。以第一条时间线为例,其摄入(ingest)的数据点为:
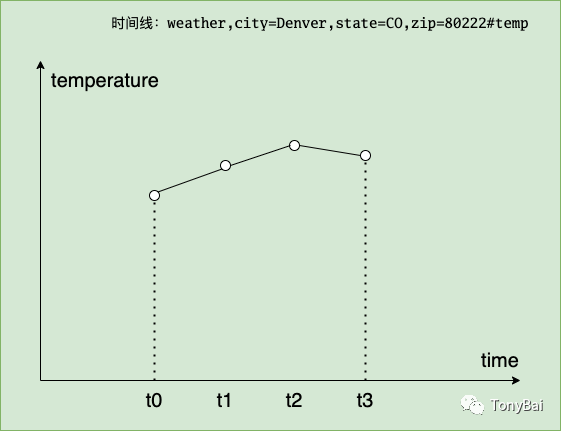
时间线key:weather,city=Denver,state=CO,zip=80222#temp
时间线value:(62.3, t0) // t0表示摄入时的时间戳为了更好体现时间线与时间点的关系,我们再利用Line Protocol在上述时间线上加几个数据点:
weather,city=Denver,state=CO,zip=80222 temp=64.3,humidity=42 // t1
weather,city=Denver,state=CO,zip=80222 temp=65.3,humidity=43 // t2
weather,city=Denver,state=CO,zip=80222 temp=64.9,humidity=45 // t3这样形成的时间线为:
时间线key:weather,city=Denver,state=CO,zip=80222#temp
时间线value集合:[(62.3, t0), (64.3, t1), (65.3, t2), (64.9, t3)]我们针对这条时间线可以直观地画出Denvor的温度趋势图(x轴为时间,y轴是denvor的温度变化):
这样看来,Line Protocol一次可以在多个时间线上各自插入一个时间点。
注:以上是influxdb 2.x对时序数据的建模。influxdb 3.0,即influxdb iox[2]对time series做了重新建模,回归了table的方式:measurement <=> table,其余标签、字段、时间戳都变成了column(列)。
InfluxDB的时间线抽象非常重要,它对influxdb的存储引擎、查询引擎等的设计有着重要影响。关于时序数据库还有一个重要的问题需要清楚认知,那就是基数(Cardinality),下面我们就来说说tsdb的基数。
3 时序数据库的基数
基数并非时序数据库专有的概念,传统关系型数据库中就有基数的概念。《SQL优化核心思想》[3]的第一章第一节讲的就是基数。书中给出的定义是:某个列唯一键(distinct keys)的数量叫作基数。书中还给出了一个比较好理解的例子。比如:性别列,其数值要么是男,要么是女,所以该列的基数为2。
那么InfluxDB是如何定义一个时序数据库相关的基数的呢?简单来说就是唯一时间线的数量。如果一个数据库只有一个measurement,那么定义该measurement的基数,就是这个measurement下的唯一时间线的数量,下面是一个例子:
measurement1:
- 2个tag
- tag1:有3个唯一值
- tag2:有4个唯一值
- 5个field该measurement1的基数为3x4x5=60。
在InfluxDB 2.x版本中,高基数意味着时间线的膨胀,可能会影响读写性能。因为高基数会增加索引大小,导致内存使用增加、查询性能下降和更长的索引维护时间。同时,高基数还会导致写入速度降低、查询执行时间变长、磁盘空间使用增加和压缩和数据维护操作变得更加复杂和耗时。为了减轻高基数对InfluxDB读写性能的影响,可以采取一些措施,如仔细设计数据模型(减少高基数维度)、使用连续查询或任务进行预聚合、或使用刚刚发布没多久的、号称支持无限时间线的InfluxDB 3.0等。
4. 小结
时序数据在现实世界中具有广泛的应用。时序数据库,如InfluxDB 2.x,采用时间线作为基本的数据结构以高效地建模、查询和管理时序数据。然而,高基数数据仍然是时序数据库面临的一个重要挑战。理解时序数据库中的时间线以及其优缺点,有助于我们更好地利用时序数据库解决实际问题。
5. 参考资料
OpenMetric与时序数据库存储模型分析 - https://zhuanlan.zhihu.com/p/410255386
Why time series - https://www.influxdata.com/time-series-database/
The Journey of InfluxDB - https://youtu.be/sfHaYdcDaAY
Time Series Data, Cardinality, and InfluxDB - https://www.influxdata.com/blog/time-series-data-cardinality-influxdb/
influxdb 2.x时间线基数 - https://docs.influxdata.com/influxdb/v2.6/reference/glossary/#series-cardinality
influxdb 2.x storage engine - https://docs.influxdata.com/influxdb/v2.6/reference/internals/storage-engine/
Line Protocol - https://docs.influxdata.com/influxdb/v2.6/reference/syntax/line-protocol/
“Gopher部落”知识星球[4]旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!2023年,Gopher部落将进一步聚焦于如何编写雅、地道、可读、可测试的Go代码,关注代码质量并深入理解Go核心技术,并继续加强与星友的互动。欢迎大家加入!




著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址[5]:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻)归档仓库 - https://github.com/bigwhite/gopherdaily
我的联系方式:
微博(暂不可用):https://weibo.com/bigwhite20xx
微博2:https://weibo.com/u/6484441286
博客:tonybai.com
github: https://github.com/bigwhite

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。
参考资料
[1]
Line Protocol: https://docs.influxdata.com/influxdb/v2.6/reference/syntax/line-protocol/
[2]influxdb iox: https://github.com/influxdata/influxdb_iox
[3]《SQL优化核心思想》: https://book.douban.com/subject/30214851/
[4]“Gopher部落”知识星球: https://wx.zsxq.com/dweb2/index/group/51284458844544
[5]链接地址: https://m.do.co/c/bff6eed92687