双列集合
- 一次需要添加一对数据,分别为键和值
- 键不可以重复,值可以重复
- 键和值是一一对应的,每一个键只可以找到自己对应的值
- 键值对在java中也叫做Entry对象
Map中常见的API
Map是双列集合的顶层接口,它的功能是全部双列集合都可以继承使用的。
| 方法 | 作用 |
|---|---|
| V put(K key,V value) | 添加元素 |
| V remove(Object key) | 根据键删除对应的键值对,并且返回被删除的值 |
| void clear() | 移除所有键值对元素 |
| boolean containKey(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,集合中键值对的个数 |
在放入键值对时,如果键重复则覆盖值并且返回被覆盖的值,如果键不存在,则直接放入,返回null
Map遍历方法
- lambda表达式增强for、迭代器、foreach都可遍历:
Set<String> strings = maps.keySet();
strings.forEach(str -> System.out.println(maps.get(str)));
- 通过键值对遍历
Set<Map.Entry<String, String>> entries = maps.entrySet();
entries.forEach(entry -> System.out.println(entry.getKey() + "=" + entry.getValue()));
- lambda表达式
maps.forEach((key, value) -> System.out.println(key + "=" + value));
HashMap
- Map的一个实现类
- 没有额外的方法
- 无需不重复无索引
- 和HashSet底层原理一模一样,都是哈希表结构
- 依赖hashcode和equals方法保证键的唯一
- 所以如果键存储自定义对象需要重写上面的两个方法
LinkedHashMap
- 有序无索引不重复
- 底层数据结构依然是哈希表,只是每个键值对元素又额外的多了一个双链表的机制记录存储的顺序
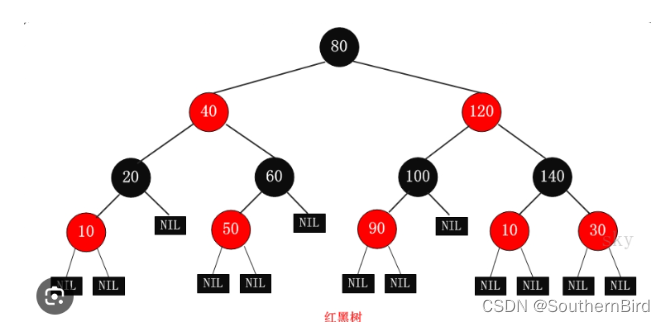
TreeMap
- 和TreeSet底层原理一样,都是红黑树结构
- 由键决定特定:不重复无索引、可排序
- 对键进行排序
- 默认排序规则为按照键从小到大排序
- 实现Comparable接口指定比较规则(在对应的自定义方法中重写此接口)
- 创建集合时传递Comparator比较器对象指定比较规则
TreeMap<Integer, String> treeMap = new TreeMap<>((o1, o2) -> o2 - o1);
如果要对结果的键进行排序请使用TreeMap否则的话可以使用效率更高的HashMap
可变参数
public static void main(String[] args) throws IOException {
System.out.println(getsum(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
}
public static int getsum(int... args) {
int sum = 0;
for (int i = 0; i < args.length; i++) {
sum += args[i];
}
return sum;
}
Collections
一个工具类
| 方法 | 作用 |
|---|---|
| public static <T>boolean addAll(Collection<T> c,T… elements) | 批量添加元素 |
| public static void shuffle(List<?>list) | 打乱List集合元素的顺序 |
| ps<T>v sort(List<T>list) | 排序 |
| ps<T>v sort(List<T>list,Comparator<T>c) | 根据制定规则进行排序 |

不可变集合
不想让被人修改集合中的内容
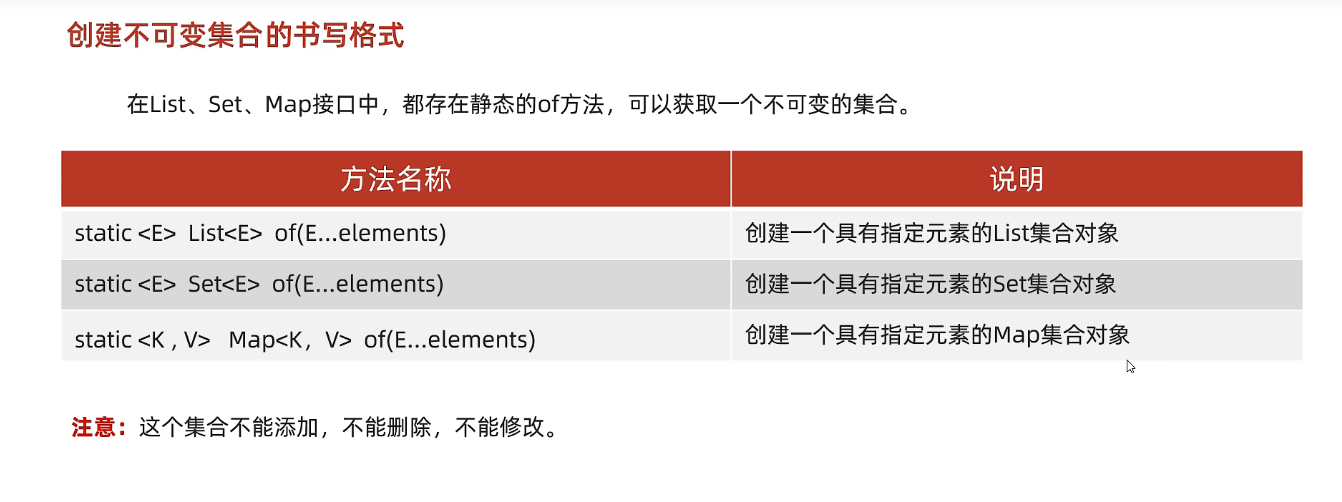
一次获取的不可变集合不可修改添加删除,只可以查询