jieba.NET支持通过两种算法提取文本关键词:TF-IDF算法和TextRank算法,关于这两种算法的介绍详见参考文献10-11,在jieba.NET中对应的类为TfidfExtractor和TextRankExtractor,这两个分词都都支持调用ExtractTags和ExtractTagsWithWeight函数,前者默认返回前20个关键词,后者还附带每个关键词的权重。
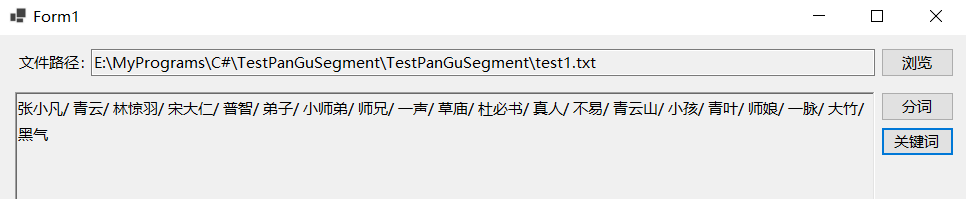
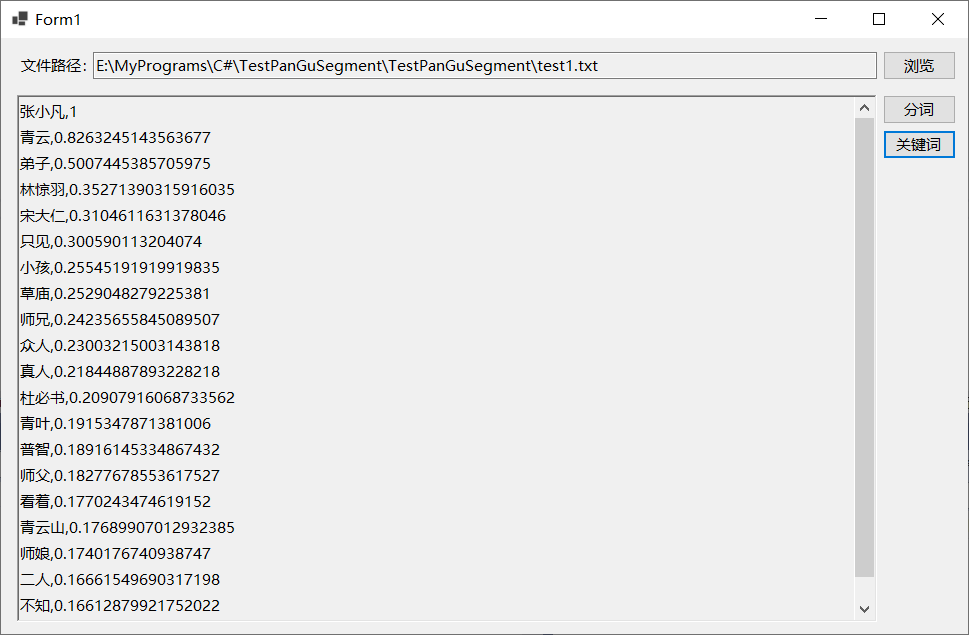
j以小说《诛仙》的前7章内容为例测试这两个类的效果,首先是TfidfExtractor,示例代码及运行效果如下所示:
//不带权重
txtResult.Text = String.Empty;
using (TextReader tr = File.OpenText(txtPath.Text))
{
TfidfExtractor extractor = new TfidfExtractor();
var keywords=extractor.ExtractTags(tr.ReadToEnd());
txtResult.Text = string.Join("/ ", keywords);
}
//带权重
txtResult.Text = String.Empty;
using (TextReader tr = File.OpenText(txtPath.Text))
{
TfidfExtractor extractor = new TfidfExtractor();
IEnumerable<WordWeightPair> results = extractor.ExtractTagsWithWeight(tr.ReadToEnd());
foreach (WordWeightPair p in results)
{
txtResult.Text += p.Word + "," + p.Weight.ToString()+ "\r\n";
}
}
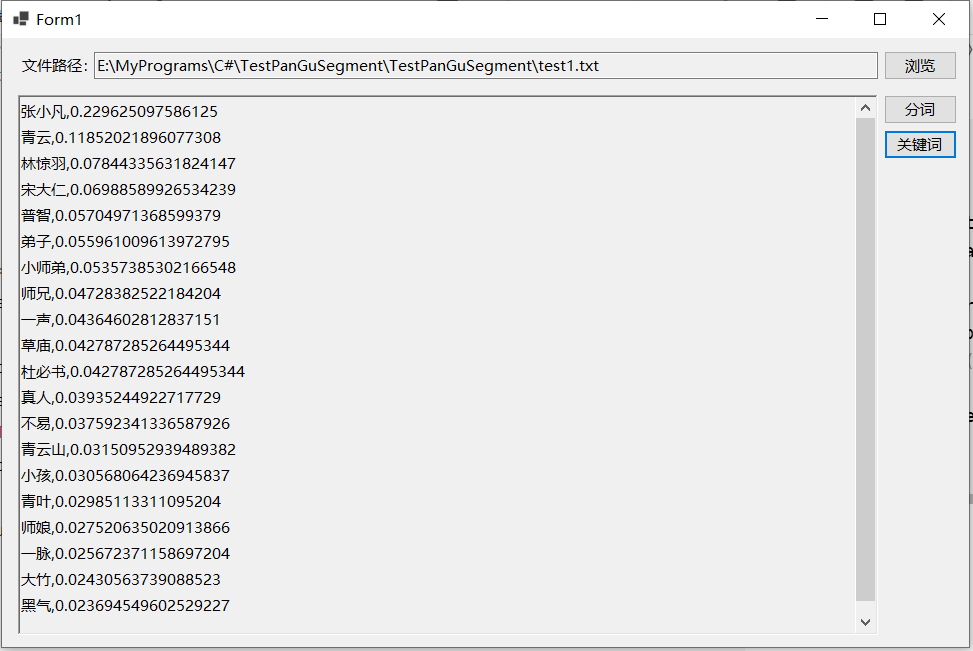
TextRankExtractor类的示例代码及运行效果如下所示,对比可以看出这两种算法的返回结果还是存在差异:
//不带权重
txtResult.Text = String.Empty;
using (TextReader tr = File.OpenText(txtPath.Text))
{
TextRankExtractorextractor = new TextRankExtractor();
var keywords=extractor.ExtractTags(tr.ReadToEnd());
txtResult.Text = string.Join("/ ", keywords);
}
//带权重
txtResult.Text = String.Empty;
using (TextReader tr = File.OpenText(txtPath.Text))
{
TextRankExtractorextractor = new TextRankExtractor();
IEnumerable<WordWeightPair> results = extractor.ExtractTagsWithWeight(tr.ReadToEnd());
foreach (WordWeightPair p in results)
{
txtResult.Text += p.Word + "," + p.Weight.ToString()+ "\r\n";
}
}

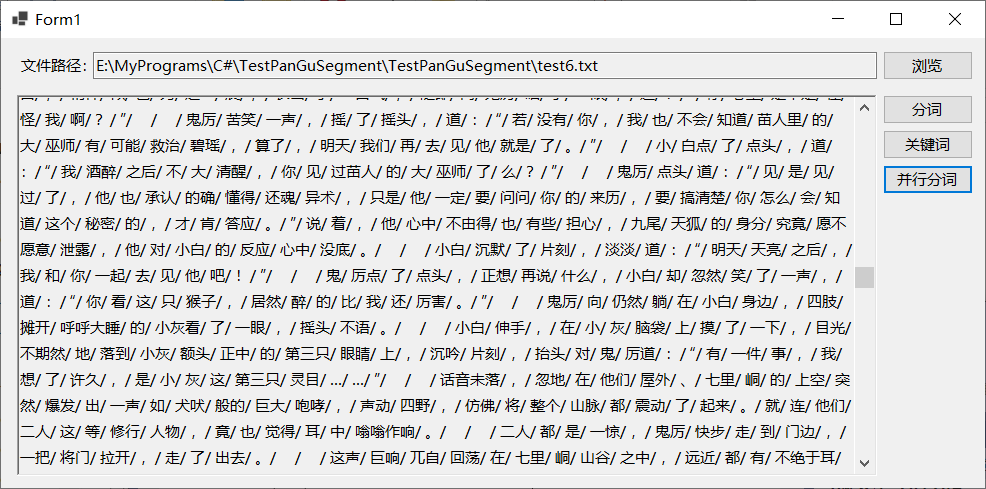
JiebaSegmenter类的CutInParallel和CutForSearchInParallel函数支持并行分词,对Cut函数相比,Cut函数的输入是单个字符串,而CutInParallel函数的输入既可以是字符串集合,也可以是单个字符串(jieba.NET会自动按行将单个字符串转换为字符串集合后再调用CutInParallel)。程序代码基本没有变化,只是将函数由Cut变成了CutInParallel。测试效果如下图所示,由于测试的文件只有几M,使用Cut函数反而比CutInParallel更快,估计是CutInParallel将单个字符串按行转换为字符串集合后再分词影响了速度。还有一定记得把文本文件转换为UTF-8或者Unicode格式,ANSI格式的文本文件分词时会卡死,不知道是什么原因。
参考文献:
[1]https://github.com/linezero/jieba.NET
[2]https://www.jianshu.com/p/6f47b670fcb0
[3]https://github.com/anderscui/jieba.NET
[4]https://github.com/JimLiu/Lucene.Net.Analysis.PanGu
[5]https://github.com/apache/lucenenet
[6]https://blog.csdn.net/lijingguang/article/details/127262360
[7]https://blog.51cto.com/u_15834522/5766716
[8]https://www.cnblogs.com/dacc123/p/8431369.html
[9]https://blog.csdn.net/wangkun9999/article/details/1574114
[10]https://baijiahao.baidu.com/s?id=1744467856047121907&wfr=spider&for=pc
[11]https://blog.csdn.net/qq_57832544/article/details/127806572