本章将介绍如何拷贝以及通过下标访问向量。为此,我们讨论一般的拷贝技术,并考虑向量与底层数组表示之间的关系。我们将展示数组与指针的关系及其使用引发的问题。我们还将讨论对于每种类型必须考虑的五种基本操作:构造、默认构造、拷贝构造、拷贝赋值和析构。另外,容器还需要移动构造函数和移动赋值。
18.1 引言
在本章中,我们将学习编程语言特性和技术,从而摆脱来自底层计算机内存的限制和困难。我们希望能够使用根据逻辑需求提供我们恰好想要的属性的类型进行编程。
vector类型能够控制所有对它元素的访问,并提供了从用户角度而不是硬件角度看起来“很自然”的操作。
本章重点介绍拷贝(copying)的概念。这是一个重要但相当技术性的问题:拷贝一个非平凡的(nontrivial,即比int等更加复杂的类型,例如string、vector等)对象意味着什么?拷贝操作后副本之间在多大程度上是独立的?有几种拷贝操作?如何指定使用哪一种?拷贝和其他基本操作(例如初始化和析构)之间有什么关系?
当没有高层次的类型(例如vector和string)时,我们不可避免地需要讨论如何操作内存。我们将研究数组和指针,以及它们的关系、用法和陷阱。这对于任何需要编写低层次C/C++代码的人而言是十分重要的。
注意,虽然vector的实现细节是特定于C++的,但每种语言中的“高层次”类型(string、vector、list、map等)的构建都反应了本章所介绍的一些基本问题的解决方案。
18.2 初始化
第17章中的vector只能初始化为默认值,之后再赋值:
vector v(2); // tedious and error-prone
v.set(0, 1.2);
v.set(1, 7.89);
v.set(2, 12.34);
这种方式不仅繁琐而且容易出错(上面的代码搞错了元素个数)。我们希望直接用一组值来初始化向量,例如:
vector v = {1.2, 7.89, 12.34};
为此,我们需要写一个接受初始化列表作为参数的构造函数。从C++11开始,{}括起来的T类型的元素列表是一个标准库类型initializer_list<T>的对象,定义在头文件<initializer_list>中。因此可以这样编写:
// initializer-list constructor
vector(initializer_list<double> lst) :sz(lst.size()), elem(new double[sz]) {
copy(lst.begin(), lst.end(), elem); // initialize (using std::copy())
}
这里使用了标准库copy()算法将初始化列表中的元素拷贝到elem数组。
简单向量v2 - 初始化列表构造函数
现在有两种方式初始化向量:
vector v1 = {1,2,3}; // three elements 1.0, 2.0, 3.0
vector v2(3); // three elements each with the (default) value 0.0
注意,()用于指定元素个数(调用构造函数vector(int)),{}用于指定元素列表(调用构造函数vector(initializer_list<double>))。例如:
vector v1{3}; // one element with the value 3.0
vector v2(3); // three elements each with the (default) value 0.0
注:如果没有初始化列表构造函数,则vector v{3};等价于vector v(3);,详见9.4.2节“C++初始化语法”。
在大多数情况下,{}前的=可以省略,因此vector v = {1, 2, 3};等价于vector v{1, 2, 3};。
注意,initializer_list<double>是传值的,这是语言规则要求的:initializer_list只是引用了分配在“其他地方”的元素(底层就是一个数组元素的指针,类似于vector,但拷贝initializer_list对象并不会拷贝这些元素)。
18.3 拷贝
再次考虑我们的vector,尝试拷贝一个向量:
void f(int n) {
vector v(3); // define a vector of 3 elements
v.set(2,2.2); // set v[2] to 2.2
vector v2 = v; // what happens here?
// ...
}
理想情况下,v2将成为v的拷贝(副本),即v2.size() == v.size(),并且对于[0, v.size())范围内的所有i满足v2[i] == v[i](虽然现在还没有定义[]运算符)。另外,当f()退出时,所有内存都被返回给自由存储。标准库vector是这样做的,但我们的(仍然过于简单的)vector却不是这样。
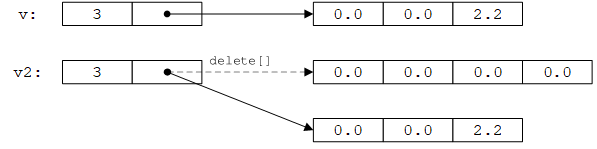
对于一个类而言,拷贝的默认含义是“拷贝所有数据成员”。对于只有内置类型成员的简单类(例如Point),这通常就足够了。但是对于指针成员,仅仅拷贝成员(指针的值)会产生问题。例如对于vector,这意味着拷贝之后v2.sz == v.sz且v2.elem == v.elem,如下图所示:

也就是说,v2并没有拷贝v的元素,只是共享了v的元素(只拷贝了指针),这会导致两个问题:
- 给
v2的元素赋值会影响v的元素,反之亦然,这不是我们想要的结果。 - 当
f()返回时,v和v2的析构函数被隐式调用,导致elem指向的内存被释放了两次,造成灾难性的结果(见17.4.6节)。
18.3.1 拷贝构造函数
我们应该提供一个拷贝操作来拷贝元素,并保证当我们使用一个vector初始化另一个vector时,这个拷贝操作将被调用。
为此,我们需要一个拷贝构造函数(copy constructor),其参数是被拷贝对象的引用。对于vector:
vector(const vector&);
当使用一个对象初始化另一个相同类型的对象时,拷贝构造函数将被调用。 包括:
- 初始化:
T a = b;或T a(b);,其中b是T类型 - 函数参数传递:
f(a),其中a和函数参数都是T类型 - 函数返回值:
return a;,其中函数返回值是T类型,且T没有移动构造函数
改进后的vector如下:
简单向量v2 - 拷贝构造函数
给定拷贝构造函数,再次考虑例子vector v2 = v;,现在的结果如下图所示:

显然,现在两个向量相互独立,改变v中元素的值不会影响v2,反之亦然。析构函数也能够正常工作。
vector v2 = v;等价于vector v2{v};或者vector v2(v);。当v和v2是相同的类型,且该类型定义了拷贝构造函数时,这几种写法的含义完全相同。
18.3.2 拷贝赋值
除了拷贝构造,还可以通过赋值来拷贝对象。和拷贝构造一样,拷贝赋值的默认含义是“拷贝所有成员”,目前的vector就是这样。例如:
void f2(int n) {
vector v(3); // define a vector
v.set(2,2.2);
vector v2(4);
v2 = v; // assignment: what happens here?
// ...
}
我们希望v2称为v的副本,但默认拷贝赋值的结果是使v2.sz == v.sz且v2.elem == v.elem,如下图所示:

这会导致两个问题:
- 重复删除:和默认拷贝构造函数一样,当
f2()返回时,v和v2共同指向的元素被释放了两次。 - 内存泄露:
v2原来指向的4个元素的内存没有被释放。
对于拷贝赋值的改进本质上与拷贝构造相同,需要定义拷贝赋值(copy assignment)运算符:
vector& operator=(const vector& v);
当对象出现在赋值表达式左侧时,拷贝赋值运算符将被调用。
简单向量v2 - 拷贝赋值
赋值比构造更复杂一些,因为必须处理旧的元素。这里先拷贝新元素,之后释放旧元素,最后让elem指向新元素,如下图所示:
现在的vector不会泄露内存和重复释放内存了。
注意,实现赋值操作时,先释放旧元素的内存再拷贝可能会简化代码,但这样无法处理将一个vector赋值给自身的情况:
vector v(10);
v = v; // self-assignment
除非先检查被拷贝的对象和当前对象是否是同一个对象,即if (&v == this) return;。书中的实现方式虽然性能不是最优的(对于自身赋值也拷贝了一次元素),但正确处理了这种情况。
18.3.3 拷贝术语
拷贝的基本问题是拷贝指针(或引用)还是拷贝被指向(或引用)的数据:
- 浅拷贝(shallow copy):只拷贝指针,从而两个指针指向同一个对象。
- 深拷贝(deep copy):拷贝指针指向的数据,从而两个指针指向不同的对象。标准库的
vector、string等都是这样。当我们想要对自己的类的对象进行深拷贝时,就需要定义拷贝构造函数和拷贝赋值。
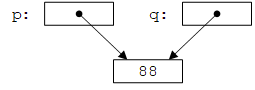
下面是一个浅拷贝的例子:
int* p = new int(77);
int* q = p; // copy the pointer p
*p = 88; // change the value of the int pointed to by p and q
相反,下面是一个深拷贝的例子:
int* p = new int(77);
int* q = new int(*p); // allocate a new int, then copy the value pointed to by p
*p = 88; // change the value of the int pointed to by p
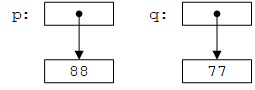
使用这一术语,原来的vector问题在于只做了浅拷贝,而改进后的vector(和标准库vector)做了深拷贝。
提供浅拷贝的类型称为具有指针语义(pointer semantics)或引用语义(reference semantics)(只拷贝地址);提供深拷贝的类型称为具有值语义(value semantics)(拷贝指向的值)。
18.3.4 移动
如果一个vector有很多元素,那么拷贝它的代价会很高。考虑一个例子:
vector fill(istream& is) {
vector res;
for (double x; is>>x; ) res.push_back(x);
return res;
}
void use() {
vector vec = fill(cin);
// ... use vec ...
}
假设res有10万个元素,则将其拷贝到vec的代价是很高的。但是我们并不希望拷贝,毕竟我们永远不会使用res。
一种替代方法是传引用参数:
void fill(istream& is, vector& v) {
for (double x; is>>x; ) v.push_back(x);
}
void use() {
vector vec;
fill(cin, vec);
// ... use vec ...
}
缺点是不能使用返回值语法,必须先声明变量。
另一种方法是返回new创建的指针:
vector* fill(istream& is) {
vector* res = new vector;
for (double x; is>>x; ) res->push_back(x);
return res;
}
void use() {
vector* vec = fill(cin);
// ... use vec ...
delete vec;
}
缺点是必须记得delete这个向量(如17.4.6节所述)。
我们希望使用返回值语法,同时避免拷贝。为此,C++11引入了移动语义(move semantics):通过“窃取”资源,直接将res的资源移动(move)到vec,如下图所示:

移动之后,vec将引用res的元素,而res将被置空(换句话说,移动 = “窃取”资源 = 浅拷贝+置空原指针)。从而以仅仅拷贝一个int和一个指针的代价将10万个元素从res移动到vec。
为了在C++中表达移动语义,需要定义移动构造函数(move constructor)和移动赋值(move assignment)运算符:
vector(vector&& v); // move constructor
vector& operator=(vector&& v); // move assignment
其中&&符号称为右值引用(rvalue reference)。注意移动操作的参数不是const,因为移动操作的目的之一是将源对象置空。
当使用一个右值初始化一个相同类型的对象时,移动构造函数将被调用。 包括:
- 初始化:
T a = std::move(b);或T a(std::move(b));,其中b是T类型 - 函数参数传递:
f(std::move(a)),其中a和函数参数都是T类型 - 函数返回值:
return a;,其中函数返回值是T类型,且T有移动构造函数
注:C++17引入了拷贝消除(copy elision),如果初始值是纯右值(prvalue),则移动构造函数调用会被优化掉。
当对象出现在赋值表达式左侧,并且右侧是一个相同类型的右值时,移动赋值运算符将被调用。
简单向量v2 - 移动构造函数和移动赋值
再次考虑前面的例子,在fill()返回时移动构造函数将被隐式调用(fill()和use()的代码均不需要修改)。
18.4 基本操作
现在可以讨论如何决定一个类应该有哪些构造函数,是否应该有析构函数,以及是否应该提供拷贝和移动操作。有7种需要考虑的基本操作:
- 有参构造函数
T(A1 a1, A2 a2, ...) - 默认构造函数
T() - 拷贝构造函数
T(const T&) - 拷贝赋值
T& operator=(const T&) - 移动构造函数
T(T&&) - 移动赋值
T& operator=(T&&) - 析构函数
~T()
通常,我们需要一个或多个带参数的构造函数来初始化对象,初始值(参数)的含义和用途完全取决于构造函数。通常我们使用构造函数来建立不变式(9.4.3节)。
如果我们希望在不指定初始值的情况下创建类的对象,则需要默认构造函数。最常见的例子是将对象放在标准库vector中(例如vector vs(10);)。当我们可以用一个有意义的、明显的默认值为类建立不变式时,默认构造函数是有意义的。例如,对于数值类型默认值为0,对于string为空字符串,对于vector为空向量。对于类型T,如果存在默认构造函数,则T{}或T()是默认值。
如果一个类获取了资源,则需要析构函数。资源包括自由存储、文件、锁、线程句柄、套接字等。一个类需要析构函数的另一个特征是它具有指针或引用成员。
一个需要析构函数的类几乎总是需要拷贝操作和移动操作。原因很简单:如果一个对象获取了资源(具有指向它的指针成员),那么拷贝的默认含义(浅拷贝)几乎肯定是错误的。vector是一个典型的例子。
另外,如果派生类具有析构函数,则基类需要虚析构函数(17.5.2节)。
18.4.1 显式构造函数
接受单个参数的构造函数定义了一个从参数类型到该类型的转换。例如:
class complex {
public:
complex(double); // defines double-to-complex conversion
complex(double,double);
// ...
};
complex z1 = 3.14; // OK: convert 3.14 to (3.14,0)
complex z2 = complex(1.2, 3.4);
然而,应该谨慎地使用这种隐式转换,因为它可能造成意想不到的结果。例如,vector有一个接受int的构造函数,因此可以这样使用:
vector v = 10; // odd: makes a vector of 10 doubles
v = 20; // eh? Assigns a new vector of 20 doubles to v
void f(const vector&);
f(10); // eh? Calls f with a new vector of 10 doubles
我们可以通过显式构造函数(explicit constructor)禁止将构造函数用于隐式转换。显式构造函数使用关键字explicit定义:
class vector {
// ...
explicit vector(int);
// ...
};
vector v = 10; // error: no int-to-vector conversion
v = 20; // error: no int-to-vector conversion
vector v0(10); // OK
void f(const vector&);
f(10); // error: no int-to-vector<double> conversion
f(vector(10)); // OK
简单向量v2 - 显式构造函数
18.4.2 调试构造函数和析构函数
在程序的执行过程中,构造函数和析构函数都在明确定义的、可预测的点被调用:
- 每当类型
X的一个对象被创建时,X的一个构造函数将被调用。例如,变量初始化、传值参数、使用new创建对象、拷贝对象等。 - 每当类型
X的一个对象被销毁时,X的析构函数将被调用。例如,变量离开作用域、delete一个指向对象的指针或者程序结束。
为了体会这个问题,一种好方法是在构造函数、赋值操作和析构函数中加入打印语句。例如:
试一试
★一定要运行这个例子,并确保你理解了输出结果,这样你就会明白对象的构造和析构的大致过程。
程序的每一行语句对应的输出如下图所示:

其中几个比较复杂语句的拷贝过程如下图所示(其中箭头上的 “c” 表示拷贝构造,“=” 表示拷贝赋值):
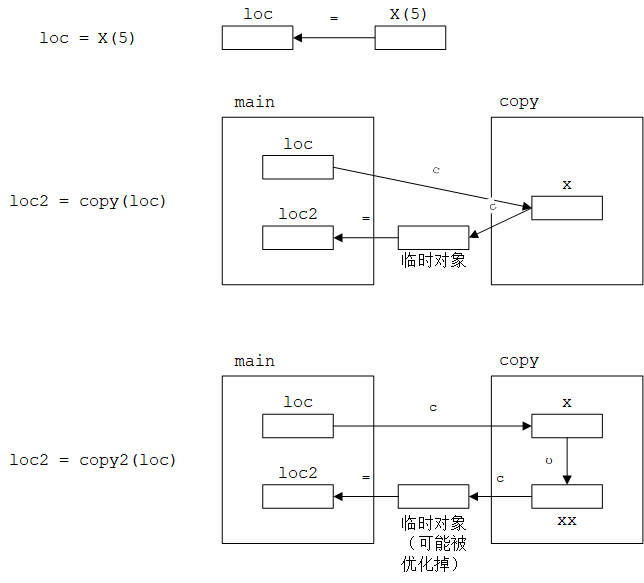
loc = X(5):①创建临时对象X(5)(地址为0xae19bffa90);②将临时对象拷贝赋值到loc(地址为0xae19bffa8c);③销毁临时对象。loc2 = copy(loc):①由loc拷贝构造copy()函数的形参x(地址为0xae19bffa98);②由形参x拷贝构造返回值临时对象(地址为0xae19bffa94);③将临时对象拷贝赋值到loc2(地址为0xae19bffa88);④销毁临时对象;⑤销毁形参x。loc2 = copy2(loc):①由loc拷贝构造copy2()函数的形参x(地址为0xae19bffaa0);②由形参x拷贝构造局部变量xx(地址为0xae19bffa9c);③由xx拷贝构造返回值临时对象;④将临时对象拷贝赋值到loc2(地址为0xae19bffa88);⑤销毁临时对象;⑥销毁局部变量xx;⑦销毁形参x。注意,这里的返回值临时对象可能会被编译器优化掉,即直接将xx拷贝赋值到loc2,上面的输出结果就是这样。X& r = ref_to(loc):参数和返回值都是引用,因此没有任何构造函数调用。vector<X> v(4):每个元素都调用默认构造函数(这也说明vector的这种用法要求元素类型必须是可默认构造的)。- 程序结束之前,所有对象的析构函数被调用,并且销毁顺序与创建顺序相反。
有些编译器足够智能,能够消除不必要的拷贝。但是,如果想要做到可移植(即在不同平台、使用不同编译器都能得到相同的效果),考虑移动操作。
18.5 访问vector元素
到目前为止,我们一直使用set()和get()成员函数访问元素。为了使用通常的下标语法v[i],需要重载[]运算符,即定义一个名为operator[]的成员函数:
double operator[](int i) { return elem[i]; }
这种实现看起来很好,但过于简单了——这个下标运算符返回的值只可读不可写(因为返回值double是一个右值而不是左值):
vector v(10);
double x = v[2]; // fine
v[3] = x; // error: v[3] is not an lvalue
其中v[i]被解释为v.operator[](i)。
返回元素的引用可以解决这一问题:
double& operator[](int n) { return elem[n]; }
现在上面的代码可以正常工作,因为double&是一个左值。
注:[]运算符可以代替set()和get()。
18.5.1 const重载
目前的operator[]还有一个问题:不能对const vector调用。例如:
void f(const vector& cv) {
double d = cv[1]; // error, but should be fine
cv[1] = 2.0; // error (as it should be)
}
其中第一个cv[1]只读取了元素的值,并没有修改vector,但编译器仍然会报错,因为operator[]的返回类型是double&,本身就是可修改的。解决方法是提供一个const成员函数版本:
double& operator[](int n); // for non-const vectors
double operator[](int n) const; // for const vectors
const版本的operator[]也可以返回const double&,但double是一个很小的对象,因此没有必要返回引用(见8.5.6节)。现在可以这样使用:
void ff(const vector& cv, vector& v) {
double d = cv[1]; // fine (uses the const [])
cv[1] = 2.0; // error (uses the const [])
d = v[1]; // fine (uses the non-const [])
v[1] = 2.0; // fine (uses the non-const [])
}
简单向量v2 - 下标运算符
18.6 数组
数组(array)是一个固定大小的、连续的元素序列。
T a[N];声明了一个由N个T类型的元素组成的数组,其中N必须是整型常量表达式。T* p = new T[n];在自由存储上分配了一个由N个T类型的元素组成的数组,其中n可以是任意整型表达式。
数组元素编号为0到N-1,可以使用下标运算符[]访问,即a[0]、…、a[N-1]。
数组有很大的局限性(例如数组不知道自身的大小),因此尽可能优先使用vector。然而,数组早在vector之前就存在了,并且与其他语言(尤其是C语言)的数组大致等价,因此你必须了解数组,以便能够应付那些很久以前的代码,或者由不能使用vector的人编写的代码。
18.6.1 指向数组元素的指针
指针可以指向数组元素。例如:
double ad[10];
double* p = &ad[5]; // point to ad[5]
现在指针p指向ad[5]:

可以对指针使用下标和解引用,从而访问数组元素:
*p = 7; // equivalent to p[0] = 7
p[2] = 6;
p[–3] = 9;
得到

下标可以是正数或负数,只要对应的元素在数组的范围[0, N)内。然而,访问数组范围之外的数据是非法的(见17.4.3节)。
当指针指向一个数组时,加减操作可以让指针指向其他元素。例如:
p += 2; // move p 2 elements to the right

p –= 5; // move p 5 elements to the left

使用+、-、+=和-=移动指针的操作称为指针运算(pointer arithmetic)。进行这种操作时,我们必须保证结果不会超过数组的范围:
p += 1000; // insane: p points into an array with just 10 elements
double d = *p; // illegal: probably a bad value (definitely an unpredictable value)
*p = 12.34; // illegal: probably scrambles some unknown data
不幸的是,并非所有涉及指针运算的bug都很容易发现。通常最好避免指针运算。
指针运算最常见的用法是使用++指向下一个元素以及使用--指向上一个元素。例如,可以这样打印ad的元素值:
for (double* p = &ad[0]; p < &ad[10]; ++p) cout << *p << '\n';
for (double* p = &ad[9]; p >= &ad[0]; ––p) cout << *p << '\n';
注:
p+i等价于&p[i],*(p+i)等价于p[i]- 指针与整数加减时,会自动放缩对象大小的倍数。例如,
p+i与p实际的地址值之差为i * sizeof(*p),因此刚好指向p之后的第i个对象。
指针运算的大多数实际用法是将指针作为函数参数传递。在这种情况下,编译器并不知道指针指向的数组有多少个元素,你必须主动提供。我们应当尽量避免这种情况。
18.6.2 指针和数组
数组名代表了数组的所有元素。例如:
char ch[100];
则sizeof(ch)是100。
然而,数组名是首元素的地址,因此可以转换(“退化”)为指针。例如:
char* p = ch;
其中p被初始化为&ch[0],但sizeof(p)是4(或8)而不是100。
这一点是非常有用的。一个原因是将数组传递给指针参数时可以避免拷贝。例如,函数strlen()统计以0结尾的字符数组中的字符数(即C风格字符串的长度):
// similar to the standard library strlen()
int strlen(const char* p) {
int count = 0;
while (*p) { ++count; ++p; }
return count;
}
可以通过strlen(ch)调用该函数,这等价于strlen(&ch[0])。和vector不同,通过参数传递数组并不会拷贝数组元素(只拷贝了一个指针)。参数声明char* p等价于char p[]。
注意,数组名不能被赋值,例如:
char ac[10];
ac = new char[20]; // error: no assignment to array name
&ac[0] = new char[20]; // error: no assignment to pointer value
也不能使用赋值拷贝数组:
int x[100];
int y[100];
x = y; // error
int z[100] = y; // error
如果需要拷贝数组,则必须编写复杂的代码。例如:
for (int i=0; i<100; ++i) x[i]=y[i]; // copy 100 ints
memcpy(x,y,100*sizeof(int)); // copy 100*sizeof(int) bytes
copy(y,y+100, x); // copy 100 ints
注:关于指针与数组的关系另见
- 《C程序设计语言》笔记 第5章 指针与数组
- 二维数组的行指针和列指针
18.6.3 数组初始化
字符数组可以使用字符串常量初始化。 例如:
char ac[] = "Beorn"; // array of 6 chars
字符串只有5个字符,但ac的长度为6,因为编译器会自动在字符串常量的末尾添加0,如下图所示:

这种以0结尾的字符数组称为C风格字符串(C-style string)。所有的字符串常量都是C风格字符串。例如:
char* pc = "Howdy"; // pc points to an array of 6 chars
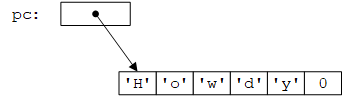
注意,结尾是字符'\0'(值为0)而不是'0'(值为48)。结尾0的目的在于让函数找到字符串的结尾(例如strlen()),因为数组不知道自身的大小。
标准库头文件<cstring>定义了strlen()函数。该函数统计字符数,不包括结尾的0。因此,n个字符的C风格字符串需要长度为n+1的字符数组来存储。
只有字符数组可以使用字符串常量初始化,但所有数组都可以使用对应元素类型的初始值列表进行初始化。例如:
int ai[] = {1, 2, 3, 4, 5, 6}; // array of 6 ints
int ai2[100] = {0,1,2,3,4,5,6,7,8,9}; // the last 90 elements are initialized to 0
double ad[100] = {}; // all elements initialized to 0.0
char chars[] = {'a', 'b', 'c'}; // no terminating 0!
注意,chars的长度是3(而不是4)——“在末尾添加0”的规则只适用于字符串。如果没有指定数组大小,则从初始化列表中推断出来。 如果初始值的个数小于数组大小(例如ai2和ad),则剩余元素将被初始化为元素类型的默认值。
18.6.4 指针问题
指针和数组经常被过度使用和误用,本节对经常出现的问题进行总结。所有与指针相关的严重问题都涉及试图访问非预期类型对象的数据,而很多这种问题涉及访问数组边界之外的数据(越界访问)。在本节中我们主要考虑:
- 通过空指针访问
- 通过未初始化的指针(野指针)访问
- 访问数组结尾之后的数据
- 访问已释放的对象
- 访问已离开作用域的对象
在所有情况下,对于程序员来说实际的问题在于代码看起来没有问题。更糟糕的是(当通过指针写数据时),问题可能在某些表面上不相关的对象被损坏很长时间之后才显现出来。下面考虑一些例子。
(1)不要通过空指针访问数据
int* p = nullptr;
*p = 7; // ouch!
显然,在真实世界的程序中,初始化和使用之间通常还存在其他代码,将p传递给函数或者接受函数返回值是十分常见的例子。尽量不要传递空指针,如果必须这么做,则在使用前检查空指针:
int* p = fct_that_can_return_a_nullptr();
if (p == nullptr) {
// do something
}
else {
// use p
*p = 7;
}
void fct_that_can_receive_a_nullptr(int* p) {
if (p == nullptr) {
// do something
}
else {
// use p
*p = 7;
}
}
使用引用和使用异常捕获错误是避免空指针的主要工具。
注:引用无法像空指针一样表达“不存在”的含义(相当于将检查空指针的工作留给了调用者)。C++17引入了optional,表示一个“可能存在的值”,同时有助于避免空指针问题。
(2)对指针进行初始化
int* p;
*p = 9; // ouch!
特别的,不要忘记初始化类成员指针。
(3)不要访问不存在的数组元素
int a[10];
int* p = &a[10];
*p = 11; // ouch!
a[10] = 12; // ouch!
小心循环的第一个和最后一个元素(例如18.6.1节最后打印数组元素的例子)。尽量不要将数组作为第一个元素的指针进行传递,取而代之的是使用vector。如果必须这么做,那么应该极其小心,并且将数组大小一起传递。
(4)不要通过已删除的指针访问数据
int* p = new int(7);
// ...
delete p;
// ...
*p = 13; // ouch!
delete p或此后的代码可能已经改写了*p或将其用于其他对象(注:有的编译器可能在delete时将p指向的内存区域填充为一些无意义的字节,之后这块内存可能被内存管理器分配给其他对象)。在所有问题中,这一问题是最难系统地避免的。防止这一问题的最有效方法是避免出现“裸露的”new和delete——只在构造函数和析构函数中使用new和delete,或者使用容器来处理delete。
(5)不要返回局部变量的指针
int* f() {
int x = 7;
// ...
return &x;
}
// ...
int* p = f();
// ...
*p = 15; // ouch!
在函数退出时局部变量将被释放。几乎没有编译器会捕获与返回局部变量的指针相关的问题。
考虑一个逻辑上等价的例子:
vector& ff() {
vector x(7); // 7 elements
// ...
return x;
} // the vector x is destroyed here
// ...
vector& p = ff();
// ...
p[4] = 15; // ouch!
很多编译器都能捕获这种返回问题。
程序员通常会低估这些问题。然而,很多有经验的程序员都曾经被这些简单的数组和指针问题不计其数的变体和组合所打败。解决方法是不要使用指针、数组、new和delete污染你的代码。如果你这么做了,那么在真实规模的程序中,“小心谨慎”是根本不够的。相反,应该依赖向量、RAII(“Resource Acquisition Is Initialization”,见19.5节),以及其他的系统途径来管理内存和其他资源。