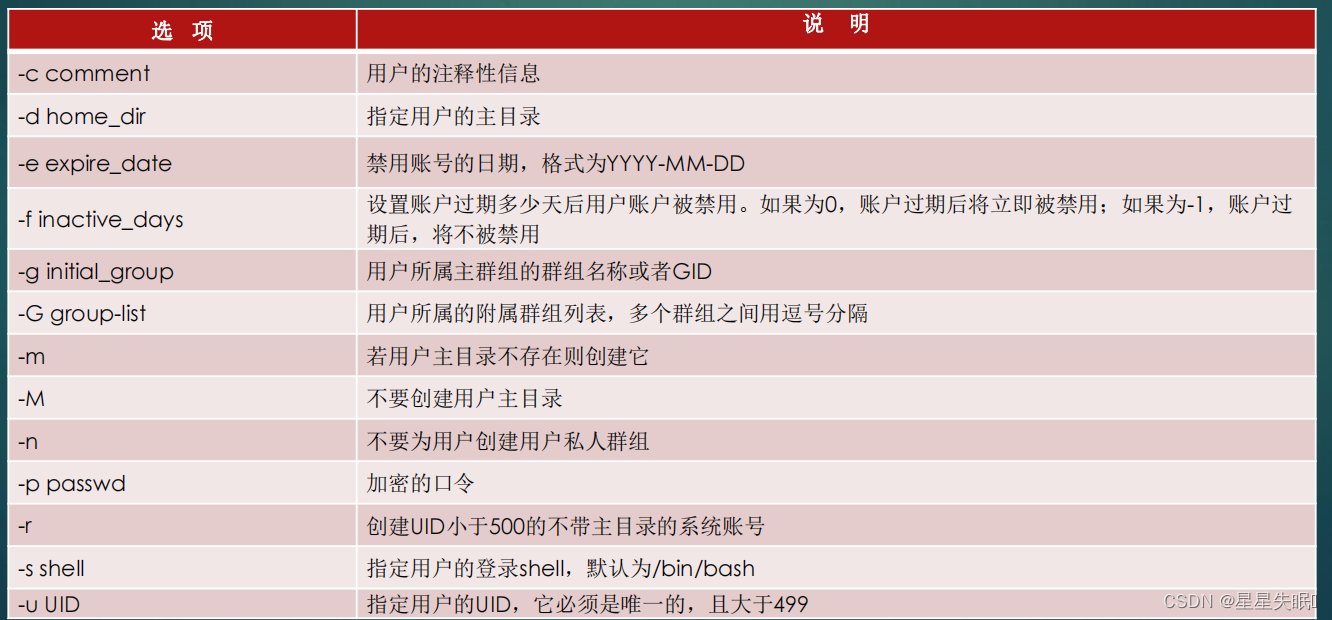
文章目录
- 1 概述
- 2 快照读与当前读
- 当前读
- 快照读
- 隔离级别:
- undo log版本链:
- 3 Read View
- 3.1 什么是Read View?
- 3.2 实现原理
- 3.3 Read View规则(可见性算法)
- 4 MVCC整体流程
- 4.1 可重复读是如何工作的?
- 4.2 读提交是如何工作的?
- 总结:
MVVC 多版本并发控制
1 概述
MVCC(Multiversion Concurrency Control),多版本并发控制。它和undo log中的版本链息息相关,MVVC通过数据行的多个版本来实现数据库的并发控制。
简单的说就是当前事务查询另一个事务正在更改的行(如果此时读取就会发生脏读),不用加锁等待,而是读取该数据的历史版本,降低响应时间。
MVCC 的实现依赖于:隐藏字段、Undo Log、Read View
2 快照读与当前读
MVCC在MySQL InnoDB中的实现主要是为了提高数据库并发性能,用更好的方式去处理 读-写冲突 ,做到 即使有读写冲突时,也能做到 不加锁 , 非阻塞并发读 ,而这个读指的就是 快照读 , 而非 当前读 。当前读 实际上是一种加锁的操作,是悲观锁的实现。而MVCC本质是采用乐观锁思想的一种方式。
当前读:读的是最新数据 (增删改、加锁的查询)
当前读读取的记录一定是最新的数据,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。
加锁的读被称为当前读,还有数据的增删改都是要先读取数据的,这一读取过程也是当前读。
SELECT * FROM t LOCK IN SHARE MODE; # 共享锁
SELECT * FROM t FOR UPDATE; # 排他锁
UPDATE SET t..
也就是MVCC进行读—写,读是读不加锁的 快照读,写是必须先读到最新的再去写,是当前读。
快照读:读的是历史版本(普通的查询)
快照读又叫一致性读,读取的是数据行的快照版本。在MySQL中,普通的select语句(不加for update或lock in share mode的select语句)默认就是使用的快照读,不加锁。
SELECT * FROM table WHERE ...
之所以这样,是因为快照读可以避免加锁操作,降低开销。
注意:当事务的隔离级别是串行时,快照读就没有用了,会退化为当前读。
隔离级别:
在MySQL中默认的隔离级别就是可重复读RR,可以解决不可重复读问题,在MySQL中,特别的还额外支持解决幻读问题。
它是如何解决幻读问题的呢?有两种方式:
可重复读级别如何解决幻读的?(面试题答案)
- 针对快照读(普通 select 语句),是通过 MVCC 方式解决了幻读,因为可重复读隔离级别下,事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,即使中途有其他事务插入了一条数据,是查询不出来这条数据的,所以就很好了避免幻读问题。
- 针对当前读(select … for update 等语句),是通过 next-key lock(记录锁+间隙锁)方式解决了幻读,因为当执行 select … for update 语句的时候,会加上 next-key lock,如果有其他事务在 next-key lock 锁范围内插入了一条记录,那么这个插入语句就会被阻塞,无法成功插入,所以就很好了避免幻读问题。
undo log版本链:
隐藏字段
对应InnoDB来说,聚簇索引中的每个记录都包含了两个必要的隐藏字段:
- trx_id:当一个事务对某条聚簇索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里;
- roll_pointer:回滚指针,每次对某条聚簇索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。
![[)(MySQL笔记.assets/image-20230527173608948.png)]](https://img-blog.csdnimg.cn/18a34484dfda48c4b5bc0f5f32da0de1.png)
回滚指针:指向之前的版本地址
举例:
有一个id为8的事务创建了一条数据,那么该记录的示意图大概如下:

假设之后两个id分别为10、20的事务对这条记录进行update操作,流程如下:
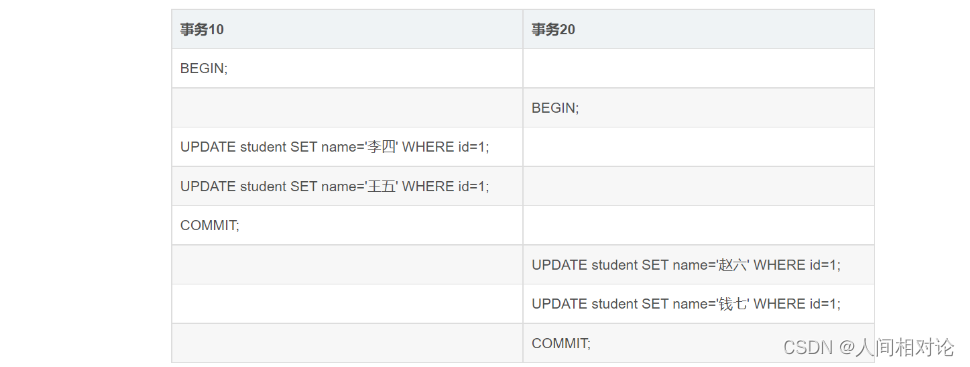
每次修改都会生成一个undo log日志,每个日志都相互链接,构成版本链,此时该条数据的示意图如下:
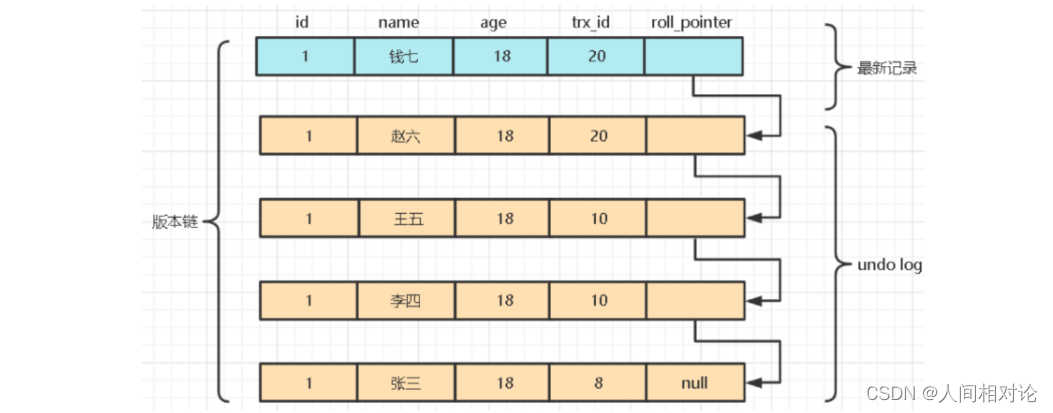
对该记录每次更新后,都会将旧值放到一条 undo日志 中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被 roll_pointer 属性连接成一个链表,我们把这个链表称之为版本链,版 本链的头节点就是当前记录最新的值。
每个版本中还包含生成该版本时对应的事务id 。
3 Read View
有了undo log就可以读取到记录的历史版本,那么在什么情况下,读取哪个版本的记录呢?这就用到了Read View,它帮我们解决了行的可见性问题。
3.1 什么是Read View?
Read View就是当某个事务在使用MVVC机制进行快照读操作时产生的读视图。
3.2 实现原理
四种隔离级别里,读未提交和串行化是不会使用MVVC的,因为读未提交直接读取某个数据的最新数据即可,串行化是通过加锁来读的。
读已提交和可重复读都必须保证读到的数据都是其他事务提交了的,所以,其他事务修改了数据但是还未提交,我们不能够访问该数据,但可以通过MVVC机制读取该记录的历史版本,核心问题就是需要判断版本链中的哪条历史版本是当前事务可见的,这也是ReadView要解决的问题。
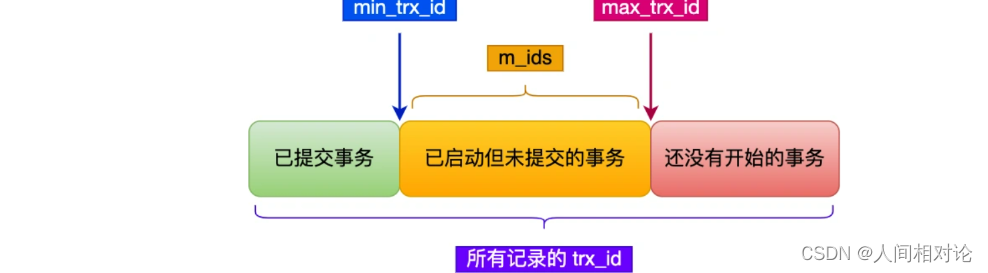
Read View包含4个比较重要的内容:

- creator_trx_id:创建这个Read View的事务id,Read View和事务是一一对应的。(只有事务对表中的记录做修改时才会为事务分配事务id,否则一个事务中只有读操作,该事务的id默认为0。)
- m_ids:指的是在创建 Read View 时,当前数据库中「活跃事务」的事务 id 列表,注意是一个列表,“活跃事务”指的就是,启动了但还没提交的事务。
- min_trx_id:指的是在创建 Read View 时,当前数据库中「活跃事务」中事务 id 最小的事务,也就是 m_ids 的最小值。
- max_trx_id:这个并不是 m_ids 的最大值,而是创建 Read View 时当前数据库中应该给下一个事务的 id 值,也就是全局事务中最大的事务 id 值 + 1;
注意:max_trx_id并不是m_ids中的最大值,事务id是递增分配的。比如,现在有id为1, 2,5这三个事务,之后id为5的事务提交了。那么一个新的读事务在生成ReadView时, m_ids就包括1和2,min_trx_id的值就是1,max_trx_id的值就是6。
3.3 Read View规则(可见性算法)
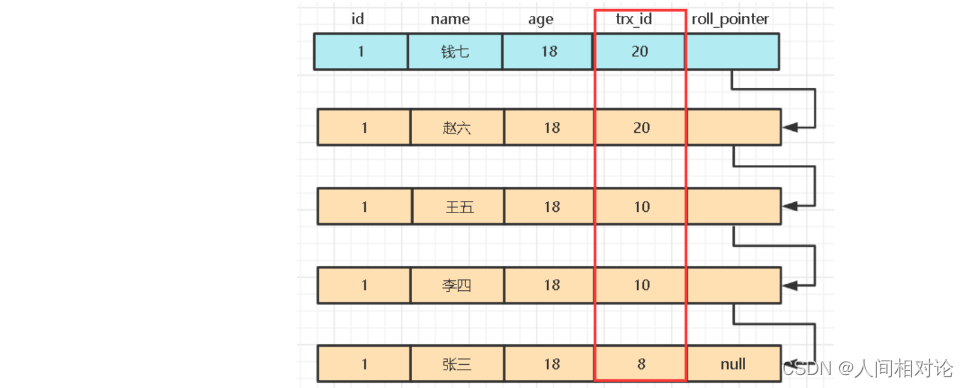
当某个事务有了Read View,访问某条记录时,需要按照下面的步骤判断该记录的哪个版本可见:
创建 Read View 后,我们可以将记录中的 trx_id 划分这三种情况:
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
- 如果记录的 trx_id 值小于 Read View 中的
min_trx_id值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。 - 如果记录的 trx_id 值大于等于 Read View 中的
max_trx_id值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。 - 如果记录的 trx_id 值在 Read View 的min_trx_id和max_trx_id之间,需要判断 trx_id 是否在 m_ids 列表中:
- 如果记录的 trx_id 在
m_ids列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见 - 如果记录的 trx_id 在
m_ids列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见
- 如果记录的 trx_id 在
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
4 MVCC整体流程
了解了这些概念之后,我们来看下当查询一条记录的时候,系统如何通过MVCC找到它:
-
- 首先获取事务自己的版本号,也就是事务 ID
-
- 获取 ReadView;
-
- 查询得到的数据,然后与 ReadView 中的事务版本号进行比较;
-
- 如果不符合 ReadView 规则,就需要从 Undo Log 中获取历史快照;
-
- 最后返回符合规则的数据。
4.1 可重复读是如何工作的?
可重复读隔离级别是启动事务时进行第一次查询前生成一个 Read View,然后整个事务期间都在用这个 Read View。
假设事务 A (事务 id 为51)启动后,紧接着事务 B (事务 id 为52)也启动了,那这两个事务创建的 Read View 如下:

事务 A 和 事务 B 的 Read View 具体内容如下:
-
在事务 A 的 Read View 中,它的事务 id 是 51,由于它是第一个启动的事务,所以此时活跃事务的事务 id 列表就只有 51,活跃事务的事务 id 列表中最小的事务 id 是事务 A 本身,下一个事务 id 则是 52。
-
在事务 B 的 Read View 中,它的事务 id 是 52,由于事务 A 是活跃的,所以此时活跃事务的事务 id 列表是 51 和 52,活跃的事务 id 中最小的事务 id 是事务 A,下一个事务 id 应该是 53。
接着,在可重复读隔离级别下,事务 A 和事务 B 按顺序执行了以下操作:
-
事务 B 读取小林的账户余额记录,读到余额是 100 万;
-
事务 A 将小林的账户余额记录修改成 200 万,并没有提交事务;
-
事务 B 读取小林的账户余额记录,读到余额还是 100 万;
-
事务 A 提交事务;
-
事务 B 读取小林的账户余额记录,读到余额依然还是 100 万;
-
接下来,具体分析
事务 B 第一次读小林的账户余额记录,在找到记录后,它会先看这条记录的 trx_id,此时发现 trx_id 为 50,比事务 B 的 Read View 中的 min_trx_id 值(51)还小,这意味着修改这条记录的事务早就在事务 B 启动前提交过了,所以该版本的记录对事务 B 可见的,也就是事务 B 可以获取到这条记录。
接着,事务 A 通过 update 语句将这条记录修改了(还未提交事务),将小林的余额改成 200 万,这时 MySQL 会记录相应的 undo log,并以链表的方式串联起来,形成版本链,如下图:
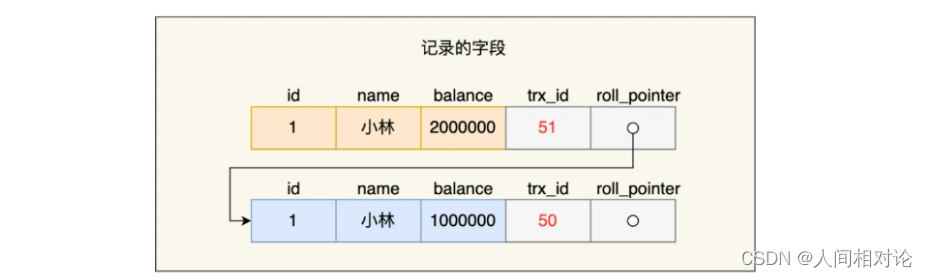
你可以在上图的「记录的字段」看到,由于事务 A 修改了该记录,以前的记录就变成旧版本记录了,于是最新记录和旧版本记录通过链表的方式串起来,而且最新记录的 trx_id 是事务 A 的事务 id(trx_id = 51)。
然后事务 B 第二次去读取该记录,发现这条记录的 trx_id 值为 51,在事务 B 的 Read View 的 min_trx_id 和 max_trx_id 之间,则需要判断 trx_id 值是否在 m_ids 范围内,判断的结果是在的,那么说明这条记录是被还未提交的事务修改的,这时事务 B 并不会读取这个版本的记录。而是沿着 undo log 链条往下找旧版本的记录,直到找到 trx_id 「小于」事务 B 的 Read View 中的 min_trx_id 值的第一条记录,所以事务 B 能读取到的是 trx_id 为 50 的记录,也就是小林余额是 100 万的这条记录。
最后,当事物 A 提交事务后,由于隔离级别时「可重复读」,所以事务 B 再次读取记录时,还是基于启动事务时创建的 Read View 来判断当前版本的记录是否可见。所以,即使事物 A 将小林余额修改为 200 万并提交了事务, 事务 B 第三次读取记录时,读到的记录都是小林余额是 100 万的这条记录。
就是通过这样的方式实现了,「可重复读」隔离级别下在事务期间读到的记录都是事务启动前的记录。
4.2 读提交是如何工作的?
读提交隔离级别是在每次读取数据时,都会生成一个新的 Read View。

也意味着,事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务。
那读提交隔离级别是怎么工作呢?我们还是以前面的例子来聊聊。
假设事务 A (事务 id 为51)启动后,紧接着事务 B (事务 id 为52)也启动了,接着按顺序执行了以下操作:
- 事务 B 读取数据(创建 Read View),小林的账户余额为 100 万;
- 事务 A 修改数据(还没提交事务),将小林的账户余额从 100 万修改成了 200 万;
- 事务 B 读取数据(创建 Read View),小林的账户余额为 100 万;
- 事务 A 提交事务;
- 事务 B 读取数据(创建 Read View),小林的账户余额为 200 万;
那具体怎么做到的呢?我们重点看事务 B 每次读取数据时创建的 Read View。前两次 事务 B 读取数据时创建的 Read View 如下图:
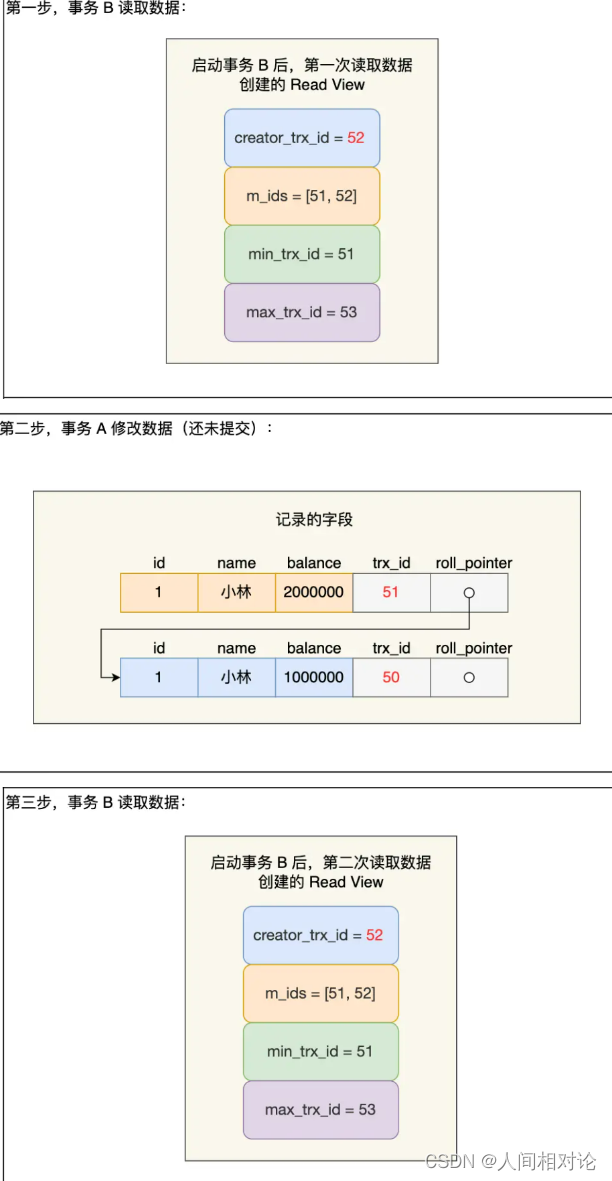
我们来分析下为什么事务 B 第二次读数据时,读不到事务 A (还未提交事务)修改的数据?
事务 B 在找到小林这条记录时,会看这条记录的 trx_id 是 51,在事务 B 的 Read View 的 min_trx_id 和 max_trx_id 之间,接下来需要判断 trx_id 值是否在 m_ids 范围内,判断的结果是在的,那么说明这条记录是被还未提交的事务修改的,这时事务 B 并不会读取这个版本的记录。而是,沿着 undo log 链条往下找旧版本的记录,直到找到 trx_id 「小于」事务 B 的 Read View 中的 min_trx_id 值的第一条记录,所以事务 B 能读取到的是 trx_id 为 50 的记录,也就是小林余额是 100 万的这条记录。
我们来分析下为什么事务 A 提交后,事务 B 就可以读到事务 A 修改的数据?
在事务 A 提交后,由于隔离级别是「读提交」,所以事务 B 在每次读数据的时候,会重新创建 Read View,此时事务 B 第三次读取数据时创建的 Read View 如下:
事务 B 在找到小林这条记录时,会发现这条记录的 trx_id 是 51,比事务 B 的 Read View 中的 min_trx_id 值(52)还小,这意味着修改这条记录的事务早就在创建 Read View 前提交过了,所以该版本的记录对事务 B 是可见的。
正是因为在读提交隔离级别下,事务每次读数据时都重新创建 Read View,那么在事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务。
总结:
幻读解决方案:
- 针对快照读(普通 select 语句),是通过 MVCC 方式解决了幻读,因为可重复读隔离级别下,事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,即使中途有其他事务插入了一条数据,是查询不出来这条数据的,所以就很好了避免幻读问题。
- 针对当前读(select … for update 等语句),是通过 next-key lock(记录锁+间隙锁)方式解决了幻读,因为当执行 select … for update 语句的时候,会加上 next-key lock,如果有其他事务在 next-key lock 锁范围内插入了一条记录,那么这个插入语句就会被阻塞,无法成功插入,所以就很好了避免幻读问题。