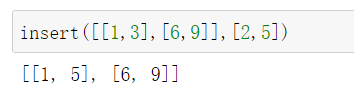
本例我们训练DeepLabV3+语义分割模型来分割车道线。
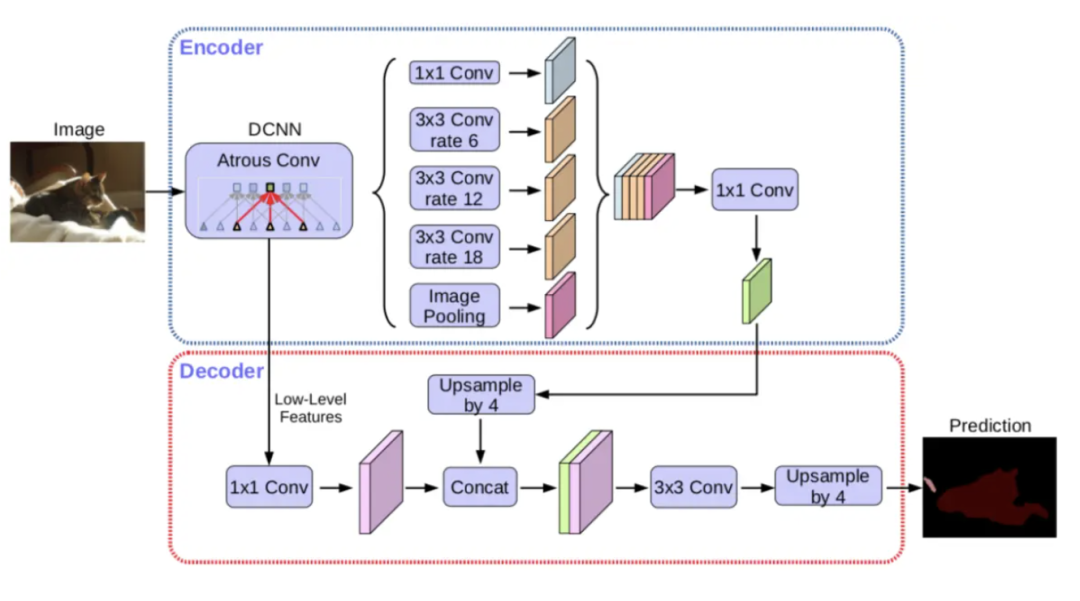
DeepLabV3+模型的原理有以下一些要点:
1,采用Encoder-Decoder架构。
2,Encoder使用类似Xception的结构作为backbone。
3,Encoder还使用ASPP(Atrous Spatial Pyramid Pooling),即空洞卷积空间金字塔池化,来实现不同尺度的特征融合,ASPP由4个不同rate的空洞卷积和一个全局池化组成。
4,Decoder再次使用跨层级的concat操作进行高低层次的特征融合。
#!pip install segmentation_models_pytorch
#!pip install albumentationsimport torchkeras
from argparse import Namespace
config = Namespace(
img_size = 128,
lr = 1e-4,
batch_size = 4,
)一,准备数据
公众号算法美食屋后台回复关键词:torchkeras,获取本文notebook代码和车道线数据集下载链接。
from pathlib import Path
from PIL import Image
import numpy as np
import torch
from torch import nn
from torch.utils.data import Dataset,DataLoader
import os
from torchkeras.data import resize_and_pad_image
from torchkeras.plots import joint_imgs_col
class MyDataset(Dataset):
def __init__(self, img_files, img_size, transforms = None):
self.__dict__.update(locals())
def __len__(self) -> int:
return len(self.img_files)
def get(self, index):
img_path = self.img_files[index]
mask_path = img_path.replace('images','masks').replace('.jpg','.png')
image = Image.open(img_path).convert('RGB')
mask = Image.open(mask_path).convert('L')
return image, mask
def __getitem__(self, index):
image,mask = self.get(index)
image = resize_and_pad_image(image,self.img_size,self.img_size)
mask = resize_and_pad_image(mask,self.img_size,self.img_size)
image_arr = np.array(image, dtype=np.float32)/255.0
mask_arr = np.array(mask,dtype=np.float32)
mask_arr = np.where(mask_arr>100.0,1.0,0.0).astype(np.int64)
sample = {
"image": image_arr,
"mask": mask_arr
}
if self.transforms is not None:
sample = self.transforms(**sample)
sample['mask'] = sample['mask'][None,...]
return sample
def show_sample(self, index):
image, mask = self.get(index)
image_result = joint_imgs_col(image,mask)
return image_resultimport albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
def get_train_transforms():
return A.Compose(
[
A.OneOf([A.HorizontalFlip(p=0.5),A.VerticalFlip(p=0.5)]),
ToTensorV2(p=1),
],
p=1.0
)
def get_val_transforms():
return A.Compose(
[
ToTensorV2(p=1),
],
p=1.0
)train_transforms=get_train_transforms()
val_transforms=get_val_transforms()
ds_train = MyDataset(train_imgs,img_size=config.img_size,transforms=train_transforms)
ds_val = MyDataset(val_imgs,img_size=config.img_size,transforms=val_transforms)
dl_train = DataLoader(ds_train,batch_size=config.batch_size)
dl_val = DataLoader(ds_val,batch_size=config.batch_size)ds_train.show_sample(10)
二,定义模型
import torch
num_classes = 1
net = smp.DeepLabV3Plus(
encoder_name="mobilenet_v2", # choose encoder, e.g. mobilenet_v2 or efficientnet-b7
encoder_weights='imagenet', # use `imagenet` pretrained weights for encoder initialization
in_channels=3, # model input channels (1 for grayscale images, 3 for RGB, etc.)
classes=num_classes, # model output channels (number of classes in your dataset)
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")三,训练模型
下面使用我们的梦中情炉~torchkeras~来实现最优雅的训练循环。😋😋
from torchkeras import KerasModel
from torch.nn import functional as F
# 由于输入数据batch结构差异,需要重写StepRunner并覆盖
class StepRunner:
def __init__(self, net, loss_fn, accelerator, stage = "train", metrics_dict = None,
optimizer = None, lr_scheduler = None
):
self.net,self.loss_fn,self.metrics_dict,self.stage = net,loss_fn,metrics_dict,stage
self.optimizer,self.lr_scheduler = optimizer,lr_scheduler
self.accelerator = accelerator
if self.stage=='train':
self.net.train()
else:
self.net.eval()
def __call__(self, batch):
features,labels = batch['image'],batch['mask']
#loss
preds = self.net(features)
loss = self.loss_fn(preds,labels)
#backward()
if self.optimizer is not None and self.stage=="train":
self.accelerator.backward(loss)
self.optimizer.step()
if self.lr_scheduler is not None:
self.lr_scheduler.step()
self.optimizer.zero_grad()
all_preds = self.accelerator.gather(preds)
all_labels = self.accelerator.gather(labels)
all_loss = self.accelerator.gather(loss).sum()
#losses
step_losses = {self.stage+"_loss":all_loss.item()}
#metrics
step_metrics = {self.stage+"_"+name:metric_fn(all_preds, all_labels).item()
for name,metric_fn in self.metrics_dict.items()}
if self.optimizer is not None and self.stage=="train":
step_metrics['lr'] = self.optimizer.state_dict()['param_groups'][0]['lr']
return step_losses,step_metrics
KerasModel.StepRunner = StepRunnerfrom torchkeras.metrics import IOU
class DiceLoss(nn.Module):
def __init__(self,smooth=0.001,num_classes=1,weights = None):
...
def forward(self, logits, targets):
...
def compute_loss(self,preds,targets):
...
class MixedLoss(nn.Module):
def __init__(self,bce_ratio=0.5):
super().__init__()
self.bce = nn.BCEWithLogitsLoss()
self.dice = DiceLoss()
self.bce_ratio = bce_ratio
def forward(self,logits,targets):
bce_loss = self.bce(logits,targets.float())
dice_loss = self.dice(logits,targets)
total_loss = bce_loss*self.bce_ratio + dice_loss*(1-self.bce_ratio)
return total_lossoptimizer = torch.optim.AdamW(net.parameters(), lr=config.lr)
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer = optimizer,
T_max=8,
eta_min=0
)
metrics_dict = {'iou': IOU(num_classes=1)}
model = KerasModel(net,
loss_fn=MixedLoss(bce_ratio=0.5),
metrics_dict=metrics_dict,
optimizer=optimizer,
lr_scheduler = lr_scheduler
)from torchkeras.kerascallbacks import WandbCallback
wandb_cb = WandbCallback(project='unet_lane',
config=config.__dict__,
name=None,
save_code=True,
save_ckpt=True)
dfhistory=model.fit(train_data=dl_train,
val_data=dl_val,
epochs=100,
ckpt_path='checkpoint.pt',
patience=10,
monitor="val_iou",
mode="max",
mixed_precision='no',
callbacks = [wandb_cb],
plot = True
)<<<<<< ⚡️ cuda is used >>>>>>
================================================================================2023-05-21 20:45:27
Epoch 1 / 100
100%|████████████████████| 20/20 [00:03<00:00, 6.60it/s, lr=5e-5, train_iou=0.15, train_loss=0.873]
100%|██████████████████████████████████| 5/5 [00:00<00:00, 8.54it/s, val_iou=0.162, val_loss=0.836]
[0;31m<<<<<< reach best val_iou : 0.16249321401119232 >>>>>>[0m
================================================================================2023-05-21 20:45:30
Epoch 2 / 100
100%|███████████████████████| 20/20 [00:02<00:00, 7.24it/s, lr=0, train_iou=0.25, train_loss=0.836]
100%|██████████████████████████████████| 5/5 [00:00<00:00, 8.49it/s, val_iou=0.291, val_loss=0.821]
[0;31m<<<<<< reach best val_iou : 0.2905024290084839 >>>>>>[0m
================================================================================2023-05-21 20:51:06
Epoch 95 / 100
100%|███████████████████| 20/20 [00:02<00:00, 7.21it/s, lr=5e-5, train_iou=0.721, train_loss=0.187]
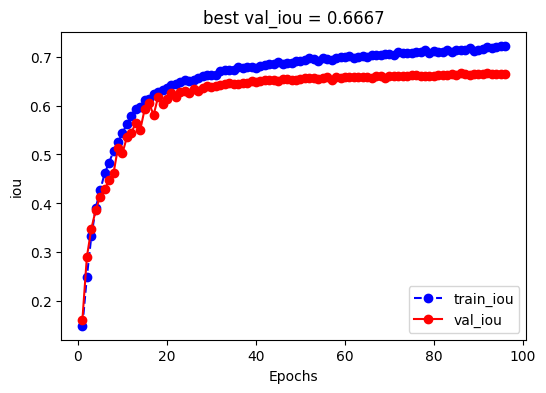
100%|██████████████████████████████████| 5/5 [00:00<00:00, 8.71it/s, val_iou=0.665, val_loss=0.249]四,评估模型
metrics_dict = {'iou': IOU(num_classes=1,if_print=True)}
model = KerasModel(net,
loss_fn=MixedLoss(bce_ratio=0.5),
metrics_dict=metrics_dict,
optimizer=optimizer,
lr_scheduler = lr_scheduler
)model.evaluate(dl_val)100%|██████████████████████████████████| 5/5 [00:00<00:00, 8.91it/s, val_iou=0.667, val_loss=0.252]
global correct: 0.9912
IoU: ['0.9911', '0.3422']
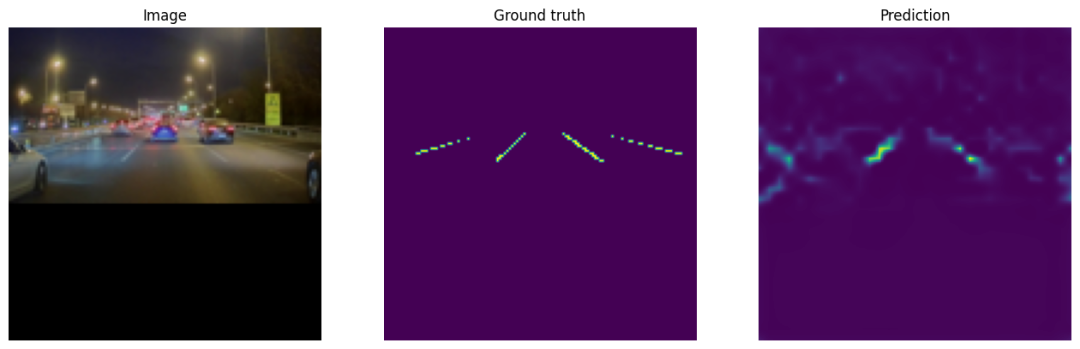
mean IoU: 0.6667五,使用模型
batch = next(iter(dl_val))
with torch.no_grad():
model.eval()
logits = model(batch["image"].cuda())
pr_masks = logits.sigmoid()from matplotlib import pyplot as plt
for image, gt_mask, pr_mask in zip(batch["image"], batch["mask"], pr_masks):
plt.figure(figsize=(16, 10))
plt.subplot(1, 3, 1)
plt.imshow(image.numpy().transpose(1, 2, 0)) # convert CHW -> HWC
plt.title("Image")
plt.axis("off")
plt.subplot(1, 3, 2)
plt.imshow(gt_mask.numpy().squeeze())
plt.title("Ground truth")
plt.axis("off")
plt.subplot(1, 3, 3)
plt.imshow(pr_mask.cpu().numpy().squeeze())
plt.title("Prediction")
plt.axis("off")
plt.show()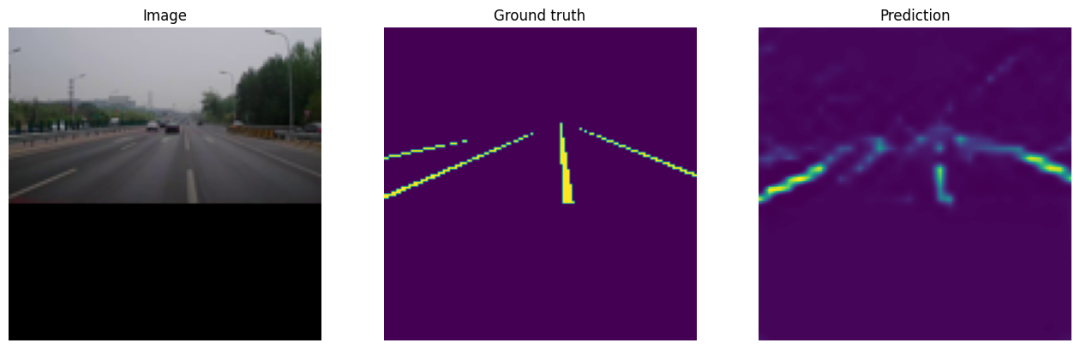


六,保存模型
torch.save(model.net.state_dict(),'deeplab_v3_plus.pt')公众号算法美食屋后台回复关键词:torchkeras,获取本文notebook代码和车道线数据集下载链接。
万水千山总是情,点个赞赞行不行?😋😋