文章目录
- 前言
- 一、目的
- 二、代码详解
- 1、Node类模板
- 2、Pylist类构造
- 3、内嵌迭代器
- 4、Python风格insert方法
- 5、Python风格append方法
- 6、Python风格[]下标操作方法
- 7、Python风格+、+= 方法
- 8、Python风格pop方法
- 9、Python风格remove方法
- 10、length、get方法
- 三、使用示例
- 总结
- 原创文章,未经许可、严禁转载
前言
前文:线性顺序表(链表) 已经完成了单向链表基本的插入、取值、删除等操作,本文将在前文的基础上更进一步完善其功能。参照Python的 List 列表的函数常用功能来实现。如+运算直接将两个列表合并,[] 运算赋值、取值。如:
a = [1, 2], b = [4, 5]
a[2] = 3
a += b
c = a + b
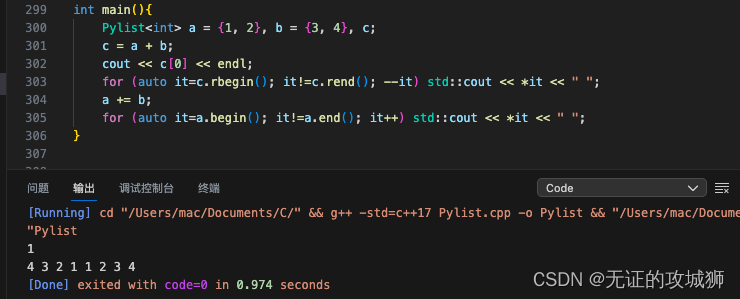
笔者是很喜欢python中列表这种骚操作的,本文就在C++中实现它。当然基本的C++语法规则笔者是没法改变的。赋值得用{},类型还是要声明的,泛型自然是可以的,但你也别想着在一个列表中同时塞入 string 和 int 。最终实现效果部分如下图:
一、目的
用 C++ 实现一个类似于 Python 中的 List 列表的链表,实现Python 中 list 的常用的几个功能,可以进一步加深对链表的理解。
- 使用双向链表实现,用以加快首尾访问速度。
- 用
initializer_list实现类似C++ STL中各种容器的初始化方法,了解不定数量参数的初始化、赋值方法。 - 实现正反向迭代器,了解迭代器运算符重载。
- 实现类Python的 [] 运算取值、赋值,了解class中的运算符重载,特别是=、+、+= 以及构造函数、复制构造函数、析构函数的实现方法、运用等知识。
- 熟悉 Iterator 内嵌类的一般应用。
二、代码详解
1、Node类模板
#include <iostream>
using namespace std;
template <typename T> class Node{
public:
T data;
Node<T>* next;
Node<T>* pre;
};
以上代码定义了一个名为 Node 的模板类,该类表示一个双向链表。下面部分 Pylist 类包含三个构造函数和一个析构函数。
2、Pylist类构造
template <typename T> class Pylist{
private:
Node<T>* head;
Node<T>* tail;
int len;
public:
Pylist(){ //tail和head必须先定义
tail = new Node<T>;
head = new Node<T>;
tail->next = NULL;
tail->pre = head;
head->next = tail;
head->pre = NULL;
len = 0;
}
Pylist(initializer_list<T> vlist){ //不定数量节点构造
tail = new Node<T>;
head = new Node<T>;
head->next = tail;
head->pre = NULL;
tail->next = NULL;
tail->pre = head;
len = 0;
Node<T>* p = head;
for (T v :vlist){
while (p->next != tail){
p = p->next;
}
Node<T>* q = new Node<T>;
q->data = v;
q->next = tail;
tail->pre = q;
q->pre = p;
p->next = q;
len++;
}
}
Pylist(Pylist& other){ //复制构造函数,重载运算+需要,默认重载是二进制拷贝
tail = new Node<T>;
head = new Node<T>;
head->next = tail;
head->pre = NULL;
tail->next = NULL;
tail->pre = head;
len = 0;
for (auto v : other){
append(v);
}
}
~Pylist(){
Node<T>* p = head;
while (p != tail){
Node<T>* q = p->next;
delete p;
p = q;
}
}
第一个构造函数是默认构造函数,它不接受任何参数。在默认构造函数中,首先创建两个新的Node对象,分别表示链表的头节点和尾节点。然后将头节点和尾节点连接起来,并将链表的长度初始化为0。
第二个构造函数接受一个initializer_list<T>类型的参数,这是C++ 11提供的一个实现不定数量参数的初始化方法,它可以用于使用初始化列表来创建一个Pylist对象。在这个构造函数中,首先创建头节点和尾节点并将它们连接起来,然后遍历初始化列表中的每个元素,使用append函数(代码在下面)将它们添加到链表中。
第三个构造函数是复制构造函数,它接受一个Pylist对象作为参数。在复制构造函数中,运行方式与前两个基本上是相同的,也使用append函数将它们添加到新创建的链表中。
析构函数用于在销毁Pylist对象时释放内存。在析构函数中,遍历链表中的每个节点,并使用delete运算释放它们占用的内存。
3、内嵌迭代器
class Iterator{
private:
Node<T>* node_;
public:
Iterator(Node<T>* node): node_(node){} //初始化
Iterator& operator++(){
node_ = node_->next;
return *this;
}
Iterator operator++(int){ //后置递增运算,int不会被使用,只是一个标记表示后增
Iterator tmp = *this;
node_ = node_->next;
return tmp;
}
Iterator& operator--(){
node_ = node_->pre;
return *this;
}
Iterator operator--(int){ //后置递减运算
Iterator tmp = *this;
node_ = node_->pre;
return tmp;
}
T& operator*() const{ //解引用迭代器
return node_->data;
}
bool operator==(const Iterator& other) const{ //比较两个迭代器
return node_ == other.node_;
}
bool operator!=(const Iterator& other) const{
return !(*this == other);
}
};
Iterator begin(){
return Iterator(head->next);
}
Iterator begin() const{
return Iterator(head->next);
}
Iterator end(){
return Iterator(tail);
}
Iterator end() const{
return Iterator(tail);
}
Iterator rbegin(){
return Iterator(tail->pre);
}
Iterator rbegin() const{
return Iterator(tail->pre);
}
Iterator rend(){
return Iterator(head);
}
Iterator rend() const{
return Iterator(head);
}
以上迭代器部分,代码中定义了一个名为Iterator的内部类,该类表示Pylist类的迭代器。迭代器可以用于遍历链表中的元素。
Iterator类包含一个私有成员变量node_,表示当前迭代器所指向的节点。它还重载了若干运算符,以便更方便地使用迭代器。
operator++ 和operator--运算符用于将迭代器向前或向后移动一个位置。它分为前置和后置两种形式,在代码中,两种形式的实现是不相同的。
代码中定义了一个后置递增运算符operator++(int),用于将迭代器向前移动一个位置。在该函数中,首先创建一个临时迭代器,用于保存递增之前的迭代器。然后将迭代器向前移动一个位置,并返回临时迭代器。
为了避免返回一个局部变量的引用,在编译时收到警告信息。在C++中,函数返回局部变量的引用是不安全的,因为当函数返回后,局部变量所占用的内存将被释放,此时返回的引用将指向一个无效的内存地址。所以带 int 后置递增运算符的返回类型更改为Iterator而不是Iterator&,将返回一个临时迭代器的副本。
operator*运算符用于解引用迭代器,获取迭代器所指向节点中存储的数据。
operator==和operator!=运算符用于比较两个迭代器是否相等。需要注意的是,此处!=运算是调用了==运算实现的,!(*this == other)中的 other 实际上是一个参数,交给上一个 == 运算的,如此写法可以避免修改多处代码。
此外,还定义了若干个成员函数,用于获取链表的起始和结束位置的迭代器。这些函数分别是:
begin()和end()函数分别返回链表起始位置和结束位置之后的迭代器。
rbegin()和rend()函数分别返回链表末尾位置和起始位置之前的迭代器。这两个前后迭代器分别定义了const版本的重载。
4、Python风格insert方法
bool insert(int i, T data){
if (i < 0 || i > len){
return false;
}
Node<T>* p = head;
for (int j = 0; j < i; j++){
p = p->next;
}
Node<T>* q = new Node<T>;
q->data = data;
q->next = p->next;
p->next->pre = q;
q->pre = p;
p->next = q;
len++;
return true;
}
此处代码中定义了一个名为insert的成员函数,该函数用于在链表中插入一个新的元素。insert函数接受两个参数,第一个参数表示插入位置的索引,第二个参数表示要插入的数据。
在insert函数中,首先检查插入位置的索引是否有效。如果索引无效,则返回false。然后遍历链表,找到插入位置之前的节点。接下来创建一个新的节点,并将其插入到链表中。最后将链表的长度加1,并返回true表示插入成功。
5、Python风格append方法
bool append(T data){
Node<T>* p = head;
while(p->next != tail){
p = p->next;
}
Node<T>* q = new Node<T>;
q->data = data;
q->next = tail;
tail->pre = q;
q->pre = p;
p->next = q;
len++;
return true;
}
以上代码中定义了一个名为append的成员函数,该函数用于在链表末尾添加一个新的元素。append函数接受一个参数,表示要添加的数据。
在append函数中,首先遍历链表,找到链表末尾之前的节点。然后创建一个新的节点,并将其插入到链表末尾。最后将链表的长度加1,并返回true表示添加成功。前面的构造函数等处也多次引用了这个函数用以简化代码。
使用append函数在链表末尾添加新元素,例如:
Pylist a;
a.append(1);
a.append(2);
a.append(3);
在执行完以上代码后,Pylist对象a将包含元素1, 2, 3。
6、Python风格[]下标操作方法
T& operator[](int index){ //运算符[]重载
if (index < 0 || index >= len){
throw std::out_of_range("Index out of range");
}
Node<T>* p = head->next;
for (int i = 0; i < index; i++){
p = p->next;
}
return p->data;
}
const T& operator[](int index) const{
if (index < 0 || index >= len){
throw std::out_of_range("Index out of range");
}
Node<T>* p = head->next;
for (int i = 0; i < index; i++){
p = p->next;
}
return p->data;
}
代码中重载了 [] 运算符,用于访问链表中指定位置的元素。operator[] 函数接受一个整数参数,表示要访问元素的索引。
在operator[]函数中,首先检查索引是否有效。如果索引无效,则抛出一个std::out_of_range异常。然后遍历链表,找到指定位置的节点。最后返回该节点中存储的数据。
operator[]函数声明为非常量成员函数,可以调用它来修改对象中的元素,常量成员函数用来访问常量对象中的元素。
7、Python风格+、+= 方法
Pylist operator+(const Pylist& other){ //运算符+重载,需要赋值=重载
Pylist res = *this;
for (auto v :other){
res.append(v);
}
return res;
}
Pylist& operator+=(const Pylist& other){
for (auto v : other){
append(v);
}
return *this;
}
Pylist& operator=(const Pylist& other){ //必须是const
if (this != &other){
Node<T>* p = head->next; //不能删除头节点
while (p != tail){
Node<T>* q = p->next;
delete p;
p = q;
}
head->next = tail;
tail->pre = head;
len = 0;
for (auto v : other){
append(v);
}
}
return *this;
}
代码中重载了+和+=运算符,用于连接两个Pylist对象。
operator+函数接受一个Pylist对象作为参数,并返回一个新的Pylist对象,该对象包含调用该函数的对象和参数对象中的所有元素。在该函数中,首先创建一个新的Pylist对象,并使用复制构造函数将调用该函数的对象中的所有元素复制到新创建的对象中。然后遍历参数对象中的所有元素,并使用append函数将它们添加到新创建的对象中。
operator+=函数也接受一个Pylist对象作为参数,但它不返回新的对象,而是直接修改调用该函数的对象。在该函数中,遍历参数对象中的所有元素,使用append函数将它们添加到调用该函数的对象中。
operator=用于将一个Pylist对象赋值给另一个Pylist对象。该函数接受一个Pylist对象作为参数,并返回调用该函数的对象的引用。它的删除部分和析构函数几乎一样,只是没有删除头、尾节点。
这样,就可以使用+和+=运算符将两个Pylist对象连接起来,例如:
Pylist a = {1, 2, 3};
Pylist b = {4, 5, 6};
Pylist c = a + b;
a += b;
在执行完以上代码后,Pylist对象c将包含元素1, 2, 3, 4, 5, 6,而对象a也将被修改为包含元素1, 2, 3, 4, 5, 6。
8、Python风格pop方法
T pop(){
Node<T>* p = tail->pre;
Node<T>* tmp = p->pre;
T q;
q = p->data;
tmp->next = tail;
tail->pre = tmp;
delete p;
len--;
return q;
}
T pop(int i){
Node<T>* p = head;
T tmp = (T)NULL;
if (i < 0 || i>= len){
throw std::out_of_range("Index out of range");
}else{
for (int j = 0; j <= i; j++){
p = p->next;
}
tmp = p->data;
Node<T>* q = p->next;
q->pre = p->pre;
p->pre->next = q;
len--;
}
return tmp;
}
代码中定义了两个名为pop的成员函数,它们用于删除链表中的元素。
第一个pop函数不接受任何参数,它用于删除链表末尾的元素,和Python中的 pop 一样。在该函数中,首先找到链表末尾之前的节点,然后将其从链表中删除,并释放它占用的内存。最后将链表的长度减1,并返回被删除元素中存储的数据。
第二个pop函数接受一个整数参数,表示要删除元素的索引,也和Python中的 pop 一样。在该函数中,首先检查索引是否有效。如果索引无效,则抛出一个std::out_of_range异常。否则,遍历链表,找到指定位置的节点。然后将该节点从链表中删除,并释放它占用的内存。最后将链表的长度减1,并返回被删除元素中存储的数据。
可以使用pop函数删除链表中的元素,例如:
Pylist a = {1, 2, 3};
int x = a.pop();
int y = a.pop(0);
在执行完以上代码后,Pylist对象a将只包含一个元素2,变量x的值为3,变量y的值为1。
9、Python风格remove方法
bool remove(int i){
if (i < 0 || i >= len){
return false;
}
Node<T>* p = head;
for (int j = 0; j < i; j++){
p = p->next;
}
Node<T>* q = p->next;
p->next = q->next;
q->next->pre = p;
delete q;
len--;
return true;
}
代码中定义了一个名为remove的成员函数,该函数用于删除链表中指定位置的元素。remove函数接受一个整数参数,表示要删除元素的索引。
在remove函数中,首先检查索引是否有效。如果索引无效,则返回false。然后遍历链表,找到指定位置之前的节点。接下来将指定位置的节点从链表中删除,并释放它占用的内存。最后将链表的长度减1,并返回true表示删除成功。
其实此处在和前面的insert、后面的get函数中以索引查找时可以进行一定的优化,先判断索引更靠近头或尾,然后再决定用正序或倒序查找,在 Pylist 对象元素很多的时候会使查找过程略快。
这样就可以使用remove函数删除链表中指定位置的元素,例如:
Pylist a = {1, 2, 3};
a.remove(1);
在执行完以上代码后,Pylist对象a将包含元素1, 3。
10、length、get方法
size_t length() const{ //返回元素数量,类似size()
return len;
}
T get(int i) const{
if (i < 0 || i >= len) {
throw std::out_of_range("Index out of range");
}
Node<T>* p = head->next;
for (int j = 0; j < i; j++){
p = p->next;
}
T data = p->data;
return data;
}
};
代码中定义了一个名为get的成员函数,代码逻辑很简单,和前面雷同。该函数用于获取链表中指定位置的元素。只有一个整数参数,表示要获取元素的索引。
三、使用示例
int main(){
Pylist<int> L;
int f;
for (int i=0; i<3; ++i) L.append(i+1);
Pylist<int> oth = {4, 5};
L = L + oth;
L += {6, 7};
L[6] = 8;
L.insert(6, 7);
L.append(9);
f = L.pop();
cout << f <<endl;
L += {9, 10};
L.pop(9);
for(auto it=L.begin(); it!=L.end(); it++){
std::cout << *it << endl;
}
for(auto it=L.rbegin(); it!=L.rend(); --it){
std::cout << *it << endl;
}
cout << "len = " << L.length() << endl;
Pylist<char> cl = {'a', 'b', 'c'};
cout << cl[0] << endl;
}
这浓浓的Python风,就不用解释了吧~
总结
代码实现了一个双向链表,具有基本的链表功能,如添加、删除、访问和修改元素等。此外,还重载了若干运算符,以便更方便地使用Pylist类。
从功能实用性的角度来看,Pylist类具有较高的实用性。它提供了丰富的接口,可以满足大多数使用场景的需求。
在代码中对各种异常情况进行了处理,例如检查索引是否有效、避免自赋值等。这些措施有助于提高代码的健壮性。
当然,代码中肯定也存在一些可以改进的地方,如插入删除成员函数的索引查找部分。笔者老说更喜欢Python是有道理的吧~,为了列表用得更舒服、更Python风,笔者尽力搞出这么个降低效率的链表类,实用的效率肯定是远不如STL中list 的,仅希望能给读者一定的启发,用以更深入的了解数据结构。
代码太长,全放在文章中怕是要被CSDN这傻傻的博文质量检测系统给出17分,以下是git和inscode链接:
github 链接
CSDN inscode 链接