总概
A、技术栈
- 开发语言:Java 1.8
- 数据库:MySQL、Redis、MongoDB、Elasticsearch
- 微服务框架:Spring Cloud Alibaba
- 微服务网关:Spring Cloud Gateway
- 服务注册和配置中心:Nacos
- 分布式事务:Seata
- 链路追踪框架:Sleuth
- 服务降级与熔断:Sentinel
- ORM框架:MyBatis-Plus
- 分布式任务调度平台:XXL-JOB
- 消息中间件:RocketMQ
- 分布式锁:Redisson
- 权限:OAuth2
- DevOps:Jenkins、Docker、K8S
B、本节实现目标
- 商品、订单数据存入ES,用于搜索
- RestHighLevelClient、ElasticsearchRestTemplate两种方式实现ES搜索
一、Elasticsearch安装
供参考:
- Windows部署Elasticsearch
- Elasticsearch基础入门
二、ES分词处理器
2.1 Elasticsearch分词
分词分为读时分词和写时分词。
2.1.1 读时分词
读时分词发生在用户查询时,ES 会即时地对用户输入的关键词进行分词,分词结果只存在内存中,当查询结束时,分词结果也会随即消失。
2.1.2 写时分词
写时分词发生在文档写入时,ES 会对文档进行分词后,将结果存入倒排索引,该部分最终会以文件的形式存储于磁盘上,不会因查询结束或者ES重启而丢失。
写时分词器需要在Mapping中指定,而且一经指定就不能再修改,若要修改必须新建索引,但Elasticsearch可以用Put Mapping API新增字段。
2.2 分词处理器
分词一般在ES中有分词器处理,英文为Analyzer,它决定了分词的规则,ES默认自带了很多分词器,如:Standard、english、Keyword、Whitespace等等。默认的分词器为Standard,通过它们各自的功能可组合成你想要的分词规则。分词器具体详情可查看官网:分词器
另外,在常用的中文分词器、拼音分词器、繁简体转换插件。国内用的就多的分别是:
- elasticsearch-analysis-ik
- elasticsearch-analysis-pinyin
- elasticsearch-analysis-stconvert
2.3 分词器插件安装
下载与ES对应版本的中文分词器。将解压后的后的文件夹放入ES根目录下的plugins/ik目录下(ik目录要手动创建)、plugins/pinyin、plugins/stconvert,重启ES即可使用。
插件
三、ES Java API
3.1 Elasticsearch三种Java客户端
Elasticsearch 存在三种Java客户端
1、Transport Client
2、Java Low Level Rest Client (低级rest客户端)
3、Java High Level Rest Client (高级rest客户端)
这三者的区别是:
1、Transport Client 没有使用RESTful风格的接口,而是二进制的方式传输数据。
2、Elasticsearch 官方推出了Java Low Level Rest Client,它支持RESTful。但是缺点是Transport Client的使用者把代码迁移到Java Low Level Rest Client的工作量比较大。
3、Elasticsearch 官方推出Java High Level Rest Client ,它是基于Java Low Level Rest Client的封装,并且API接收参数和返回值和Transport Client是一样的,使得代码迁移变得容易并且支持了RESTful的风格,兼容了这两种客户端的优点。强烈建议ES 5 及其以后的版本使用Java High Level Rest Client。
3.2 Spring Data Elasticsearch
Spring Data Elasticsearch是Spring Data项目下的一个子模块。查看 Spring Data的官网:http://projects.spring.io/spring-data/
Spring Data 的使命是给各种数据访问提供统一的编程接口,不管是关系型数据库(如MySQL),还是非关系数据库(如Redis),或者类似Elasticsearch这样的索引数据库。从而简化开发人员的代码,提高开发效率。
Spring Data Elasticsearch包含了Java High Level Rest Client,从maven依赖包里就可以证实:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>3.0.5</version>
</dependency>
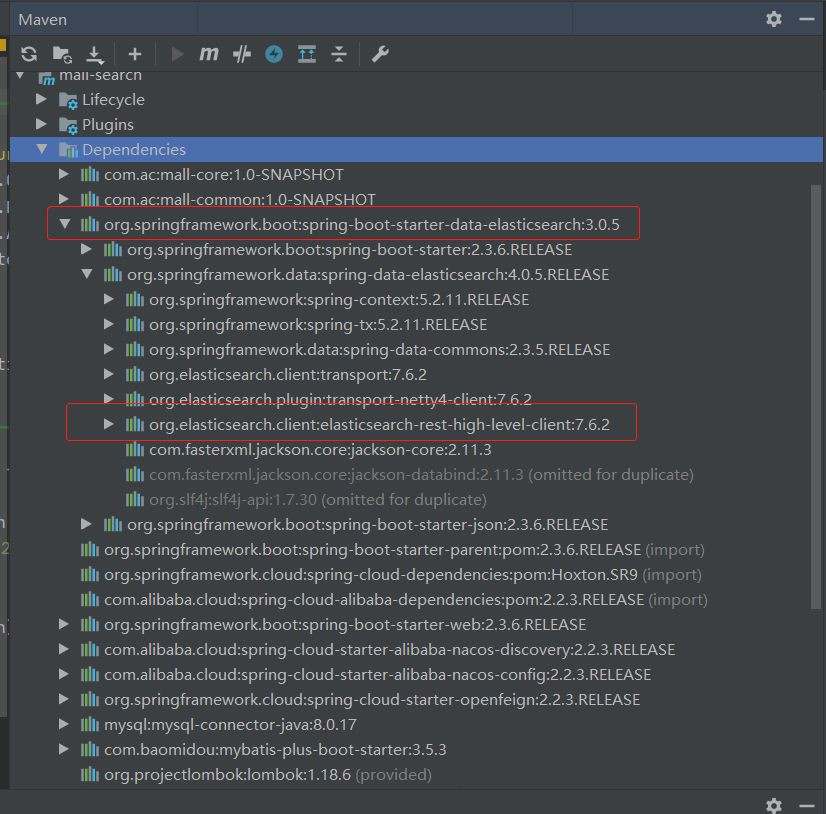
spring-boot-starter-data-elasticsearch
四、代码实现
4.1 新建mall-search服务
新建mall-search服务,该服务专门用户搜索功能,包括提供订单搜索、商品搜索、用户搜索等等。
4.2 maven加ES依赖包
我们使用Spring Data Elasticsearch,因此引入spring-boot-starter-data-elasticsearch
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>3.0.5</version>
</dependency>
由于ES API只会在mall-search服务中使用,因此该maven依赖只在mall-search服务的pom.xml中加入,而不是在mall-pom项目中全局配置
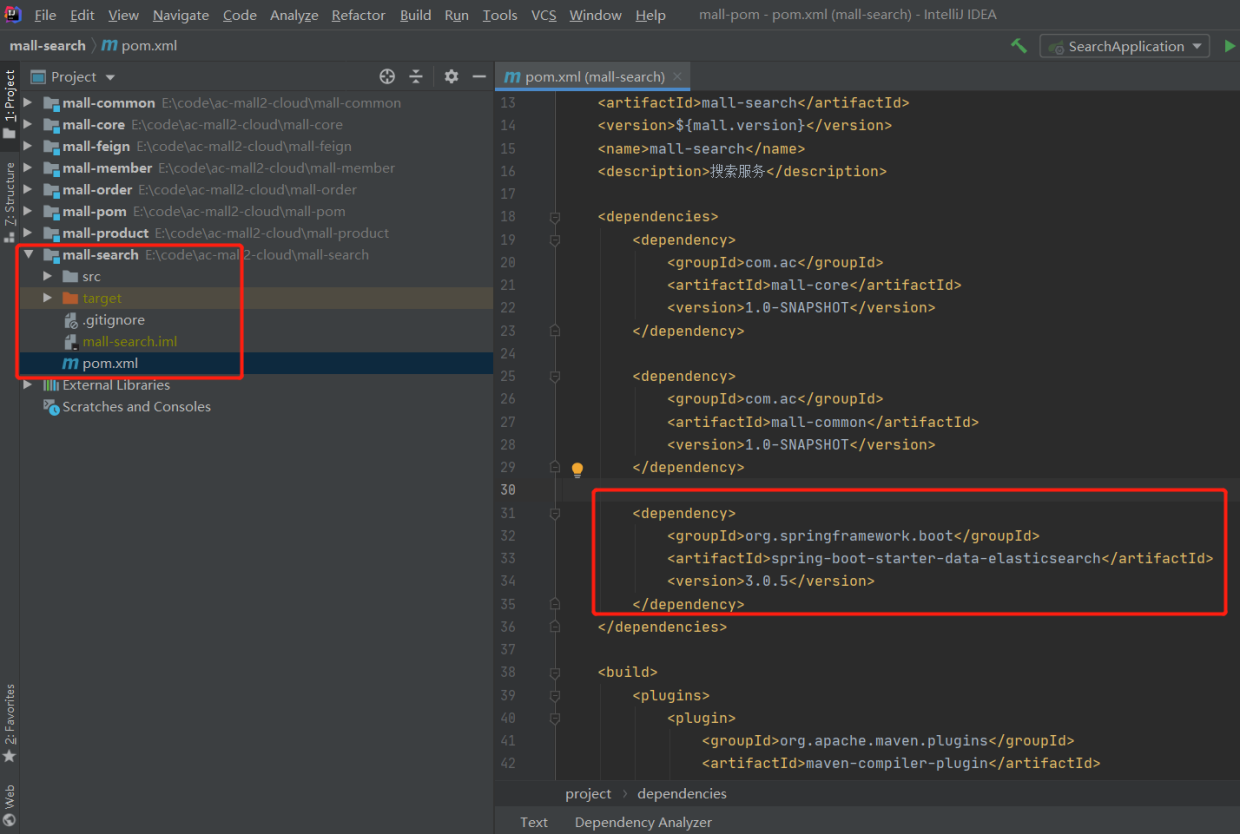
pom.xml
4.3 Elasticsearch配置信息
旧版Elasticsearch配置信息都是在application.yml里配置的,但如果用的是新版Elasticsearch,这样配置会提示已过时,新版我们需要用配置类。
@Configuration
@EnableElasticsearchRepositories
public class EsRestClientConfig extends AbstractElasticsearchConfiguration {
@Value("${es.url}")
private String esUrl;
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo(esUrl)
.build();
return RestClients.create(clientConfiguration).rest();
}
}
ES连接地址我们在Nacos配置(开发、测试、生产都不一样),由于ES连接地址只有我们mall-search服务需要用到,因此该配置项最好不配置在common.yml里,而是新建一个专门给mall-search服务用的配置文件,在Nacos上新建一个yml配置文件,名字(Data ID)要与我们在Nacos上注册的服务名保持一致,不然无法mall-search无法读取到该配置文件的配置内容。
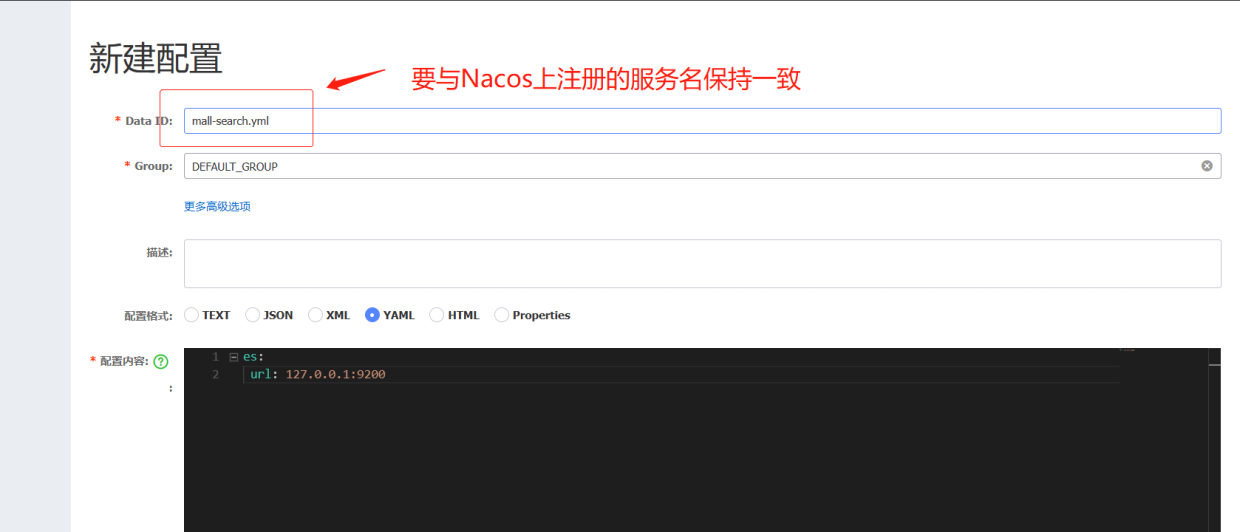
mall-search.yml

配置列表
4.4 两种实现方式
本项目提供了两种实现方式,分别为:RestHighLevelClient、ElasticsearchRestTemplate,分别放在client、template包下,如下图:
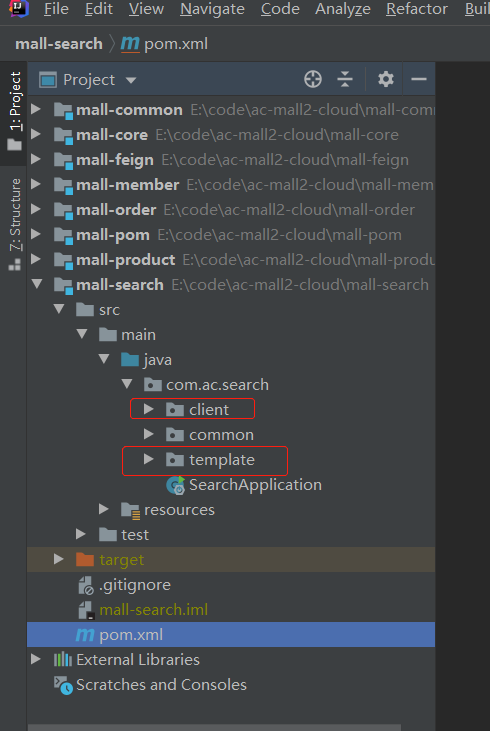
两种实现方式
两种方式,本人更推荐使用client的方式,个人感觉client API更友好。
4.4.1 RestHighLevelClient实现方式
使用该方式,文档对象只是一个普通的Java对象,没有任何ES的相关注解
@Data
public class ProductDoc {
@ApiModelProperty(value = "ID")
private String id;
@ApiModelProperty("产品名称")
private String productName;
@ApiModelProperty("分类")
private String category;
@ApiModelProperty("品牌")
private String brand;
@ApiModelProperty("产品详情描述")
private String remark;
@ApiModelProperty(value = "地理位置")
private GeoPoint location;
}
创建index时也提供了两种方式:
- XContentBuilder
- json文件格式
推荐使用json文件格式的方式,理由有二,一是json文件格式阅读修改更直观,二是json文件里的配置信息可以直接在kibana控制台执行进行调试。
4.4.1.1 XContentBuilder方式
EsClientSetting
@Slf4j
@Component
public class EsClientSetting {
/**
* 创建索引setting
* <p>
* ngram分词器配置
* ngram:英文单词按字母分词
* field("filter","lowercase"):大小写兼容搜索
* <p>
* index.max_ngram_diff: 允许min_gram、max_gram的差值
* https://www.elastic.co/guide/en/elasticsearch/reference/6.8/analysis-ngram-tokenizer.html
* <p>
* normalizer:解决keyword区分大小写
* https://www.elastic.co/guide/en/elasticsearch/reference/6.0/normalizer.html
* <p>
* 拼音搜索
* https://github.com/medcl/elasticsearch-analysis-pinyin
* <p>
* 简体繁华转换
* https://github.com/medcl/elasticsearch-analysis-stconvert
* <p>
* 样例
* https://blog.csdn.net/qq_39211866/article/details/85178707
*
* @return
*/
public XContentBuilder packageSetting() {
XContentBuilder setting = null;
try {
setting = XContentFactory.jsonBuilder()
.startObject()
.field("index.max_ngram_diff", "6")
.startObject("analysis")
.startObject("filter")
.startObject("edge_ngram_filter")
.field("type", "edge_ngram")
.field("min_gram", "1")
.field("max_gram", "50")
.endObject()
.startObject("pinyin_edge_ngram_filter")
.field("type", "edge_ngram")
.field("min_gram", 1)
.field("max_gram", 50)
.endObject()
//简拼
.startObject("pinyin_simple_filter")
.field("type", "pinyin")
.field("keep_first_letter", true)
.field("keep_separate_first_letter", false)
.field("keep_full_pinyin", false)
.field("keep_original", false)
.field("limit_first_letter_length", 50)
.field("lowercase", true)
.endObject()
//全拼
.startObject("pinyin_full_filter")
.field("type", "pinyin")
.field("keep_first_letter", false)
.field("keep_separate_first_letter", false)
.field("keep_full_pinyin", true)
.field("keep_original", false)
.field("limit_first_letter_length", 50)
.field("lowercase", true)
.endObject()
.endObject()
//简2繁
.startObject("char_filter")
.startObject("tsconvert")
.field("type", "stconvert")
.field("convert_type", "t2s")
.endObject()
.endObject()
.startObject("analyzer")
//模糊搜索、忽略大小写(按字符切分)
.startObject("ngram")
.field("tokenizer", "my_tokenizer")
.field("filter", "lowercase")
.endObject()
//ik+简体、繁体转换(ik最小切分)-用于查询关键字分词
.startObject("ikSmartAnalyzer")
.field("type", "custom")
.field("tokenizer", "ik_smart")
.field("char_filter", "tsconvert")
.endObject()
//ik+简体、繁体转换(ik最大切分)-用于文档存储
.startObject("ikMaxAnalyzer")
.field("type", "custom")
.field("tokenizer", "ik_max_word")
.field("char_filter", "tsconvert")
.endObject()
//简拼搜索
.startObject("pinyinSimpleIndexAnalyzer")
.field("type", "custom")
.field("tokenizer", "keyword")
.array("filter", "pinyin_simple_filter", "pinyin_edge_ngram_filter", "lowercase")
.endObject()
//全拼搜索
.startObject("pinyinFullIndexAnalyzer")
.field("type", "custom")
.field("tokenizer", "keyword")
.array("filter", "pinyin_full_filter", "lowercase")
.endObject()
.endObject()
.startObject("tokenizer")
.startObject("my_tokenizer")
.field("type", "ngram")
.field("min_gram", "1")
.field("max_gram", "6")
.endObject()
.endObject()
.startObject("normalizer")
.startObject("lowercase")
.field("type", "custom")
.field("filter", "lowercase")
.endObject()
.endObject()
.endObject()
.endObject();
} catch (Exception e) {
log.error("setting构建失败");
e.printStackTrace();
}
BytesReference bytes = BytesReference.bytes(setting);
String json = bytes.utf8ToString();
log.info("settingJson={}",json);
return setting;
}
}
ProductDocMapping
@Slf4j
@Component
public class ProductDocMapping {
public XContentBuilder packageMapping() {
XContentBuilder mapping = null;
try {
//创建索引Mapping
mapping = XContentFactory.jsonBuilder()
.startObject()
.field("dynamic", true)
.startObject("properties")
.startObject("id")
.field("type", "keyword")
.endObject()
//分类(关键字)
.startObject("category")
.field("type", "keyword")
.endObject()
//品牌(关键字)
.startObject("brand")
.field("type", "keyword")
.endObject()
//产品名称(模糊搜索)
.startObject("productName")
.field("type", "text")
.field("analyzer", "ngram")
.field("search_analyzer", "ikSmartAnalyzer")
.startObject("fields")
.startObject("pinyin")
.field("type", "text")
.field("index", true)
.field("analyzer", "pinyinFullIndexAnalyzer")
.endObject()
.endObject()
.endObject()
//产品详情描述(分词搜索)
.startObject("remark")
.field("type", "text")
.field("analyzer", "ikMaxAnalyzer")
.field("search_analyzer", "ikSmartAnalyzer")
.startObject("fields")
.startObject("pinyin")
.field("type", "text")
.field("index", true)
.field("analyzer", "pinyinFullIndexAnalyzer")
.endObject()
.endObject()
.endObject()
//经纬度
.startObject("location")
.field("type", "geo_point")
.endObject()
.endObject()
.endObject();
} catch (Exception e) {
log.error("packageMapping失败");
e.printStackTrace();
}
BytesReference bytes = BytesReference.bytes(mapping);
String json = bytes.utf8ToString();
log.info("ProductDocMapping={}",json);
return mapping;
}
}
创建代码:
@Override
public boolean createIndex() {
return esClientDdlTool.createIndex(IndexNameConstants.PRODUCT_DOC, productDocMapping.packageMapping());
}
public boolean createIndex(String indexName, XContentBuilder mapping) {
CreateIndexRequest request = buildCreateIndexRequest(indexName);
request.settings(esClientSetting.packageSetting());
request.mapping(mapping);
return doCreateIndex(request);
}
4.4.1.2 json文件格式
common-setting.json
{
"index.max_ngram_diff": "6",
"analysis": {
"filter": {
"edge_ngram_filter": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "50"
},
"pinyin_edge_ngram_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 50
},
"pinyin_simple_filter": {
"type": "pinyin",
"keep_first_letter": true,
"keep_separate_first_letter": false,
"keep_full_pinyin": false,
"keep_original": false,
"limit_first_letter_length": 50,
"lowercase": true
},
"pinyin_full_filter": {
"type": "pinyin",
"keep_first_letter": false,
"keep_separate_first_letter": false,
"keep_full_pinyin": true,
"keep_original": false,
"limit_first_letter_length": 50,
"lowercase": true
}
},
"char_filter": {
"tsconvert": {
"type": "stconvert",
"convert_type": "t2s"
}
},
"analyzer": {
"ngram": {
"tokenizer": "my_tokenizer",
"filter": "lowercase"
},
"ikSmartAnalyzer": {
"type": "custom",
"tokenizer": "ik_smart",
"char_filter": "tsconvert"
},
"ikMaxAnalyzer": {
"type": "custom",
"tokenizer": "ik_max_word",
"char_filter": "tsconvert"
},
"pinyinSimpleIndexAnalyzer": {
"type": "custom",
"tokenizer": "keyword",
"filter": [
"pinyin_simple_filter",
"pinyin_edge_ngram_filter",
"lowercase"
]
},
"pinyinFullIndexAnalyzer": {
"type": "custom",
"tokenizer": "keyword",
"filter": [
"pinyin_full_filter",
"lowercase"
]
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": "1",
"max_gram": "6"
}
},
"normalizer": {
"lowercase": {
"type": "custom",
"filter": "lowercase"
}
}
}
}
product-mapping.json
{
"dynamic": true,
"properties": {
"id": {
"type": "keyword"
},
"category": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"productName": {
"type": "text",
"analyzer": "ngram",
"search_analyzer": "ikSmartAnalyzer",
"fields": {
"pinyin": {
"type": "text",
"index": true,
"analyzer": "pinyinFullIndexAnalyzer"
}
}
},
"remark": {
"type": "text",
"analyzer": "ikMaxAnalyzer",
"search_analyzer": "ikSmartAnalyzer",
"fields": {
"pinyin": {
"type": "text",
"index": true,
"analyzer": "pinyinFullIndexAnalyzer"
}
}
},
"location": {
"type": "geo_point"
}
}
}
创建代码:
@Override
public boolean createIndexByJson() {
return esClientDdlTool.createIndexByJson(IndexNameConstants.PRODUCT_DOC, "/json/product-mapping.json");
}
public boolean createIndexByJson(String indexName, String mappingPath) {
CreateIndexRequest request = buildCreateIndexRequest(indexName);
String settings = ResourceUtil.readFileFromClasspath("/json/common-setting.json");
String mapping = ResourceUtil.readFileFromClasspath(mappingPath);
request.settings(settings, XContentType.JSON);
request.mapping(mapping, XContentType.JSON);
return doCreateIndex(request);
}
其他实现,可查看本项目源代码的client包。
4.4.2 ElasticsearchRestTemplate实现方式
使用该方式,有一个巨坑需要注意,我们在字段上使用@Field注解定义字段类型,analyzer都是无效的,如下代码:
@Field(index = false, type = FieldType.Keyword)
@ApiModelProperty("订单号")
private String orderNo;
我们想将orderNo定义为Keyword类型,但ES还是将orderNo推断并定义成了text类型。
SpringDataElasticsearch版本变动频繁,有很多方法标记为过时,ElasticsearchRestTemplate不读@Filed注解,所以你在@Field里面写再多代码也没用。
ElasticsearchRestTemplate在创建索引的时候不读@Mapping,也就是需要两步才能创建完整的索引 :
- 创建索引
- 更新字段mapping。
ElasticsearchRestTemplate 创建的索引名只读@Document注解,所以必须包含@Document注解。
文档对象:
/**
* @description 订单
*
* 提示:ElasticsearchRestTemplate不读@Filed注解,所以你在@Field里面写再多代码也没用
* 参考:https://blog.csdn.net/QQ401476683/article/details/121422427
*/
@Data
@Setting(settingPath = "/json/common-setting.json")
@Mapping(mappingPath = "/json/order-mapping.json")
@Document(indexName = "order_doc", shards = 1, replicas = 0)
public class OrderDoc {
//@Id
@ApiModelProperty(value = "ID")
private String id;
//@Field(index = false, type = FieldType.Keyword)
@ApiModelProperty("订单号")
private String orderNo;
//@Field(type = FieldType.Text, analyzer = "ik_max_word")
@ApiModelProperty("产品名称")
private String productName;
}
创建index
@Slf4j
@Component
public class EsTemplateDdlTool {
@Resource
private ElasticsearchRestTemplate elasticsearchRestTemplate;
public boolean createIndex(Class<?> clazz) {
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(clazz);
indexOperations.create();
Document document = indexOperations.createMapping(clazz);
indexOperations.putMapping(document);
indexOperations.getSettings();
return true;
}
}
mapping:
{
"dynamic": true,
"properties": {
"id": {
"type": "keyword"
},
"orderNo": {
"type": "keyword"
},
"productName": {
"type": "text",
"fields": {
"pinyin": {
"type": "text",
"analyzer": "pinyinFullIndexAnalyzer"
}
},
"analyzer": "ngram",
"search_analyzer": "ikSmartAnalyzer"
}
}
}
setting:
{
"index.max_ngram_diff": "6",
"analysis": {
"filter": {
"edge_ngram_filter": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "50"
},
"pinyin_edge_ngram_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 50
},
"pinyin_simple_filter": {
"type": "pinyin",
"keep_first_letter": true,
"keep_separate_first_letter": false,
"keep_full_pinyin": false,
"keep_original": false,
"limit_first_letter_length": 50,
"lowercase": true
},
"pinyin_full_filter": {
"type": "pinyin",
"keep_first_letter": false,
"keep_separate_first_letter": false,
"keep_full_pinyin": true,
"keep_original": false,
"limit_first_letter_length": 50,
"lowercase": true
}
},
"char_filter": {
"tsconvert": {
"type": "stconvert",
"convert_type": "t2s"
}
},
"analyzer": {
"ngram": {
"tokenizer": "my_tokenizer",
"filter": "lowercase"
},
"ikSmartAnalyzer": {
"type": "custom",
"tokenizer": "ik_smart",
"char_filter": "tsconvert"
},
"ikMaxAnalyzer": {
"type": "custom",
"tokenizer": "ik_max_word",
"char_filter": "tsconvert"
},
"pinyinSimpleIndexAnalyzer": {
"type": "custom",
"tokenizer": "keyword",
"filter": [
"pinyin_simple_filter",
"pinyin_edge_ngram_filter",
"lowercase"
]
},
"pinyinFullIndexAnalyzer": {
"type": "custom",
"tokenizer": "keyword",
"filter": [
"pinyin_full_filter",
"lowercase"
]
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": "1",
"max_gram": "6"
}
},
"normalizer": {
"lowercase": {
"type": "custom",
"filter": "lowercase"
}
}
}
}
mall-search截图
其他实现,可查看本项目源代码的template包。
五、ES数据同步及数据展示
5.1 ES与MySQL数据同步
ES与MySQL数据同步的方式有很多种,在我们实际项目中用的方式是通过MQ同步数据,比如发布、更新、删除了一个产品,则发布一条MQ消息,将产品的信息放在消息体里,search服务监听MQ,从消息体里取出产品数据并更新到ES里。
5.2 ES数据查询展示更多数据
我们在ES的文档里,ProductDoc基本只存了搜索用到的字段,其他字段没有存,但在我们返回到前端时,需要返回ProductDoc全部字段数据,我们一般的做法是:
- 1、通过ES查询出所有符合条件的数据。
- 2、通过id集合调用product服务的fegin接口,返回ProductDoc全部字段数据。