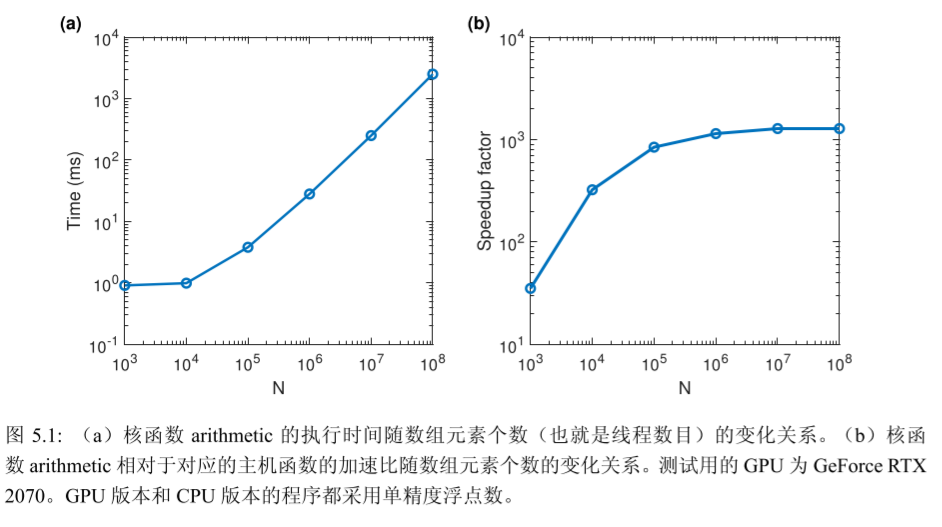
前言
参考资料:
高升博客
《CUDA C编程权威指南》
以及 CUDA官方文档
CUDA编程:基础与实践 樊哲勇
文章、讲解视频同步更新公众《AI知识物语》,B站:出门吃三碗饭
1:编写头文件erro.cuh
编写一个头文件(error.cuh),它包含一个检测CUDA运行 时错误的宏函数(macro function),内容如下:
(1) #pragma once 是一个预处理指令,其作用是确保当前文件在一个 编译单元中不被重复包含。
(2)该宏函数的名称是 CHECK,参数 call 是一个CUDA运行时 API 函数。
(3)定义宏时,如果一行写不下,需要在行末写 \,表示续行。
(4)第 7 行定义了一个 cudaError_t 类型的变量 error_code,并初始化为函数 call 的 返回值。
(5)第 8 行判断该变量的值是否为 cudaSuccess。如果不是,在第 9-16 行报告相关文件、 行数、错误代号及错误的文字描述并退出程序。第14行的cudaGetErrorString()显然也是一个CUDA运行时 API 函数,作用是将错误代号转化为错误的文字描述。
#pragma once
#include <stdio.h>
#define CHECK(call) \
do \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)
2:编写测试程序
#include<stdint.h>
#include<cuda.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <math.h>
#define CHECK(call) \
do \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)
const double EPSILON = 1.0e-15;
const double a = 1.23;
const double b = 2.34;
const double c = 3.57;
void __global__ add(const double* x, const double* y, double* z, const int N);
void check(const double* z, const int N);
int main(void)
{
const int N = 100000000;
const int M = sizeof(double) * N;
double* h_x = (double*)malloc(M);
double* h_y = (double*)malloc(M);
double* h_z = (double*)malloc(M);
for (int n = 0; n < N; ++n)
{
h_x[n] = a;
h_y[n] = b;
}
double* d_x, * d_y, * d_z;
CHECK(cudaMalloc((void**)&d_x, M));
CHECK(cudaMalloc((void**)&d_y, M));
CHECK(cudaMalloc((void**)&d_z, M));
CHECK(cudaMemcpy(d_x, h_x, M, cudaMemcpyDeviceToHost));//Set Error
CHECK(cudaMemcpy(d_y, h_y, M, cudaMemcpyDeviceToHost));
const int block_size = 128;
const int grid_size = (N + block_size - 1) / block_size;
add << <grid_size, block_size >> > (d_x, d_y, d_z, N);
CHECK(cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost));
check(h_z, N);
free(h_x);
free(h_y);
free(h_z);
CHECK(cudaFree(d_x));
CHECK(cudaFree(d_y));
CHECK(cudaFree(d_z));
return 0;
}
void __global__ add(const double* x, const double* y, double* z, const int N)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
if (n < N)
{
z[n] = x[n] + y[n];
}
}
void check(const double* z, const int N)
{
bool has_error = false;
for (int n = 0; n < N; ++n)
{
if (fabs(z[n] - c) > EPSILON)
{
has_error = true;
}
}
printf("%s\n", has_error ? "Has errors" : "No errors");
}

可见,宏函数正确地捕捉到了运行时刻的错误,告诉我们文件 checkerror.cu 的第 50 行代 码中出现了非法的参数。非法参数指的是 cudaMemcpy 函数的参数有问题,因为我们故意 将 cudaMemcpyHostToDevice 写成了 cudaMemcpyDeviceToHost。可见,用了检查错误的宏 函数之后,我们可以得到更有用的错误信息,而不仅仅是一个错误的运行结果。从这里开 始,我们将坚持用这个宏函数包装大部分的 CUDA 运行时 API 函数。有一个例外是 cudaEventQuery 函数,因为它很有可能返回 cudaErrorNotReady,但又不代表程序出错了。
3:检测核函数
上述方法不能捕捉调用核函数的相关错误,因为核函数不返回任何值(回顾一下,核 函必须用 void 修饰)。有一个方法可以捕捉调用核函数可能发生的错误,即在调用核函数之后加上如下两个语句:
CHECK(cudaGetLastError());
CHECK(cudaDeviceSynchronize());
第一个语句的作用是捕捉第二个语句之前的最后一个错误,第二个语句的作用是同 步主机与设备。之所以要同步主机与设备,是因为核函数的调用是异步的,即主机发出调用核函数的命令后会立即执行后面的语句,不会等待核函数执行完毕。
编写程序来测试核函数error
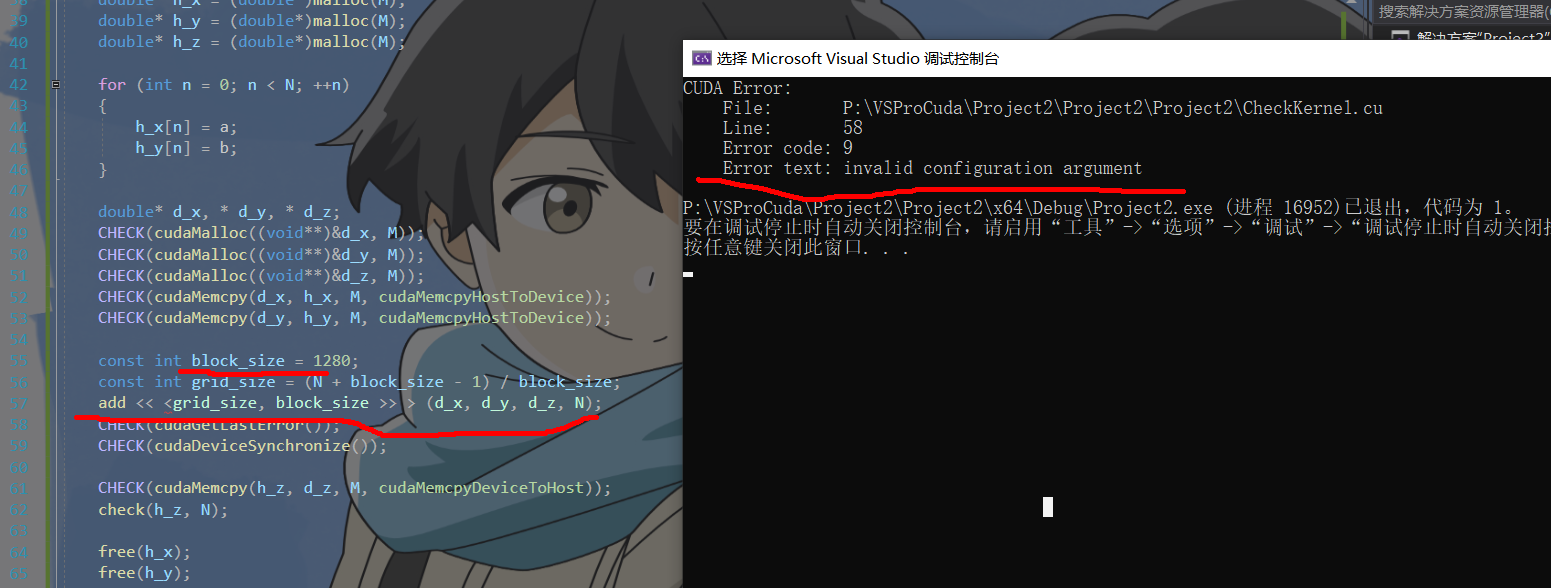
线程块大小的最大值 是 1024(这对从开普勒到图灵的所有架构都成立)。假如我们不小心将核函数执行配置中 的线程块大小写成了 1280,该核函数将不能被成功地调用。第 57 行的代码成功地捕获了该错误,告诉我们程序中核函数的执行配置参数有误:
#include <math.h>
#include <stdio.h>
#include<stdint.h>
#include<cuda.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#define CHECK(call) \
do \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)
const double EPSILON = 1.0e-15;
const double a = 1.23;
const double b = 2.34;
const double c = 3.57;
void __global__ add(const double* x, const double* y, double* z, const int N);
void check(const double* z, const int N);
int main(void)
{
const int N = 100000000;
const int M = sizeof(double) * N;
double* h_x = (double*)malloc(M);
double* h_y = (double*)malloc(M);
double* h_z = (double*)malloc(M);
for (int n = 0; n < N; ++n)
{
h_x[n] = a;
h_y[n] = b;
}
double* d_x, * d_y, * d_z;
CHECK(cudaMalloc((void**)&d_x, M));
CHECK(cudaMalloc((void**)&d_y, M));
CHECK(cudaMalloc((void**)&d_z, M));
CHECK(cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice));
const int block_size = 1280;
const int grid_size = (N + block_size - 1) / block_size;
add << <grid_size, block_size >> > (d_x, d_y, d_z, N);
CHECK(cudaGetLastError());
CHECK(cudaDeviceSynchronize());
CHECK(cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost));
check(h_z, N);
free(h_x);
free(h_y);
free(h_z);
CHECK(cudaFree(d_x));
CHECK(cudaFree(d_y));
CHECK(cudaFree(d_z));
return 0;
}
void __global__ add(const double* x, const double* y, double* z, const int N)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
if (n < N)
{
z[n] = x[n] + y[n];
}
}
void check(const double* z, const int N)
{
bool has_error = false;
for (int n = 0; n < N; ++n)
{
if (fabs(z[n] - c) > EPSILON)
{
has_error = true;
}
}
printf("%s\n", has_error ? "Has errors" : "No errors");
}