文章目录
- 前言
- 一、聚合查询
- 1, 聚合函数
- 2, 聚合函数使用示例
- 3, GROUP BY 子句
- 4, HAVING 子句
- 二、联合查询(重点)
- 1, 笛卡尔积
- 2, 内连接
- 2.1, 示例1
- 2.2, 示例2
- 2.3, 示例3
- 3, 外连接
- 4, 自连接
- 总结
前言
各位读者好, 我是小陈, 这是我的个人主页, 希望我的专栏能够帮助到你:
📕 JavaSE基础: 基础语法, 类和对象, 封装继承多态, 接口, 综合小练习图书管理系统等
📗 Java数据结构: 顺序表, 链表, 堆, 二叉树, 二叉搜索树, 哈希表等
📘 JavaEE初阶: 多线程, 网络编程, TCP/IP协议, HTTP协议, Tomcat, Servlet, Linux, JVM等(正在持续更新)
从本篇开始介绍 MySQL 数据库的相关知识

提示:是正在努力进步的小菜鸟一只,如有大佬发现文章欠佳之处欢迎批评指点~ 废话不多说,直接上干货!
一、聚合查询
1, 聚合函数
常见的统计总数、计算平均值等操作,可以使用聚合函数来实现,常见的聚合函数有 :
| 函数 | 说明 |
|---|---|
| COUNT() | 返回查询到的数据的数量 |
| SUM() | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG() | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX() | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN() | 返回查询到的数据的 最小值,不是数字没有意义 |
这些聚合函数都是针对多个行的运算
2, 聚合函数使用示例
sql 语句 : select 聚合函数(列名) from 表名
- 首先准备一张考试成绩表
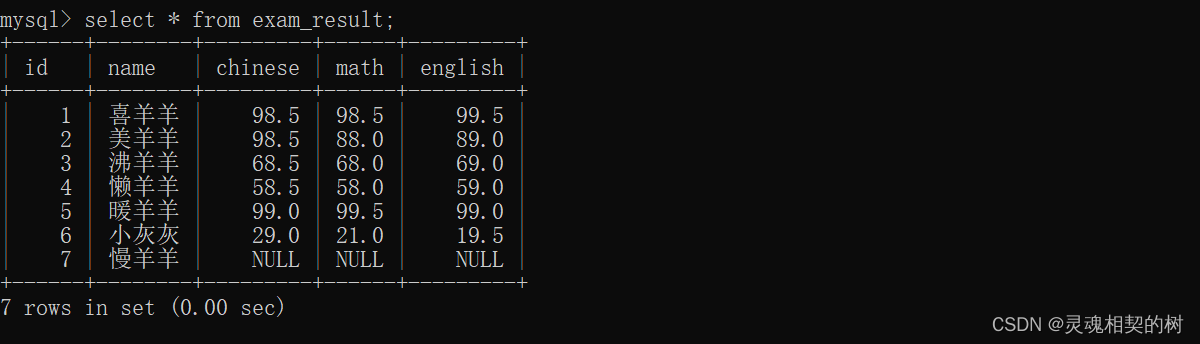
- 查询表中记录的人数

- 查询表中记录的语文成绩的个数, 只能查到 6 个, 因为慢羊羊的成绩为 null , 不计入查询结果

- 查询全班语文成绩的总和

在 MySQL 中, 任何数和 null 做运算的结果还是 null , 但是这里求 sum 计算总和时, 已经把 null 过滤掉了, 所以结果并非为 null
-
查询语文成绩的平均分

-
参数也可以是表达式, 比如查询全班同学的平均总分

-
查询总分最高的是多少

-
查询总分最低的是多少

这些聚合函数能比较方便的实现简单逻辑的运算, 逻辑太过于复杂的 sql 也不是不能写, 但是会导致查询的效率极慢, 建议借助 Java 或其他编程语言来实现
3, GROUP BY 子句
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。
-
先准备一张学生表(id, 姓名, 数学成绩, 角色)

-
按照角色进行分组之后, 查询每组的人数
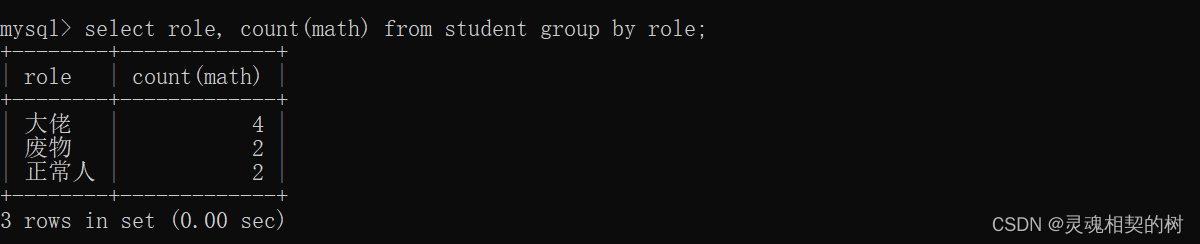
-
按照角色进行分组之后, 查询每组的平均数学成绩

分组查询需要满足:使用 GROUP BY 时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
- 反例 : 在 select 语句中多加一个id 字段, 虽然可以在临时表中显示出来, 但没有任何意义

4, HAVING 子句
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用 HAVING
比如刚刚查询每组的数学平均分时, 不想看到"废物组"的记录, 只想要两组, 这就需要一定的手段把"废物组"过滤掉

分组前的过滤使用 where , 分组后的过滤使用 having
二、联合查询(重点)
之前所有的查询都是基于一张表进行单表查询, 实际使用 sql 进行查询数据时, 往往是多张表进行多表查询, 联合查询是对多张表的数据取笛卡尔积
当需要查询的关键信息处在多张表时, 就需要把关键信息所在的表联合成一张表再查询
1, 笛卡尔积
对两张表(多张表)的数据进行笛卡尔积运算, 运算的过程就是对这两张表(多张表)每行的数据进行排列组合, 如图 :
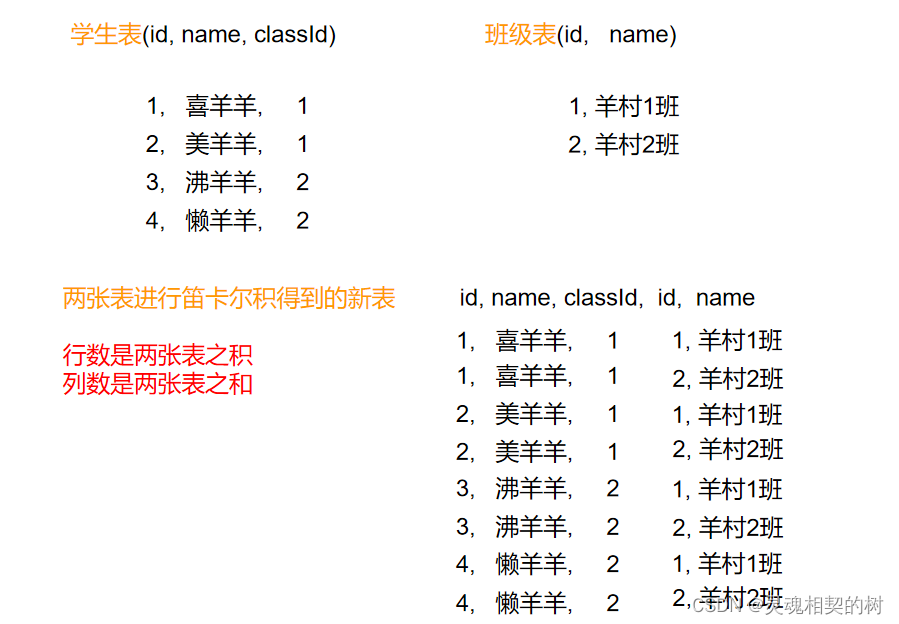
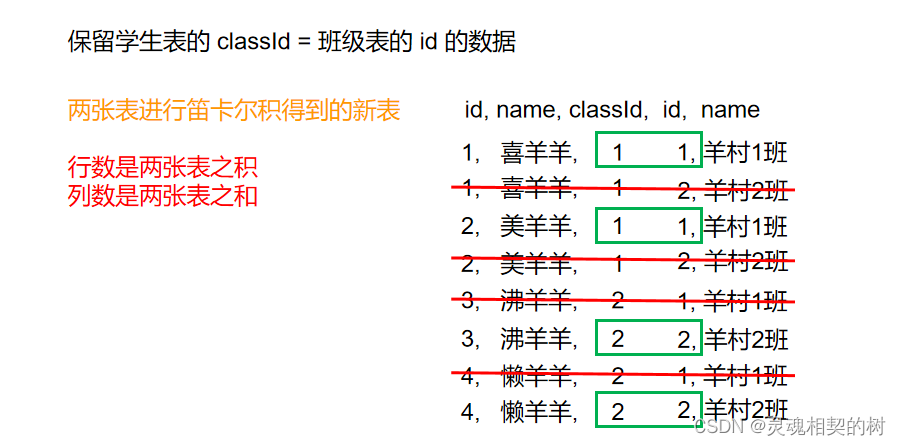
虽然笛卡尔积之后表中的数据很多, 但是包含无效信息, 只有学生表中的 classId 和班级表中的 id 相同时, 该条数据才是有意义的, 所以在进行多表查询时, 首先要对笛卡尔积的结果进行过滤
2, 内连接
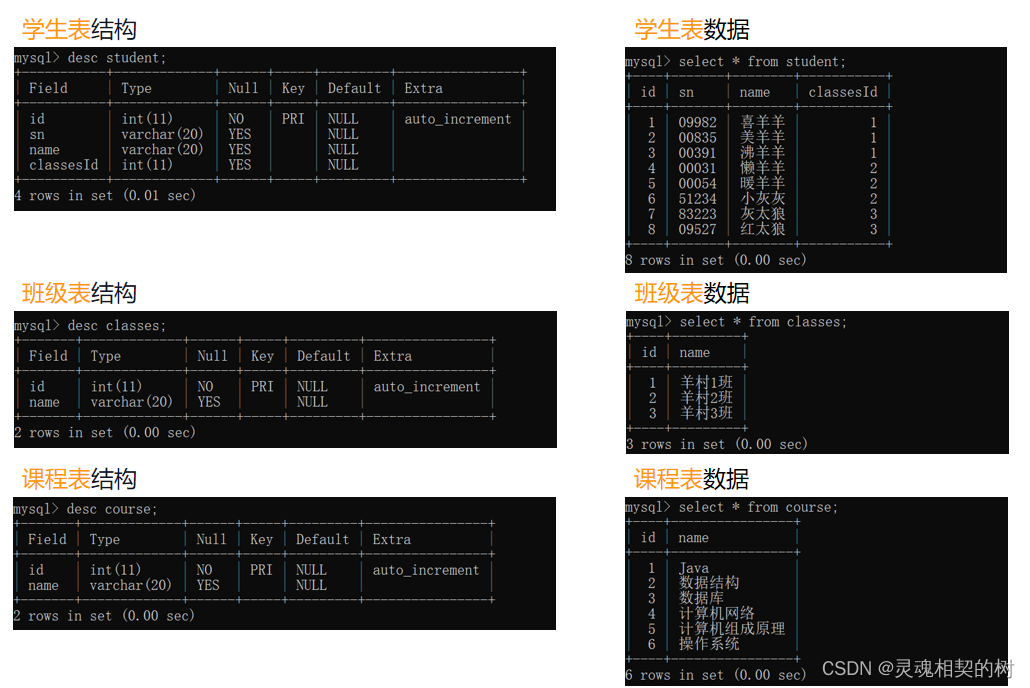
首先创建四张表, 代码如下 :
drop table if exists classes;
drop table if exists student;
drop table if exists course;
drop table if exists score;
create table student (id int primary key auto_increment, sn varchar(20), name varchar(20), classesId int);
create table classes (id int primary key auto_increment, name varchar(20));
create table course(id int primary key auto_increment, name varchar(20));
create table score(score decimal(3, 1), studentId int, courseId int);
insert into classes(name) values
('羊村1班'),
('羊村2班'),
('羊村3班');
insert into student(sn, name, classesId) values
('09982', '喜羊羊', 1),
('00835', '美羊羊', 1),
('00391', '沸羊羊', 1),
('00031', '懒羊羊', 2),
('00054', '暖羊羊', 2),
('51234', '小灰灰', 2),
('83223', '灰太狼', 3),
('09527', '红太狼', 3);
insert into course(name) values
('Java'), ('数据结构'), ('数据库'), ('计算机网络'), ('计算机组成原理'), ('操作系统');
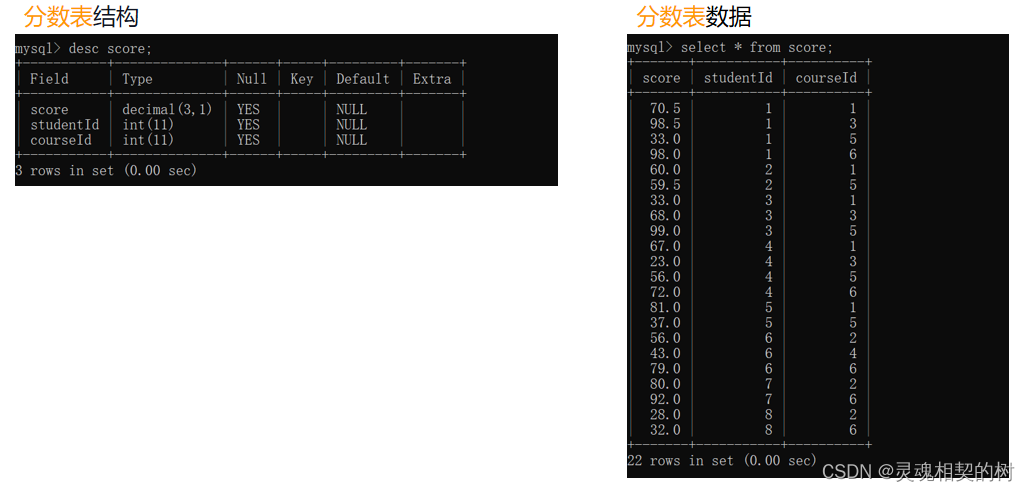
insert into score(score, studentId, courseId) values
-- 喜羊羊
(70.5, 1, 1), (98.5, 1, 3), (33, 1, 5), (98, 1, 6),
-- 美羊羊
(60, 2, 1), (59.5, 2, 5),
-- 沸羊羊
(33, 3, 1), (68, 3, 3), (99, 3, 5),
-- 懒羊羊
(67, 4, 1), (23, 4, 3), (56, 4, 5), (72, 4, 6),
-- 暖羊羊
(81, 5, 1), (37, 5, 5),
-- 小灰灰
(56, 6, 2), (43, 6, 4), (79, 6, 6),
-- 灰太狼
(80, 7, 2), (92, 7, 6),
-- 灰太狼
(28, 8, 2), (32, 8, 6);
2.1, 示例1
查询"喜羊羊"的成绩
- 学生表中有学生信息, 分数表中有成绩信息, 所以用这两张表做笛卡尔积 :
sql 语句 :select * from 表1, 表2;
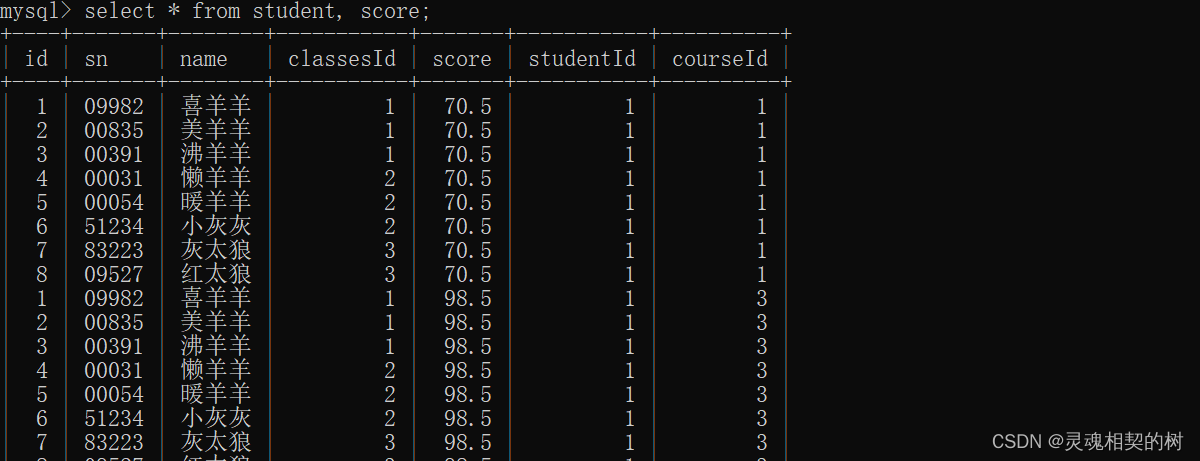
- 总共有176条数据, 需要进行过滤, 只有学生表中的 id = 分数表中的 studentId 时, 数据有效, 所以加上 where 条件:
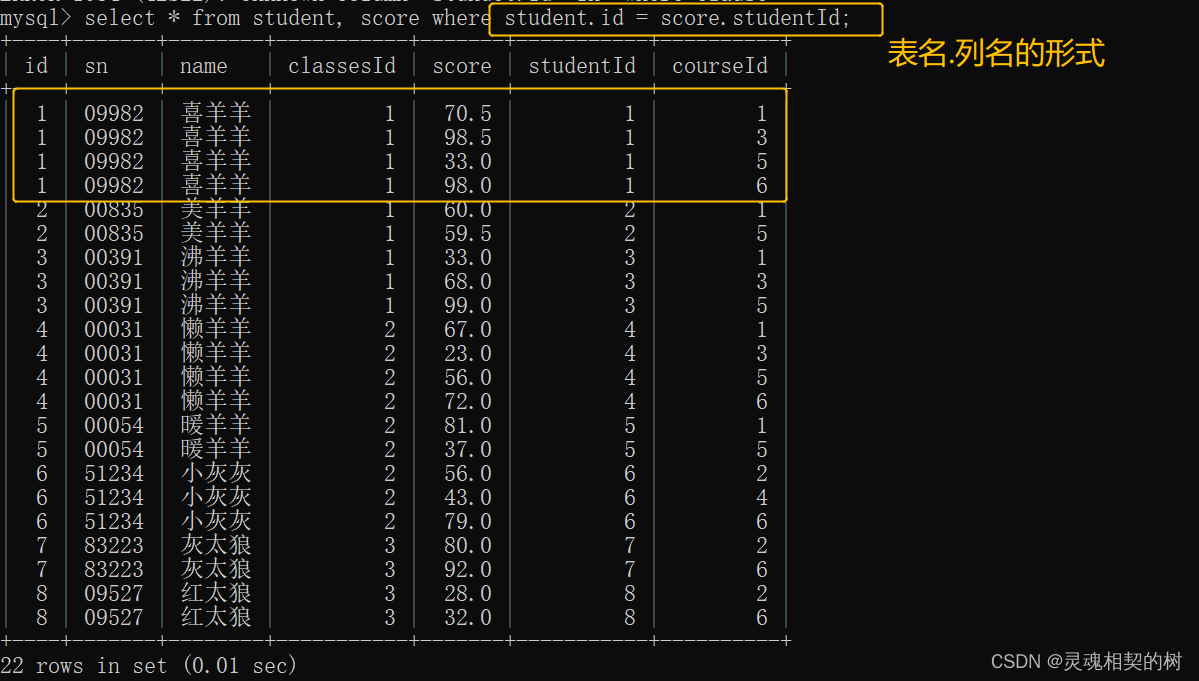
建议多表查询时, 使用
表名.列名的方式, 因为在不同的表中可能存在相同的列名
- 加上 where 条件之后 17 6行只剩下了 22 行, 但是我们只需要喜羊羊的成绩, 所以使用 and 再加一个条件, 过滤不需要的数据 :
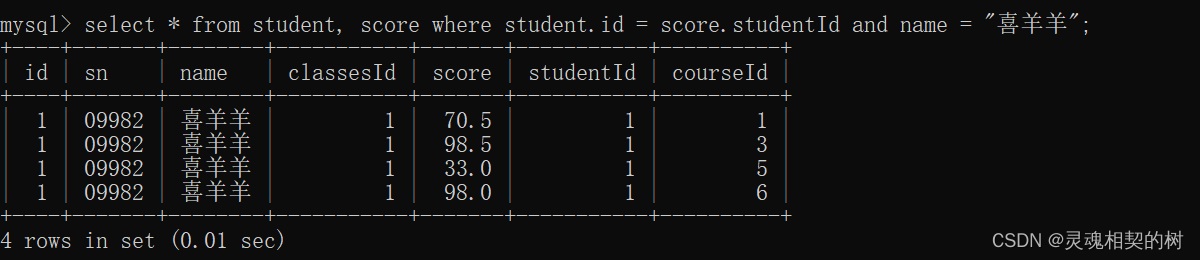
- 列的信息还比较多, 所以使用指定列查询, 再进一步过滤 :
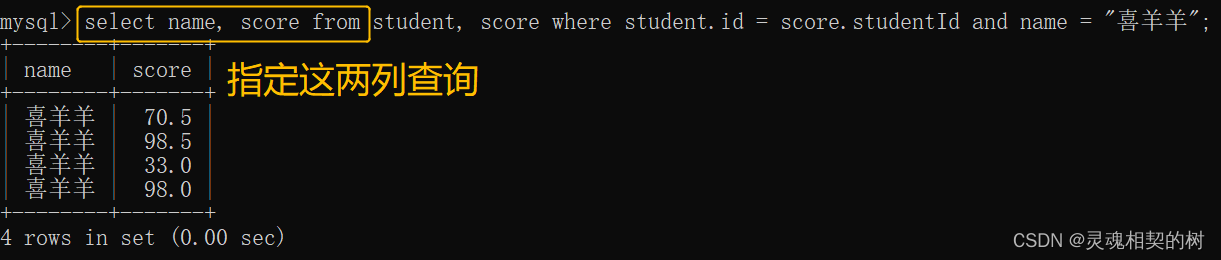
联合查询有两种语法 :
1,select * from 表1, 表2 where 条件;
2,select * from 表1 join 表2 on 条件;
(join 代替逗号, on 代替 where)
2.2, 示例2
查询全班同学的总成绩
还是刚才的四张表 :
- 还是学生表和成绩表做笛卡尔积
通过学生表的 id 和成绩表的 studentId 进行条件查询, 得到每个同学的成绩信息 :
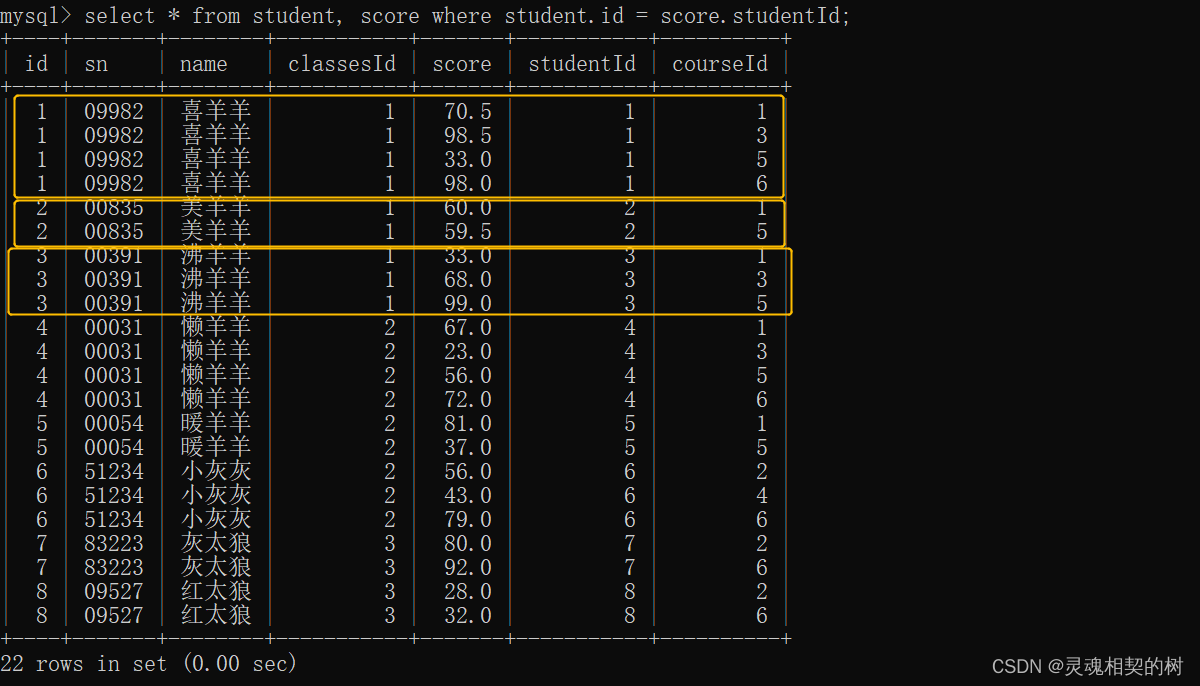
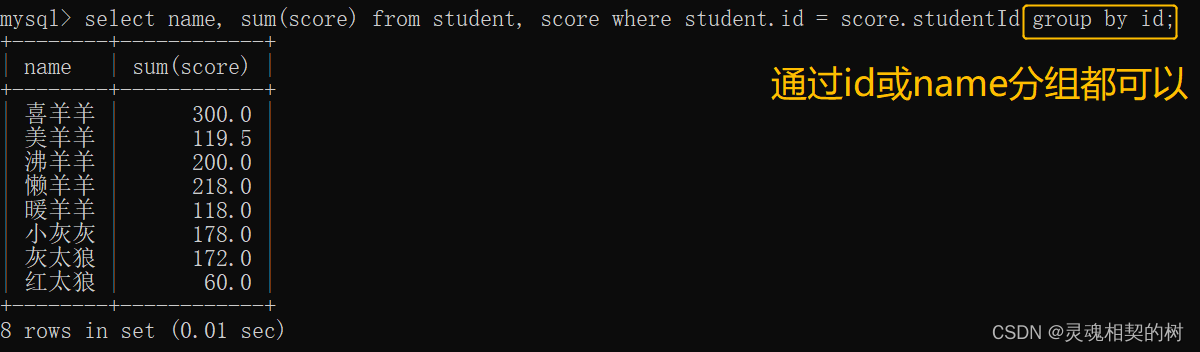
- 再针对每个同学的成绩进行聚合查询(sum求和)
别忘了需要加上 group by 子句 :
2.3, 示例3
查询同学们的成绩和课程信息
还是刚才的四张表 :
- 同学的成绩和课程信息, 关键信息分别在学生表, 分数表和课程表中, 所以需要三张表进行联合查询, 这就要两个 where 条件让三张表两两关联
1, 学生表的 id = 成绩表的 studentId
2, 成绩表的 courseId = 课程表的 id
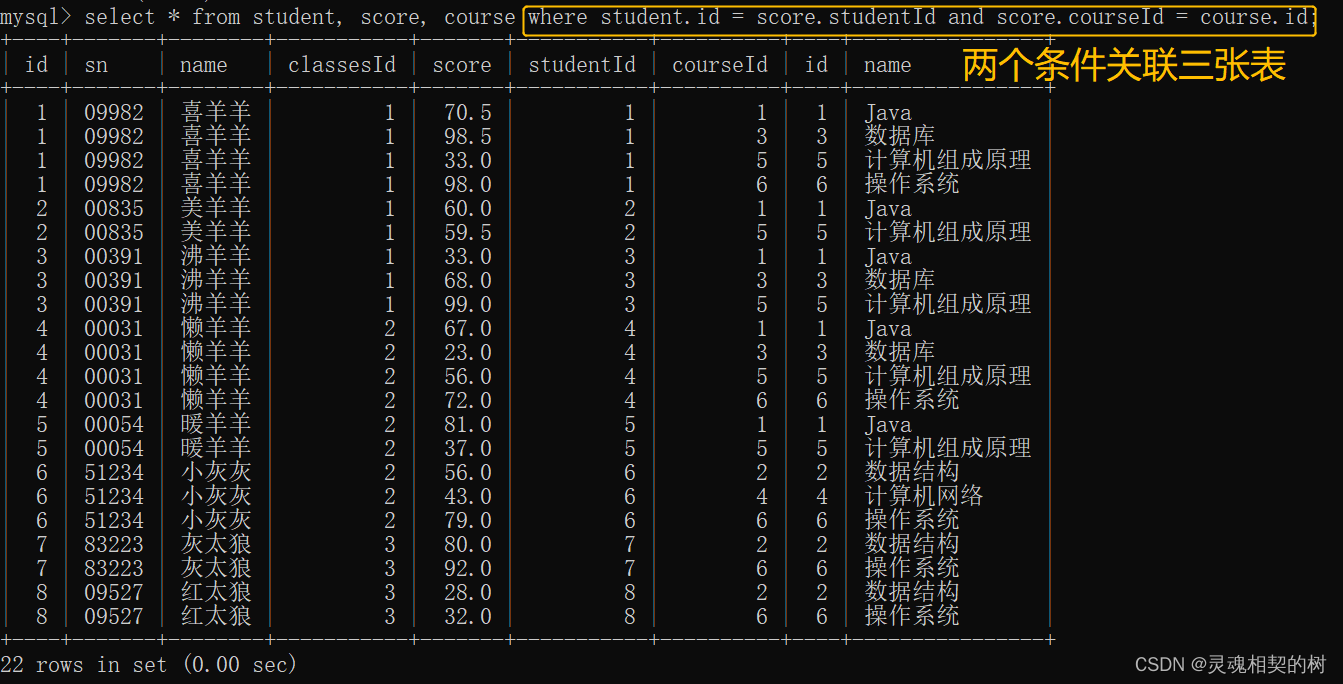
如果这句 sql 不加这两个条件, 查询结果有1000多条记录, 如果每张表的数据都很多, 直接使用联合查询是非常恐怖的
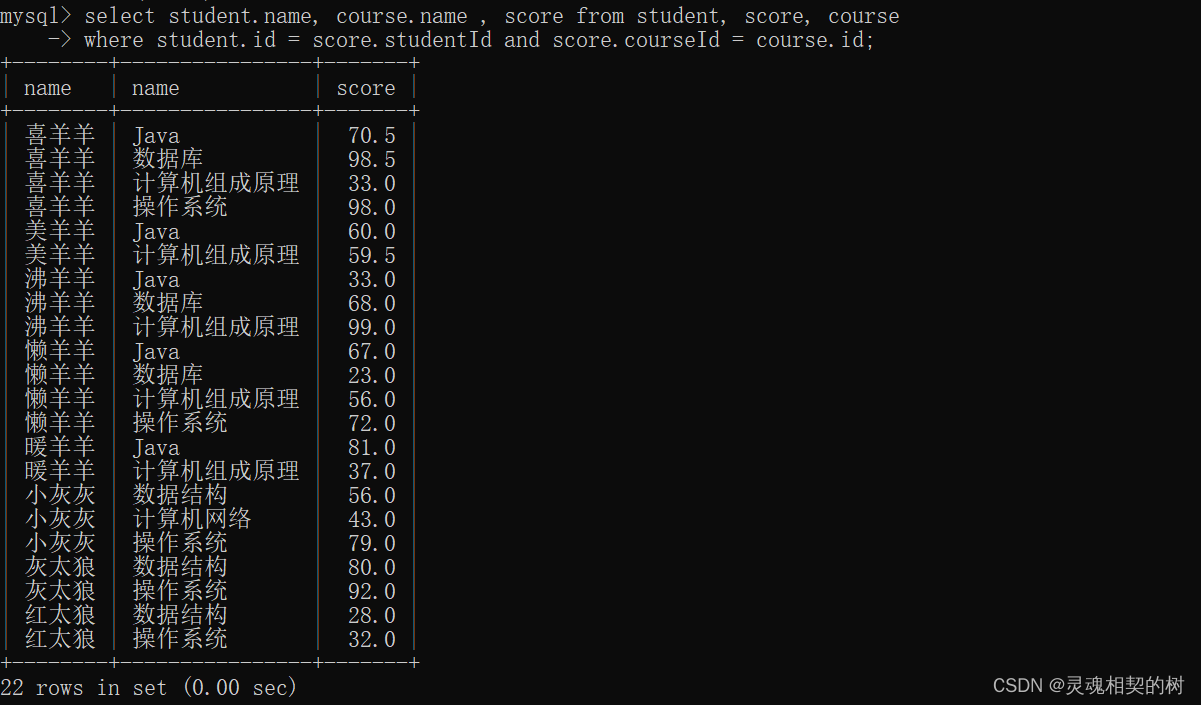
- 使用指定列查询, 过滤不需要的字段

3, 外连接
外连接分为左外连接和右外连接, 如果联合查询, 左侧的表完全显示我们就说是左外连接; 右侧的表完全显示我们就说是右外连接
当两张表的数据一一对应时, 内连接和外连接没有区别

接下来按照图中的表结构创建学生表和班级表
create table student(id int primary key auto_increment, name varchar(50), classId int);
create table class(id int primary key auto_increment, name varchar(50));
insert into student values
(1, "喜羊羊", 1),
(2, "美羊羊", 1),
(3, "沸羊羊", 3),
(4, "懒羊羊", 3);
insert into class values
(1, "羊村1班"),
(2, "羊村2班");
- 使用左外链接对学生表和班级表进行笛卡尔积
sql 语句 :select * from 表1 left join 表2 on 条件;表 1 为左表, 表 2 为右表
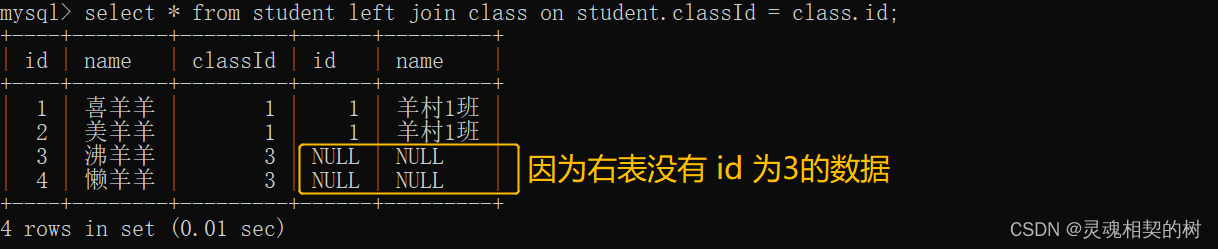
可以看到, 左外连接会以左边的表(学生表)为基准, 显示所有左表的数据, 如果某条数据没有在右表中存在, 显示为NULL
- 使用右外链接对学生表和班级表进行笛卡尔积
sql 语句 :select * from 表1 right join 表2 on 条件;表 1 为左表, 表 2 为右表

可以看到, 右外连接会以右边的表(班级表)为基准, 显示所有右表的数据, 如果某条数据没有在左表中存在, 显示为NULL
4, 自连接
自连接是指在同一张表连接自身进行查询, 比如要查询 java 成绩比数据库成绩高的同学都有谁, 如果 java 成绩和数据库成绩在一条记录中, 可以直接进行比较----列与列之间的比较
可是当前表中 java 成绩和数据库成绩不在同一行----需要行与行之间的比较

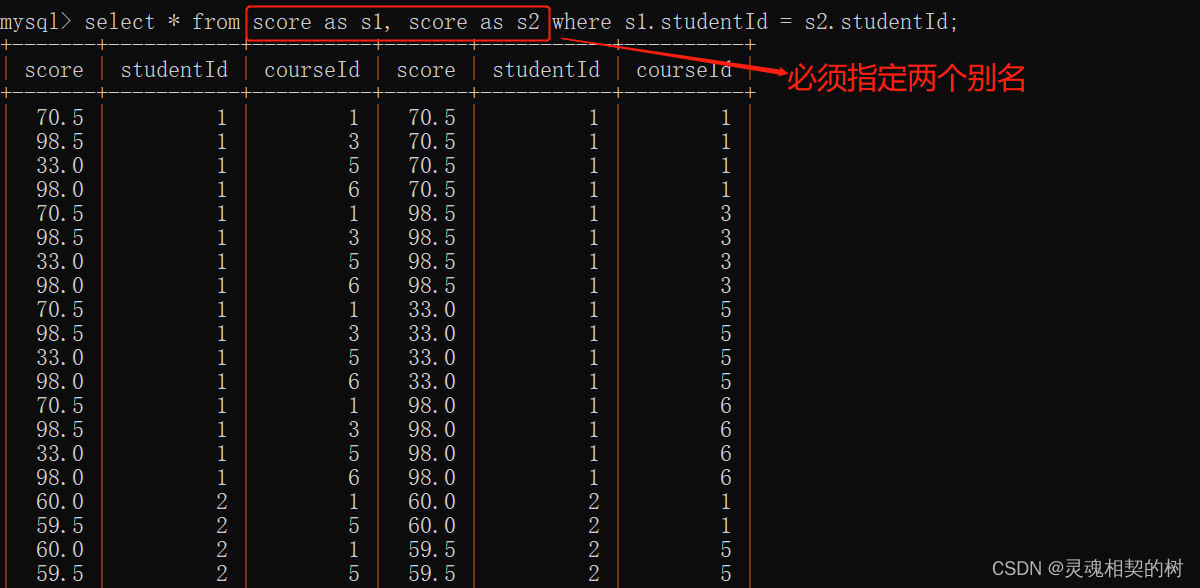
这就需要自连接, 让自己和自己进行笛卡尔积, 就能把行转化成列, 再进行列与列之间的比较了, 注意自连接必须给表分别指定两个别名
-
自链接sql 语句 :
select * from 表 as 别名1, 表 as 别名2;
再加上 where 条件过滤一部分无效数据
-
在笛卡尔积的这么多结果中, 一定有 s1 的课程 id 对应着 java , 并且 s2 的课程 id 对应着数据库, 但是我们的成绩表中只有课程 id, 没有课程名称, 所以在此之前先去查一下课程表

-
然后在刚刚的自链接的 sql 语句上使用 and 再加两个条件: s1.courseId = 1 和 s2.courseId = 3

-
现在 s1 中都是 java 成绩, s2 中都是数据库成绩, 只需最后一步 : 再使用 and 再加一个条件, 找到 s1 的成绩> s2 的成绩

终于找到了 studentId 为 4 的同学满足 java 成绩比数据库成绩高, 虽然查到结果了, 但可以看到这条记录中并不包含学生姓名, 还是不够直观
所以 sql 表达逻辑的能力是比较弱的, 对于逻辑比较复杂的查询, 还是不建议单独使用sql, 而是借助 java 等编程语言来实现
总结
以上就是本篇的全部内容, 主要介绍了 数据库中聚合查询和多表联合查询
这些是比较复杂的查询, 尤其是多表查询中的内连接, 外连接, 自连接
如果本篇对你有帮助,请点赞收藏支持一下,小手一抖就是对作者莫大的鼓励啦😋😋😋~
上山总比下山辛苦
下篇文章见