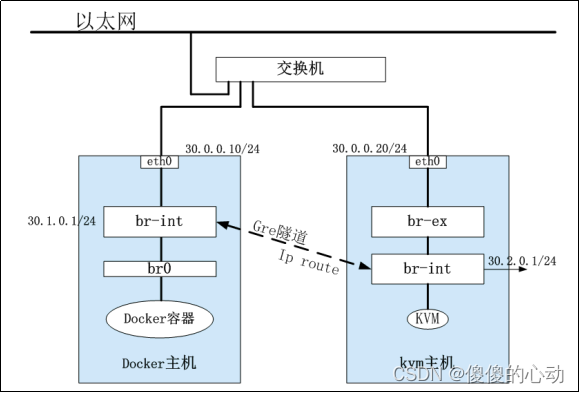
先填坑,一贯习惯
nginx如果要支持SSE,要调整一些参数
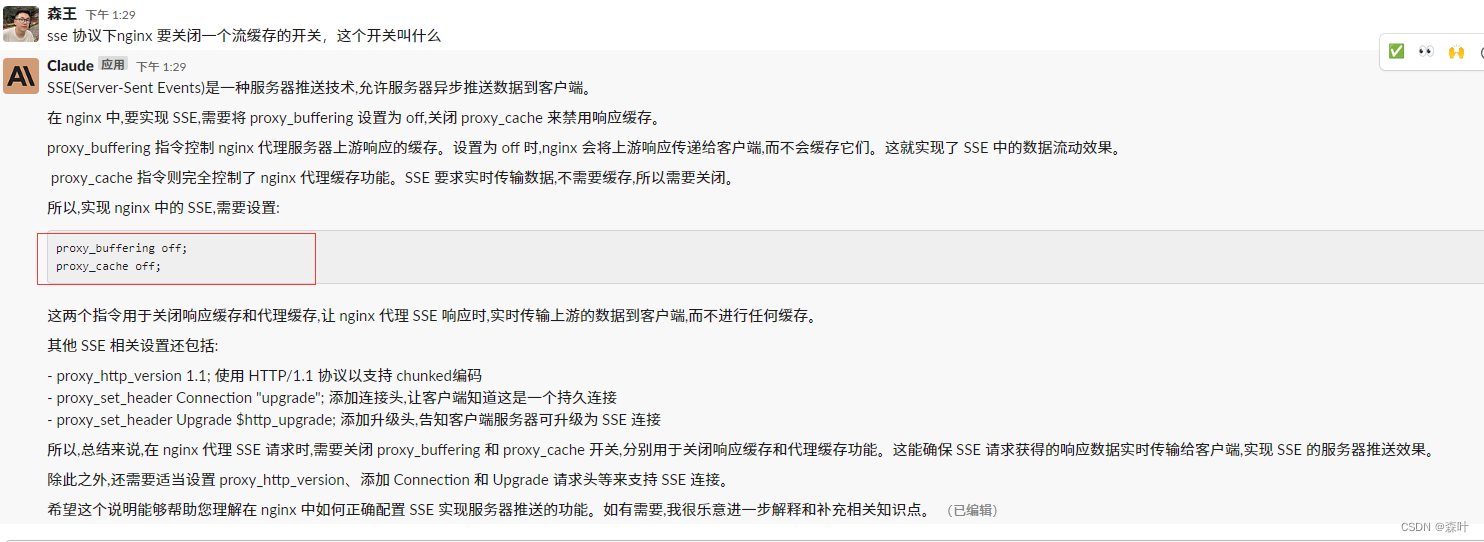
conf配置文件,AI给的,具体自己没搭,应该是正确的
nginx
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8000;
server_name localhost;
location /sse {
proxy_buffering off;
proxy_cache off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_pass http://127.0.0.1:9000;
}
}
}
这个配置的主要内容如下:1. 在 /sse 路径代理请求到本地 9000 端口
2. 关闭 proxy_buffering 和 proxy_cache,禁用缓存
3. 设置 proxy_http_version 为 1.1,支持 HTTP 协议升级
4. 添加 Upgrade 和 Connection 头,支持升级到 WebSocket 协议
5. 代理到上游服务器,并在上游成功升级协议实现服务器推送其他内容如 worker_processes、events 等与 SSE 无直接关系,仅用于说明完整配置。工作流程:1. 客户端发起 /sse 路径请求到 nginx
2. nginx 识别到这是一个协议升级的请求,需要代理到上游
3. 添加Upgrade和Connection头,告知上游服务器支持SSE
4. 上游服务器接收请求,并成功将 HTTP 协议升级为 WebSocket 协议
5. 建立WebSocket连接,实现服务器到客户端的持续数据推送
6. nginx 代理上游推送回的所有数据实时发送给客户端
7. 实现服务器主动和持续向客户端推送数据的SSE效果所以,这个 nginx 配置通过支持 HTTP 到 WebSocket 的协议升级,并关闭相关缓存,实现了代理服务器推送数据流到客户端的 SSE 技术。客户端可以通过标准的 EventSource API 连接到这个服务器,接收服务器推送的消息。希望这个完整的配置示例能够加深您对 nginx 中 SSE 技术实现的理解。如果有任何其他问题,请随时提出,我很乐意进行更详尽的讲解。
很多过程都跟websocket很像,为何还要用SSE的必要性?
AI Claude给出的见解,我个人是对这个无感,因为平时都是用websocket,而且已经有很成熟的socket.io技术,结合fastapi可以很好的进行双向通信,还不会不会经常掉线,OpenAI在普及一项不怎么用的技术,哈哈!

正式开始
OpenAI 官方给我了一个超简单的文档,还直接用curl的方式搞得,真是能多省就多省,大家可以使用apifox 或者 postman 将curl 转成 fetch 或者 request 等自己能看懂的代码,当然也可以自己自学一下curl的命令,如果你能访问OpenAI,可以点下面的链接,自己看看
https://platform.openai.com/docs/api-reference/chat/create![]() https://platform.openai.com/docs/api-reference/chat/create
https://platform.openai.com/docs/api-reference/chat/create

大家如果对上面的双语翻译感兴趣,我推荐一个技术大佬的免费插件,沉浸式翻译
https://chrome.google.com/webstore/detail/immersive-translate/bpoadfkcbjbfhfodiogcnhhhpibjhbnh![]() https://chrome.google.com/webstore/detail/immersive-translate/bpoadfkcbjbfhfodiogcnhhhpibjhbnh
https://chrome.google.com/webstore/detail/immersive-translate/bpoadfkcbjbfhfodiogcnhhhpibjhbnh
其中有个 stream 使用讲解,stream这个东西,我之前也没用过,经过学习后,发现这东西一直都存在就是一个content-type格式,只是我们原来没有注意过,我们都是用urlencode或者json格式来处理数据的,其实可以以二进制的方式,发过来,然后你再自行处理。
当然第一次接触SSE是个什么鬼,后来我发现了第一个大佬,竟然开源了一个插件,从中窥见了SSE的使用案例,大家有兴趣,可以看另外一篇SSE的学习案例,这里不对前端再做深入的讨论了
ChatGPT API SSE(服务器推送技术)和 Fetch 请求 Accept: text/event-stream 标头案例_森叶的博客-CSDN博客在需要接收服务器实时推送的数据时,我们可以使用 `fetch()` 方法和 `EventSource` API 进行处理。使用 `fetch()` 方法并在请求头中添加 `Accept: text/event-stream` 可以告诉服务器我们想要接收 Server-Sent Events (SSE) 格式的数据流。`fetch()` 对流处理有良好的支持,我们可以使用 `body` 属性来读取 SSE 消息,同时也可以利用 `fetch()` 的其他功能如超时控制、请求重试等。缺点是需要手动解析数据、https://blog.csdn.net/wangsenling/article/details/130490769Python 端官方提供了openai 库,这个也是开源的,大家可以找到看看
GitHub - openai/openai-python: The OpenAI Python library provides convenient access to the OpenAI API from applications written in the Python language.The OpenAI Python library provides convenient access to the OpenAI API from applications written in the Python language. - GitHub - openai/openai-python: The OpenAI Python library provides convenient access to the OpenAI API from applications written in the Python language. https://github.com/openai/openai-python/我没怎么看,但看起来没有给stream案例,只是给了request的案例,如果只是request的那其实就挺简单了,就没啥讲的了
https://github.com/openai/openai-python/我没怎么看,但看起来没有给stream案例,只是给了request的案例,如果只是request的那其实就挺简单了,就没啥讲的了
SSE 是一种传输方式
我一开始把这东西预websocket放在一起理解,方向就搞偏了,这东西还真跟websocket不一样,websocket必须是异步的,而且长连接之后,服务端的任何一个进程都可以给客户端发消息,例如A与服务端建立了websocket之后,B发送一个请求,B的http请求可以作为消息发给A客户端,这个过程是纯异步的
SSE 我没找到内部进程通信的方式,另外也不知道Nginx会不会到点就给中断了,但是看nginx升级了协议,应该也是保持该http为长链接,不会轻易断掉,但是如果没有心跳反应,应该就会断,服务端也只是一直向前端发送信息,这个类似于打字机的方式更合适,每次请求,OpenAI一点点推送过来,对大量信息不至于让用户等待太久而产生的,如果向长链接还是建议使用websocket吧,必定解决方案比较多
我想到一种方式,是开子线程的方式,往一个队列的push数据,而主进程不断pop数据再发给前端 ,很多人给的案例是生成器的方式,这个也可以吧,生成器+Future也可以实现异步任务的处理,通信方式比队列灵活多了。
不用官网的openai库,根据开发文档,直接发送request请求也可以,这里给的是一位大佬的请求方式,用的是httpx,大家可以自行学习下,知乎有一篇比较文
浅度测评:requests、aiohttp、httpx 我应该用哪一个? - 知乎在 Python 众多的 HTTP 客户端中,最有名的莫过于 requests、aiohttp和httpx。在不借助其他第三方库的情况下,requests只能发送同步请求;aiohttp只能发送异步请求;httpx既能发送同步请求,又能发送异步请求。所…![]() https://zhuanlan.zhihu.com/p/103711201
https://zhuanlan.zhihu.com/p/103711201
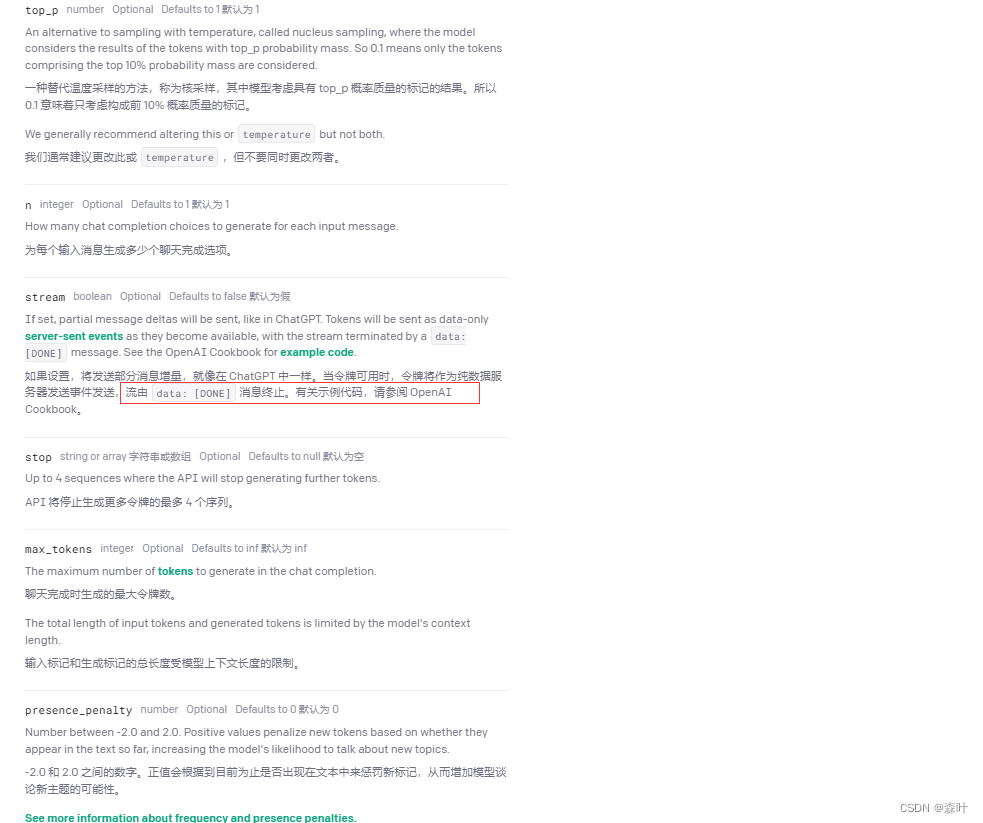
核心参数截图
为何不上代码?自己敲敲更健康,别形成拿来主义,抄一遍有利于记忆和理解
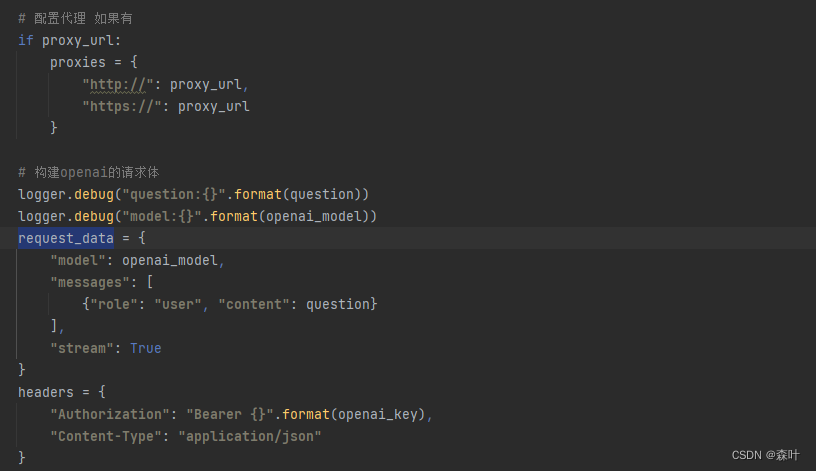
请求主体代码截图
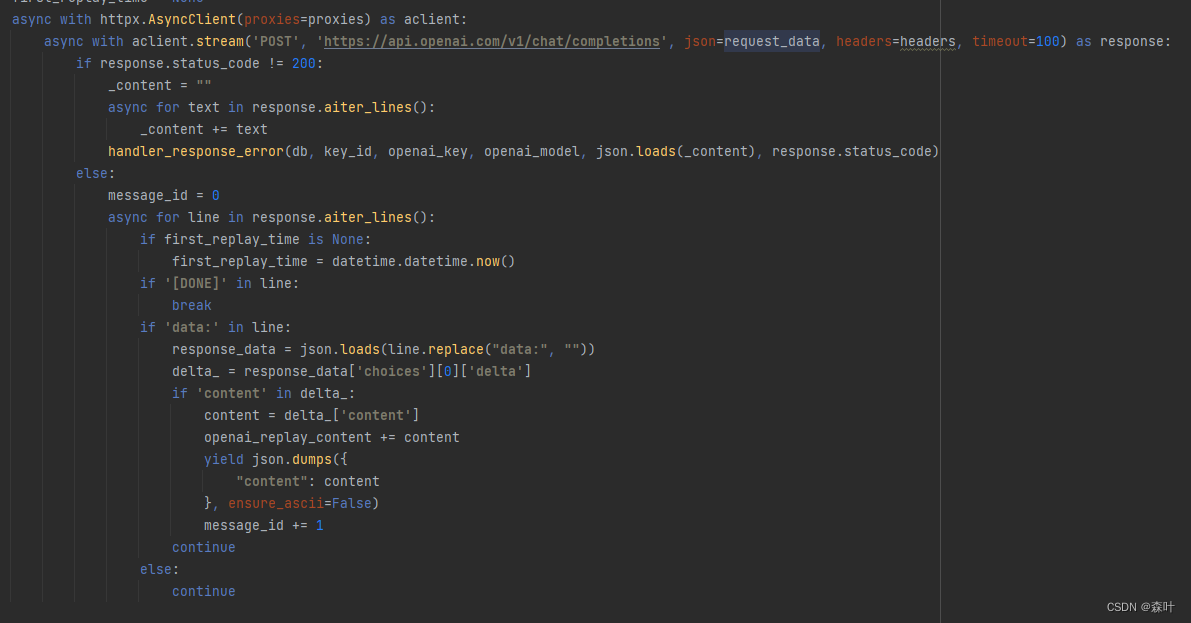
AI Claude 给的讲解
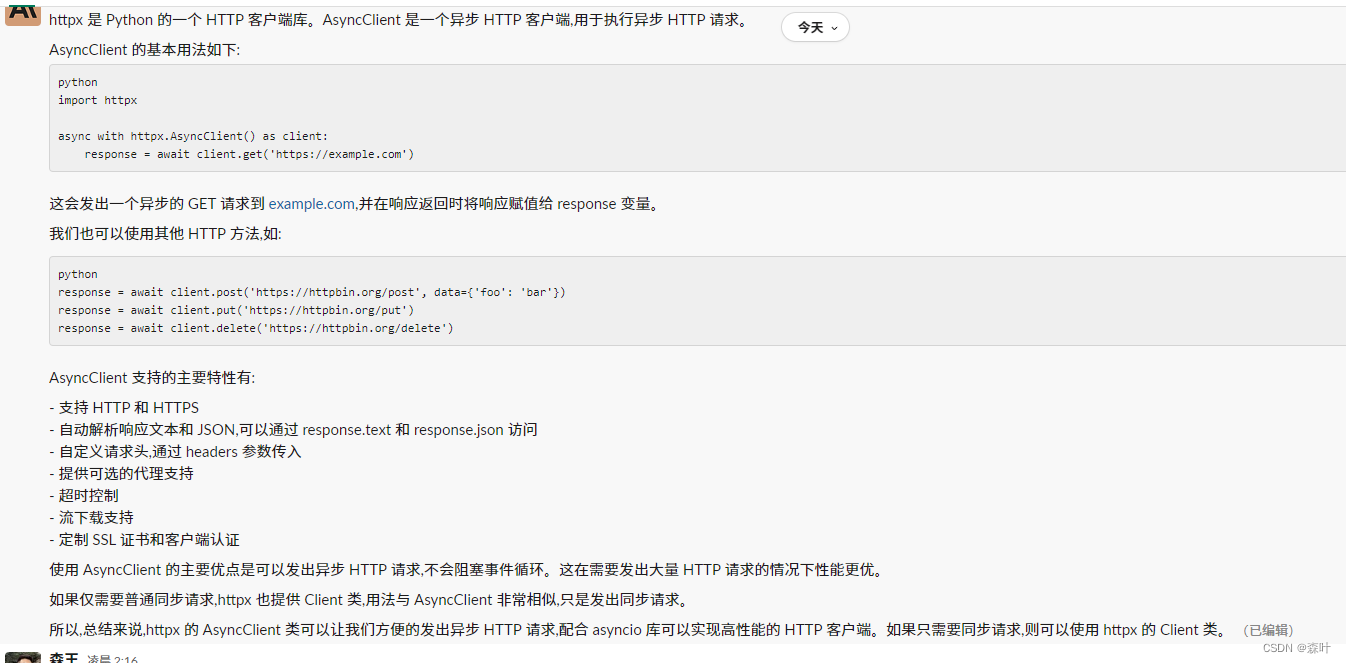
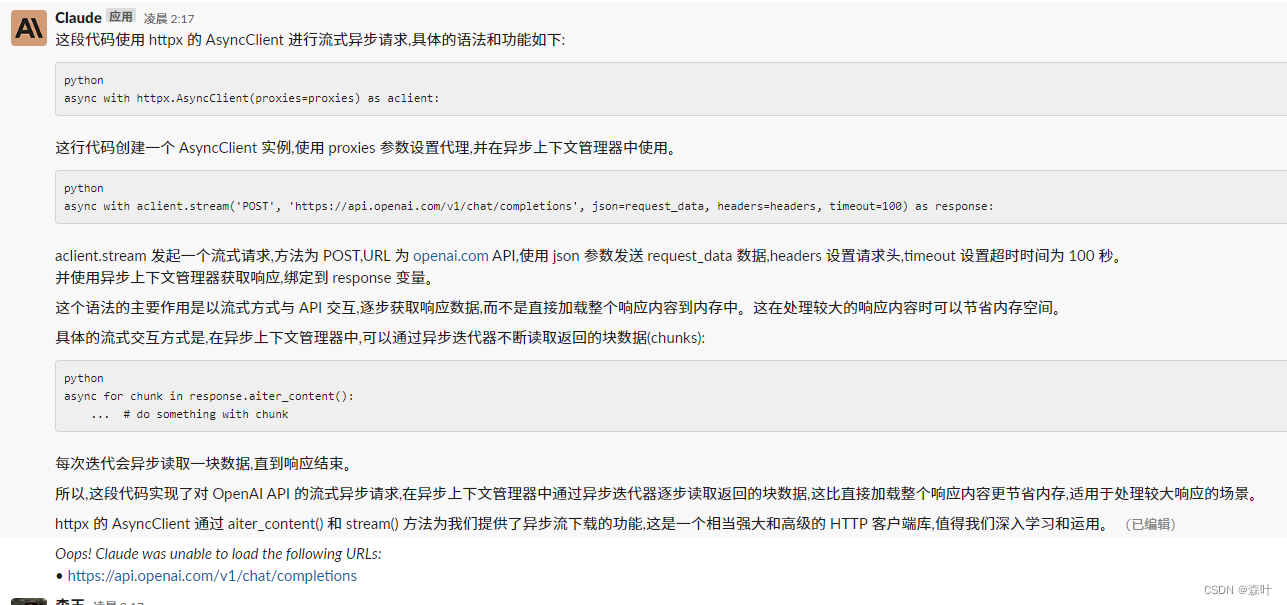
这是一个生成器函数,通过yield函数,yield 很多地方都讲得很晦涩难懂,《你不知道的javascript》中非常简洁地说,这就是一个return,只是对于生成器来说,return次数要进行多次,所以搞了一个yield用来区分同步函数的return,而且return的意义还有停止下面的代码,而返回数据的意思,两者还是有点差异,但是yield就是return,多次返回的return
核心库EventSourceResponse
from sse_starlette import EventSourceResponse

AI给出的EventSourceResponse解读,自己也可以把EventSourceResponse源码丢给Claude,让其看过,给你解读,都是好方法
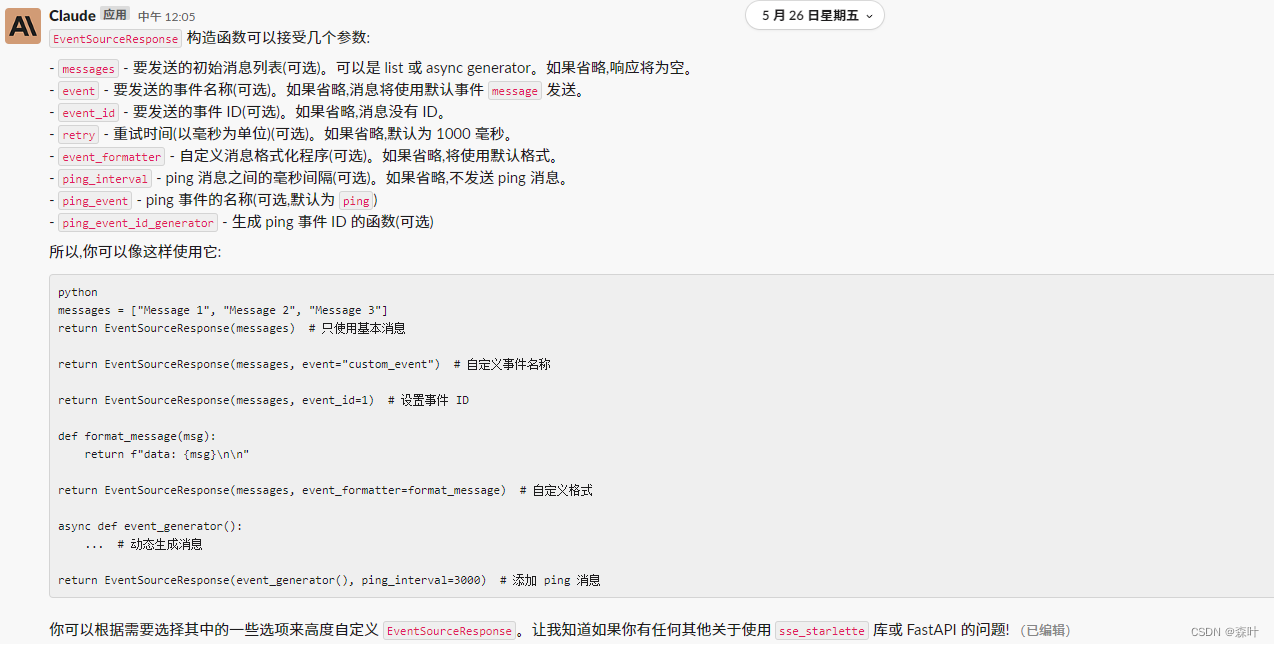
下面给下EventSourceResponse的FastAPI简单案例代码,让大家玩起来
import uvicorn
import asyncio
from fastapi import FastAPI, Request
from fastapi.middleware.cors import CORSMiddleware
from sse_starlette.sse import EventSourceResponse
times = 0
app = FastAPI()
origins = [
"*"
]
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
@app.post("/sse/data")
async def root(request: Request):
event_generator = status_event_generator(request)
return EventSourceResponse(event_generator)
status_stream_delay = 1 # second
status_stream_retry_timeout = 30000 # milisecond
# 其实就是绑定函数事件 一直在跑循环
async def status_event_generator(request):
global times
while True:
if not await request.is_disconnected() == True:
yield {
"event": "message",
"retry": status_stream_retry_timeout,
"data": "data:" + "times" + str(times) + "\n\n"
}
print("alive")
times += 1
await asyncio.sleep(status_stream_delay)
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000, log_level='info')大家对照着上面的讲解,就能把代码搞出来
fetch('http://localhost:8000/sse/data', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
text: "hello"
})
}).then(async response=>{
const reader = response.body.pipeThrough(new TextDecoderStream()).getReader()
while (true) {
let {value, done} = await reader.read();
if (done)
break;
if (value.indexOf("data:") < 0 || value.indexOf('event: ping') >= 0)
continue;
// console.log('Received~~:', value);
let values = value.split("\r\n")
for (let i = 0; i < values.length; i++) {
let _v = values[i].replace("data:", "")
// console.log(_v)
if (_v.trim() === '')
continue
console.log(_v)
}
}
}
).catch(error=>{
console.error(error);
}
);因为自己的业务代码有很多鉴权和数据库操作,就不便放出来了,大家根据自己的所需,可以在这个简单的代码基础上,只要自己写生成器函数即可