Python词性分析:一步步了解自然语言处理技术
Python是一种高级编程语言,拥有广泛的应用领域。自然语言处理技术是其中一个重要的领域,它包含了词性分析、命名实体识别、句法分析等多项任务。词性分析是自然语言处理中的基本任务之一,它有助于从文本中抽取有意义的信息,进行文本分类、情感分析、机器翻译等其他处理。在本文中,我们将详细介绍Python词性分析的方法,并提供一个示例以展示其具体应用。
什么是词性分析?
词性分析(Part of Speech Tagging)是自然语言处理中的一种基本技术,它用于确定单词在上下文中的语法类型。在词性分析中,每个单词都会被打上一个特定的标记,用于表示它所属的词性类别。这些标记可以表示名词、动词、形容词、副词等等,它们有助于识别文本中的语言结构,为文本处理提供更为准确的信息。
例如,在句子“我今天打了一场精彩的篮球比赛”中,每个词都可以被打上一个特定的标记表示它的词性类别。如下所示:
我/代词 今天/副词 打了/动词 一/数词 场/量词 精彩/形容词 的/助词 篮球/名词 比赛/名词
通过词性分析,我们可以知道这是一句描述打篮球比赛的句子,其中动词“打”表示了主语“我”的行为,形容词“精彩”的描述赛事的结果。
Python中的词性分析
Python是一种功能强大的编程语言,拥有许多自然语言处理库,其中最受欢迎的是nltk。nltk是一个开源的Python库,它提供了许多自然语言处理工具,包括文本分析、词性标注和句法分析。在本文中,我们将使用nltk包进行Python中的词性分析。
在完成词性分析前,我们需要先安装nltk库,并下载所需的词性标记器。可以使用以下命令完成:
!pip install nltk
import nltk
nltk.download('averaged_perceptron_tagger')
然后,我们可以使用以下代码进行Python中的词性分析:
import nltk
text = "I am learning nltk for natural language processing"
tokens = nltk.word_tokenize(text)
tags = nltk.pos_tag(tokens)
print(tags)
在上述代码中,我们首先定义text变量作为要分析的文本,然后使用word_tokenize函数将其转换为单词列表。接下来,我们使用pos_tag函数对每个单词进行词性标记,最后输出所有的标记结果。
执行上述代码后,输出结果将是一个包含每个单词和对应词性标记的元组列表,如下所示:
[('I', 'PRP'), ('am', 'VBP'), ('learning', 'VBG'), ('nltk', 'NN'), ('for', 'IN'), ('natural', 'JJ'), ('language', 'NN'), ('processing', 'NN')]
元组的第一项是单词本身,第二项是所属词性标记。
Python词性分析的应用
词性分析可以在很多场景中得到应用,例如文本分类、命名实体识别、情感分析等。在本文中,我们将以情感分析为例来展示Python词性分析的应用。
情感分析是一种文本分类任务,它用于判断一段文本的情感色彩,例如积极、消极或中性等。为了进行情感分析,我们需要先确定词汇的情感极性,即它们是否是正面的、负面的或中性的单词。然后,可以将这些单词的情感极性汇总,来确定整个文本的情感色彩。
在使用Python进行情感分析时,我们需要先准备一个情感词汇表。情感词汇表是一个包含许多单词及其情感极性的列表,通常包括正面词汇、负面词汇和一些中性词汇。在本文中,我们将使用一个简单的情感词汇表来演示该过程。
首先,我们需要定义一些规则来决定一个句子的情感色彩。在本文中,我们将使用以下规则:
- 如果句子中有正面情感词汇且没有负面情感词汇,则句子为正面;
- 如果句子中有负面情感词汇且没有正面情感词汇,则句子为负面;
- 如果句子中没有正面或负面情感词汇,则句子为中性。
然后,我们可以使用以下代码实现情感分析:
import nltk
# 定义情感词汇表
positive_words = ['happy', 'good', 'great']
negative_words = ['sad', 'bad', 'terrible']
neutral_words = ['the', 'is', 'at']
# 定义情感分析函数
def sentiment(text):
tokens = nltk.word_tokenize(text)
tags = nltk.pos_tag(tokens)
pos = 0
neg = 0
for word, tag in tags:
if word.lower() in positive_words:
pos += 1
elif word.lower() in negative_words:
neg += 1
if pos > neg:
return 'positive'
elif pos < neg:
return 'negative'
else:
return 'neutral'
# 测试情感分析函数
text1 = 'I am very happy today'
text2 = 'I feel sad about the loss'
text3 = 'This is a book'
print(sentiment(text1)) # 输出 positive
print(sentiment(text2)) # 输出 negative
print(sentiment(text3)) # 输出 neutral
在上述代码中,我们首先定义了一个简单的情感词汇表,包括几个正面、负面和中性词汇。然后,我们定义了一个情感分析函数sentiment,它接收一段文本,使用词性分析来确定该文本中正面和负面情感单词的数量,并根据规则确定文本的情感色彩。最后,我们测试了该函数,将几个不同的文本作为输入,并输出它们的情感色彩。
结论
Python是一种功能强大的编程语言,拥有广泛的应用领域,其中自然语言处理技术也是其中重要的领域之一。词性分析是自然语言处理中的基本任务之一,它用于确定单词在上下文中的语法类型。在Python中,我们可以使用nltk库进行词性分析,并将其应用于文本分类、情感分析、命名实体识别等任务。本文详细介绍了Python词性分析的方法,并提供了一个简单的示例来演示它的具体应用。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲
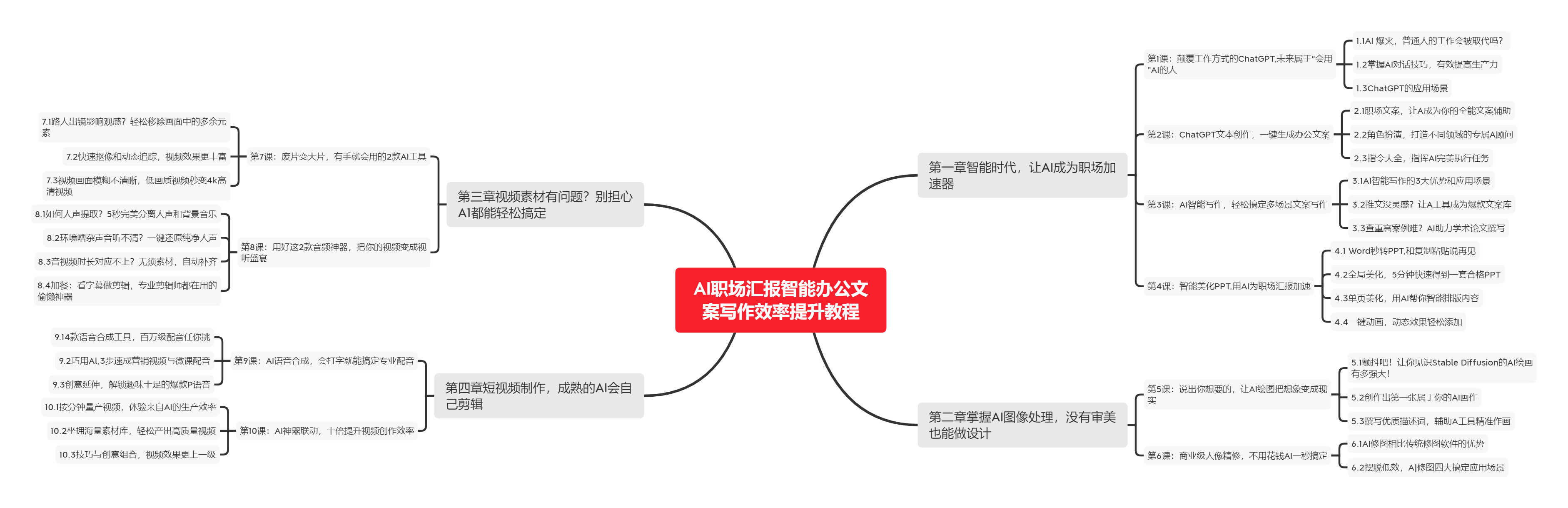

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |