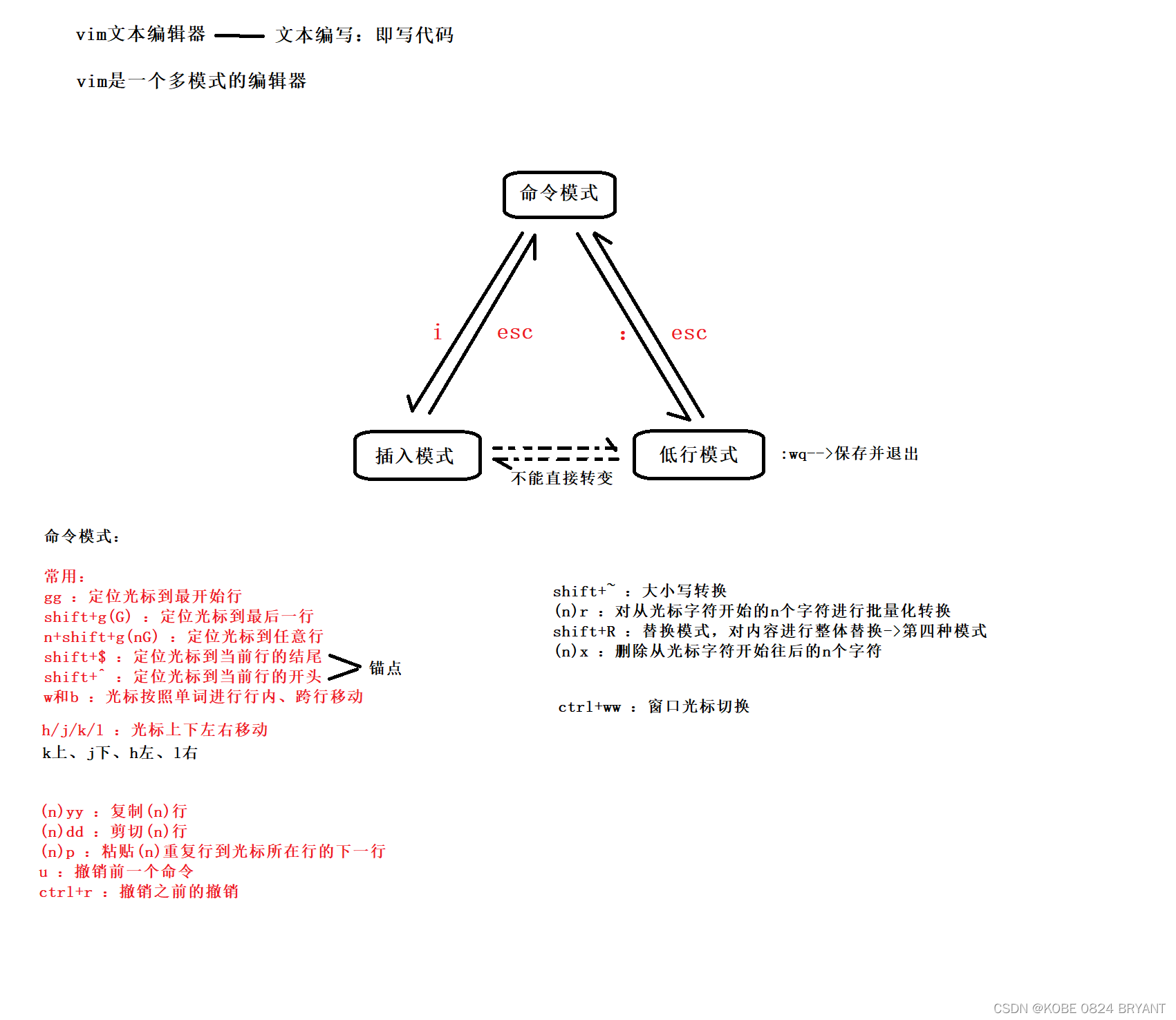
paper:RepGhost: A Hardware-Efficient Ghost Module via Re-parameterization
official implementation:https://github.com/chengpengchen/repghost
存在的问题
特征重用feature reuse是轻量网络设计中常用的一种技术,现有的方法通常使用拼接操作concatenation operator来重用其它层的feature map,从而保持大的通道数以及大的网络容量。尽管拼接操作是parameter-free和FLOPs-free的,但它在硬件设备上的计算成本是不可忽略的。这是因为参数和FLOPs并不是模型实际运行时直接的成本指标(延迟latency是),作者通过实验证明,由于其复杂的内存拷贝,concatenation操作要比add操作低效的多。
本文的创新点
为了解决上述问题,本文提供了一个新的视角来实现特征重用——结构重参数化。本文并不仅仅是将重参数化技术直接应用到现有的Ghost module中,而是利用重参数技术改进Ghost module从而实现更快的推理。作者通过重参数化实现隐式特征重用,替代了拼接操作,提出了一种新的在硬件上高效的RepGhost module。然后又在RepGhost模块的基础上设计了一个高效的RepGhost bottleneck以及RepGhostNet。
本文的贡献总结如下
- 本文指出,在硬件高效的结构设计中,拼接操作对于特征重用不是无成本和必不可少的,并提供了一个新的视角——通过结构重参数化来实现特征重用。
- 本文设计了一种新的RepGhost module,可以实现隐式特征重用,并设计了一种比GhostNet和MobileNetV3更hardware-efficient的RepGhostNet。
- 通过实验表明,本文提出的RepGhostNet在多个视觉任务上比之前的最先进的轻量级网络的性能更好,并且延迟更低。
方法介绍
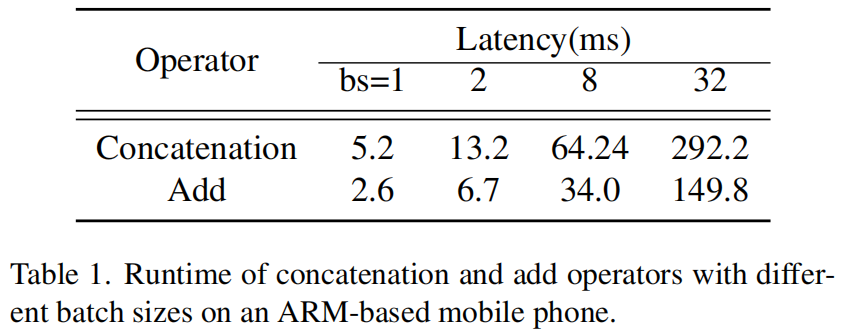
作者首先对比了拼接和相加操作的延迟,以GhostNet 1.0x为例,把所有的拼接操作换成相加进行对比,结果如表1所示,可以看出,拼接的延迟基本是相加的两倍。
Re-parameterization vs. Concatenation
设 \(y\in \mathbb{R}^{N\times C_{out}\times H\times W}\) 表示通道数为 \(C_{out}\) 的输出,\(x\in \mathbb{R}^{N\times C_{in}\times H\times W}\) 表示待被处理和重用的输入。 \(\Phi_{i}(x),\forall i=1,...,s-1\) 表示会应用到 \(x\) 上的其它网络层比如卷积或BN层。通过拼接进行特征重用可以表示如下
![]()
其中 \(Cat\) 是拼接操作。它保留现有特征,并把信息处理留给其它操作。例如一个拼接操作后通常会接一个1x1卷积层用来处理通道信息。
结构重参数化在训练时利用一些线性操作来生成不同的特征图,并在推理时通过参数融合将多个操作融合为一个。也就是说它将融合过程从特征空间转移到权重空间,这可以被视为一种隐形的特征重用。通过结构重参数化进行特征重用可以表示如下
![]()
特征融合过程是在权重空间中完成的,这不会引入任何额外的推理时间,使得最终的架构比使用拼接的更高效。
RepGhost Module
图3展示了原始的Ghost module如何一步步演化成RepGhost module的,其中(a)是原始的Ghost module
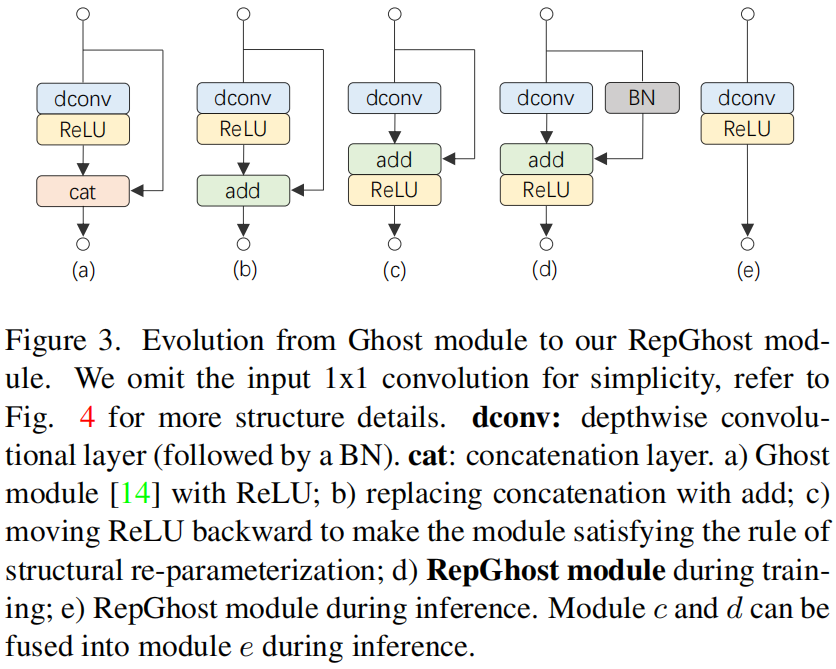
Add Operator. 由于拼接的低效,首先把所有的concatenation换成add,得到(b)。
Moving ReLU Backward. 为了可以进行重参数化,把depthwise卷积后的ReLU移到add后面,得到(c)。
Re-parameterization. 作为一个可重参数化的module,(c)可以更加灵活,因此作者把identity mapping分支换成了BN,引入了非线性,得到(d)。这就是训练阶段完整的RepGhost module。
Fast Inference. 利用重参数化技术,(c)和(d)都可以融合成(e),即推理阶段的RepGhost module。
Building our Bottleneck and Architecture
RepGhost Bottleneck. 基于图4(a)的Ghost bottleneck,作者用RepGhost module替换掉所有的Ghost module来直接构建RepGhost bottleneck。但是RepGhost module中的add操作和Ghost module中的concatenation操作得到的输出通道不同,前者是后者的一半,直接改变下一层的输入通道会严重影响网络的性能。为了解决这个问题,RepGhost bottleneck保持和Ghost bottleneck一样的输入和输出通道,如图4(b)所示,RepGhost bottleneck做了两点改变,一是中间通道减小一半,即第一个module的输出通道。二是第二个module的输入通道增大一倍,这样就可以保持输入和输出通道与Ghost bottleneck一致。推理阶段重参数化后的bottleneck如图4(c)所示。
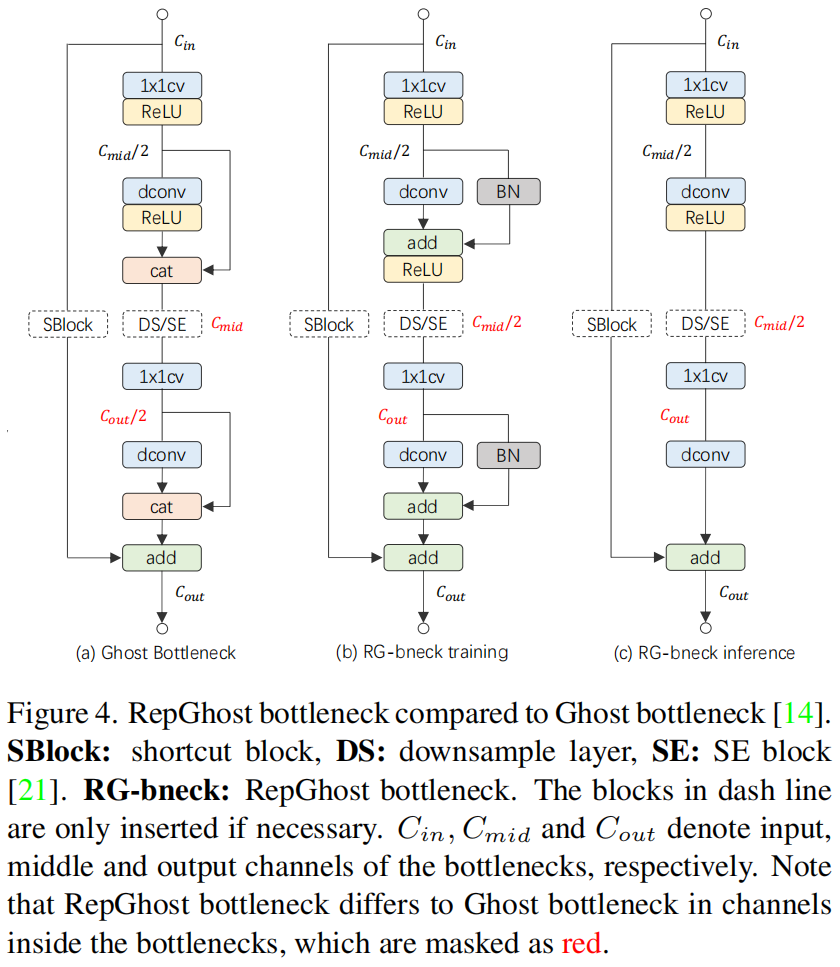
RepGhostNet. 由于RepGhost bottleneck和Ghost bottleneck的输入输出大小通道都相同,作者简单地将GhostNet中的Ghost bottleneck换成RepGhost bottleneck来构建RepGhostNet,网络的详细结构如表2所示。其中输入经过一个普通3x3卷积得到通道数为16的输出,最后经过普通的1x1卷积和全局平均池化来得到网络输出。根据输入大小,将RG-bneck分为5个部分,除了最后一组,每组的最后一个bottleneck进行stride=2的下采样。

实验结果
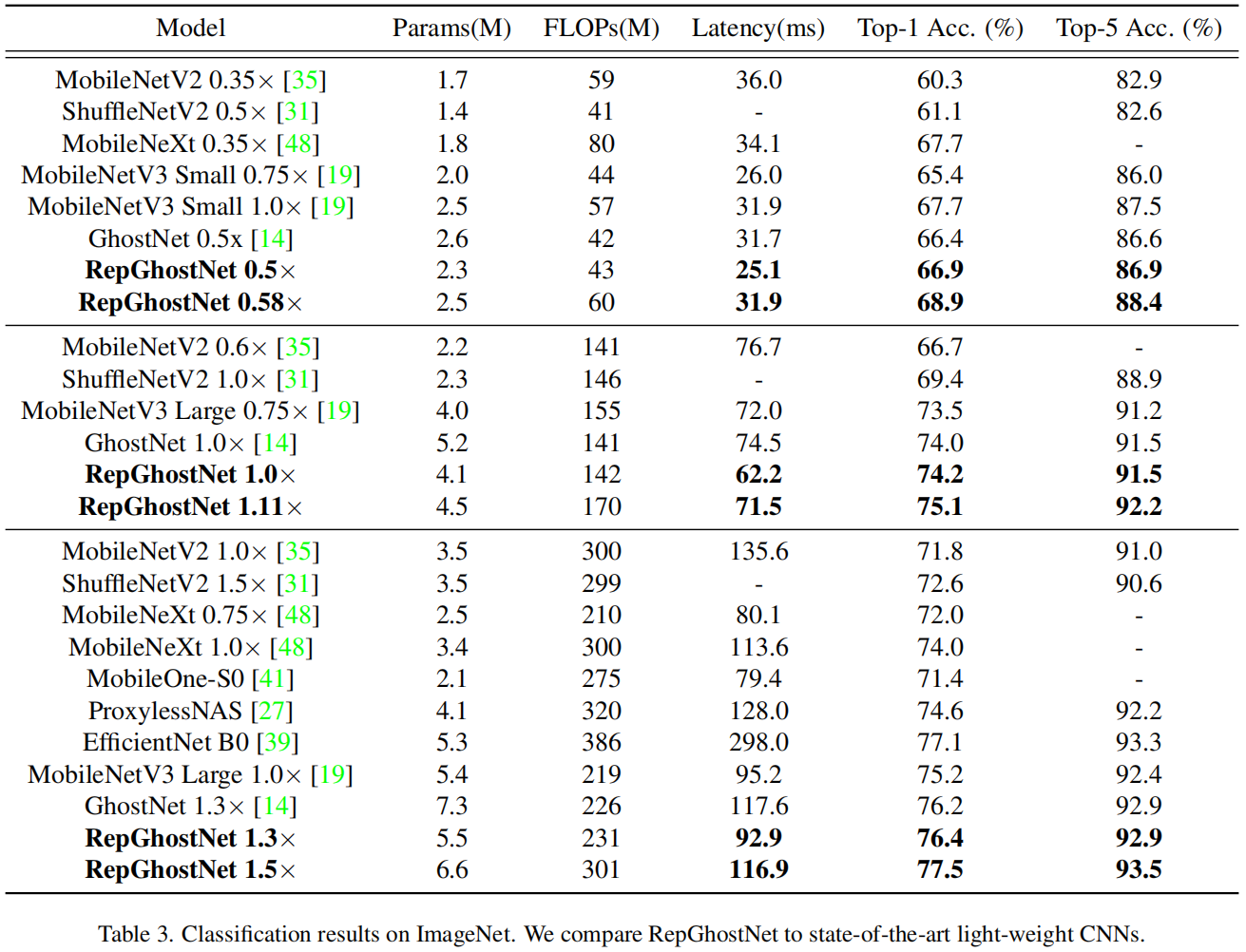
在ImageNet数据集上,和其它一些轻量模型的结果对比如表3所示
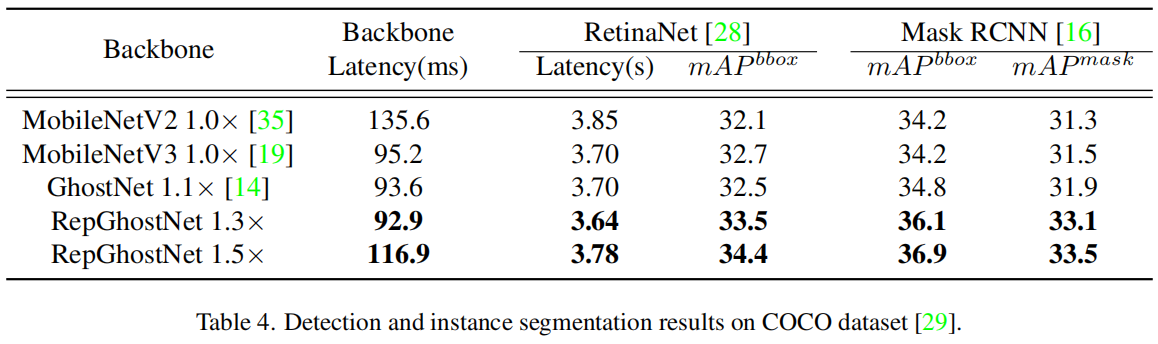
在下游任务目标检测和实例分割任务上,结果对比如表4所示
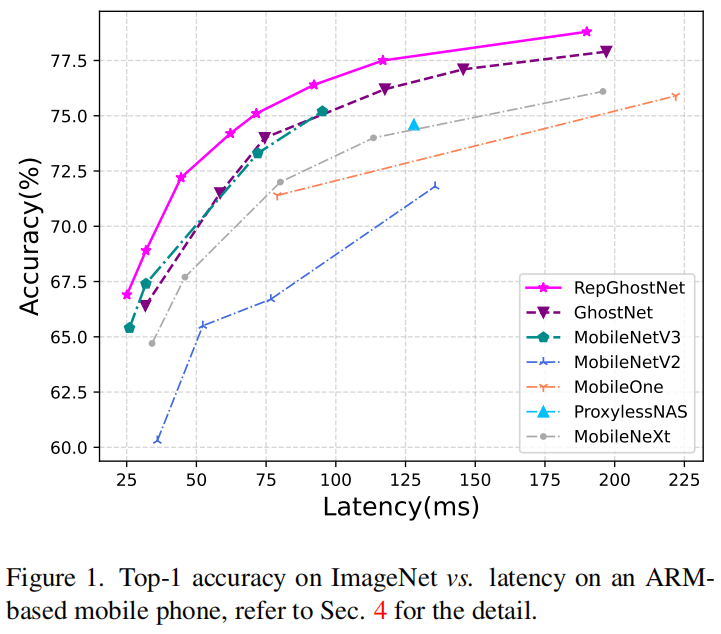
在基于ARM结构的移动手机上进行测试,ImageNet上top-1精度和延迟的变化曲线如图1所示
在iphone12上与MobileOne的对比

![[元带你学: eMMC协议详解 10] Device 识别流程 与 中断模式](https://img-blog.csdnimg.cn/img_convert/262abfa94e2b5642120b21810384ce4b.png)









![[k8s]Kubernetes简介](https://img-blog.csdnimg.cn/06a83908c3a14c638630043b2178652c.png#pic_center)