AI绘画可控性研究与应用清华美院课程的文字稿和PPThttps://mp.weixin.qq.com/s?__biz=MzIxOTczNjQ2OQ==&mid=2247484794&idx=1&sn=3556e5c467512953596237d71326be6e&chksm=97d7f580a0a07c968dedb02d0ca46a384643e38b51b871c7a4f89b38a04fb2056e084167be05&scene=21#wechat_redirectGAN“家族”又添新成员——EditGAN,不但能自己修图,还修得比你我都好 - 知乎作者 | 莓酊,链接: GAN新成员EditGAN 欢迎关注 @机器学习社区 ,专注学术论文、机器学习、人工智能、Python技巧首先想让大家猜一猜,这四张图中你觉得哪张是P过的?小编先留个悬念不公布答案,请继续往下看。 生…
![]() https://zhuanlan.zhihu.com/p/435400695StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery 阅读笔记 - 知乎论文:StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery code: https://github.com/orpatashnik/StyleCLIP 效果: 由于StyleGAN、StyleGAN2在生成图像上的优秀表现,越来越多的paper基于styleGAN来对图像…
https://zhuanlan.zhihu.com/p/435400695StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery 阅读笔记 - 知乎论文:StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery code: https://github.com/orpatashnik/StyleCLIP 效果: 由于StyleGAN、StyleGAN2在生成图像上的优秀表现,越来越多的paper基于styleGAN来对图像…![]() https://zhuanlan.zhihu.com/p/368134937https://ai.plainenglish.io/draggan-an-interactive-point-based-manipulation-technique-for-deep-generative-models-343c9be6cf6e
https://zhuanlan.zhihu.com/p/368134937https://ai.plainenglish.io/draggan-an-interactive-point-based-manipulation-technique-for-deep-generative-models-343c9be6cf6e![]() https://ai.plainenglish.io/draggan-an-interactive-point-based-manipulation-technique-for-deep-generative-models-343c9be6cf6eAI 图像编辑技术 DragGAN 问世,该技术有哪些亮点功能值得关注? - 知乎出品人:Towhee 技术团队 作者:张晨DragGAN介绍合成满足用户需求的视觉内容往往需要对生成对象的姿势、…
https://ai.plainenglish.io/draggan-an-interactive-point-based-manipulation-technique-for-deep-generative-models-343c9be6cf6eAI 图像编辑技术 DragGAN 问世,该技术有哪些亮点功能值得关注? - 知乎出品人:Towhee 技术团队 作者:张晨DragGAN介绍合成满足用户需求的视觉内容往往需要对生成对象的姿势、…![]() https://www.zhihu.com/question/602358712/answer/3045167594
https://www.zhihu.com/question/602358712/answer/3045167594
DragGAN主要还是应用于图像编辑领域,在图像编辑领域之前有代表性的可控生成的作品包括editgan和styleclip,前者是通过分割图去定点控制生成图,后者是通过文本来实现控制,DragGAN将控制的方式变成了人工交互,通过点移动的方式,draggan的理论框架:点在图像空间中的移动对应于GAN的潜在空间中的移动,利用这一观察结果,制定了一个优化问题,旨在最小化用户输入和生成的图像之间的差异,该优化问题通过一种基于梯度的方法解决,该方法调整GAN的latent code以匹配用户的输入。DragGAN包括三个步骤,初始化:将用户输入映射到GAN的潜在空间中,跟踪涉及跟踪用户输入点在图像上的移动,优化涉及调整GAN的latent code已匹配用户输入。
1.abstract
生成对象的姿态、形状、表情和布局通常需要灵活和精确的可控性,现有的方法通过手动注释的训练数据或3D模型获得GAN的可控性,本文控制GAN的方式,即以用户交互的方式控制图像中的点,以精确达到目标点(sam中提供了点,框,mask和text),为了实现这一点,draggan由两个部分组成,1.基于特征的运动监督,驱动控制点向目标位置移动,2.一种新的点跟踪方法。
2.introduction
理想的可控图像合成应具备以下特点:1.灵活性,能够控制生成物体的不同空间属性,包括位置,姿态,形状,表情和布局;2.精度,它应该能高精度的控制空间属性;3.普遍性:能用于不同的对象类别,但不局限于某个特定类别。
文本引导合成,在空间属性编辑上,文本引导缺乏精度和灵活性,无法将对象移动特定数量的像素,本文允许用户在图像上点击任意数量的处理点和目标点,目标是驱动处理点达到相应的目标点,这种基于点的操作允许用户控制歌各种空间属性,并且与对象类别无关。
GAN的高保真,EditGAN不是对条件分布进行建模,而是通过寿险建模图像和分割图的联合分布,然后计算与编辑分割图相对应的新图像来实现定性编辑。UserControllabeLT。扩散模型在文本输入下可以实现丰富的图像,然后文本无法对图像进行细致的控制,因此受到高级语义编辑的限制。

DragGAN解决了两个问题,1.监督处理点向目标点移动,2.跟踪点移动。我们的技术建立在一个关键的观察上,即GAN的特征空间足够有区别性,可以实现运动监督和精确点跟踪,具体而言,通过一种shifted feature patch loss优化latent code,每次优化都会使处理点跟接近目标,在特征空间中执行最近邻搜索来进行点跟踪,这个过程不断重复,直到handle点到达目标点,还允许用户选择特定的区域进行编辑,不依赖任何额外的网络,在大多数情况下,在单个RTX 3090上一张图只需要几秒,其实也挺慢的。与传统的应用于图像上的变形warm操作不同,draggan的变形操作是作用在latent code上的,再通过latent code反演(生成器)到图像上。
在视频中跟踪点的方法是通过连续帧之间的光流估计来实现。RAFT通过迭代计算估计光流,PIPs考虑了做个帧之间的信息,更好的处理长距离跟踪。本文在GAN生成的图像上进行点跟踪时,不需要任何神经网络,GAN的特征空间具有足够的区分度,可以通过特征匹配来简单的实现跟踪。
3.方法
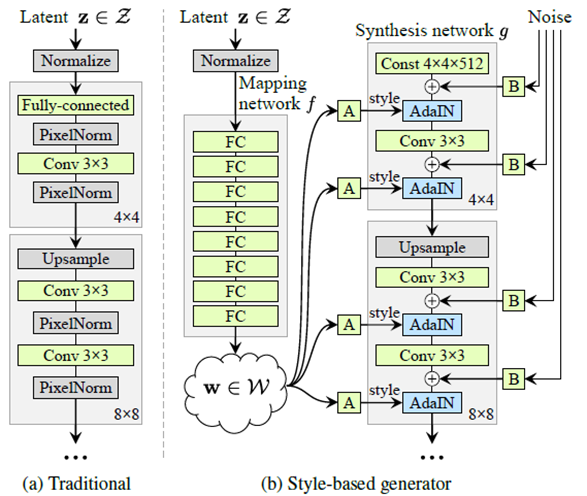
stylegan,一个512维latent code通过mapping network被映射到一个中间潜在编码w,再将w送到生成器的不同层中来控制不同的属性。stylegan是后续几乎所有的可控图像编辑的pipeline,因为在产生的潜空间w被送入到不同生成器的层中认为可以改变生成图像的对应属性,stylegan的两个最主要的贡献,1.产生了latent space w,2.将w放入到生成器中每层结构中,真实数据不是高斯,输入是高斯,很难匹配起来,w是隐变量空间,可以是任意的空间,更好的匹配真实数据。
3.1 interactive point-based manipulation
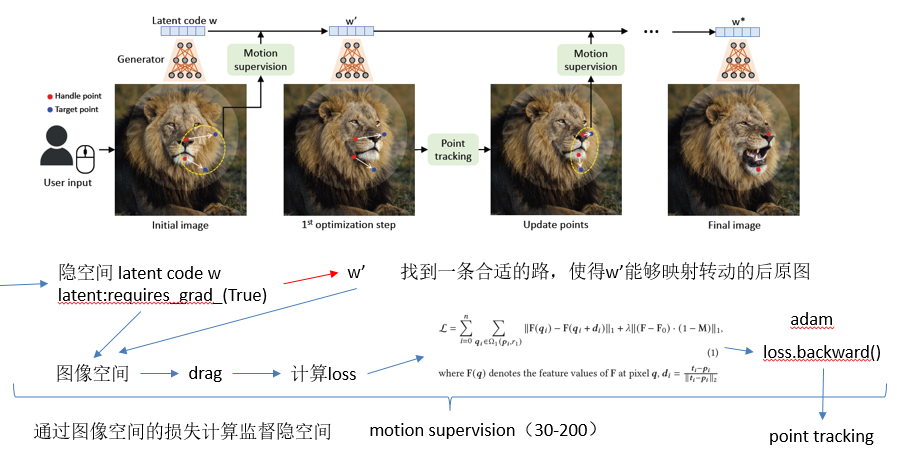
红色是处理点,蓝色是目标点,运动监督,使用handle点向目标点移动的损失来优化latent code w,经过一次优化,得到一个新的latent code w‘和一个新的图像I‘,更新会导致图像中物体轻微移动,从复现代码看,是进行一次梯度优化就进行一次点追踪,运动监督仅将每个控制点向其目标移动一小步,但确切步长不知道,取决于复杂的优化过程,或者理解成使用梯度优化从w中找到一个合适的路到w',而w’即是图像上满足要求的图,找到了分布中和图对应的映射关系,损失之所以在图像层面是因为好算,在图像层面通过F,即生成器就可以拿到对应点的特征值,对应点特征值相减来控制点的不变形,前提就是点的不变性在隐空间中有对应关系,而stylegan的隐空间其实学到了很好的和原图对应的映射关系。更新控制点的位置以跟踪物体上的相应点,如果没有准确跟踪,在下一步运动监督中就会产生错误的监督,点追踪其实和运动监督不同的是,运动监督更新点后只计算loss,用隐形latent生成更好的图像,不更新点,且实际计算loss时,也不是只取一个点,而是以该点为中心,r=3,在点追踪中,取r=12,并且进行点更新,优化通常需要30-200次迭代。
3.2 motion supervision
不依赖任何额外网络,关键思想是生成器的中间特征非常具有区分性,选择latent的前6组,并且在计算loss时,通过双线性差值恢复到原图,损失函数:
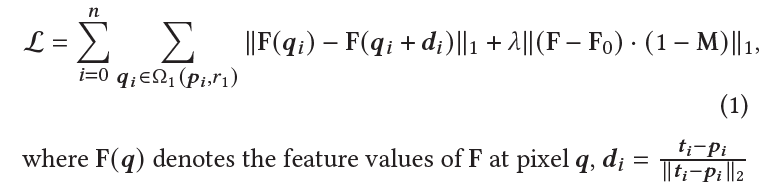
损失函数很简单,qi表示移动前原图所在点,qi+di表示移动后原图上点,F即是生成器函数,F(qi)是在qi点处产生的特征值,在前向时只会给latent一个梯度回传,后半部分是考虑mask之外的不要动,但实际并不一定,也会因为GAN产生新东西。
3.3 point tracking
使点变得更精准。
3.4 Implementation Details
生成能力来源于stylegan2,但是stylegan2是在特定场景数据中进行训练和生成的,FFHQ(人脸,1024x1024)、AFQCat(猫,512x512)、SHHQ(自然风景、城市风景、人类图像)、LSUN Car(汽车,256x256)、LSUN Cat、Landscapes HQ(风景图,山、沙漠和海洋)、microscope(显微镜下图)、Lion、Dog、Elephant。
代码:
wrapped_model=ModelWrapper()->
sample_z=torch.randn([1,512])->
latent,noise=wrapped_model.g_ema.prepare([sample_z])->
sample,F=wrapped_model.g_ema.generate(latent,noise)->
on_drag->
model:wrappped_model,
points:target:[887,484],handle:[721,493],
state:latent:1x18x512,noise:17,F:,sample:1x3x1024x1024
size:2014,
mask:
max_iters:20->
drag_gan->
r1,r2,lam,d=3,12,20,1->
F0=F.detach().clone()->1x128x1024x1024
latent_trainable=latent[:,:6,:].detach().clone().requires_grad_(True)->1x6x512
latent_untrainable=latent[:,6:,:].detach().clone().requires_grad_(False)->1x12x512
optimizer=torch.optim.Adam([latent_trainable],lr=2e-3)->
for iter in range(max_iter)->
optimizer.zero_grad()->
latent=torch.cat([latent_trainable,latent_untrainable],dim=1)->1x18x512
sample2,F2=g_ema.generate(latent,noise)->sample2:1x3x1024x1024,F2:1x128x1024x1024
pi,ti=handle_points[i],target_points[i]->[721,493],[887,484]
di=(ti-pi)/torch.sum((ti-pi)**2)->[0.0060,=0.0003]
for qi in neighbor(int(pi[0]),int(pi[0]),r1)->[718,490]
f1=bilinear_interpolate_torch(F2,qi[0],qi[1]).detach()->
f2=bilinear_interpolate_torch(F2,qi[0]+di[0],qi[1]+di[1])->
loss+=FF.l1_loss(f2,f1)->
loss+=((F2-F0)*(1-mask)).abs().mean()*lam->
loss.backward()->
optimizer.step()->
sample2,F2=gma.generate(latent,noise)->
pi=handle_points0[i]->
f0=bilinear_interpolate_torch(F0,pi[0],pi[1])->
f2=bilinear_interpolate_torch(F2,qi[0],qi[1])->
v=torch.norm(f2-f0,p=1)->
handle_points[i][0]=minx->
handle_points[i][1]=miny->从代码上看,latent在梯度优化中是始终保持反向传播的,通过优化latent,在生成图上每次前进一个di,来实现运动监督。
stylegan2预训练数据集: