引言
在隐马尔可夫模型中介绍了HMM的理论部分,为了巩固理论知识,本文基于HMM实现中文分词。具体来说,通过HMM实现基于字级别的分词算法。
HMM

这里简单说明一下,更详细的请参考隐马尔可夫模型。
这里输入序列为 X 1 : N X_{1:N} X1:N,是可观测的。每个输入对应是不可观测的隐状态,一一对应。
在中文分词任务中,输入序列中每个元素就是句子中的每个字,对应的隐藏状态就是下面介绍的SBME中的一种。
语料说明
首先,对语料进行说明。在中文分词中,通常用SBME字标注法来标注语料,标注单位为字。
-
S: Single token 单字词
-
B: Begin of token 词语(标记)的开始
-
M: Middle of token 词语的中间
-
E: End of token 词语的结尾
以“小明毕业于北京大学”为例,假设分词结果为"小明/毕业/于/北京/大学",那么对应的标注结果为"BE/S/BE/BE"。
这里句子“小明毕业于北京大学”就是我们的观测序列,是可以可以看到的。而对应的标注结果,或者说状态序列是"BESBEBE",是我们要预测的隐状态序列。有了这个隐状态序列,我们就可以进行中文分词。
从这个标注法我们可以得到一些信息,比如E和M不可能出现在句子的开头;B和M后面为M或E等。
我们这里基于监督学习方法来得到HMM模型的参数,即给定一些已经分好词的语料。但通常是没有对应的SBME标注,需要我们自己标记上。
这里用的语料是人民日报语料库,是已经分好词的,大概长这样:
十亿 中华 儿女 踏上 新 的 征 程 。
过去 的 一 年 ,
是 全国 各族 人民 在 中国 共产党 领导 下 ,
在 建设 有 中国 特色 的 社会主义 道路 上 ,
下载地址:链接:https://pan.baidu.com/s/1lqPXyLp12-X0k1WTXLbZkQ?pwd=ye56 提取码:ye56
标注语料
本节编写标注语料的代码,同时有了观测数据和对应的隐藏状态后,这是监督学习问题,我们可以利用极大似然估计法来估计HMM的参数。
算法如下:
1.转移概率 a i j a_{ij} aij的估计
设样本中时刻
t
t
t处于状态
i
i
i,时刻
t
+
1
t+1
t+1转到到状态
j
j
j的频数为
A
i
j
A_{ij}
Aij,那么状态转移概率
a
i
j
a_{ij}
aij的估计是
a
^
i
j
=
A
i
j
∑
j
N
A
i
j
,
i
=
1
,
2
,
⋯
,
N
;
j
=
1
,
2
,
⋯
,
N
\hat a_{ij} = \frac{A_{ij}}{\sum_j^N A_{ij}},\quad i=1,2,\cdots,N; \quad j=1,2,\cdots,N
a^ij=∑jNAijAij,i=1,2,⋯,N;j=1,2,⋯,N
2.观测概率
b
j
(
k
)
b_j(k)
bj(k)的估计
设样本中状态为
j
j
j并观测为
k
k
k的频数是
B
j
k
B_{jk}
Bjk,那么状态为
j
j
j观测为
k
k
k的概率
b
j
(
k
)
b_j(k)
bj(k)的估计是
b
^
j
(
k
)
=
B
j
k
∑
k
=
1
M
B
j
k
,
j
=
1
,
2
,
⋯
,
N
;
k
=
1
,
2
,
⋯
,
M
\hat b_j(k) = \frac{B_{jk}}{\sum_{k=1}^M B_{jk}}, \quad j=1,2,\cdots,N; \quad k=1,2,\cdots, M
b^j(k)=∑k=1MBjkBjk,j=1,2,⋯,N;k=1,2,⋯,M
3.初始状态概率
π
i
\pi_i
πi的估计
π
^
i
\hat \pi_i
π^i为
S
S
S个样本中初始状态为
q
i
q_i
qi的频率
比如要把"过去 的 一 年 ,“标注成"BE S BE”。核心代码如下:
for line in lines:
line_num += 1
# 处理每行
# 先去掉前后空白符
line = line.strip()
# 如果去掉空格后变成了空行
if not line:
continue
# 根据空白符分隔
tokens = line.split()
# 加入到token集合
seen_tokens.update(tokens)
# 添加对应的状态 BMES
states = []
for token in tokens:
if len(token) == 1:
# 单字词,对应S
states.append("S")
else:
states.append("B" + "M" * (len(token) - 2) + "E")
# 现在有了token,以及对应的状态: 比如 [我 是 中国人] [S S BME]
# 但是此时需要将它们拼起来,变成 我是中国国人 SSBME
token_line = "".join(tokens)
state_line = "".join(states)
# 它们俩的长度应该相等
assert len(token_line) == len(state_line)
这里逐行标注,代码很简单,因为我们以经有了分词结果,直接套用SMBE的规则即可。
注意,我们对语料库中的样本按行拆分,即每行就是一个样本。这样len(token_line)就是样本长度,i=0的位置为第一个字。当i=0时,我们更新初始状态统计init_counter,对应算法中的
π
^
i
\hat \pi_i
π^i:
for i in range(len(token_line)):
# 初始状态
if i == 0:
init_counter[state_line[i]] += 1
else:
# 由i-1状态变成i状态的频次
# 更新A
A_counter[state_line[i - 1]][state_line[i]] += 1
# 更新B 状态为i观测为字char的频数
B_counter[state_line[i]][token_line[i]] += 1
有了 A , B , π A,B,\pi A,B,π的统计后,我们就可以计算三个概率:
# 计算初始概率
# 所有初始状态的频数之和
total_init_chars = sum(init_counter.values())
for state, value in init_counter.items():
# 所有的概率计算都取对数,使得后面的概率连乘变成连加
self.init_prob[state] = log(value / total_init_chars)
# 计算状态转移概率
for state, state_dict in A_counter.items():
# state_dict 是当前状态 state 转移到其他状态(包括自己)的频次
total_state_count = sum(state_dict.values())
for s, v in state_dict.items():
self.trans_mat[state][s] = log(v / total_state_count)
# 计算发射概率
for state, state_dict in B_counter.items():
# state_dict 是当前状态 state 观测到不同char的频次
total_char_count = sum(state_dict.values())
for ch, value in state_dict.items():
self.emission_prob[state][ch] = log(value / total_char_count)
这里为了防止很小的概率连乘后导致数值下溢,我们对概率取对数,使得后面所有连乘的地方变成了连加。
最后看一下计算出来的结果。
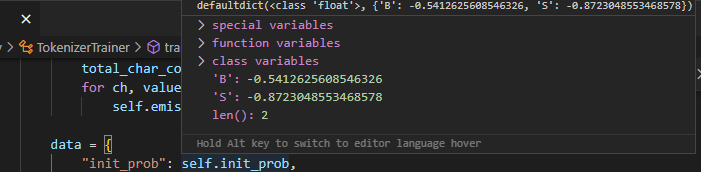
上图是init_prob的结果,可以看到它只有BS作为句子开头的情况,这符合我们的直觉。这是一个负的值,就是概率取对数之后的结果,想要变回概率直接取指数即可。
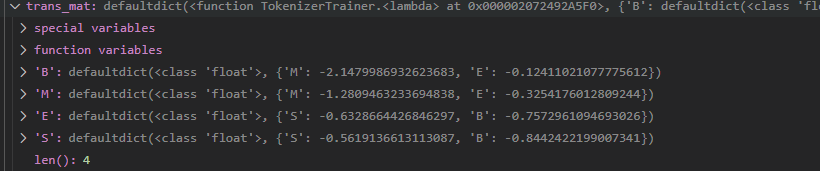
还有一个有意思的是转移概率,这里用的是嵌套字典来保存。保存外面字典的key的状态转移到嵌套字典内key状态的概率。比如第一条记录保存了状态B转移到状态M和E的概率。这也符合标注法的定义,因为B不能转移到S和B。
对于这种情况,我们可以给B转移到S赋值概率0,在对数的情况下,我们设置一个_MIN_FLOAT,并认为log(0)=_MIN_FLOAT。
完整代码
from collections import defaultdict
from math import log
import json
"""
("B", "M", "E", "S")
用于分词的几个状态:
B: Begin of token 单词(标记)的开始
M: Middle of token 单词的中间
E: End of token 单词的结尾
S: Single token 单字词
"""
class TokenizerTrainer:
init_prob: dict = defaultdict(float) # π 初始概率
trans_mat: dict = defaultdict(lambda: defaultdict(float)) # 状态转移概率
emission_prob: dict = defaultdict(lambda: defaultdict(float)) # 发射概率(观测概率)
def __init__(
self,
input_path: str,
output_path: str = "output.json",
verbose: bool = False,
print_every: int = 10000,
) -> None:
"""初始化分词训练器
Args:
input_path (str): 输入文件路径
output_path (str, optional): 输出文件路径,json格式 . Defaults to "output.json".
verbose (bool, optional): 是否打印信息. Defaults to False.
print_every (int, optional): 打印的话,处理多少行后打印一次. Defaults to 10000.
"""
self.input_path = input_path
self.output_path = output_path
self.verbose = verbose
self.print_every = print_every
def train(self):
"""开始训练,先基于字典保存"""
# 对概率值取对数, 连乘变成连加
A_counter = defaultdict(lambda: defaultdict(int)) # 由状态i转移到状态j的频数
B_counter = defaultdict(lambda: defaultdict(int)) # 状态为j观测为k的频数
init_counter = defaultdict(int) # 状态i作为初始状态的频数
line_num = 0 # 当前处理的行数
seen_tokens = set() # 已保存的token
with open(self.input_path, "r", encoding="utf-8") as f:
lines = f.readlines()
# 注意,每行相当于一个样本,而不是每个单词
for line in lines:
# 可能的问题 数字和中文连在一起了,比如 6年 1日
line_num += 1
# 处理每行
# 先去掉前后空白符
line = line.strip()
# 如果去掉空格后变成了空行
if not line:
continue
# 根据空白符分隔
tokens = line.split()
# 加入到token集合
seen_tokens.update(tokens)
# 添加对应的状态 BMES
states = []
for token in tokens:
if len(token) == 1:
# 单字词,对应S
states.append("S")
else:
states.append("B" + "M" * (len(token) - 2) + "E")
# 现在有了token,以及对应的状态: 比如 [我 是 中国人] [S S BME]
# 但是此时需要将它们拼起来,变成 我是中国国人 SSBME
token_line = "".join(tokens)
state_line = "".join(states)
# 它们俩的长度应该相等
assert len(token_line) == len(state_line)
for i in range(len(token_line)):
# 初始状态
if i == 0:
init_counter[state_line[i]] += 1
else:
# 由i-1状态变成i状态的频次
# 更新A
A_counter[state_line[i - 1]][state_line[i]] += 1
# 更新B 状态为i观测为字char的频数
B_counter[state_line[i]][token_line[i]] += 1
if self.verbose and line_num % self.print_every == 0:
print(line_num)
print(f"Total tokens size: {len(seen_tokens)}.")
print(
"Complete the calculation of A and B, and now start calculating their log probabilities."
)
# 计算初始概率
# 所有初始状态的频数之和
total_init_chars = sum(init_counter.values())
for state, value in init_counter.items():
# 所有的概率计算都取对数,使得后面的概率连乘变成连加
self.init_prob[state] = log(value / total_init_chars)
# 计算状态转移概率
for state, state_dict in A_counter.items():
# state_dict 是当前状态 state 转移到其他状态(包括自己)的频次
total_state_count = sum(state_dict.values())
for s, v in state_dict.items():
self.trans_mat[state][s] = log(v / total_state_count)
# 计算发射概率
for state, state_dict in B_counter.items():
# state_dict 是当前状态 state 观测到不同char的频次
total_char_count = sum(state_dict.values())
for ch, value in state_dict.items():
self.emission_prob[state][ch] = log(value / total_char_count)
data = {
"init_prob": self.init_prob,
"trans_mat": self.trans_mat,
"emission_prob": self.emission_prob,
"chars": list(
{char for token in seen_tokens for char in token}
), # 所有训练数据中已知的字(char) ,set不能用于JSON序列号,先转换为set去重后,再转换为list
}
with open(self.output_path, "w", encoding="utf-8") as f:
# 计算完成,保存
json.dump(data, f)
print(f"Success save data to {self.output_path}")
if __name__ == "__main__":
trainer = TokenizerTrainer(".\data\RenMinData.txt_utf8", verbose=True)
trainer.train()
计算出来以后通过JSON保存计算结果,用之前可以直接读取。
>>> python .\train.py
10000
20000
30000
40000
50000
60000
70000
80000
90000
100000
110000
120000
130000
140000
150000
160000
170000
180000
190000
200000
210000
220000
230000
240000
250000
260000
270000
280000
290000
Total tokens size: 25005.
Complete the calculation of A and B, and now start calculating their log probabilities.
Success save data to output.json
下面来实现预测算法,这里用维特比算法。
实现预测算法
同样,把算法和示例贴过来。
维特比算法
输入: 模型 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π)和观测 O = ( o 1 , o 2 , ⋯ , o T ) O=(o_1,o_2,\cdots,o_T) O=(o1,o2,⋯,oT);
输出: 最优路径 I ∗ = ( i 1 ∗ , i 2 ∗ , ⋯ , i T ∗ ) I^* = (i^*_1,i^*_2,\cdots,i^*_T) I∗=(i1∗,i2∗,⋯,iT∗)。
(1) 初始化
δ
1
(
i
)
=
π
i
b
i
(
o
1
)
,
i
=
1
,
2
,
⋯
,
N
Ψ
1
(
i
)
=
0
,
i
=
1
,
2
,
⋯
,
N
\delta_1(i) = \pi_ib_i(o_1), \quad i=1,2,\cdots,N \\ \Psi_1(i) = 0, \quad i=1,2,\cdots,N
δ1(i)=πibi(o1),i=1,2,⋯,NΨ1(i)=0,i=1,2,⋯,N
在时刻
t
=
1
t=1
t=1状态为
i
i
i的概率最大值即为初始概率乘以
b
i
(
o
1
)
b_i(o_1)
bi(o1),
Ψ
1
(
i
)
=
0
\Psi_1(i)=0
Ψ1(i)=0表示未知,或者说后面回溯时的终止条件。
(2) 递推。对
t
=
2
,
3
,
⋯
,
T
t=2,3,\cdots,T
t=2,3,⋯,T
δ
t
(
i
)
=
max
1
≤
j
≤
N
[
δ
t
−
1
(
j
)
a
j
i
]
b
i
(
o
t
)
,
i
=
1
,
2
,
⋯
,
N
Ψ
t
(
i
)
=
arg
max
1
≤
j
≤
N
[
δ
t
−
1
(
j
)
a
j
i
]
,
i
=
1
,
2
,
⋯
,
N
\delta_t(i) = \max_{1 \leq j \leq N} [\delta_{t-1}(j)a_{ji}]b_i(o_{t}),\quad i=1,2,\cdots,N \\ \Psi_t(i) = \arg \max_{1 \leq j \leq N} [\delta_{t-1}(j)a_{ji}],\quad i=1,2,\cdots,N
δt(i)=1≤j≤Nmax[δt−1(j)aji]bi(ot),i=1,2,⋯,NΨt(i)=arg1≤j≤Nmax[δt−1(j)aji],i=1,2,⋯,N
根据递归公式由前一时刻的最大值来计算当前时刻。
(3) 终止
终止就是计算各个状态的最大概率:
P
∗
=
max
1
≤
i
≤
N
δ
T
(
i
)
i
T
∗
=
arg
max
1
≤
i
≤
N
[
δ
T
(
i
)
]
P^* = \max_{1 \leq i \leq N} \delta_T(i) \\ i^*_T = \arg \max_{1 \leq i \leq N} [\delta_T(i)]
P∗=1≤i≤NmaxδT(i)iT∗=arg1≤i≤Nmax[δT(i)]
(4) 最优路径回溯。对
t
=
T
−
1
,
T
−
2
,
⋯
,
1
t=T-1,T-2,\cdots,1
t=T−1,T−2,⋯,1
上一步得到的
T
T
T时刻的终结点,然后从
T
−
1
T-1
T−1时刻利用
i
T
−
1
∗
=
Ψ
T
(
i
T
∗
)
i^*_{T-1}=\Psi_{T}(i^*_{T})
iT−1∗=ΨT(iT∗)求得
T
T
T时刻状态为
i
T
∗
i^*_T
iT∗概率最大路径的前一个时刻最优结点
i
T
−
1
∗
i^*_{T-1}
iT−1∗,以此类推:
i
t
∗
=
Ψ
t
+
1
(
i
t
+
1
∗
)
i_t^* = \Psi_{t+1}(i^*_{t+1})
it∗=Ψt+1(it+1∗)
求得最优路径
I
∗
=
(
i
1
∗
,
i
2
∗
,
⋯
,
i
T
∗
)
I^*=(i_1^*,i_2^*,\cdots,i_T^*)
I∗=(i1∗,i2∗,⋯,iT∗)。
下面通过书上的例子,并画图来理解一下维特比算法。
例 10.3 已知模型参数 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π)和观测序列 O = ( 红,白,红 ) O=(红,白,红) O=(红,白,红),试求最优状态序列,即最优路径。
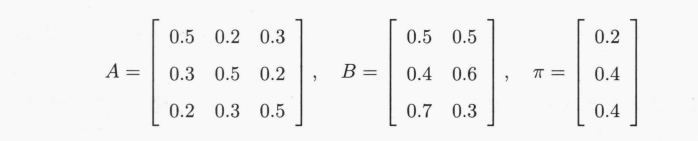
按照上面介绍的维特比算法一步一步来求。
对于
t
=
1
t=1
t=1,即初始化时,对所有的状态
i
(
i
=
1
,
2
,
3
)
i\,\,(i=1,2,3)
i(i=1,2,3)求状态为
i
i
i观测
o
1
o_1
o1为红球的概率
δ
1
(
i
)
\delta_1(i)
δ1(i):
δ
1
(
1
)
=
π
1
b
1
(
o
1
)
=
0.2
×
0.5
=
0.10
δ
1
(
2
)
=
π
2
b
2
(
o
1
)
=
0.4
×
0.4
=
0.16
δ
1
(
3
)
=
π
3
b
3
(
o
1
)
=
0.4
×
0.7
=
0.28
\delta_1(1) = \pi_1b_1(o_1) = 0.2 \times 0.5 = 0.10 \\ \delta_1(2) = \pi_2b_2(o_1) = 0.4 \times 0.4 = 0.16 \\ \delta_1(3) = \pi_3b_3(o_1) = 0.4 \times 0.7 = 0.28
δ1(1)=π1b1(o1)=0.2×0.5=0.10δ1(2)=π2b2(o1)=0.4×0.4=0.16δ1(3)=π3b3(o1)=0.4×0.7=0.28
且
Ψ
1
(
i
)
=
0
,
i
=
1
,
2
,
3
\Psi_1(i) = 0, \quad i=1,2,3
Ψ1(i)=0,i=1,2,3。
此时,如下图所示:

对于 t = 2 t=2 t=2,对所有的状态 i ( i = 1 , 2 , 3 ) i\,\,(i=1,2,3) i(i=1,2,3)求状态为 i i i观测 o 2 o_2 o2为白球的概率 δ 2 ( i ) \delta_2(i) δ2(i)。
对于
i
=
1
i=1
i=1有:
δ
2
(
1
)
=
max
1
≤
j
≤
3
[
δ
1
(
j
)
a
j
1
]
b
1
(
o
2
)
=
max
[
0.1
×
0.5
,
0.16
×
0.3
,
0.28
×
0.2
]
×
0.5
=
0.056
×
0.5
=
0.028
\delta_2(1) = \max_{1 \leq j \leq 3} [\delta_{1}(j)a_{j1}]b_1(o_{2}) = \max [0.1 \times 0.5,0.16 \times 0.3,0.28 \times 0.2] \times 0.5 = 0.056 \times 0.5 = 0.028
δ2(1)=1≤j≤3max[δ1(j)aj1]b1(o2)=max[0.1×0.5,0.16×0.3,0.28×0.2]×0.5=0.056×0.5=0.028
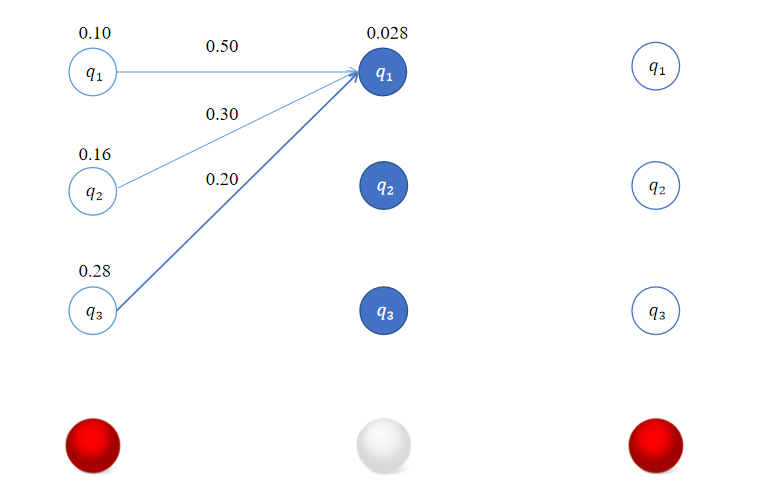
类似地,对于
i
=
2
i=2
i=2有:
δ
2
(
2
)
=
max
1
≤
j
≤
3
[
δ
1
(
j
)
a
j
2
]
b
2
(
o
2
)
=
max
[
0.1
×
0.2
,
0.16
×
0.5
,
0.28
×
0.3
]
×
0.6
=
0.084
×
0.6
=
0.0504
\delta_2(2) = \max_{1 \leq j \leq 3} [\delta_{1}(j)a_{j2}]b_2(o_{2}) = \max [0.1\times 0.2,0.16 \times 0.5,0.28 \times 0.3] \times 0.6 = 0.084 \times 0.6 = 0.0504
δ2(2)=1≤j≤3max[δ1(j)aj2]b2(o2)=max[0.1×0.2,0.16×0.5,0.28×0.3]×0.6=0.084×0.6=0.0504
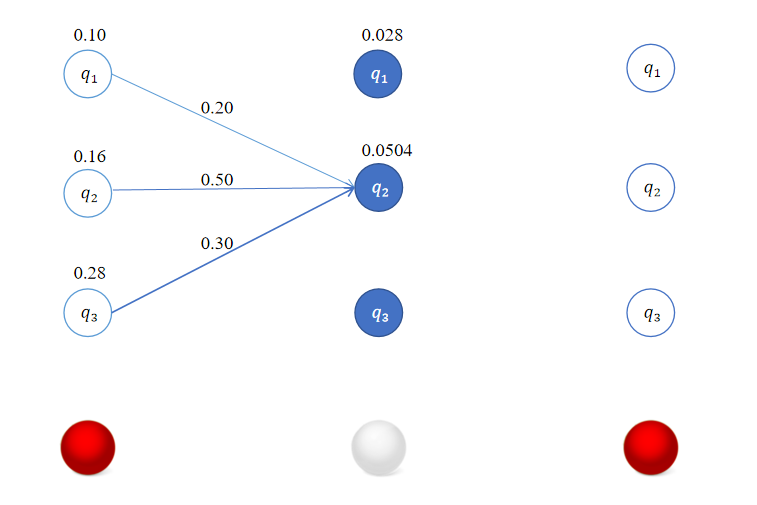
对于
i
=
3
i=3
i=3有:
δ
2
(
3
)
=
max
1
≤
j
≤
3
[
δ
1
(
j
)
a
j
3
]
b
3
(
o
2
)
=
max
[
0.1
×
0.3
,
0.16
×
0.2
,
0.28
×
0.5
]
×
0.3
=
0.14
×
0.3
=
0.042
\delta_2(3) = \max_{1 \leq j \leq 3} [\delta_{1}(j)a_{j3}]b_3(o_{2}) = \max [0.1\times 0.3,0.16 \times 0.2,0.28 \times 0.5] \times 0.3 = 0.14 \times 0.3 = 0.042
δ2(3)=1≤j≤3max[δ1(j)aj3]b3(o2)=max[0.1×0.3,0.16×0.2,0.28×0.5]×0.3=0.14×0.3=0.042
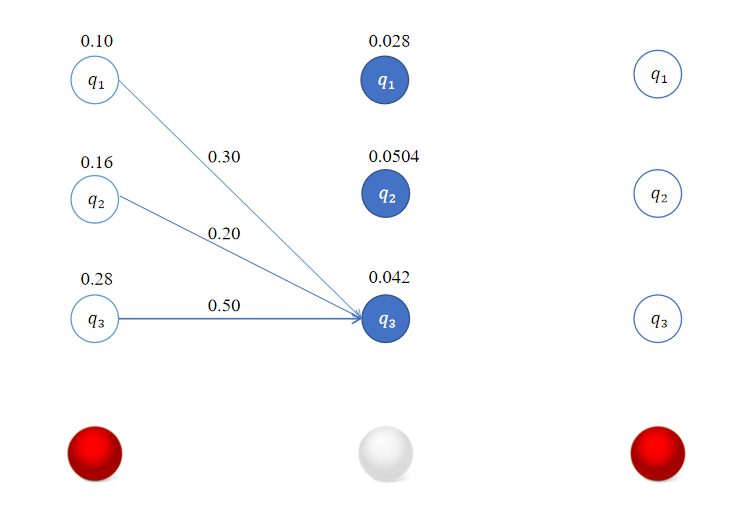
这样我们得到了在时刻 t = 2 t=2 t=2时,转移到各个状态的最优路径,这里恰巧它们都是从 t = 1 t=1 t=1时状态 q 3 q_3 q3出发的。
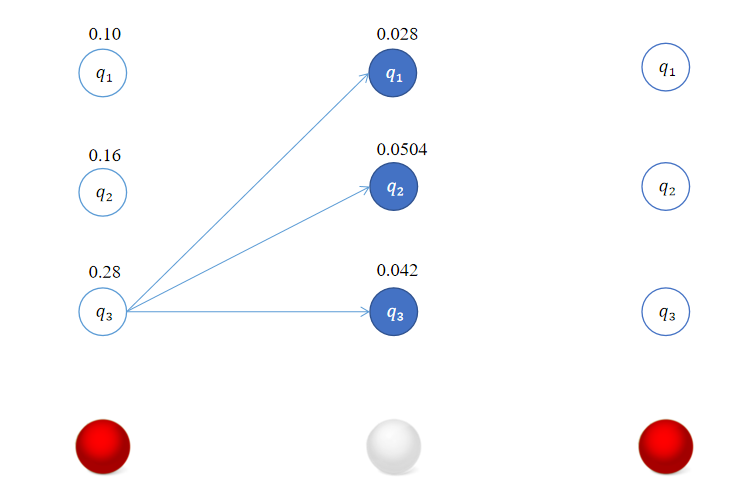
同理,对于
t
=
3
t=3
t=3,对所有的状态
i
(
i
=
1
,
2
,
3
)
i\,\,(i=1,2,3)
i(i=1,2,3)求状态为
i
i
i观测
o
3
o_3
o3为红球的概率
δ
3
(
i
)
\delta_3(i)
δ3(i)。
δ
3
(
1
)
=
max
1
≤
j
≤
3
[
δ
2
(
j
)
a
j
1
]
b
1
(
o
3
)
=
max
[
0.028
×
0.5
,
0.0504
‾
×
0.3
,
0.042
×
0.2
]
×
0.5
=
0.01512
×
0.5
=
0.000756
δ
3
(
2
)
=
max
1
≤
j
≤
3
[
δ
2
(
j
)
a
j
2
]
b
2
(
o
3
)
=
max
[
0.028
×
0.2
,
0.0504
‾
×
0.5
,
0.042
×
0.3
]
×
0.4
=
0.02520
×
0.4
=
0.001008
δ
3
(
3
)
=
max
1
≤
j
≤
3
[
δ
2
(
j
)
a
j
3
]
b
3
(
o
3
)
=
max
[
0.028
×
0.3
,
0.0504
×
0.2
,
0.042
‾
×
0.5
]
×
0.7
=
0.02100
×
0.7
=
0.001470
\delta_3(1) = \max_{1 \leq j \leq 3} [\delta_{2}(j)a_{j1}]b_1(o_{3}) = \max [0.028 \times 0.5,\overline{0.0504} \times 0.3,0.042 \times 0.2] \times 0.5 = 0.01512 \times 0.5 = 0.000756 \\ \delta_3(2) = \max_{1 \leq j \leq 3} [\delta_{2}(j)a_{j2}]b_2(o_{3}) = \max [0.028 \times 0.2,\overline{0.0504} \times 0.5,0.042 \times 0.3] \times 0.4 = 0.02520 \times 0.4 = 0.001008 \\ \delta_3(3) = \max_{1 \leq j \leq 3} [\delta_{2}(j)a_{j3}]b_3(o_{3}) = \max [0.028 \times 0.3,0.0504 \times 0.2,\overline{0.042} \times 0.5] \times 0.7 = 0.02100 \times 0.7 = 0.001470
δ3(1)=1≤j≤3max[δ2(j)aj1]b1(o3)=max[0.028×0.5,0.0504×0.3,0.042×0.2]×0.5=0.01512×0.5=0.000756δ3(2)=1≤j≤3max[δ2(j)aj2]b2(o3)=max[0.028×0.2,0.0504×0.5,0.042×0.3]×0.4=0.02520×0.4=0.001008δ3(3)=1≤j≤3max[δ2(j)aj3]b3(o3)=max[0.028×0.3,0.0504×0.2,0.042×0.5]×0.7=0.02100×0.7=0.001470
最终我们得到的结果如下:
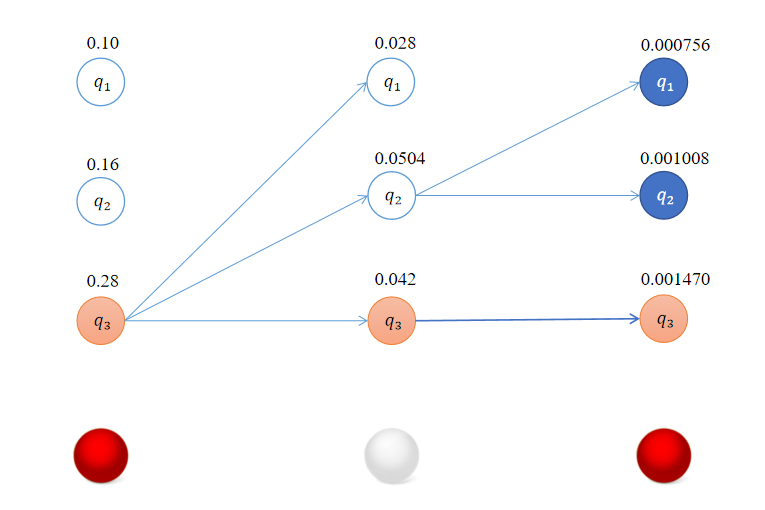
回溯得到最优路径的状态序列 ( q 3 , q 3 , q 3 ) (q_3,q_3,q_3) (q3,q3,q3)。
这个示例对应中文分词来说,不同颜色的球可以看成是不同的字,不同的状态可以看到是BMES中的一种。
本来计划基于中文分词一步一步重新画一个这样的图,但由于时间的关系暂时先不画了,应该也不难理解。
第一步是加载之前计算好的结果:
@classmethod
def load(cls, dict_path: str, verbose=False):
with open(dict_path, "r", encoding="utf-8") as f:
data_dict = json.load(f)
return cls(**data_dict, verbose=verbose)
核心代码如下,deltas就是算法中的
δ
\delta
δ,这里path进行了简化,直接保存最优路径。在实现的过程中参考了结巴分词的源码。
def viterbi(self, observations: str):
"""
基于log概率的维特比算法,所有的连乘变成连加
:observations: (str) 观测
"""
seq_len = len(observations)
deltas = [{}] # 保存所有时刻以状态结束的最优(对数)概率
path = {} # 记录当前最优的以状态结束的路径,保存的是一个列表
# 遍历所有状态
for s in self.states:
deltas[0][s] = self.init_prob[s] + self.emission_prob[s].get(
observations[0], _MIN_FLOAT
)
path[s] = [s]
for t in range(1, seq_len):
new_path = {} # 新路径
deltas.append({})
# 遍历所有状态
for cur_state in self.states:
# 返回最好的概率和对应的前一状态
log_prob, state = max(
[
(
deltas[t - 1][pre_state] # 前一状态的最优概率
+ self.trans_mat[pre_state].get(cur_state) # 前一状态 转移到 当前状态
+ self.emission_prob[cur_state].get(
observations[t], _MIN_FLOAT
), # 当前状态产生观测的概率
pre_state, # 对应的前一状态
)
for pre_state in self.valid_trans_states[
cur_state
] # 但并不需要遍历所有状态,只遍历能转移到当前状态的前一状态
]
)
deltas[t][cur_state] = log_prob
# 更新路径 ,注意 cur_state 在 + 右边,说明已经是顺序的,后续不需要逆序
new_path[cur_state] = path[state] + [cur_state]
path = new_path # 只保存概率最大的路径
if self.verbose:
print(
f"delta_{t+1}:{deltas[-1]}, {chr(10)}path:{['->'.join(v) for v in path.values()]}"
)
# 结尾只能有两种状态
log_prob, state = max((deltas[-1][state], state) for state in "ES")
return log_prob, path[state]
这里利用规则没有遍历所有的状态。
完整代码
from math import exp
from collections import defaultdict
import json
_MIN_FLOAT = -3.14e100 # 表示概率为0 ,假定log(0)≈-3.14e100
class HMMTokenizer:
def __init__(
self,
chars: list,
init_prob: dict,
trans_mat: dict,
emission_prob: dict,
verbose=False,
):
"""初始化HMM模型
Args:
chars (list): 所有可能的观测 all possible observation symbols
init_prob (dict, optional): 初始概率 π initial distribution.
trans_mat (dict, optional): 状态转移概率矩阵 A transition probs .
emission_prob (dict, optional): 观测概率矩阵 B emission probs.
verbose (bool, optional): 是否打印详细信息. Defaults to False.
"""
# 可能的状态个数 number of states of the model
self.M = len(chars) # 可能的观测个数 number of observations of the model
self.verbose = verbose
self.chars = set(chars) # 转变成set
self.init_prob = defaultdict(lambda: _MIN_FLOAT, init_prob)
self.trans_mat = trans_mat
self.emission_prob = emission_prob
self.states = (
emission_prob.keys()
) # 注意:如果 emission_prob 不包含所有的状态,那么需要做额外的处理。比如预先加入所有的状态作为它的key;或者加一个参数接收所有的状态。
self.N = len(self.states)
# 有效的状态转移矩阵
# {k for k in self.trans_mat if v in self.trans_mat[k]} 通过一个集合推导式,返回所有可以到达状态 v 的其他状态
valid_trans_states = {
v: {k for k in self.trans_mat if v in self.trans_mat[k]}
for v in self.states
}
self.valid_trans_states = valid_trans_states
def __str__(self) -> str:
"""简单打印出初始概率矩阵和转移概率矩阵,打印时将对数概率转回为概率"""
# chr(10) 就是"\n"
init_prob_str = (
f"{', '.join([f'{k}: {exp(v)}' for k, v in self.init_prob.items()])}"
)
trans_mat_str = f"{chr(10)}".join(
[
f"\t{k} -> {', '.join([f'{_k}: {exp(_v)}' for _k, _v in v.items()])}"
for k, v in self.trans_mat.items()
]
)
return f"init_prob:\t{init_prob_str}{chr(10)}trans_mat:{chr(10)}{trans_mat_str}"
@classmethod
def load(cls, dict_path: str, verbose=False):
with open(dict_path, "r", encoding="utf-8") as f:
data_dict = json.load(f)
return cls(**data_dict, verbose=verbose)
def viterbi(self, observations: str):
"""
基于log概率的维特比算法,所有的连乘变成连加
:observations: (str) 观测
"""
seq_len = len(observations)
deltas = [{}] # 保存所有时刻以状态结束的最优(对数)概率
path = {} # 记录当前最优的以状态结束的路径,保存的是一个列表
# 遍历所有状态
for s in self.states:
deltas[0][s] = self.init_prob[s] + self.emission_prob[s].get(
observations[0], _MIN_FLOAT
)
path[s] = [s]
for t in range(1, seq_len):
new_path = {} # 新路径
deltas.append({})
# 遍历所有状态
for cur_state in self.states:
# 返回最好的概率和对应的前一状态
log_prob, state = max(
[
(
deltas[t - 1][pre_state] # 前一状态的最优概率
+ self.trans_mat[pre_state].get(cur_state) # 前一状态 转移到 当前状态
+ self.emission_prob[cur_state].get(
observations[t], _MIN_FLOAT
), # 当前状态产生观测的概率
pre_state, # 对应的前一状态
)
for pre_state in self.valid_trans_states[
cur_state
] # 但并不需要遍历所有状态,只遍历能转移到当前状态的前一状态
]
)
deltas[t][cur_state] = log_prob
# 更新路径 ,注意 cur_state 在 + 右边,说明已经是顺序的,后续不需要逆序
new_path[cur_state] = path[state] + [cur_state]
path = new_path # 只保存概率最大的路径
if self.verbose:
print(
f"delta_{t+1}:{deltas[-1]}, {chr(10)}path:{['->'.join(v) for v in path.values()]}"
)
# 结尾只能有两种状态
log_prob, state = max((deltas[-1][state], state) for state in "ES")
return log_prob, path[state]
def cut(self, sentence: str):
log_prob, path = self.viterbi(sentence)
if self.verbose:
print(f"Best path:{''.join(path) }")
tokens = []
for ch, state in zip(sentence, path):
# BS是token的开头,添加新token
if state in "BS":
tokens.append(ch)
else:
# 否则为token的中间或结尾,直接拼接
tokens[-1] += ch
return tokens
if __name__ == "__main__":
hmm = HMMTokenizer.load("./output.json", True)
print(hmm)
text = "小明毕业于北京大学"
print(hmm.cut(text))
输出
>>> python hmm.py
init_prob: B: 0.5820129615148393, S: 0.4179870384851607
trans_mat:
B -> M: 0.1167175117318146, E: 0.8832824882681853
M -> M: 0.2777743117140081, E: 0.7222256882859919
E -> S: 0.5310673430644739, B: 0.46893265693552616
S -> S: 0.5701170084080499, B: 0.42988299159195004
delta_2:{'M': -16.23200813281353, 'E': -12.79051513085541, 'S': -15.71451997165292, 'B': -15.380359122017133},
path:['B->M', 'B->E', 'S->S', 'S->B']
delta_3:{'M': -29.14098381555806, 'E': -25.86403733079306, 'S': -23.60920635993498, 'B': -21.339561224083518},
path:['B->M->M', 'S->B->E', 'B->E->S', 'B->E->B']
delta_4:{'M': -28.49685029320371, 'E': -26.036620952624098, 'S': -32.07056168922347, 'B': -31.82000895013858},
path:['B->E->B->M', 'B->E->B->E', 'B->E->S->S', 'B->E->S->B']
delta_5:{'M': -37.41684192938396, 'E': -34.03592829777967, 'S': -32.91894505645745, 'B': -36.81528311897966},
path:['B->E->B->M->M', 'B->E->B->M->E', 'B->E->B->E->S', 'B->E->B->E->B']
delta_6:{'M': -45.30853777531357, 'E': -44.168420068955285, 'S': -41.598465424853714, 'B': -39.5480342822418},
path:['B->E->B->M->M->M', 'B->E->B->E->B->E', 'B->E->B->E->S->S', 'B->E->B->E->S->B']
delta_7:{'M': -47.498062227498764, 'E': -45.700381243389224, 'S': -50.449977143651296, 'B': -51.899180856604445},
path:['B->E->B->E->S->B->M', 'B->E->B->E->S->B->E', 'B->E->B->E->S->S->S', 'B->E->B->E->S->S->B']
delta_8:{'M': -53.470695174409244, 'E': -53.29099133942528, 'S': -51.91963296118969, 'B': -51.28742490259683},
path:['B->E->B->E->S->B->M->M', 'B->E->B->E->S->B->M->E', 'B->E->B->E->S->B->E->S', 'B->E->B->E->S->B->E->B']
delta_9:{'M': -57.92696974664399, 'E': -56.83450586180529, 'S': -59.64173365256305, 'B': -58.16609509813262},
path:['B->E->B->E->S->B->E->B->M', 'B->E->B->E->S->B->E->B->E', 'B->E->B->E->S->B->E->S->S', 'B->E->B->E->S->B->E->S->B']
Best path:BEBESBEBE
['小明', '毕业', '于', '北京', '大学']
可以看到,开启verbose后,打印了详细的信息。
比如,这里B作为初始状态的概率为58.2%,S作为初始状态的概率为41.7%。
由于这是针对字级别的分词,HMM算法有机会识别一些未登录词,比如"小明"这个词是语料中没有的。还有一个特点是,它倾向于拆分成双字词,比如“北京大学”这四个字组成的词语在语料库中是有的,但它还是拆分为”北京“和”大学“。
完整代码给出来了,分为两步,第一步利用train.py计算参数;第二步调用hmm.py进行预测。