0. 引言
core核心是solr中的重中之重,类似数据库中的表,在搜索引擎中也叫做索引,在solr中索引的建立,要先创建基础的数据结构,即schema的相关配置,今天继续来学习solr的核心知识:
solr快速上手:solr简介及安装(一)
solr快速上手:核心概念及solr-admin界面介绍(二)
1. schema标签
schema实际上就是solr核心的数据结构,即字段的定义集。
在solr安装目录下,有这样一个文件夹server/solr/configsets/_default/conf,里面附带了要创建索引的默认的基础配置文件。我们可以通过复制这个文件夹下的配置文件,来帮助我们快速创建索引
这些文件中有两个核心的配置文件需要我们掌握:
- menaged-schema: 字段配置文件
- solrconfig.xml:solr核心配置文件
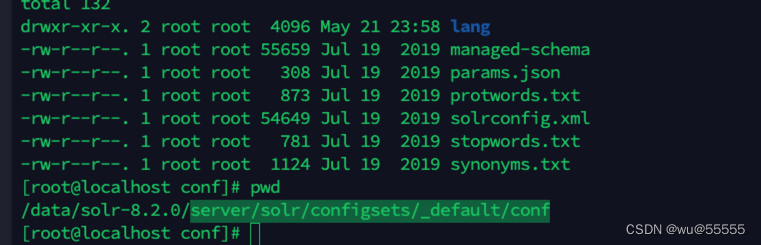
但在我们真正开始创建之前,还是要先学习其中schema的常用标签
首先我们需要知道,我们字段结构的定义都是在managed-schema文件中的,当然有时我们能看到又使用的是schema.xml文件,这是因为solr提供了两种定义模式,默认使用managed-schema,如果需要使用schema.xml,则需要在solrconfig.xml中配置如下标签
<schemaFactory class="ClassicIndexSchemaFactory"/>
通过上述文件夹中复制下来的managed-schema已经有各类标签的使用案例了,只不过都是注释的,我们来详细看看几个常用的标签:
<schema name="example" version="1.5">
<field name="id" type="int" indexed="true" stored="true" multiValued="false" required="true"/>
...
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
...
<uniqueKey>id</uniqueKey>
<copyField source="sourceFieldName" dest="destinationFieldName"/>
<fieldtype name="textSimple" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.solr.JcsegTokenizerFactory" mode="detect"/>
</analyzer>
</fieldtype>
<fieldType name="string" class="solr.StrField" sortMissingLast="true"/>
...
</schema>
1.1 field 字段标签
filed标签用于配置字段信息,该标签中包含如下属性:
- name: 字段名称,值要求唯一
- type: 字段数据类型
支持哪些常用的数据类型
string 字符串
int, long 整数
float, double 浮点数
date 日期时间
bool 布尔类型
text 文本类型
binary 二进制类型
- indexed: 当前字段是否创建索引,默认值为true
这里的索引指的是什么?
因为solr使用倒排索引,所以创建索引的含义,就是将字段值包含在倒排索引中,也就是用该值分词创建倒排索引,从而支持基于该字段的搜索和过滤。
创建索引的好处和坏处?
好处是提高了查询小了,坏处当然是增加了存储空间占用,而且当字段值本身很大时,创建索引也会带来一定的性能损耗。因此在指定索引字段时,也要综合考虑。
- stored: 当前字段是否存储,默认为true
是否存储,指的是存储到哪里?
配置该字段的值是否存储到solr本身的存储库中,如果存储,那么当查询后的显示就不需要再查询数据源了,对于只需要排序、索引的字段,则可以设置为false来节约空间
比如设置indexed=true, stored=false, 则表示该字段值用于创建索引,但不做存储吗?
是的,该字段值不做存储,但是值会被分词用于创建倒排索引,如此当查询的结果需要再显示该字段时,就需要再次查询数据源来显示,而查询数据源本身是相对较慢的操作
这里的数据源到底指的是什么?
solr的数据源可能是数据库、文件、接口等,比如配置了solr数据是从mysql通过dataimport同步过来了,那么数据源就是mysql,查询数据源就表示通过sql再查一遍mysql,所以速度自然就慢
stored=true的好处和坏处?
好处是提高读取性能,直接存储在solr了,无需再从数据源获取,提高查询效率;坏处当然是占用磁盘空间,对于海量的数据时,如果不需要显示,仅仅只是做索引则不用存储,存储也意味着更高的磁盘、网络IO
- docValues: 是否启用点列存储当前字段值,默认为false, 当需要字段做排序或者聚合查询时需要设置为true
什么是点列存储?
点列存储(也叫列存储)是倒排索引之外的一种存储结构,我们更加熟悉的是数据库的行存储,但实际上像oracle,sqlserver都已经在支持列存储,列存储是指的是按照列来进行分组存储
比如我们有如下的几行数据
| name | age | sex | address | school |
|---|---|---|---|---|
| 张三 | 28 | 男 | 广州市xxx路 | 南京大学 |
| 李四 | 18 | 男 | 北京市xxx路 | 湖南大学 |
| 丽丽 | 19 | 女 | 福州市xxx路 | 江南大学 |
这几个数据按行存储的话,在磁盘中的存储方式如下所示
同一行的数据是放在一起的
而列存储的话,就是同一列的数据放在一起
这样存储的好处在于当我们需要对年龄进行分组的时候,我们就不需要把全部数据查询一遍,而只需要找到对应列的位置,然后将这一连续空间的数据查询出来,进行聚合操作即可
这样的存储方式,极大的方便了针对数值型字段聚合、重复度高的字段分组、需要排序的字段的查询操作
并且联想一下,针对数值列,重复度高的列,我们还可以进行压缩操作,更加节约存储空间


上述图形中,姓名、地址、学校这些字段也按列存储了,是不是造成浪费了?
其实有这个问题,你大概率是陷入了误区,上述是为了给大家展示按列存储的物理结构,实际的操作时,我们是按需定义的,不要忘记这个属性是在field标签下的,也就是说他是针对某一列设置是否按列存储,所以如果不需要的字段,你不设置即可
- multiValues: 字段值是否可重复,或者说是否为多个值,默认为false。一般用于数组字段
比如如下的数据中,技能字段skills就是一个数组类型,就需要用multiValues=true标识
{
"name": "张三",
"age": 28,
"sex": "男",
"address": "广州市xxx路",
"school": "南京大学",
"skills": [
"Java",
"Python",
"C++",
"数据结构与算法"
]
}
默认字段
基于以上的属性我们就可以自定义字段了,但同时solr也提供了一些默认的字段,也称为域
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="_version_" type="plong" indexed="false" stored="false"/>
<field name="_root_" type="string" indexed="true" stored="false" docValues="false" />
<field name="_nest_path_" type="_nest_path_" /><fieldType name="_nest_path_" class="solr.NestPathField" />
<field name="_text_" type="text_general" indexed="true" stored="false" multiValued="true"/>
如上所示,其中包括:
id: 文档的唯一标识符,可以指定为数据源中的唯一索引字段_version_: 版本号,用于并发控制,每次更新文档,版本值都会自动递增_root_: 用于嵌套文档结构,表示潜逃文档所属的最外层文档_nest_path_: 用于嵌套文档结构,表示嵌套文档在文档中的路径,可以根据该路径来查询嵌套文档_text_: 文档的主要内容,用于全文检索
假设有如下文档值:
{
"id": "001",
"title": "Solr 学习笔记",
"content": "这是一篇关于 Solr 的学习笔记,包含了 Solr 的介绍、安装、配置和使用等内容。"
}
则对应的这几个字段的值是:
{
"id": "001", // 文档唯一标识符
"_version_": 1, // 并发控制版本号
"_root_": "001", // 嵌套文档根节点(此处与id相同)
"_nest_path_": "", // 嵌套文档路径(顶级文档为空字符串)
"_text_": [ // 全文检索内容
"这是一篇关于 Solr 的学习笔记,包含了 Solr 的介绍、安装、配置和使用等内容。",
"Solr 学习笔记"
]
}
比如有点赞信息时,就会引入嵌套文档
{
"id": "002",
"title": "Solr 文档结构示例",
"content": "这是一篇 Solr 文档嵌套结构的示例。",
"_root_": "002", // 根节点为自己
"_nest_path_": "", // 初始情况下为空字符串
"_text_": [
"这是一篇 Solr 文档嵌套结构的示例。",
"Solr 文档结构示例"
],
"like": [ // 嵌套文档:点赞
{
"id": "u001",
"user_name": "Tom",
"_root_": "002", // 父文档ID
"_nest_path_": "/like", // 嵌套路径为 /like
"_text_": ["Tom"]
},
{
"id": "u002",
"user_name": "Jack",
"_root_": "002", // 父文档ID
"_nest_path_": "/like", // 嵌套路径为 /like
"_text_": ["Jack"]
}
]
}
1.2 dynamicField 动态字段标签
动态字段是用来做什么的?
当我们出现部分字段名都是类似的,且表示相同的含义时,比如:name_1, name_2, name_3 ,如果有成百上千个这样的字段需要定义,还是很麻烦的,可能你觉得不会有这样的场景,但是在搜索引擎的业务场景下,存在大批量字段是比较常见的事情。
这个时候,我们就希望能有一个类似通配符匹配配置的模式,来帮助我们批量定义字段,于是就出现了动态字段,比如上述的name_1, name_2, name_3 我们就可以定义为:
<dynamicField name="name_*" type="pint" indexed="true" stored="true"/>
动态字段只能有前缀和后缀两种匹配模式,用*来表示
同时需要注意,在solr中,只有在managed-schema文件中配置过的字段,才能在查询时使用,这与数据库的逻辑是一致的,没有定义过的字段,直接使用就会报错"字段未找到"
1.3 uniqueKey 唯一主键标签
solr中默认使用id作为唯一主键,更新和新增时就通过唯一主键是否存在来决定
1.4 copyField 复制字段标签
复制字段的意思就是将一个或多个字段的值填充到另一个字段中,主要用来:
- 将多个字段填充到一个字段方便搜索;
如果目标字段中已经有自己的数据,那么会把复制字段的内容作为附加值添加到目标字段的内容中,从而实现更加全面的搜索覆盖
<copyField source="name" dest="search_total"/>
<copyField source="content" dest="search_total"/>
<copyField source="title" dest="search_total"/>
- 对同一个字段定义不同的分词器,用于不同的搜索场景
比如将某字段值,定义英文分词器,中文分词器,西巴牙语分词器,以应对不同语种的搜索场景
<copyField source="name" dest="name_english"/>
<copyField source="name" dest="name_chinese"/>
1.5 fieldType 字段类型标签
filedType标签主要用于定义字段的分词器、过滤器,实现为不同字段定义不同的分词、过滤器
相当于是定义一个字段类型,然后在类型中指定使用的类,然后在field标签中就可以直接使用这个自定义的类型
如下示例,就定义了一个类型my_text,定义了两个分析器,一个用于索引(index),一个用于查询(query),都是用StandardTokenizerFactory作为默认的分词器,StopFilterFactory作为过滤器,分别用于去除标点和停用词。不同的是查询时额外使用了SynonymGraphFilterFactory从synonyms.txt获取同义词
PS:
1、solr有哪些分词器和过滤器,我们将在后续讲解,或者大家也可自行拓展搜索,中文中还有常用的中文分词器——IK分词器
2、不清楚同义词、过滤器、停用词作用的,因为是搜索引擎的基础概念,大家可自行搜索,如果仍不清楚,可留言提问
<fieldType name="my_text" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
filedType标签中常用的属性如下:
- name: 定义类型名称
- class: 定义类型使用的class类,比如text类型的用的就是solr自带的TextField类
- positionIncrementGap 属性指定了位置增量间隔,用于多值字段在索引中处理位置信息,默认是0,也就是每个分词之间存储的间隔
默认为0的话,比如这样的文档:
<doc>
<filed name="id">1</field>
<filed name="content">wu quick study</field>
<filed name="content">solr study</field>
</doc>
如果针对content字段设置的fieldType指定了默认positionIncrementGap=0,那么content的位置编号就是:
| 位置编号 | 文本 |
|---|---|
| 1 | wu quick study |
| 2 | solr study |
如果设置的positionIncrementGap=10,则位置编号为,及文本不是连续存储的
| 位置编号 | 文本 |
|---|---|
| 1 | wu quick study |
| 11 | solr study |
设置positionIncrementGap的好处和坏处?
设置后可以控制多值字段不同值之间的位置增量,这样solr可以更加准确的计算匹配文档和查询相关度,从而计算结果排名,简言之就是查询的结果排名计算更加准确。当然他的坏处就是占用的空间变大,使得索引变大,那么查询性能就受到影响了
其次,fieldType也支持filed中的以下标签:
indexed:是否可以被索引,默认为 true。
stored:是否可以被存储,默认为 true。
multiValued:是否为多值字段,默认为 false。
docValues:是否启用 DocValues,默认为 false。
termVectors:是否启用 TermVectors,默认为 false。
2. 总结
今天,我们针对schema标签的详解就到此结束了,是不是感觉标签属性很多,记不过来,其实没关系,实际使用部分标签是用不到的,我们还可以根据模版参考配置,无需专门背诵,根据实际场景,多写几遍,自然就记住了



![[极客大挑战 2019]PHP1](https://img-blog.csdnimg.cn/img_convert/ab42769906d3495fb599cd71c10f2fa4.png)


![[论文分享] jTrans: Jump-Aware Transformer for Binary Code Similarity](https://img-blog.csdnimg.cn/f72e9f084be64fc2b7141c6be203e0a5.png)