笔记整理:刘健宇,东南大学硕士,研究方向为知识图谱规则学习与推理
链接:https://dl.acm.org/doi/abs/10.1145/3534678.3539405
动机
知识图谱(KG) 以头-关系-尾三元组的形式捕获知识,是许多人工智能系统中的重要组成部分。KG上有两个重要的推理任务:(1)单跳知识图谱补全,涉及预测 KG 中的各个链接;(2)多跳推理,其目标是预测哪些KG实体满足给定的逻辑查询。基于嵌入的方法通过首先计算每个实体和关系的嵌入,然后使用它们形成预测来解决这两个任务。然而,现有的可扩展KG嵌入框架仅支持单跳知识图谱补全,无法应用于更具挑战性的多跳推理任务。
基于嵌入对KG进行多跳推理存在两个重大挑战:(1)在算法方面,给定一个庞大的 KG(具有数亿个实体),通过实例进行训练不再可行。(2)在系统方面,目前单跳大规模 KG 嵌入框架是基于图分区的,但多跳推理需要遍历图中的多个关系,这通常会跨越多个分区,因而造成推理上的困难。
本文提出Scalable MultihOp REasoning (SMORE)实现在大规模知识图谱上进行单跳和多跳推理,通过对KG进行实例化查询在线生成正负样例,并提出了一种双向拒绝抽样方法有效地为实例化查询获取高质量的负样例。针对挑战2,设计一个异步调度程序,通过重叠采样、异步嵌入读/写、神经网络前馈和优化器更新来最大化 GPU 计算的吞吐量,加速在大规模KG上进行推理。
贡献
本文的主要贡献有:
(1) 提出了一个名为SMORE的框架,是第一个支持知识图谱单跳和多跳推理的通用框架。
(2) 提出了一种新颖的双向拒绝抽样方法,实现了在线训练数据生成复杂度的平方根降低。
(3) 设计了一种分布式训练、异步更新机制,避免繁重的CPU/GPU内存读/写,用于在每个随机梯度更新中对各个阶段进行流水线处理。
方法
1. 训练数据采样
针对无法对大规模知识图谱所有实例进行训练获取嵌入表示的问题,本文提出动态采样、实例化查询获取训练实例以进行多跳推理的对比学习。
为了生成具有一组正实体和负实体的训练示例,首先从一组查询逻辑结构(见图1)中实例化对给定知识图谱的查询。实例化查询的根代表一个已知的肯定(答案)实体,然后反向定向采样使用深度优先搜索 (DFS)对从根(答案)到叶(锚点实体)的查询逻辑结构。在 DFS 期间,查询结构中的每个节点都与知识图谱上的一个实体相对应,并且边与之前关联的实体的关系相对应。在实例化(节点/边缘接地)查询结构后,获得正样本。

图1 不同的查询逻辑结构以及双向拒绝采样使用的最佳节点切割(阴影节点)
对于负样本的获取,本文使用双向拒绝采样。受双向搜索的启发,首先在查询计算计划中获得Node cut,即切割每个叶节点和根节点之间的所有路径的节点子集。然后执行双向搜索:遍历从叶子(锚点)到Node cut,并缓存在遍历中获得的实体——前向缓存。然后对负实体进行采样,从根遍历到Node cut,并通过检查缓存实体和遍历集的重叠来验证它们是否为真负实体——反向验证。
2. 训练策略
SMORE结合了 CPU 和 GPU 的使用,其中密集矩阵计算部署在 GPU 上,采样操作在 CPU 上。
对于拥有超过数百万个实体的大型 KG,嵌入表示不能存储在 GPU 中,SMORE将嵌入矩阵放在共享 CPU 内存上,同时在每个单独的 GPU 中放置其他参数,例如神经逻辑运算符。分布式训练流程如下:
(1) 从采样器 中收集一小批训练样本 。
(2) 将相关实体嵌入从 CPU 加载到 GPU。
(3) 在本地计算梯度,并执行梯度 θ 。更新本地副本 θ 。
(4) 用 θ 异步更新共享 θ 。
其中 θ 是嵌入矩阵, θ 是其他参数的副本。
本文为了避免繁重的CPU/GPU内存读/写,提出一种异步机制,用于在每个随机梯度更新中对各个阶段进行流水线处理,包含四个元线程:
(1) 多线程采样器:每个工作节点维护一个采样器 ,该采样器可以访问共享的KG。采样器包含一个线程池,可以并行地对查询进行采样,并获取相应的正/负答案。
(2) 稀疏嵌入读/写:对于嵌入矩阵 θ ,创建一个单独的后台线程和一个CUDA流用于嵌入读写。当将某些实体的嵌入加载到GPU时,后台线程首先将其加载到固定的内存区域中,然后CUDA异步流将执行固定内存到GPU内存的复制。该读取操作是非阻塞的,只有在主CUDA流中的CUDA运算符请求时才会同步。写操作类似但方向相反。
(3) 稠密计算:当训练数据准备好并将锚实体的嵌入 获取到GPU后,模型开始前馈。在获取局部梯度 θ 和 θ 之后,会首先异步调用 θ 的更新操作,而不会阻塞,同时AllReduce操作将开始,随后是GPU上 θ 的密集参数更新。
(4) 具有异步读写的稀疏优化器:与 θ 不同,每个随机更新中只涉及 θ 的一小部分行。因此,只跟踪 θ,θ, θ 及其梯度,即与正/负实体和锚实体相关的嵌入。
实验
本文在KG完成和KG上的多跳推理任务上评估 SMORE。实验任务是给定一个不完整的 KG,目标是训练查询嵌入方法以发现复杂逻辑查询的缺失答案。数据集采用FB15k、FB15k-237、NELL。
对于算法效率提升的表现,图2结果表明,双向采样器相比遍历能够实现计算成本的平方根降低,验证了所提出的双向采样器相对于朴素的穷举遍历方法的加速。
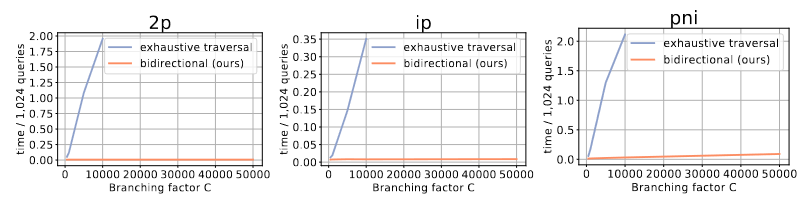
图2 在不同查询结构上执行 KG 遍历与双向采样的效率比较
由于SMORE采用了查询采样方案,可以为一批采样的查询共享负样本,从而显着提高了各种查询嵌入的端到端训练效率。如表1所示,实验表明SMORE平均提高了119.4%的速度,并减少了30.6%的GPU内存使用率。
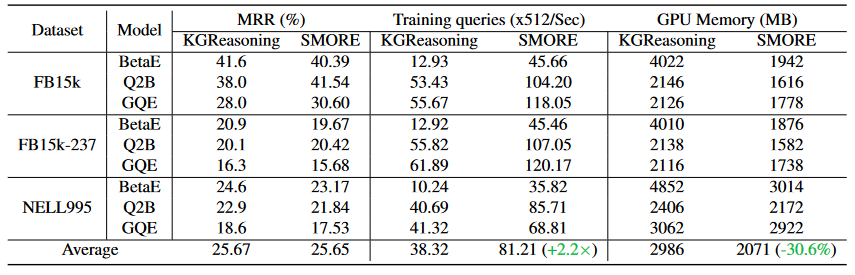
表1 SMORE与KGReasoning在小型 KG 上的性能比较
此外还发现,在多卡GPU上进行训练,训练速度随着GPU的数量几乎呈线性增长,这表明异步训练机制的有效性。
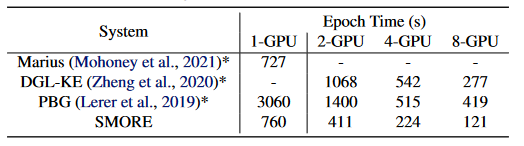
表2 各框架在Freebase KG 上运行时的性能
从表2结果分析可知,SMORE在单跳链接预测(KG补全)运行时性能与最先进的大型 KG 框架(包括 Marius、DGL-KE 和 PBG)相比较,SMORE 在 1-GPU 设置中的运行时间明显快于 PBG,但比 Marius 稍慢。它还比其他系统具有更好的扩展性,在多GPU设置中运行速度显著比DGL-KE 和 PBG更快,表明系统在运行效率上的优越性。
对于推理预测方面的表现,实验结果表明,在FB15k上,SMORE在Q2B模型中将MRR提高了3.54%,证明了系统对提升KG推理的有效性。在面对大型 KG 的查询回答,由于 GPU 内存不足和计算量大的详尽查询采样,基线方法无法扩展到如此庞大的 KG,而由于SMORE 使用具有稀疏嵌入和优化器的异步设计,可以轻松地将查询嵌入扩展到这些大型 KG。
此外实验比较了在不同采样器下训练的Q2B模型的性能,结果表明,采用双向采样器(bidirectional)的性能要优于穷举采样器(exhaustive traversal),而随机采样的性能最差,证明了双向采样策略的有效性。
总结
本文研究知识图谱的补全和多跳推理问题。作者提出了一个名为SMORE的框架,它是第一个支持知识图谱单跳和多跳推理的通用框架。SMORE可实现在大规模知识图谱上进行单跳和多跳推理。SMORE的运行时性能关键在于一种新颖的双向拒绝抽样,它实现了在线训练数据生成复杂度的平方根降低。此外,SMORE利用异步调度、重叠CPU数据采样、GPU嵌入计算等策略降低了推理复杂度,在单GPU和多GPU设置下实现了与最先进框架相当甚至更好的运行时性能。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。