原创:谭婧

全球AI大模型的技术路线,没有多少秘密,就那几条路线,一只手都数得过来。
而举世闻名的GPT-4浑身上下都是秘密。
这两件事并不矛盾。为什么呢?
这就好比,回答“如何制造一台光刻机?”。
“所需要的任何数学公式、物理学定律和工作原理,都可以在任何一所理工科大学的图书馆里找全,但是这距离制造出光刻机,完全是两码事,中间需要解决的工程问题是数以十万级。”
光刻机的例子来自曾任微软雷德蒙德研究院深度学习技术中心的首席研究员,现任京东集团副总裁、京东科技智能服务与产品部负责人的何晓冬博士。
将技术做到极致,人类智慧正在打开“机器智慧”的魔盒。
极致背后的奥秘被多位科学家以毕生之经历数次总结。
我于2021年7月收藏了何晓冬博士在京东AI研究院内部分享的九条经验,频频回顾,总有收获。

分享得到了他的允许。
在这九条经验中,何晓冬博士不仅再次强调了“工程能力”的重要性,而且毫无保留地将他心中的普世科研真谛递给麾下科研人员。
如今,大模型的爆发将AI工程实践推向了一个崭新巅峰。在何晓冬博士看来,AI在科学原理意义上的进步,离不开工程的极致实现。
这是一个“既要”“也要”的难题。
历史反复证明,技术是创新的核心,但它也需要资源和管理的加持才能产生预期的成果。所以,创新不是技术的独角戏,而是与资源与管理的合奏曲。
当今世上,一个人一支笔依然可以拿诺贝尔文学奖,但一个人就想造出有竞争力的千亿参数的AI大模型,已绝无可能。

那些容易被忽略的细节,科技观察者应该重视。
当某一技术路线蓄积爆发的力量,那么多年前这个技术路线上奠基论文的引用数量就会突然间增长。
时隔五年,一篇完成于2018年,关于注意力机制的论文(“Bottom-up and top-down attention”)引用量,悄然增长(截至发稿前4028次引用)。
这篇论文的学术价值在于,在更高层次上提出一个比较基础的问题:“跨模态的语言和图像信息,在语义层次怎么对齐?”
假如哪位读者对多模态技术感到兴奋,那“对齐”这个词,定是“后会有期”。
稍作论文综述与归纳就会发现,这篇论文是更早期三篇论文的“集大成者”。文中提出了一种非常创新的注意力机制。前三篇之一的论文“Hierarchical attention networks”,截至我的这篇文章发稿前,有4953次引用。一般来说,AI领域论文引用量在一千以上就算较高。
而今看来,三篇蓄力一篇发力的技艺让这套“三+一”的论文有了里程碑式的意义。

有趣的是,过去五年,CVPR会议发表的所有论文中,“Bottom-up”这篇论文排名前二十。
更有趣的是,排名前二十的论文中,只有“Bottom-up”这一篇是有关多模态的。
要我说,排名前二十的论文中,按多模态技术排名,这篇论文排第一。(因为前19篇都是关于计算机视觉的,哈哈。)
这项多模态学术论文奠基工作来自何晓冬与京东云言犀人工智能应用平台团队。
CVPR在世界上所有期刊和会议文集中排名第四,有多少AI科研工作者宵衣旰食、不辞劳苦都是为了在会议截稿前争取“一张门票”。
CVPR有一个指标(H5因子),在此发表的重要工作(不是所有工作)的科研价值已经跟科学杂志Nature(《自然》),Science(《科学》)处于同一水平。
从2014年的第一篇发布至今,日月不居,匆匆九年。
多模态技术之于大模型重要性不言而喻,时间会等待想法不同的人最终到达同一个目的地。
在这九年中,2018年是一个特别重要的年份。
那一年,何晓冬出任京东AI 研究院常务副院长。
那一年,何晓冬博士团队用文生图算法(AttnGAN)生成了一张小鸟“照片”。
可以说,这是人工智能文生图的“古早小鸟”。
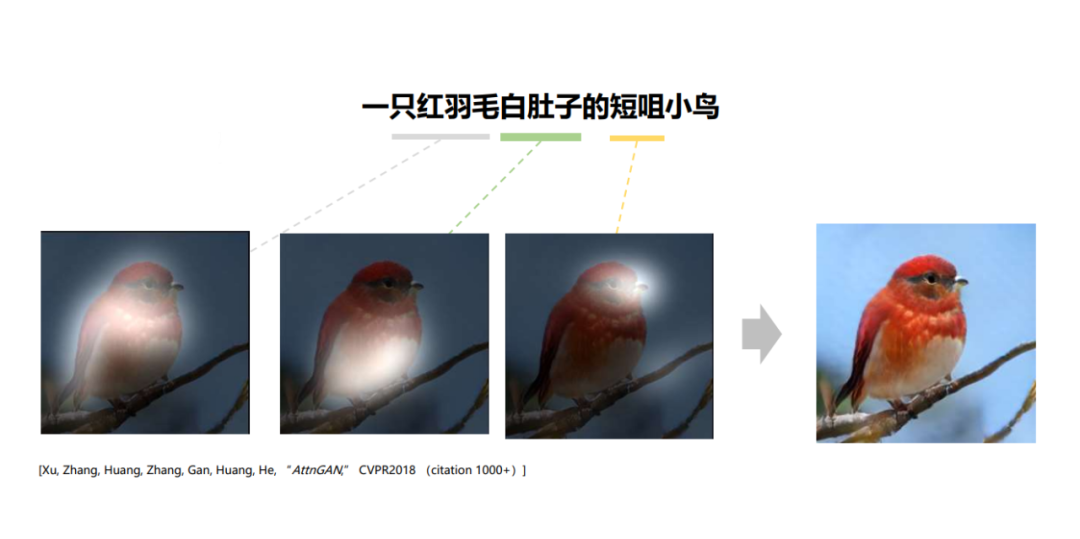
那是一只红羽毛白肚子的短嘴小鸟,胖憨可爱,加上两道黑粗剑眉,神似风靡全球的游戏“愤怒小鸟”里的主角。何晓冬博士告诉我,他喜欢给阶段性工作留下纪念品,这只小鸟有段时间是他的手机屏保。
那一年,时光仿佛打开了一扇门。他从门缝中看到了一个更大的空间,一个从未见过的空间,他对到达那个空间充满信心。
何晓冬博士说:“不只是我的团队做大模型要走多模态这一条路,其他团队也得走这条路。”
“走多模态大模型技术路线,就一定会决策要在哪个层次做多模态融合。“他强调。
显然,这是在考验科研团队带头人的决策能力。
“这是一个科学问题。”何博士说。我补充道:“这是一个离应用非常近的科学问题。”
何晓冬博士点了点头,表示认可。
谛听于此,心潮澎湃。
此前我一直认为,在大模型的世界里,多模态技术还有很大机会。
我请教何博士几个令人兴奋的技术问题:
1.要实现多模态大模型的涌现,现在的Transformer模型架构是否足够?Transformer模型架构有没有必要做底层改变?
何博士说,也许有必要,也许没有必要,需要探索研究。
2.是在语义层面对齐,还是数据层面对齐?
何博士的观点是,在语义层面,或者更低。

我认为,多模态大模型的起点是语言大模型。
也就是说从某种程度上,语言大模型的科研水平和工程能力是大模型的坚实基础。
一开始,何晓冬与言犀团队语言大模型的发展目标是使其具有更强的语言能力,特别是语言生成能力。这种能力很快在京东就用起来了。说白了,写商品文案能写得越来越好。
团队的大模型原创性工作包括10亿规模参数的K-PLUG大模型。K代表knowledge,知识。这个大模型从2019年开始推动,到2021年就成熟了。
京东毕竟是一家擅长于用技术推动零售生意的企业,基于京东云言犀AI应用平台的基础能力,内容审核,拍照购、商品营销文案生成等多种应用应运而生。
比如,在京东商城里,商品营销文案工作量大,文案生成很有必要,且已覆盖到商品三级类目(服装,女装,连衣裙),已达3000余个三级类目。
清点一下总体工作量,K-PLUG大模型累计生成超30亿字,直接带来了至少3亿元人民币的收入。
我向团队中的吴博士和张博士了解到,文案生成场景有一个有趣的地方,文案生成后要人工审核,而通过率就好比成绩单,目前成绩是95分(满分100分)。因为通过率已经超过了95%。
产业场景对大模型的常态是“苛求”。
团队发现,很多产业应用对“生成内容”的忠实度和可靠性要求极高,营销一个商品不能一味堆砌赞美之词,真实的赞美尤其重要。
日常推荐冰箱都会谈到绿色节能制冷好,但是情况不适用于奢侈款冰箱,节能不是奢侈款冰箱的优势。
在传统语言模型时代,很可能会把一些词就放上去了。对冰箱产业链来讲,忌讳“有名无实”,把不存在的“亮点”硬塞给商品,商家完全不可能接受。
何晓冬与言犀团队不会只做一个技术路线,大模型背后有很多尝试工作,或者说创新本身就包含多种尝试。
团队的大模型原创性工作还包括一个多模态文本生成模型。也就是说,现有的两类大模型将会是未来京东产业大模型的重要组件。
团队对大模型的技术布局,既是场景推动,也是产业推动。
那么,团队的当下聚焦与未来远景分别是什么?
目前聚焦AGI,第一步做通用语言大模型。
第二步做多模态大模型(在这步一定会决策在哪个层次做多模态融合)。
何晓冬博士说,接下来,团队会从文生图技术着手。
“文生图会是很好的一个牵引性的应用。”何晓冬博士说,“虽然这是科学问题,但我们还是希望有一个应用来牵引。”
这也是一个非常务实的做法,对何博士来说,产业落地始终是不懈追求。
第三步,当通用智能向前进发,除了多模态技术非常关键之外,数字智能会走向实体世界。物理世界中的机械体,不管是手臂,机器人,还是无人驾驶汽车,将通用智能赋予机械体会是一个巨大飞跃。
未来,人均毕业于哈利·波特的母校霍格沃茨四大学院,这是不是会让人感到害怕?
2017年美国耶鲁大学的一次会议上,何晓冬博士和美国波士顿动力机器人团队有一场令双方兴奋的交流。
何晓冬博士说,如果把多模态认知智能装到机器狗里去,会发生什么?
比如,去隔壁小卖店帮我买一瓶可乐。这个对人类小孩来说是简单任务,对机械狗来说是高难度的。复杂环境下的定位,识别,外加推理、数学、对话等“技能”。
能不能进店?
认不认识可乐?
买回来口香糖怎么办?
机械狗可能也会为自己犯下“花式错误”辩解:“起猛了,犯错有点多。”
何晓冬博士的观点是,比较之前的感知智能,认知智能进入到一个学习曲线更加陡峭,也就是说,更加艰难的学习过程里。
越是难走,越无法预判出人类走出这条“山路”的时间。
难在何处呢?
到了认知智能这个层次后,学习会变得困难。而在感知智能这个层次,你可以很清晰地告诉计算机,识别错了,改过来。打标签就是公布答案。反复试验(trial and error)这个机制很清晰。
然而,认知智能则行不通。
人们常说:“一千个人心中有一千个哈姆雷特。”在认知智能这个层次,情况变得微妙和复杂,也就是说,AI要理解事务的复杂性,涵义的宽泛性。一幅画,每个人都有自己的理解,也许各个角度的描述都是正确的,那么如何设计训练?
这个问题我们遇到了,美国公司OpenAI肯定也遇到了。人类反馈是非常重要的技术。人类可能只能给出一些非常大致(general)的反馈,但是很难给出非常细节(detail)的标注。
日前,很多人对大模型无止境的算力,数据,参数量的增长,持悲观态度,担忧有可能形成新一轮的技术垄断。
那些中小企业势穷力尽也不能从零造出世界领先大模型,他们的诉求是“用”。在这一点上,何博士做了乐观的判断。
何博士描述了两个台阶。
第一个台阶很难迈上去,踏步难度大。
在这个台阶,我们制造一个通用大模型,通识能力强,异常困难,且所费不赀。
当大模型具备了信息压缩、逻辑判断与推理等良好能力之后,下一个台阶的踏步高度就会降低。
“门槛”变低的技术原理是,大模型能力强了之后,下一步“微调”,算力成本也降低。
此时,产业受益之处就体现出来了。
产业利润低洼地的企业,以及供应链上地位低的中小企业都有机会用上“大模型”。如此一来,不仅不会加大数字和技术鸿沟,还会产生普惠价值。

先抛一个问题:“我昨天在电商下单的手机今天什么时候到?”
从技术的角度,这个问题内容简短,意图清晰。
只可惜,ChatGPT回答不了。
因为答案不在公共信息里。
想回答这个问题,ChatGPT就得知道在哪里下单,得接入电商业务系统,包括订单、下单、仓储、物流。
毫无疑问,一个相对独立的“领地”,会有独特的场景和数据。
毫无疑问,这样的“领地”有成千上万个。
在京东,仅靠“实验室指标成功”和“比赛打榜第一”的技术结果,这些都远远不够。
因为京东对购物体验要求高,人类客服都不能服务差,更别说机器人了。所以,从技术走到服务这个过程必须在京东内部有非常严格的验证,验证逻辑就是直接和人类服务对比。
“服务水平”差,那个技术就完蛋了,用不了。
举三个例子,体会“独家难题”。
第一,京东智能客服有一个指标叫“首句挂断率”。这很好理解,操着某某浓厚方言又不着五六的腔调的电话和你说人货钱,你不仅不信,而且想挂断。
人在通电话时也会被挂断,但是,智能客服被挂断的比率一定要接近人类客服挂断比率。
家电大件商品配送货的时间预约电话,接起来一听就是机器人的冰冷声音,电话瞬间被挂,实在很耽误事。
第二个例子是售后。
比如用户带着售后问题来了,得尽快把人家的问题解决掉。这时候,客服不需要“嘴甜留人”,而是尽快理解人家之所急,给一个满意的方案,然后,就没有然后了,服务结束,满意而归。
聊天时间长,闲扯能聊,这都不是对售后智能客服的要求。
用技术语言来总结就是:人机对话中,通常带有明确目的指向,需完美解决客户售前售后咨询、价保、交易、支付、配送、退换货服务等各环节需求。
第三个例子是400热线。用户来电投诉,谁也不会准备投诉的演讲稿,再照稿朗诵。用户想怎么说都行,一边说一边想,想停就停。
半句话,倒装句,车轱辘话,能不能听懂?
说错了,再纠正,能不能理解?
旁边有人说话,有电视声音,能不能区分?
这些都是在语音交互里面的难点。
第三个例子,虽然口语谈话打断习以为常,但曾经是个技术难点。比如,智能客服说完了,轮到人类发言了,人类可能在思考。
犹太谚语说:“人类一思考,上帝就发笑。”
机器人怎么知道对方说完了?
比如,超过2秒对方就不说了,写这么一个规则够用吗?我们很难写一个规则让大多数人舒服。
对此,何晓冬与言犀团队用一个多模态的话语决策模型解决。原理是,通过语音信号、停顿时间、语意完整度、语气相关等多模态信号综合做动态决策模型,来判断人类是说完了还是在思考,等对方表述结束,再去接话。
恭而有礼,莫过于此。
一般人认为客服不就是对话机器人,有语言文字能力强的大模型,情况并非如此。
京东需要多模态大模型。
在京东,有400电话(声音);有商品照片(图片);有安装指南(视频);有好评如潮(文字)。
模态是一种学术词汇,更准确而久远的来源是和“信号”相关的。简单理解,不同种类的数据就是“模态”。
这些多模态信息,需要多模态大模型来处理。
所以,不用好奇京东这里会成长出什么样的大模型。多模态是一个顺承并满足业务场景需求的技术路线,以此类推到与京东密切相关的产业,比如零售,比如金融。
京东科技智能服务与产品部门的出现,就是因为京东日益增长的客服业务需要一支专门的技术团队,把内部所有的客服单独拿出来用“智能”来解决。多年以来,陆续将技术和能力沉淀成一个可用的产品能力平台,就是言犀平台。
“我们平台(京东云言犀人工智能应用平台)有40多个独立子系统,3000多个意图和3000万个高质量问答知识点。”何晓冬团队的吴博士说。
京东全量智能服务的技术经验,加上在京东零售、物流、健康等多类业务的多年实践,体量做到了日均千万次智能交互。
谈笑间,那些轻量化模型任务(信息抽取、语音识别、方言语音识别、关键词识别、语义识别、情感分析)早已“拿下”。
京东生意额增长,带来“三高”要求:真实场景要求高,用户体验要求高,大规模服务要求高。
所以,高难度的技术问题内部早已入手研发,内容生成,复杂语义理解或意图识别,多轮对话决策推理都是重点。
何晓冬博士是自然语言处理和跨模态智能领域极具影响力的科学家。在AI2000人工智能全球最具影响力学者榜单中,同时入选三个领域(NLP、Speech、IR),为全球60人之一。
他是教授,也是IEEE Fellow,他虽然有极强的学术背景,但特别重视技术的应用前景。何晓冬团队的技术领域的积累建立在200余篇学术论文、近4万次学术论文引用、5.8亿用户真实场景的练兵场上。对于有能力挑战的人来说,难度越高,能把技术水平提得更高。
2023年5月6日,第十二届吴文俊人工智能科学技术奖正式公布,京东云言犀团队凭“任务型智能对话交互关键技术及大规模产业应用”,斩获吴文俊人工智能科学技术奖科技进步奖。
“产生了逾20亿元的直接经济效益和良好的社会效益,促进了零售、物流、金融、政务等相关产业的快速发展。” 组委会点评。
与此同时,何晓冬博士获得了吴文俊人工智能科学技术奖杰出贡献奖。
“他的耐心是一种鼓励。”
“他擅长指明方向,总是能在讨论中找到问题的本质,帮助我们打开思路。”何晓冬博士麾下的吴博士、范博士这样评价道。
京东对人工智能大模型的布局可以从一个个前沿酷炫的实验室名称中洞见。那些研究员们有些来自图生文实验室,有些来自基础模型与系统实验室,有些来自跨模态视觉生成实验室,未来还会来自机械智能实验室。这里鼓励探索,策励探讨,不欢迎施号发令、刻板短视。
回到文章开头第一句。
在大模型的技术路线之争这件举足轻重的事情上,到底是Decode-Only胜出,还是Encode-Decode胜出,任谁目前也不能草率得出结论。
虽然目前走Decode-Only路线的大模型GPT-4暂时领先,可保不齐谷歌哪天逆风翻盘,大大书写一笔《谷歌战微软:AI大模型反转史》。

何晓冬与言犀团队对发展产业大模型的三个条件是这样理解的:
第一,看得懂,懂业务逻辑。
垂直的场景自有壁垒,懂业务,懂行业,一步步弄懂。
第二,摸得到,运营了业务才会有数据,进而喂给大模型,发展出特有的能力。
第三,数据飞轮转起来,有反馈再优化的循环。
这三点既是本质,又是限制。大模型制高点是强者之间的游戏,产业大模型与通用大模型的竞争优势来自于此。
得到产业的认知规律,从来都不容易:今天有多懂,昨天就有多艰难。
在一次次的错误中成长,将所有的经验导向理解与正确的结果。
每一次变革都有规律可循,从消费互联网到产业互联网的变革亦是如此。像京东这样的技术企业,有供应链思维的企业,那些年虽有优势但也不能保证稳胜。
京东相关内部人士也有类似观点:
虽然我们是做零售出身的,但每一次进入零售细分领域,也是从头学习。早期做家电,后来做生鲜(7FRESH),再次出发做大量的线下零售,摸爬滚打。零售是一个巨大的场景,每一个赛道都是不一样的,都有单独的解决方案。深入行业不能仅靠想象力,浮泛的议论好发却无用。
“用通用数据把大模型常识能力训练足够,再用精准,少量的行业数据,最终以产业大模型的形式提供给产业。” 何晓冬博士说。
当技术和意义都存在,何晓冬与言犀团队如何理解大模型与上层应用的关系?
数据依然在大模型的发展中占据无以复加的重要地位,这无疑会增加产业大模型的竞争优势。大模型是迄今为止人类最高智能的AI原生产品,有实力颠覆SaaS层现有生态。
在所有的科技企业中,京东在零售产业和零售供应链实力最为雄厚,他们理解零售业的高度动态极其需要敏捷推动,他们理解零售以SaaS的形式提供服务最为合适。
产业需求的共性可以提炼,数智供应链的能力可以复制,数百个场景都会得到赋能。
比如,农产品和电商的关系日益紧密,搜索关键词“产地+特色农产品”,在京东APP消费者TOP搜索热词中,连续四年持续增长。
近5年,地标农产品消费金额年均增长36%,高于农产品整体增速4个百分点;地标生鲜农产品消费金额年均增长41%,高于生鲜农产品整体增速7个百分点。
销量的增长需要高效供应链与先进营销方式,这也是京东产业大模型未来落地的重点方向之一。
离需求最近的人,最有机会。京东在产业大模型的加持下,有机会生长出一个市值等同于Salesforce的龙头企业。
从某种程度上讲,Salesforce是一家定义了SaaS的公司。有了美国Salesforce,才有了SaaS。
在产业大模型上,每一个人都可以通过SaaS套件,不仅是开商店、做生意,而是把各个行业的销售和服务做好。从货到钱的支付物流,从后端客服到前台导购营销,有全生命用户全生命周期管理服务。并且,不但有自己的SaaS产品(模块),还要建一个允许第三方开发的平台。这样才能把产业大模型的生态真正做起来。
产业随着社会分工的发展而发展,垂直产业中成千上万个企业未来一定会用大模型。谁来做?
良机在望,来者可追。
-结束-

更多阅读
AI框架系列:
1.搞深度学习框架的那帮人,不是疯子,就是骗子(一)
2.搞AI框架那帮人丨燎原火,贾扬清(二)
3.搞 AI 框架那帮人(三):狂热的 AlphaFold 和沉默的中国科学家
4.搞 AI 框架那帮人(四):AI 框架前传,大数据系统往事
注:(三)和(四)现在并未公开发表,将会以图书出版的形式与各位见面。
漫画系列
1. 解读硅谷风投A16Z“50强”数据公司榜单
2. AI算法是兄弟,AI运维不是兄弟吗?
3. 大数据的社交牛逼症是怎么得的?
4. AI for Science这事,到底“科学不科学”?
5. 想帮数学家,AI算老几?
6. 给王心凌打Call的,原来是神奇的智能湖仓
7. 原来,知识图谱是“找关系”的摇钱树?
8. 为什么图计算能正面硬刚黑色产业薅羊毛?
9. AutoML:攒钱买个“调参侠机器人”?
10. AutoML:你爱吃的火锅底料,是机器人自动进货
11. 强化学习:人工智能下象棋,走一步,能看几步?
12. 时序数据库:好险,差一点没挤进工业制造的高端局
13. 主动学习:人工智能居然被PUA了?
14. 云计算Serverless:一支穿云箭,千军万马来相见
15. 数据中心网络:数据还有5纳秒抵达战场
16. 迟到不可怕,可怕的是别人都没迟到, 数据中心网络“卷”AI:
17. 是喜,还是悲?AI竟帮我们把Office破活干完了
AI大模型与ChatGPT系列:
18. ChatGPT大火,如何成立一家AIGC公司,然后搞钱?
19. ChatGPT:绝不欺负文科生
20. ChatGPT触类旁通的学习能力如何而来?
21. 独家丨从大神Alex Smola与李沐离职AWS创业融资顺利,回看ChatGPT大模型时代“底层武器”演进
22. 独家丨前美团联合创始人王慧文“正在收购”国产AI框架OneFlow,光年之外欲添新大将
23. ChatGPT大模型用于刑侦破案只能是虚构故事吗?
24. 大模型“云上经济”之权力游戏
25. 深聊丨第四范式陈雨强:如何用AI大模型打开万亿规模传统软件市场?
26. 云从科技从容大模型:大模型和AI平台什么关系?为什么造行业大模型?
DPU芯片系列:
1. 造DPU芯片,如梦幻泡影?丨虚构短篇小说
2. 永远不要投资DPU?
3. DPU加持下的阿里云如何做加密计算?
4. 哎呦CPU,您可别累着,兄弟CIPU在云上帮把手
长文系列:
1. 我怀疑京东神秘部门Y,悟出智能供应链真相了
2. 超级计算机与人工智能:大国超算,无人领航


最后,再介绍一下主编自己吧,
我是谭婧,科技和科普题材作者。
为了在时代中发现故事,
我围追科技大神,堵截科技公司。
偶尔写小说,画漫画。
生命短暂,不走捷径。
原创不易,多谢转发
还想看我的文章,就关注“亲爱的数据”。