除了图片之外,电子文件中使用的字体都必须要在本机中安装才能正常查看文字(word缺少字体的话会自动使用相似或默认字体),要想知道电子文件中使用的字体,可以将电子文件转换为PDF文件(如果是打印成PDF的话,不能按图片方式打印),然后调用组件获取PDF文件中使用的字体。通过学习参考文献1-2,本文学习并记录调用FreeSpire.PDF获取PDF文件的字体并检查本地缺少的字体。
Free Spire.PDF是Spire.PDF的免费版本,后者是专业的基于.NET平台的PDF文档控制组件。它能够让开发人员在不使用Adobe Acrobat和其他外部控件的情况下,运用.NET 应用程序创建,阅读,编写和操纵PDF 文档(来自百度百科)。Free Spire.PDF可以免费下载和使用,但是使用有限制,只能处理10页及以下的PDF文档。

FreeSpire.PDF的功能很多,但是获取PDF文档使用的字体的话,主要使用的是PdfDocument类,通过该类打开指定PDF文档,然后其UsedFonts属性返回文档使用的字体信息(原文:Retruns the fonts which are used in the PDF document.)。代码很简单,主要参考自参考文献1:,代码及程序运行效果如下所示:
txtResult.Text = string.Empty;
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(fileName);
PdfUsedFont[] usedfont = doc.UsedFonts;
foreach (PdfUsedFont font in usedfont)
{
string fontInfo = string.Format("{0}, {1}, {2},{3}", font.Name, font.Size, font.Style,font.Type);
//打印每个字体的字体名称、大小及类型
txtResult.Text+=fontInfo+ "\r\n";
}
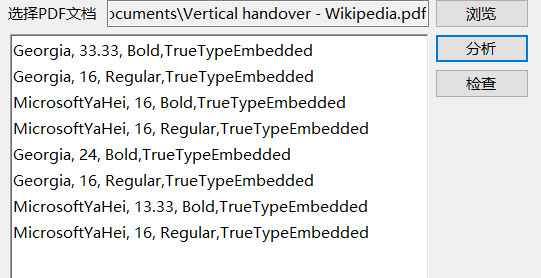
接着是检查本地安装的字体,这个主要是通过InstalledFontCollection类获取,然后检查PDF文件中的字体名称是否在本地安装的字体集合中即可。
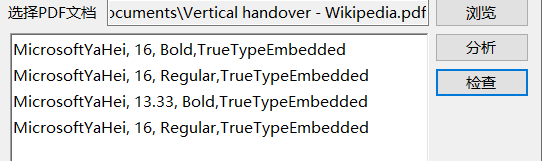
这里的问题是通过FreeSpire.PDF获取的PDF文件中的字体名字与本地的名字不完全一样。如上图所示FreeSpire.PDF获取的字体名称角MicrosoftYaHei,但是本地安装的字体名字是中间可能有空格,自动查找不一定能查得出来。
除了FreeSpire.PDF,还有其它开源的PDF操作组件,后续还会测试使用其它PDF组件获取PDF文档使用字体的方式。
参考文献:
[1]https://blog.51cto.com/u_15926533/5987791
[2]https://blog.csdn.net/sD7O95O/article/details/125591811
[3]https://www.e-iceblue.com/Introduce/free-pdf-component.html