【h5】实现语音转文字
- 一、需求
- 功能概述是:
- 二、实现过程
- 1、实现按住录音,松开发送。有两个录音按钮。
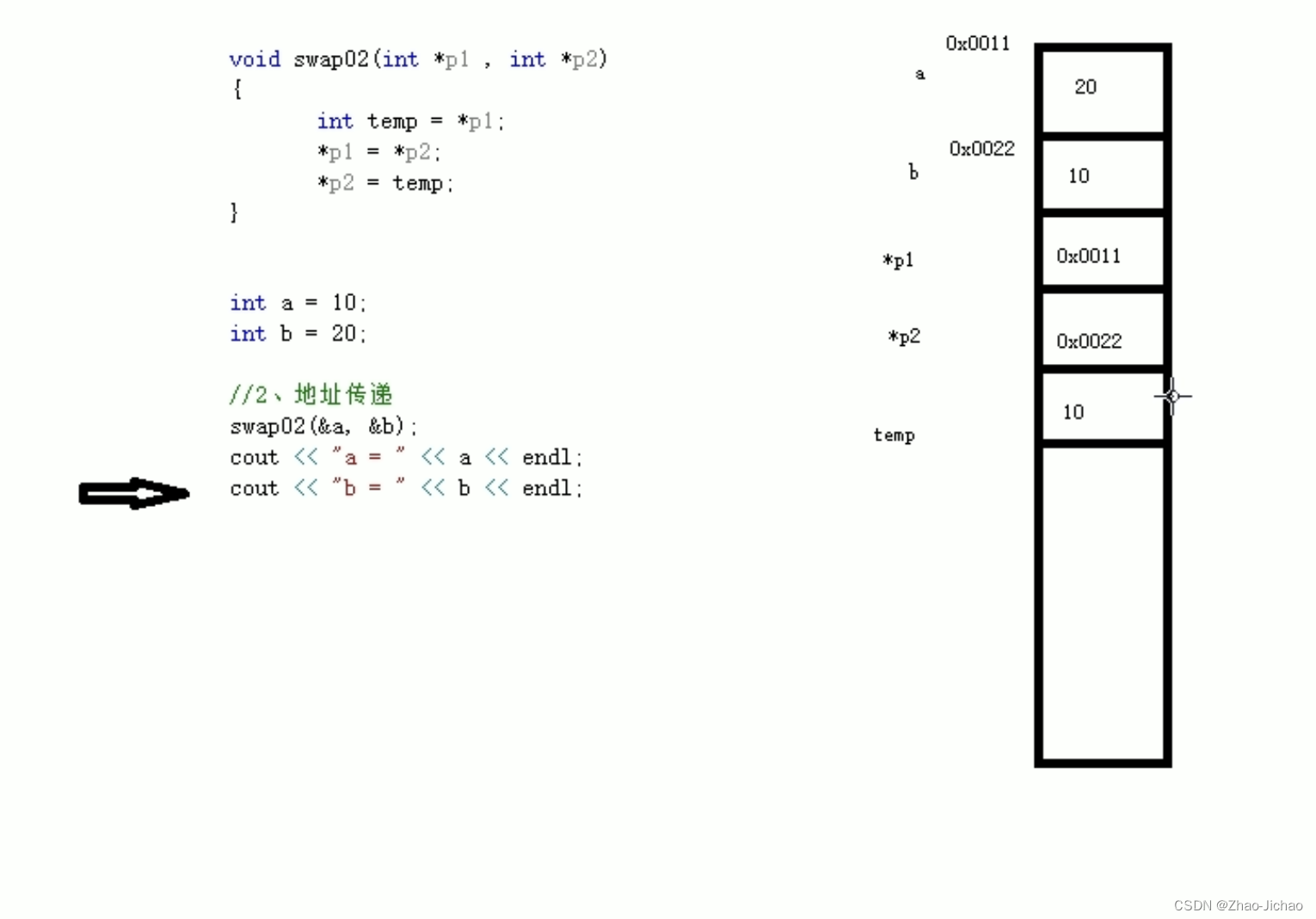
- a. 获取用户的麦克风声音和创建一个MediaRecorder对象:
- b. 启动和停止录音:
- c. 将音频数据上传到服务器,并在处理完后返回结果并在前端展示:
- 2. 上移到特定区域取消。
- a. 获取要监听区域的坐标范围:
- b. 在touchmove事件中判断用户手指的位置是否在指定区域内:
- c. 在被判断为取消区域的情况下,需要为用户提供取消的提示信息。最好的做法是记录用户的取消动作并复原已有界面。例如:
- 3. 略微上移是ASR和展示为文字。
- a. 监听用户手指移动事件。通过touchstart、touchmove、touchend事件获取用户移动手指的位置。
- b. 监听录音停止事件,获取录音的Blob数据,并将其转化为Base64格式。
- c. 将Base64格式的语音数据上传到服务器进行处理,并在处理完成后将结果展示在前端。
- d. 在前端页面上展示语音识别结果。
- 4、查看历史消息。
- a. 在LocalStorage中保存历史消息:
- b. 在前端页面上显示历史消息列表:
- c. 在前端页面上展示历史记录并且提供删除功能。(代码在b步骤中已经给出了)。
- 三、延伸:前端H5实现调用麦克风,录音功能
- 下面是一个简单的实现流程:
- 1. 首先,我们需要请求用户授权使用麦克风。调用Navigator.mediaDevices.getUserMedia()方法即可。在授权成功后,可以通过回调函数来获取到用户的音频输入流。
- 2. 通过获取到的音频输入流,我们可以创建一个MediaRecorder对象,用于进行录音操作。MediaRecorder对象支持多种不同的配置选项,可以根据实际需要进行设置。
- 3. 开始录音:通过调用MediaRecorder对象的start()方法来开始录音。同时通过start()方法的参数可以设置录音的时长限制。
- 4. 停止录音:调用MediaRecorder对象的stop()方法停止录音。在停止录音之后,可以通过ondataavailable事件来获取录音的数据,这里的数据是一个Blob类型的对象。
一、需求
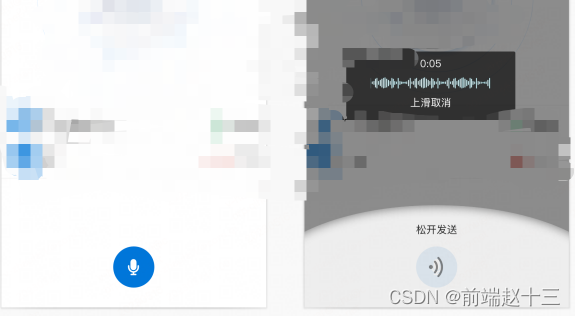
功能概述是:
- 按住录音,松开发送。有两个录音按钮。
- 上移到特定区域取消。
- 略微上移是asr和展示为文字。
- 查看历史消息。
需求是:可以h5开发,即:可以网页版,也打包为apk的安卓包
二、实现过程
1、实现按住录音,松开发送。有两个录音按钮。
a. 获取用户的麦克风声音和创建一个MediaRecorder对象:
const audioBuffer = await navigator.mediaDevices.getUserMedia({ audio: true, video: false });
const recorder = new MediaRecorder(audioBuffer);
b. 启动和停止录音:
const startRecordButton = document.getElementById('start-record');
const stopRecordButton = document.getElementById('stop-record');
function handleStartRecording() {
recorder.start();
}
function handleStopRecording() {
recorder.stop();
recorder.ondataavailable = (e) => {
const audioBlob = e.data;
const reader = new FileReader();
reader.readAsDataURL(audioBlob);
reader.onloadend = () => {
const audioBase64 = reader.result.split(',')[1];
// 将录制好的音频数据上传到服务器进行处理,并在处理完成后将结果展示在前端
postAudioDataToServer(audioBase64);
}
}
}
startRecordButton.addEventListener('touchstart', handleStartRecording);
stopRecordButton.addEventListener('touchend', handleStopRecording);
c. 将音频数据上传到服务器,并在处理完后返回结果并在前端展示:
async function postAudioDataToServer(audioBase64) {
const response = await fetch(SERVER_URL, {
headers: {
'Content-Type': 'application/json'
},
method: 'POST',
body: JSON.stringify({ audio: audioBase64 })
});
const result = await response.json();
// 在前端页面上展示处理后的语音识别结果
showAsrResult(result.result);
}
2. 上移到特定区域取消。
a. 获取要监听区域的坐标范围:
const cancelArea = document.getElementById('cancel-area');
const cancelAreaRect = cancelArea.getBoundingClientRect();
b. 在touchmove事件中判断用户手指的位置是否在指定区域内:
const recordedArea = document.getElementById('recorded-area');
function handleTouchMove(e) {
const touchY = e.touches[0].clientY;
if (touchY < cancelAreaRect.top) {
// 用户的手指已经滑出了取消所在的区域
recordedArea.classList.remove('cancel');
} else {
// 用户的手指仍在取消所在区域内
recordedArea.classList.add('cancel');
}
}
document.addEventListener('touchmove', handleTouchMove);
c. 在被判断为取消区域的情况下,需要为用户提供取消的提示信息。最好的做法是记录用户的取消动作并复原已有界面。例如:
function handleTouchEnd(e) {
if (recordedArea.classList.contains('cancel')) {
// 用户已经划出了取消区域
recorder.stop();
recorder.ondataavailable = null;
recorder = null;
// 给用户展示取消信息
alert('录音已取消');
} else {
// 用户完成了一次完整的录音,并且已经成功上传到服务器
alert('录音上传成功');
}
}
document.addEventListener('touchend', handleTouchEnd);
3. 略微上移是ASR和展示为文字。
a. 监听用户手指移动事件。通过touchstart、touchmove、touchend事件获取用户移动手指的位置。
let startY = 0;
let currentY = 0;
function handleTouchStart(e) {
startY = e.touches[0].clientY;
}
function handleTouchMove(e) {
currentY = e.touches[0].clientY;
}
function handleTouchEnd(e) {
const deltaY = startY - currentY;
if (deltaY > MIN_SLIDE_DISTANCE) {
// 触发ASR操作
shouldAsr = true;
}
}
document.addEventListener('touchstart', handleTouchStart, { passive: true });
document.addEventListener('touchmove', handleTouchMove, { passive: true });
document.addEventListener('touchend', handleTouchEnd, { passive: true });
b. 监听录音停止事件,获取录音的Blob数据,并将其转化为Base64格式。
recorder.ondataavailable = (e) => {
const audioBlob = e.data;
const reader = new FileReader();
reader.readAsDataURL(audioBlob);
reader.onloadend = () => {
const audioBase64 = reader.result.split(',')[1];
// 将录制好的音频数据上传到服务器进行处理,并在处理完成后将结果展示在前端
postAudioDataToServer(audioBase64);
}
}
c. 将Base64格式的语音数据上传到服务器进行处理,并在处理完成后将结果展示在前端。
async function postAudioDataToServer(audioBase64) {
const response = await fetch(SERVER_URL, {
headers: {
'Content-Type': 'application/json'
},
method: 'POST',
body: JSON.stringify({ audio: audioBase64 })
});
const result = await response.json();
// 在前端页面上展示语音识别结果
showAsrResult(result.result);
}
d. 在前端页面上展示语音识别结果。
function showAsrResult(result) {
const asrResultArea = document.getElementById('asr-result');
const p = document.createElement('p');
p.innerText = result;
asrResultArea.appendChild(p);
}
4、查看历史消息。
a. 在LocalStorage中保存历史消息:
// 保存历史消息列表
let historyList = JSON.parse(localStorage.getItem('historyList')) || [];
// 在按钮点击事件中将当前的录音数据添加到LocalStorage中
function handleStopRecording() {
// ...
reader.onloadend = () => {
const audioBase64 = reader.result.split(',')[1];
// 将录制好的音频数据上传到服务器进行处理,并在处理完成后将结果展示在前端
postAudioDataToServer(audioBase64);
// 将音频数据添加到历史记录中
historyList.push({ audio: audioBase64 });
localStorage.setItem('historyList', JSON.stringify(historyList));
}
}
b. 在前端页面上显示历史消息列表:
// 渲染历史记录列表在页面上
function renderHistoryList() {
const historyList = JSON.parse(localStorage.getItem('historyList')) || [];
const historyListArea = document.getElementById('history-list');
historyListArea.innerHTML = '';
if (historyList.length > 0) {
historyList.forEach((item, idx) => {
const li = document.createElement('li');
const deleteBtn = document.createElement('button');
deleteBtn.innerText = 'Delete';
// 点击删除按钮,从LocalStorage中删除对应的历史记录
deleteBtn.addEventListener('click', () => {
historyList.splice(idx, 1);
localStorage.setItem('historyList', JSON.stringify(historyList));
renderHistoryList();
});
li.appendChild(deleteBtn);
historyListArea.appendChild(li);
});
} else {
historyListArea.innerHTML = '没有历史记录';
}
}
// 初始化页面时渲染历史记录
renderHistoryList();
c. 在前端页面上展示历史记录并且提供删除功能。(代码在b步骤中已经给出了)。
三、延伸:前端H5实现调用麦克风,录音功能
我们可以通过Web Audio API以及Navigator.mediaDevices.getUserMedia()方法来实现。
下面是一个简单的实现流程:
1. 首先,我们需要请求用户授权使用麦克风。调用Navigator.mediaDevices.getUserMedia()方法即可。在授权成功后,可以通过回调函数来获取到用户的音频输入流。
navigator.mediaDevices.getUserMedia({ audio: true, video: false })
.then(stream => {
console.log('获取到麦克风输入流,可以进行录音操作');
})
.catch(error => {
console.log('获取麦克风输入流失败', error);
});
2. 通过获取到的音频输入流,我们可以创建一个MediaRecorder对象,用于进行录音操作。MediaRecorder对象支持多种不同的配置选项,可以根据实际需要进行设置。
let recorder = null;
navigator.mediaDevices.getUserMedia({ audio: true, video: false })
.then(stream => {
recorder = new MediaRecorder(stream, {
mimeType: 'audio/webm;codecs=opus',
audioBitsPerSecond: 128000,
videoBitsPerSecond: null,
});
console.log('获取到麦克风输入流,可以进行录音操作');
})
.catch(error => {
console.log('获取麦克风输入流失败', error);
});
3. 开始录音:通过调用MediaRecorder对象的start()方法来开始录音。同时通过start()方法的参数可以设置录音的时长限制。
// 开始录音
recorder.start();
4. 停止录音:调用MediaRecorder对象的stop()方法停止录音。在停止录音之后,可以通过ondataavailable事件来获取录音的数据,这里的数据是一个Blob类型的对象。
// 停止录音
recorder.stop();
// 获取录音数据
recorder.ondataavailable = (e) => {
const audioBlob = e.data;
// 这里可以上传录音数据等操作
};
在获取到录音数据之后,我们就可以进行 上传 等其他操作。上传数据可以使用XMLHttpRequest、fetch等常用的浏览器API进行处理。
需要注意的是,由于不同的浏览器可能存在兼容性问题,所以在开发过程中需要进行
兼容性测试。
同时,为了避免产生大量无用的录音数据占用用户空间,可以在录音数据被上传至服务器之后尽早地删除掉该数据。