珍惜当下的一切,相信未来的一切都是美好的。 -- 丹尼尔·迪凯托
目录
一.堆的概念及结构
二.堆的各种函数的实现
1.结构体的内容
2.堆的初始化
3.堆的插入
4.堆的向上调整法
5.验证堆的向上调整法
6.堆顶的删除
7.堆的向下调整法
8.返回堆顶的元素
9.堆的数据个数
10.堆的判空
11.堆的销毁
三.全部代码:
1.Heap.h
2.Heap.c
3.test.c
四.堆的向上调整法和堆的向下调整法的区别(含手写推导)
1.堆的向上调整法的时间复杂度
2.堆的向下调整法的时间复杂度
3.没分清这两种方法吗?那就记一个口诀吧
五.堆的应用
1.堆排序
1.1.如何计算它的时间复杂度
2.Topk应用
一.堆的概念及结构
如果有一个关键码的集合K ={k0,k1, k2,…,kn-1},把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足:Ki <= K2i+1 且 Ki<= K2i+2 (Ki >= K2i+1 且 Ki >= K2i+2) 则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆的性质:
1.堆中某个节点的值总是不大于或不小于其父节点的值;
2.堆总是一棵完全二叉树。
总之,根结点的值总是小于或者等于它的孩子的值,组成的完全二叉树叫作小堆。
根结点的值总是大于或者等于它的孩子的值,组成的完全二叉树叫作大堆。
大小堆的结构:
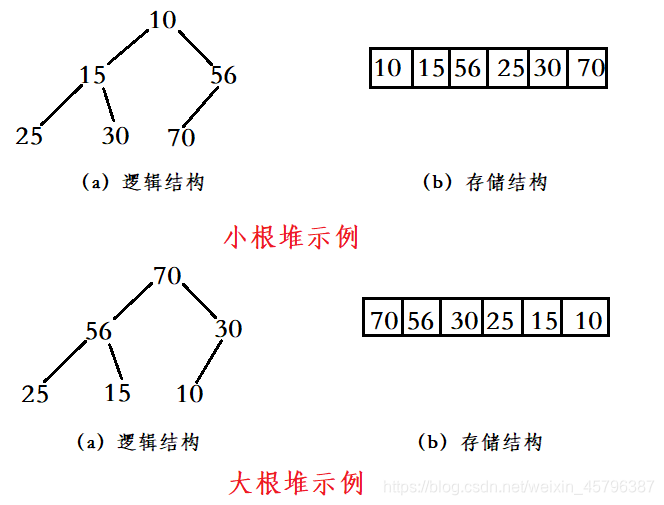
这里我们操作的是数组,也就相当于操作了二叉树,这就是完全二叉树的魅力。
二.堆的各种函数的实现
堆的实现,就是我们把一组随机的数据,把它们建成小堆或者大堆。接下来就是各种函数的实现,各位老铁坐稳了,老司机发车了。
1.结构体的内容
这个比较简单,因为不管小堆和大堆,它们都是完全二叉树,物理上使用一维数组来顺序存储,所以结构体中包含的内容就和之前顺序表实现的一样,动态的数组,数据的个数和数组的容量。
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;//动态的数组
int size;//数据的个数
int capacity;//数组的容量
}Heap;2.堆的初始化
我们可以初始化数组开始为NULL,size和capacity都为0,然后在堆的插入的时候,再开辟空间,或者我们可以初始化的时候先给数组开辟几个空间。这里我们实现初始化就先开辟几个空间。
void HeapInit(Heap* hp)
{
assert(hp);
hp->a = (HPDataType*)malloc(sizeof(HPDataType) * 4);//先开辟四个空间
if (hp->a == NULL)
{
perror("malloc\n");
return;
}
hp->size = 0;
hp->capacity = 4;
}3.堆的插入
这里的插入和顺序表的插入一样,我们一个一个的把数据插入到数组中去,插入第一个数据,我们不需要调整为堆,因为当数组中只有一个数据的时候,它就可以看作为一个堆。然后当数组中插入第二个数据了之后,我们就要调用向上调整法,把它调整为小堆或者大堆。所以说数组中每插入一个数据之后,我们就得调用向上调整法,把它调整为小堆或者大堆。当把数据插入完了之后,这个数组构成的二叉树就自动变成了小堆或者大堆了。
堆插入的代码实现:
// 堆的插入
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
if (hp->size == hp->capacity)//空间不够了,就要扩容
{
HPDataType* temp = (HPDataType*)realloc(hp->a, sizeof(HPDataType) * hp->capacity * 2);
if (temp == NULL)
{
perror("realloc");
return;
}
hp->a = temp;
hp->capacity *= 2;
}
hp->a[hp->size++] = x;
Adjustup(hp->a, hp->size - 1);//向上调整法,hp->size-1就是调整插入的这个数的下标
}4.堆的向上调整法
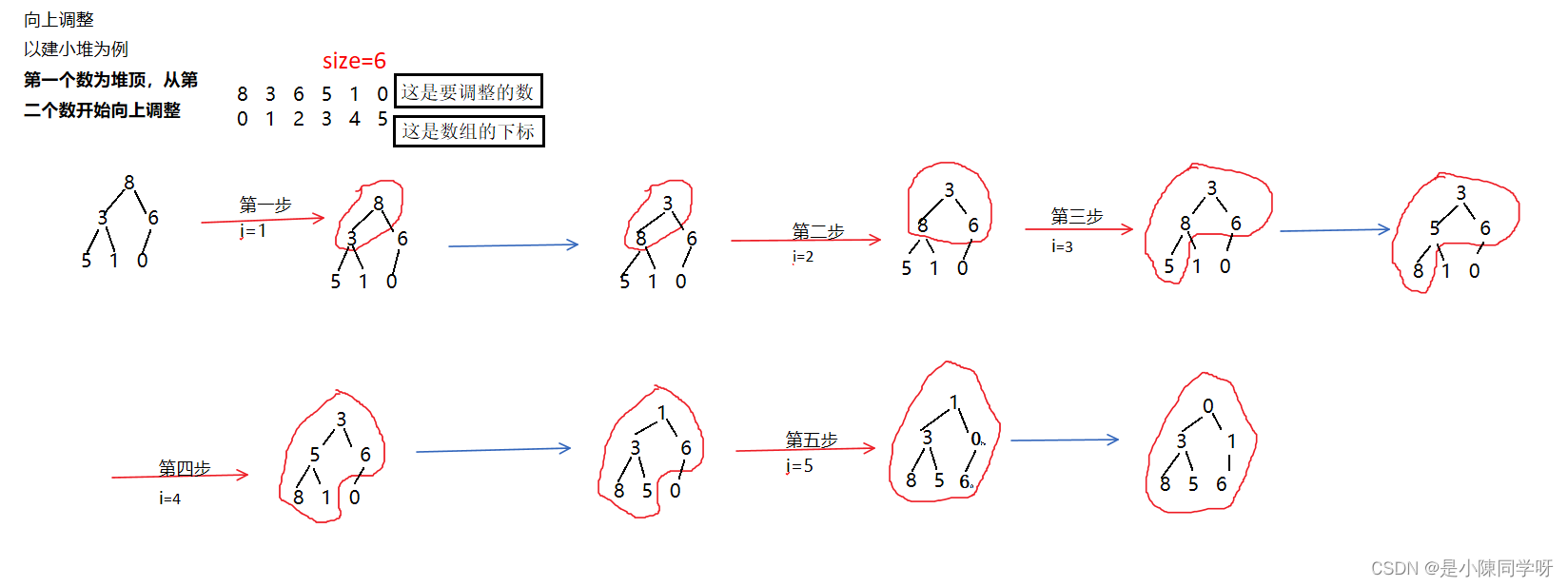
堆的向上调整的思路:
数组中的第一个数据本身就可以看作为一个堆,然后插入第二个数据时,我们以小堆为例。
1.当插入的数据值小于它的双亲结点数据值时,我们就交换这两个数据。
2.交换好了之后,这个数据就变成它双亲结点的位置了,如果这个位置还有双亲,那么就再比较,如果还小于就继续交换,如果是大于,就停止交换,然后等待下一个数的插入。
依次类推,插入一个数进去,就调整为小堆,当值插入完了之后,最后一次调整即可,使得这个数组变成小堆的结构。
画图理解:
代码实现:
//向上调整堆
void Adjustup(int* a, int child)
{
int parent = (child - 1) / 2;//知道插入数据的下标,算它的双亲结点的下标
while (child > 0)
{
if (a[parent] > a[child])//如果双亲的值大于插入的值就交换
{
swap(&a[parent], &a[child]);//交换值的函数
child = parent;
parent= (child - 1) / 2;//这两个代码块是更新双亲结点的下标
}
else//如果双亲的的值小于插入的值就退出循环
{
break;
}
}
}交换值的函数:
//交换值
void swap(int* p1, int* p2)//记得传参一定要传地址
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}5.验证堆的向上调整法
理解了堆的向上调整法,我们就可以往数组里面入几个数据来试试看,来验证我们写的程序到底有没有问题,这是我们每个人都应该养成的写代码的好习惯,写一部分,验证一部分,不然到时候写完了,再来运行,可能会出现一堆bug。
#include"Heap.h"
int main()
{
Heap hp;
HeapInit(&hp);
HeapPush(&hp, 5);
HeapPush(&hp, 4);
HeapPush(&hp, 7);
HeapPush(&hp, 2);
HeapPush(&hp, 1);
HeapPush(&hp, 9);
printf("小堆的顺序为\n");
Heapprint(&hp);
return 0;
}我们插入数组的值是5 4 7 2 1 9。然后最后的结果应该是一个小堆的结构,我们来看是不是?
其实很明显,这就是一个小堆的结构,如果不能很好的看出,画图就可以很清晰的看出了。
根结点始终比它的孩子结点小,故而这符合小堆。
6.堆顶的删除
我们知道顺序表中数组首元素的删除,是移动后面数往前面一位,这样就把数组的首元素给覆盖掉了,这就达到了删除的目的,那关于这个二叉树的堆顶的删除我们可不可以这么做呢?
显然没有这么简单,因为如果我们直接删除了堆顶的元素,然后所有的数往前面移动了一位,它们的位置全部发生了变化,小堆的结构也不存在了,而且自己孩子可能会变成自己的兄弟,这显然是不允许的。
就像下面的结构:
这里我们就要用到一个非常牛逼的方法:
我们先把堆顶的元素和堆尾的交换,然后数组里面的size--即可把堆顶的元素给删除了,然后堆尾的数据就到了堆顶了,整个堆的大致结构还是没变的,我们只需要调整把这个堆顶的元素依次往下调,直到把这个结构调成一个小堆的结构。
这里调的方法叫做堆的向下调整法:
// 堆顶的删除
void HeapPop(Heap* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
swap(&hp->a[0], &hp->a[hp->size - 1]);//交换堆顶和堆尾的数据
hp->size--;//删除堆尾的数据,也就是还没交换之前的堆顶数据
Adjustdown(hp->a, hp->size, 0);//向下调整法
}7.堆的向下调整法
现在我们给出一个数组,逻辑上看做一颗完全二叉树。我们通过从根节点开始的向下调整算法可以把它调整成一个小堆。向下调整算法有一个前提:左右子树必须是一个堆,才能调整。
就比如说刚刚那个数组,删除堆顶的元素之后,二叉树变成了这样:
堆的向下调整法的思路:
我们看双亲结点的孩子谁更小,然后双亲结点和更小的那个孩子交换,然后更新双亲结点,使原本孩子的结点位置变成双亲的结点位置,再通过双亲结点的位置找到孩子结点,继续比较它们两个的大小,从而看是交换还是不交换。
代码的实现:
//向下调整堆
void Adjustdown(int* a, int n, int parent)
{
int child = parent * 2 + 1;//假设左孩子小
while (child < n)
{
if (child+1<n&&a[child + 1] < a[child])
//如果右孩子小,我们就让child++,就使得左孩子变成右孩子了
{
child++;
}
if (a[child] < a[parent])//如果双亲结点比最小的那个孩子大,就交换
{
swap(&a[child], &a[parent]);
parent = child;//更新双亲结点
child = parent * 2 + 1;//继续找孩子结点
}
else
{
break;
}
}
}同样我们写了一个堆顶的删除,我们还是测试一些,我们写得对不对。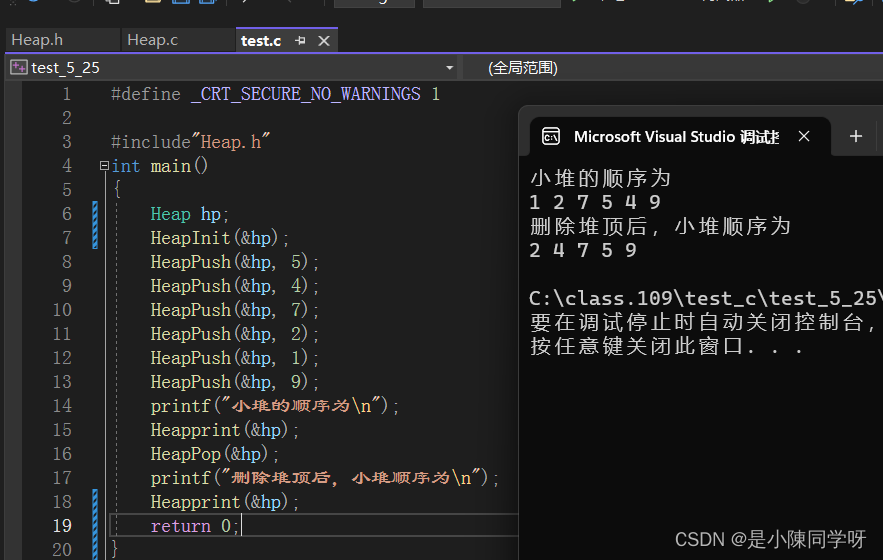 果然和我们推导的一样,那就说明写得没有问题。
果然和我们推导的一样,那就说明写得没有问题。
8.返回堆顶的元素
这个就比较简单了,堆顶就是下标为0的位置。
// 取堆顶的数据
HPDataType HeapTop(Heap* hp)
{
assert(hp);
return hp->a[0];
}9.堆的数据个数
每插入一个数据,size就++,所以size就堆的数据个数。
// 堆的数据个数
int HeapSize(Heap* hp)
{
return hp->size;
}10.堆的判空
就只有size=0的时候,堆才为空。
// 堆的判空
int HeapEmpty(Heap* hp)
{
assert(hp);
return hp->size == 0;//为空,就为真,否则为假
}11.堆的销毁
// 堆的销毁
void HeapDestory(Heap* hp)
{
assert(hp);
free(hp->a);
hp->a = NULL;
hp->size = hp->capacity = 0;
}三.全部代码:
1.Heap.h
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdbool.h>
#include<stdlib.h>
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int size;
int capacity;
}Heap;
//堆的初始化
void HeapInit(Heap* hp);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆顶的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
int HeapEmpty(Heap* hp);
//打印
void Heapprint(Heap* hp);
2.Heap.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"Heap.h"
void HeapInit(Heap* hp)
{
assert(hp);
hp->a = (HPDataType*)malloc(sizeof(HPDataType) * 4);
if (hp->a == NULL)
{
perror("malloc\n");
return;
}
hp->size = 0;
hp->capacity = 4;
}
//交换值
void swap(int* p1, int* p2)
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
//向上调整堆
void Adjustup(int* a, int child)
{
int parent = (child - 1) / 2;//知道插入数据的下标,算它的双亲结点的下标
while (child > 0)
{
if (a[parent] > a[child])//如果双亲的值大于插入的值就交换
{
swap(&a[parent], &a[child]);//交换值的函数
child = parent;
parent= (child - 1) / 2;//这两个代码块是更新双亲结点的下标
}
else//如果双亲的的值小于插入的值就退出循环
{
break;
}
}
}
// 堆的插入
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
if (hp->size == hp->capacity)
{
HPDataType* temp = (HPDataType*)realloc(hp->a, sizeof(HPDataType) * hp->capacity * 2);
if (temp == NULL)
{
perror("realloc");
return;
}
hp->a = temp;
hp->capacity *= 2;
}
hp->a[hp->size++] = x;
Adjustup(hp->a, hp->size - 1);
}
// 堆的销毁
void HeapDestory(Heap* hp)
{
assert(hp);
free(hp->a);
hp->a = NULL;
hp->size = hp->capacity = 0;
}
// 堆的数据个数
int HeapSize(Heap* hp)
{
return hp->size;
}
// 堆的判空
int HeapEmpty(Heap* hp)
{
assert(hp);
return hp->size == 0;
}
// 取堆顶的数据
HPDataType HeapTop(Heap* hp)
{
assert(hp);
return hp->a[0];
}
//向下调整堆
void Adjustdown(int* a, int n, int parent)
{
int child = parent * 2 + 1;//假设左孩子小
while (child < n)
{
if (child+1<n&&a[child + 1] < a[child])//如果右孩子小,我们就让child++,就使得左孩子变成右孩子了
{
child++;
}
if (a[child] < a[parent])//如果双亲结点比最小的那个孩子大,就交换
{
swap(&a[child], &a[parent]);
parent = child;//更新双亲结点
child = parent * 2 + 1;//继续找孩子结点
}
else
{
break;
}
}
}
// 堆顶的删除
void HeapPop(Heap* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
swap(&hp->a[0], &hp->a[hp->size - 1]);//交换堆顶和堆尾的数据
hp->size--;//删除堆尾的数据,也就是还没交换之前的堆顶数据
Adjustdown(hp->a, hp->size, 0);//向下调整法
}
//打印
void Heapprint(Heap* hp)
{
assert(hp);
for (int i = 0; i < hp->size; i++)
{
printf("%d ", hp->a[i]);
}
printf("\n");
}
void HeapSort(int* a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
Adjustdown(a, n, i);
}
int end = n - 1;
while (end > 0)
{
swap(&a[0], &a[end]);
Adjustdown(a, end, 0);
end--;
}
printf("小堆排降序为:\n");
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
}3.test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"Heap.h"
int main()
{
Heap hp;
HeapInit(&hp);
HeapPush(&hp, 5);
HeapPush(&hp, 4);
HeapPush(&hp, 7);
HeapPush(&hp, 2);
HeapPush(&hp, 1);
HeapPush(&hp, 9);
printf("小堆的顺序为\n");
Heapprint(&hp);
HeapPop(&hp);
printf("删除堆顶后,小堆顺序为\n");
Heapprint(&hp);
return 0;
}
四.堆的向上调整法和堆的向下调整法的区别(含手写推导)
上面我们分别使用了两种调堆的方式:
一个是堆的向上调整法:从开始插入就逐渐调整堆。
一个是堆的向下调整法:需要下面的子树是堆结构,然后再进行调堆。
堆的向下调整法是需要子树是堆结构,那我们就从倒数第一个非叶子结点开始调堆,然后逐渐往前面调堆,就如下图所示:
我们估量一个算法的效率,就是看它的时间复杂度和空间复杂度,这里我们就来看看这两个算法的时间复杂度怎么样。
1.堆的向上调整法的时间复杂度

手推: 
2.堆的向下调整法的时间复杂度:

手推: 
这里可以看出堆的向上调整法时间复杂度是O(N*logN),而堆的向下调整法时间复杂度是O(N),可以看出堆的向下调整法效率要高一点。
等会我们还会具体说的这个两种方法。
3.没分清这两种方法吗?那就记一个口诀吧
堆的向上调整法,就是从上依次往下建堆;而堆的向下调整法,就是从下依次往上建堆。
记忆:上调上下建,下调下上建。第一个上下就是具体的方法,后面的上下就是建的顺序。
五.堆的应用
说完了如何建堆,那我们就该说说堆的具体作用了。
堆的应用有以下几个方面:
1.堆排序
2.Topk应用
3.优先级队列
这里我们只说堆排序和Topk应用,优先级队列需要学习了C++了之后,再实现。
1.堆排序
刚刚我们实现了把一个数组建成一个堆的结构,但是它并不是完全降序和升序的,而马上要学习的堆排序就是,把堆结构进行降序或者升序排列。
很早之前我们学习过冒泡排序,非常的简单,使用两个循环即可实现,它的时间复杂度是O(N^2),可以说时间复杂度是很高的了,而堆排序将是我们学习的第一种时间复杂度为O(N*logN)的排序。
具体实现:
1.给你一个数组,然后我们把它建成小堆,故而堆顶的数据便是最小的。
2.再把堆顶的数据和堆尾的数据进行交换。
3.然后size--,不管堆尾的数据,然后把剩下的结构再使用堆的向下调整法,把它们重新建成小堆。
4.然后最小的数据又在堆顶了,然后重复上面的步骤,依次把最小的数据往数组后面放,那么最后的结果就是一个降序的结构。
所以我们有两个口诀:降序建小堆,升序建大堆。
这里有两种建堆的方式,一个是向上建堆的方式,另一个是向下建堆的方式,这里我们向下建堆的方式,这样不仅只需要写向下建堆的函数,而且效率更高。
代码实现:
#include<stdio.h>
//交换函数
void swap(int* p1, int* p2)
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
//堆的向上调整法
void AdjustUp(int* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] < a[parent])
{
swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
//堆的向下调整法
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;//假设左孩子是更小的
while (child < n)
{
if (child + 1 < n && a[child + 1] < a[child])
{
child++;
}
if (a[child] < a[parent])
{
swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//堆排序
void Heapsort(int* arr, int n)
{
/*for (int i = 1; i < n; i++)//向上建堆的方式
{
AdjustUp(arr, i);
}*/
for (int i = (n - 1 - 1) / 2; i >= 0; i--)//从倒数第一个非叶子结点开始向上建堆
{
AdjustDown(arr, n, i);
}
int end = n - 1;
while (end > 0)
{
swap(&arr[end], &arr[0]);//交换顶和尾的数据
AdjustDown(arr, end, 0);
end--;
}
}
int main()
{
int arr[] = { 80,68,43,55,90,54 };
Heapsort(arr, sizeof(arr) / sizeof(int));
for (int i = 0; i < sizeof(arr) / sizeof(int); i++)
{
printf("%d ", arr[i]);
}
return 0;
}
1.1.如何计算它的时间复杂度
代码我们已经实现好了,那我们来计算一下它的时间复杂度。
第一个for循环很简单,它就是堆的向下调整法的时间复杂度O(N)。
第二个while循环,可能就会困惑,包括我开始也是。while循环是N,然后里面嵌套堆的向下调整法,那时间复杂度应该是*O(NN)才对呀,这样理解确实感觉也没毛病。这里可不是这样算滴。
交换最后一个数,就要向下调整一次,最后一层有多少个结点,就要交换多少次。
整个while循环的逻辑,其实和堆的向上调整法是一样的,最后一层有2^(h-1)个结点,一个结点需要向上调整h-1。然后相乘起来,再算上面层数的次数,最后相加起来。逻辑一模一样。不懂仔细琢磨一下堆的向上调整法的时间复杂度的计算方法:
所以堆排序的总的次数是N+N*logN。故而时间复杂度是O(N*logN)。
排序结果: 
2.Topk应用
Topk问题:即求数据集合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
我们最容易想到的方法就是全部进行降序排序,然后Topk问题就直接解决了。
但是数据量非常多,我们的内存是存不下这么多的数据的,这里我们就要用到堆来实现。
假如我们需要找到10万个数里面的最大的前5个数。
具体思路:
1.我们取10万个数的前10个数,然后放到一个能容纳10个数的小堆里面,
2.然后依次取10万个数出来,依次和堆顶的元素进行比较,如果大于堆顶的元素就直接入堆,然后调整堆,然后再入,再调,最后堆中的元素就最大的前10个数。
注意:这里找最大的k个数,一定要建小堆,找最小的k个数,一定要建大堆。
这里我们把数据写到文件里面去。
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
void swap(int* p1, int* p2)
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;//假设左孩子是更小的
while (child < n)
{
if (child + 1 < n && a[child + 1] < a[child])
{
child++;
}
if (a[child] < a[parent])
{
swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//生成10万个随机数
void CreatData()
{
int n = 100000;
srand(time(0));//使用time生成随机数
const char* file = "data.txt";//创建一个文件
FILE* fin = fopen(file, "w");//以写的方式
if (fin == NULL)
{
perror("fopen error");
return;
}
for (size_t i = 0; i < n; i++)
{
int x = rand() % 100000;//取余操作即生成n个小于100000的数
fprintf(fin, "%d\n", x);
}
fclose(fin);
}
//打印出来最大的前k个数据
void PrintTopk(int k)
{
const char* file = "data.txt";//创建一个文件
FILE* fout = fopen(file, "r");//以读的方式
if (fout == NULL)
{
perror("fopen error");
return;
}
int* HeapTopk = (int*)malloc(sizeof(int) * k);//创建k个数据的数组
if (HeapTopk == NULL)
{
perror("malloc");
return;
}
for (int i = 0; i < k; i++)
{
fscanf(fout, "%d", &HeapTopk[i]);//把k个数存到数组里面去
}
for (int i = (k - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(HeapTopk, k, i);//建成一个小堆
}
int val = 0;
while (!feof(fout))//结束标志
{
fscanf(fout, "%d", &val);
if (val > HeapTopk[0])//如果大于就交换
{
HeapTopk[0] = val;
AdjustDown(HeapTopk, k, 0);//向下调整
}
}
for (int i = 0; i < k; i++)
{
printf("%d ", HeapTopk[i]);
}
printf("\n");
}
int main()
{
CreatData();
PrintTopk(10);
return 0;
}
 这里如何验证找到的是不是最大的前k个呢?
这里如何验证找到的是不是最大的前k个呢?
我们可以到文件里面去修改,看找到的数据是不是我们修改的那几个。 这是我们修改的最大的几个数。
这是我们修改的最大的几个数。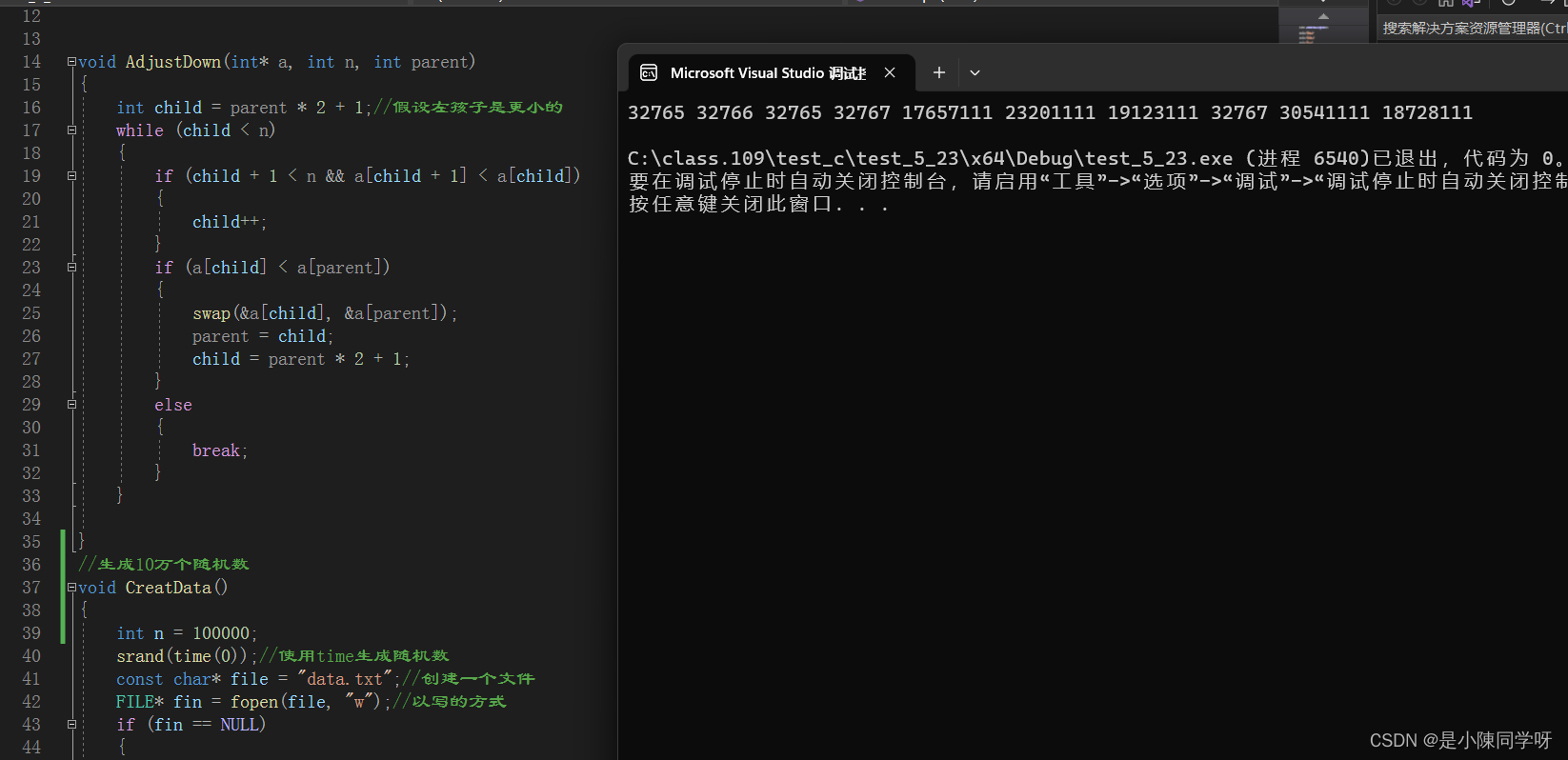 这确实是我们修改的几个数,最后你还可以使用堆排序,把这几个数排成升序。
这确实是我们修改的几个数,最后你还可以使用堆排序,把这几个数排成升序。
总结:堆的讲解到这里就结束了,希望对大家有所帮助。