1、流程解析
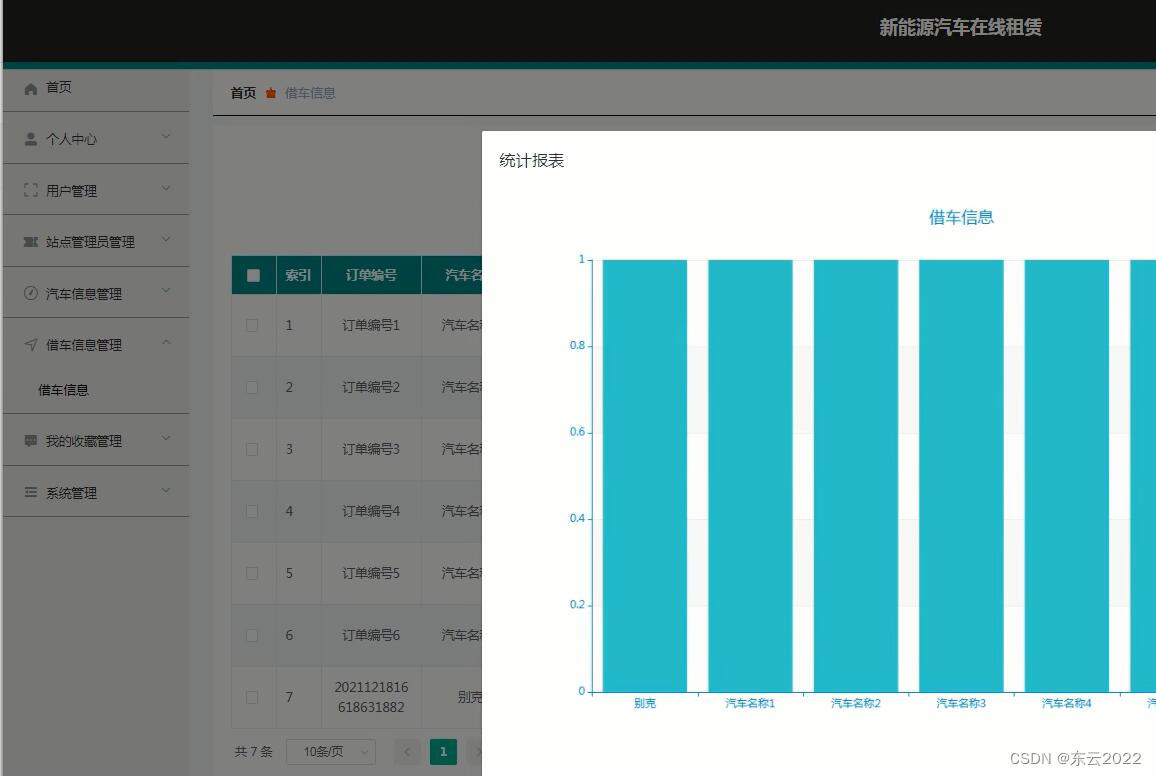
在该系列第二篇文章中介绍了spark sql整体的解析流程,我们知道整体的sql解析分为未解析的逻辑计划(Unresolved LogicalPlan)、解析后的逻辑计划(LogicalPlan)、优化后的逻辑计划(Optimized LogicalPlan)、物理计划(PhysiclPlan)等四个阶段。物理计划是sql转换执行的最后一个环节,过程比较复杂,其内部又分三个阶段,如下图所示:
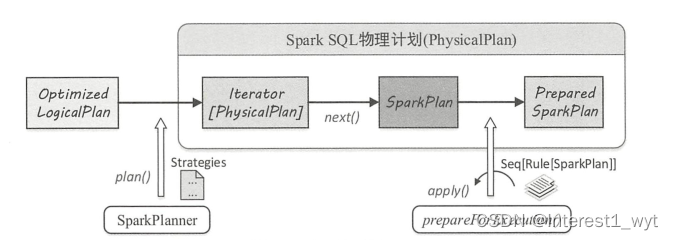
这3个阶段所做的工作分别如下:
1)由SparkPlanner将各种物理计划策略(Strategy,可自定义扩展)作用于对应的LogicalPlan节点上,生成SparkPlan列表(注:一个 LogicalPlan 可能产生多种 SparkPlan)。
2)选取最佳的SparkPlan,在Spark3.0.1版本中的实现较为简单,在候选列表中直接用 next()方法获取第一个。
3)提交前进行准备工作,进行一些分区排序方面的处理,确保SparkPlan各节点能够正确执行,这一步通过 prepareForExecution方法调用若干规则(Rule,可自定义扩展)进行转换。
注:如果对Strategy和Rule的扩展入口感兴趣的,可以参考该系列的第二篇文章:spark sql(二)sql解析流程扩展_Interest1_wyt的博客-CSDN博客
2、节点分类
根据SparkPlan的子节点数目,可以大致将其分为4类。分别为 LeafExecNode、UnaryExecNode、BinaryExecNode和其他不属于这3种子节点的类型。
1)LeafExecNode
叶子节点类型的物理执行计划不存在子节点,物理执行计划中与数据源相关的节点都属于该类型。LeafExecNode类型的SparkPlan负责对初始RDD的创建。例如:
angeExec会利用SparkContext中的parallelize方法生成给定范围内的64位数据的RDD;HiveTableScanExec会根据Hive数据表存储的HDFS信息直接生成HadoopRDD;FileSourceScanExec根据数据表所在的源文件生成FileScanRDD。
2)UnaryExecNode
UnaryExecNode类型的物理执行计划的节点是一元的,意味着只包含1个子节点,UnaryExecNode类型的物理计划也是数量最多的类型。UnaryExecNode节点的作用主要是对RDD进行转换操作。例如:
ProjectExec和FilterExec分别对子节点产生的RDD进行列剪裁与行过滤操作;
Exchange负责对数据进行重分区;
SampleExec对输入RDD中的数据进行采样;
SortExec按照一定条件对输入RDD中数据进行排序;
WholeStageCodegenExec类型的SparkPlan将生成的代码整合成单个Java函数。
3)BinaryExecNode
BinaryExecNode类型的SparkPlan具有两个子节点,这种二元类型的物理执行计划大多与数据的关联处理有关,比如常见的join处理。
4)其它节点
除上述3种类型的SparkPlan外,SparkSQL中还有许多其他类型的物理执行计划,如Union等。
3、源码追踪
spark sql物理计划这一块内容很杂,特别是还涉及分区与排序。所以理解起来很困难,本人也是处于知其然不知其所有然的尴尬状态,故下面通过源码的追踪串一下整体的逻辑。具体的细节则需要时间慢慢打磨。代码demo如下:
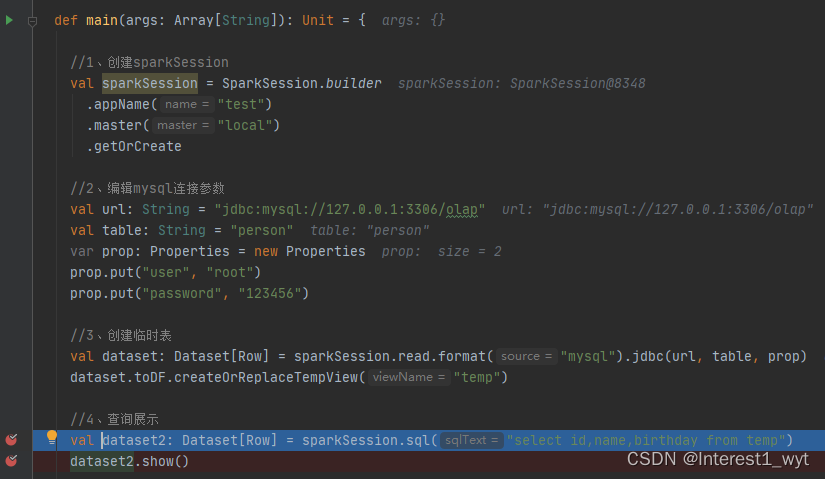
def main(args: Array[String]): Unit = {
//1、创建sparkSession
val sparkSession = SparkSession.builder
.appName("test")
.master("local")
.getOrCreate
//2、编辑mysql连接参数
val url: String = "jdbc:mysql://127.0.0.1:3306/olap"
val table: String = "person"
var prop: Properties = new Properties
prop.put("user", "root")
prop.put("password", "123456")
//3、创建临时表
val dataset: Dataset[Row] = sparkSession.read.format("mysql").jdbc(url, table, prop)
dataset.toDF.createOrReplaceTempView("temp")
//4、查询展示
val dataset2: Dataset[Row] = sparkSession.sql("select id,name,birthday from temp")
dataset2.show()
}前三部分主要是构建环境和创建临时表,这里不过多解释,我们从 第四部分查询开始追踪源码。因为大体流程在前面讲过,所以这里对于物理计划之前的流程简单介绍,在物理计划解析时进行详细介绍。首先是执行sql语句生成Dataset数据集(注意这里的数据集还没数据,只有在执行show方法时才会触发计算操作):
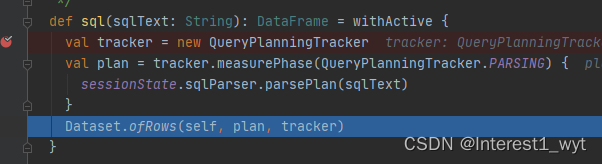
这里tracker是一个追踪器,追踪sql计划各个阶段的起止时间以及各个规则作用的时间段等。plan则是生成最基础的未解析的逻辑计划。最后通过ofRows返回一个Dataset数据集。我们接着到ofRows中查看:
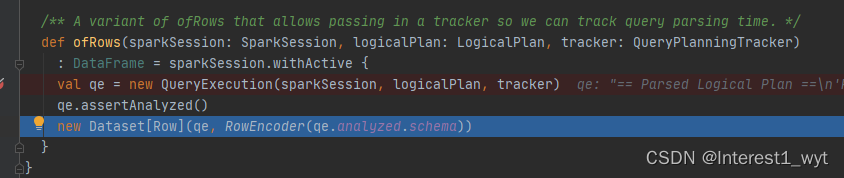
ofRows方法中首先是创建一个QueryExecution对象,这是很重要的一个对象,它包含了sql计划的各个阶段。其次是通过assertAnalyzed将未解析的逻辑计划转换为解析后的逻辑计划。最后封装成Dataset返回(此时的Dataset还没有数据,只有遇到action算子才会触发后续流程)。
最后一路返回到最后的demo代码中,接着从show方法开始看:

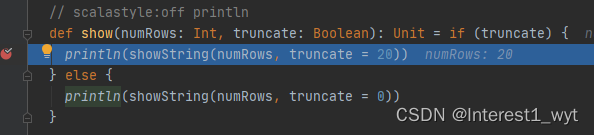
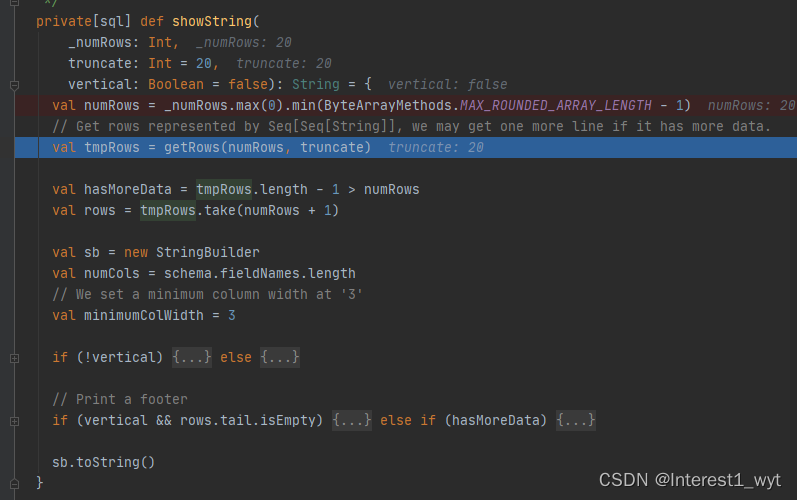
这里第一行代码是获取要展示数据的行数,第二行getRows则是获取具体的数据,所以进入getRows看一下:
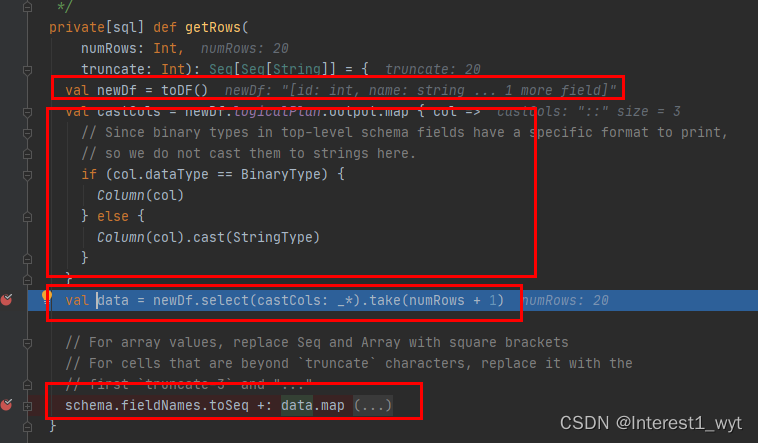
这里首先是重新生成一个Dataset数据集,随后对新数据集的数据字段的类型做一些转换——非日期字段统一转为字符串类型。然后执行select转换和take行动操作。select主要是基于逻辑计划做一些转换,不是此次的重点,感兴趣的自己看下。最后一步操作则是拼装返回结果,也不是重点。这里我们直接看下take的操作:

 这里withAction是一个高阶函数,乍一看可能不知道这个函数的执行逻辑。这里我大致介绍下:首先当前所在的类是Dataset,所以执行limit(n).queryExecution其实就是在当前数据集所对应的逻辑计划上加一层limit封装,然后返回当前sql计划的QueryExecution对象。至于最后的collectFromPlan则是一个函数,其当做参数传递到withAction方法中。这里我们接着到withAction中看一下:
这里withAction是一个高阶函数,乍一看可能不知道这个函数的执行逻辑。这里我大致介绍下:首先当前所在的类是Dataset,所以执行limit(n).queryExecution其实就是在当前数据集所对应的逻辑计划上加一层limit封装,然后返回当前sql计划的QueryExecution对象。至于最后的collectFromPlan则是一个函数,其当做参数传递到withAction方法中。这里我们接着到withAction中看一下:

这里的逻辑也是比较绕,首先最外层SQLExecution.withNewExecutionId还是一个高阶函数,其封装整个action操作。具体的封装细节不是此次重点,感兴趣的可以再看。这里关键操作只有两行代码,第一行是重置SparkPlan物理计划的度量信息,其次是从物理计划获取结果,注意这里的action对象其实是上一步我们传递进来的collectFromPlan方法。这里我们先看下比较重要的qe.executedPlan这个方法,它返回了物理计划SparkPlan。具体我们到源码中看一下:
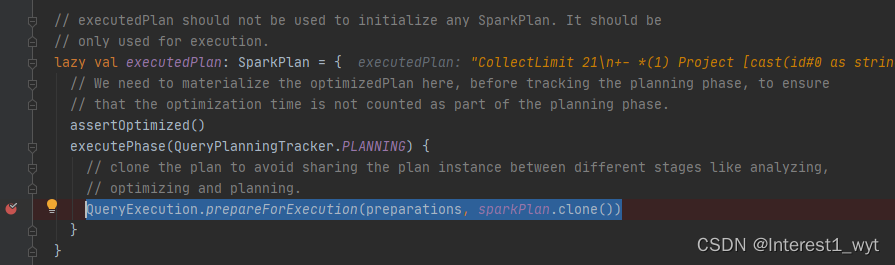
首先第一行是判断是否执行逻辑计划的优化,如果没执行则执行。其次是执行物理计划的准备,不过在这一步还有一个容易忽略的点。就是sparkPlan.clone方法。它是获取物理计划的第一步。我们进入源码看一下:
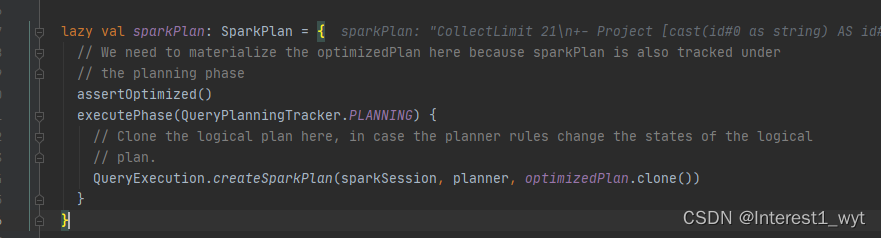
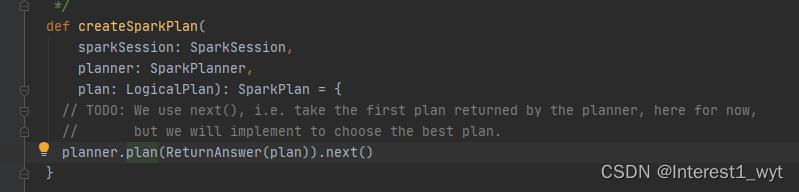 createSparkPlan是物理计划的第一步,其将逻辑计划LogicPlan转换为SparkPlan。我们到plan方法中接着看下其具体的转换流程:
createSparkPlan是物理计划的第一步,其将逻辑计划LogicPlan转换为SparkPlan。我们到plan方法中接着看下其具体的转换流程:
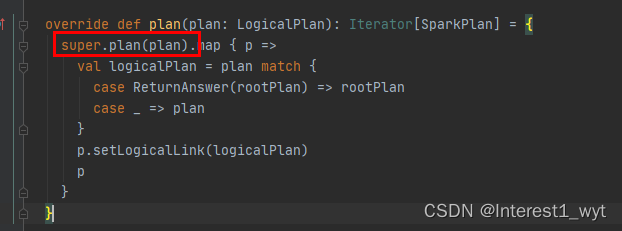
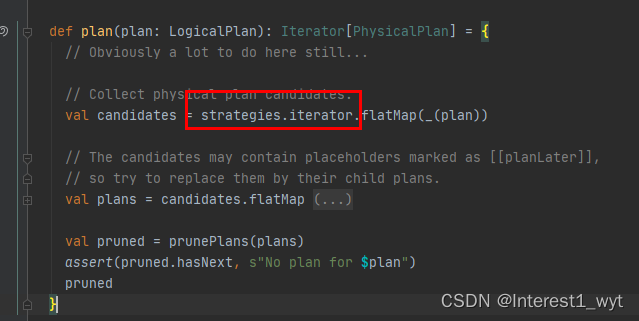
可以看到是将各种strategy应用到逻辑计划上,进而生成PhysicalPlan,随后通过map函数对PhysicalPlan进行简单的处理进而转换成SparkPlan。再回到createSparkPlan中可以看到,即使有多个物理计划返回,默认也只返回第一个物理计划进行使用(当前spark版本3.0.1)。至此我们获得了一个可用的SparkPlan物理计划。接着回到executedPlan属性方法中:
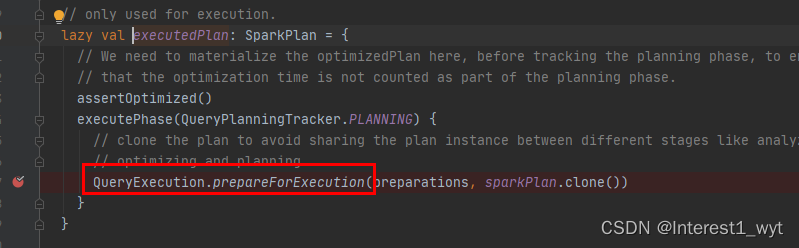
这里的QueryExecution.prepareForExecution,主要是将各种规则作用于物理计划上,使得所有逻辑计划树转换为物理算子树。我们接着回到withAction方法中。
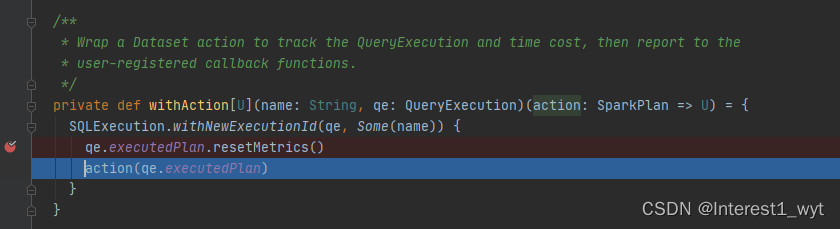
当我们获得了SparkPlan物理计划并重置物理计划的度量信息后,接着执行action操作,这里的action其实就是一开传进来的collectFromPlan方法,所以接着到该方法中查看一下:
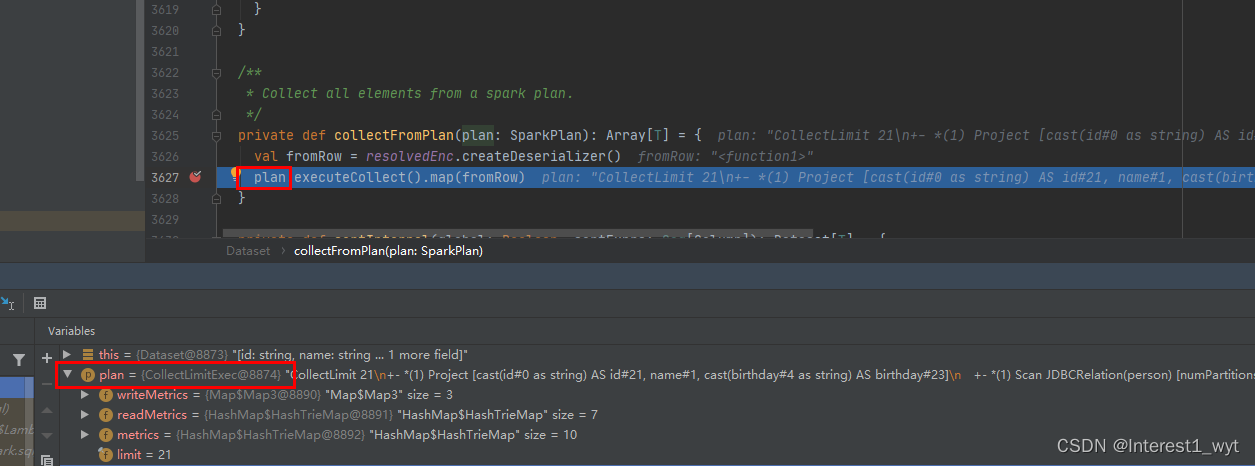
在该方法中可以看到会调用物理计划的executeCollect方法。而这里的物理计划通过断点可以看到是一个CollectLimitExec算子对象,所以我们接着到该对象的方法中看一下:
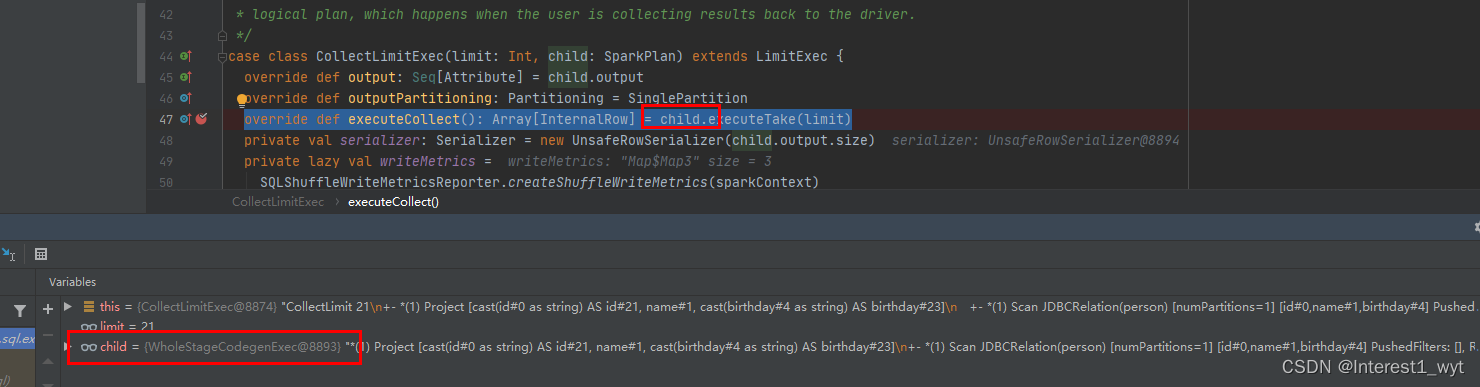
可以看到这里其实是调用WholeStageCodegenExec中的方法,而该对象其实是用于生成代码的。随后将代码发送到各个节点执行。后续是不是感觉不知道去哪追踪?去除代码生成和任务下发,其实后续剩下的内容不多,主要就是去哪拿数据。这里我们可以一层层展开WholeStageCodegenExec算子,看看其底层的RDD数据到底来自于哪:
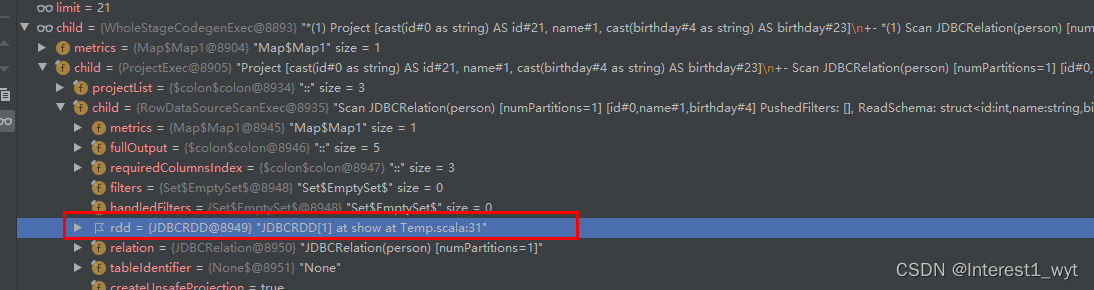
可以看到最底层RDD数据是JDBCRDD,而RDD最核心的就是其compute方法,所以我们直接看下JDBCRDD的compute方法:
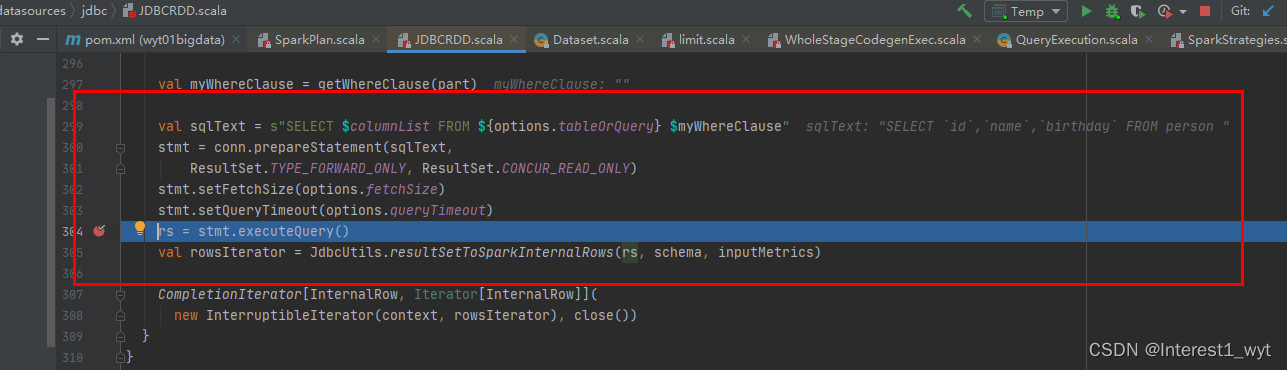
可以看到其最终还是通过将语法树转换成sql语句,然后通过jdbc连接发送请求并获得数据。至此是不是感觉豁然开朗,原来sparksql底层也是用jdbc查询的。为了防止大家被误导,这里要介绍下,本文之所以最后是jdbc查询,是跟我查询mysql数据库有关的,如果你查的是文件或其它非数据库的源,最后的物理算子肯定不是通过jdbc去查。但是整个spark sql计划转换流程和物理计划执行过程都是一样的。后期想扩展或者排查问题也可以参考该流程。
至此,我们物理计划获取数据的整个流程就完全清晰了。后续还会有些其它文章进一步探讨spark sql中问题定位以及功能扩展的用法。
4、总结:
1)因为spark sql计划的转换执行,很多都是懒加载,所以有的时候加的断点会不生效。这个时候可以吧其它断点都放开,只在目标位置放一个断点。然后重启程序即可。
2)spark sql物理计划转换的内容真的太多,本文主要注重将整个流程穿起来,所以很多细节讲解的不够到位。感兴趣或者有需要的可以自己再看。
3)物理计划内部包含Physical、SparkPlan、PreparedSparkPlan三个小阶段。
4)spark 3.0.1版本物理计划即使有多个也是默认使用第一个
5)本文之所以最后是jdbc查询,是跟我查询mysql数据库有关的,如果你查的是文件或其它非数据库的源,最后的物理算子肯定不是通过jdbc去查。但是整个spark sql计划转换流程和物理计划执行过程都是一样的。后期想扩展或者排查问题也可以参考该流程。
参考文献:
《spark sql内核剖析》