写这篇博客还是很激动开心的,因为是我经过两周的时间,查阅各个地方的资料,经过不断的代码修改,不断的上传到有显卡的服务器运行才得出的可行的接口调用解决方案,在这里记录并分享一下。
研究历程(只是感受,这段可以跳过,直接看下边的正题,找“正题”二字)
起初领导让我写一个接口——前端传递用户问题,后端返回ChatGLM模型生成的问题的答案。这个工作太简单了,因为GitHub上ChatGLM-6B根目录的api.py已经实现了,我只需改一个模型路径、端口号启动即可,我默默地更新了代码然后修改后启动运行了,然后摸了三天鱼,三天后和领导说完成了,深藏功与名。领导高兴地拿着我的接口文档就给其他部门的同事用了,结果没几天,同事就反馈说,这接口是http请求啊,前端一请求,后端带着问题去送入模型,这模型生成还需要时间,等完全生成了,服务端再返给前端,这期间用户一直等待,还没等返回结果,用户早生气的买套壳ChatGPT公司的服务了,谁还用你的ChatGLM?我当然知道接口慢了,而且返回时间和生成的文本长度成正比,这怎么办?用websocket?双向通信?这接口是python写的,我再研究一下python的websocket怎么写?当初干java一看websocket的代码就劝退——又臭又长,导致我现在都不会ws,所以我现学一下吗?不,不可能,我对ws过敏,我查了查ChatGPT是如何实现的,网上说是用SSE(Server-sent Events)实现的,我还问了一下ChatGPT,结果他嘴硬,说没有。。。
无语~,我用postman调了一下ChatGPT的api,发现返回的数据德行如下:
data: {"id":"cmpl-7Jy6ml72P6prTUU5mmtMGUsWBOgNY","object":"text_completion","created":1684993644,"choices":[{"text":"新","index":0,"logprobs":null,"finish_reason":null}],"model":"text-davinci-003"}
data: {"id":"cmpl-7Jy6ml72P6prTUU5mmtMGUsWBOgNY","object":"text_completion","created":1684993644,"choices":[{"text":"能","index":0,"logprobs":null,"finish_reason":null}],"model":"text-davinci-003"}
data: {"id":"cmpl-7Jy6ml72P6prTUU5mmtMGUsWBOgNY","object":"text_completion","created":1684993644,"choices":[{"text":"源","index":0,"logprobs":null,"finish_reason":null}],"model":"text-davinci-003"}
...<省略若干数据>
data: {"id":"cmpl-7Jy6ml72P6prTUU5mmtMGUsWBOgNY","object":"text_completion","created":1684993644,"choices":[{"text":"节","index":0,"logprobs":null,"finish_reason":null}],"model":"text-davinci-003"}
data: {"id":"cmpl-7Jy6ml72P6prTUU5mmtMGUsWBOgNY","object":"text_completion","created":1684993644,"choices":[{"text":"能","index":0,"logprobs":null,"finish_reason":null}],"model":"text-davinci-003"}
data: {"id":"cmpl-7Jy6ml72P6prTUU5mmtMGUsWBOgNY","object":"text_completion","created":1684993644,"choices":[{"text":"材","index":0,"logprobs":null,"finish_reason":null}],"model":"text-davinci-003"}
data: {"id":"cmpl-7Jy6ml72P6prTUU5mmtMGUsWBOgNY","object":"text_completion","created":1684993644,"choices":[{"text":"料","index":0,"logprobs":null,"finish_reason":null}],"model":"text-davinci-003"}
data: {"id":"cmpl-7Jy6ml72P6prTUU5mmtMGUsWBOgNY","object":"text_completion","created":1684993644,"choices":[{"text":"等","index":0,"logprobs":null,"finish_reason":"length"}],"model":"text-davinci-003"}
data: [DONE]
不用问,有用的字段就是text,猜也能猜出是前端拼接的这个字段的数据,组成一句话然后渲染。这里除了text字段,大家还要注意一下最后一行,data: [DONE],这个应该是要告诉前端,后端已经生成完毕,至于怎么用,前端小姐姐可能清楚。
那这个是不是SSE通信呢?不急,我们来小小写点SSE通信接口代码玩玩。
- 服务端
sse_test.py
import asyncio
import uvicorn, json, datetime
import uvicorn
from fastapi import FastAPI, Request
from fastapi.middleware.cors import CORSMiddleware
from sse_starlette.sse import ServerSentEvent, EventSourceResponse
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=False,
allow_methods=["*"],
allow_headers=["*"]
)
@app.get('/stream')
async def stream():
def generator():
for char in '李总是个大帅逼':
yield char
async def event_generator():
for i in generator():
now = datetime.datetime.now()
time = now.strftime("%Y-%m-%d %H:%M:%S")
yield {"data": {"data": i, "history": [], "finished": False, "time": time}}
await asyncio.sleep(1)
yield {"data": '[DONE]'}
return EventSourceResponse(event_generator())
if __name__ == '__main__':
uvicorn.run('sse_test:app', reload=True)
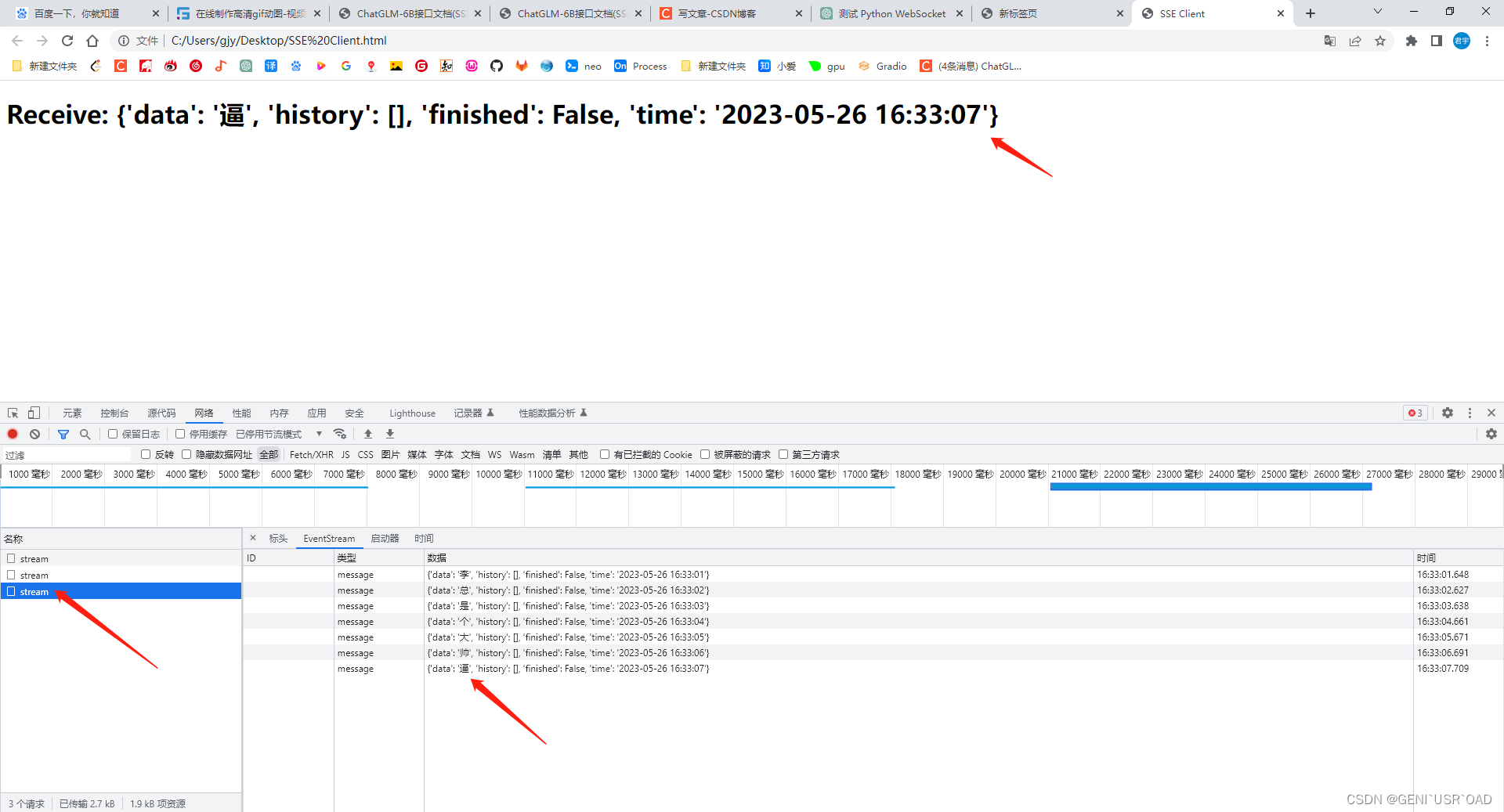
上述服务启动后,是可以直接用postman调用的,访问[get]http://localhost:8000/stream即可,结果如下:
data: {'data': '李', 'history': [], 'finished': False, 'time': '2023-05-26 15:35:14'}
data: {'data': '总', 'history': [], 'finished': False, 'time': '2023-05-26 15:35:15'}
data: {'data': '是', 'history': [], 'finished': False, 'time': '2023-05-26 15:35:16'}
data: {'data': '个', 'history': [], 'finished': False, 'time': '2023-05-26 15:35:17'}
data: {'data': '大', 'history': [], 'finished': False, 'time': '2023-05-26 15:35:18'}
data: {'data': '帅', 'history': [], 'finished': False, 'time': '2023-05-26 15:35:19'}
data: {'data': '逼', 'history': [], 'finished': False, 'time': '2023-05-26 15:35:20'}
data: [DONE]
看见没?“李总是个大帅逼!”不对没有叹号,不对李总不是大帅逼,不对,这不是重点,重点是看返回结构,是不是和ChatGPT返回的很像?我在代码里贴心的写下了yield {"data": '[DONE]'},返回结果还把[DONE]的引号去了。(哈哈,ChatGPT就是嘴硬,之前问他有没有用到知识图谱,他说用到了,过两三个月再问,他说没用到。。。再看ChatGLM代码,模型和接口突出一个清晰明了,哪有什么知识图谱?开箱即用)。
这里大家可能有疑问,postman请求接口后好像不是及时返回,还是后端一句话生成好返回的,postman还是等待了,没错,你没错,这个是postman的问题,有诗为证,不,有前端代码为证,我写了一点小前端来验证一下,如下:
- 客户端
SSE Client.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>SSE Client</title>
</head>
<body>
<h1>Receive: <span id="sse"></span></h1>
<script>
const numberElement = document.getElementById("sse");
const source = new EventSource('http://localhost:8000/stream');
source.onmessage = (event) => {
numberElement.innerText = event.data;
};
source.onerror = (error) => {
console.error("SSE error:", error);
};
</script>
</body>
</html>
直接双击Chrome打开,自己看看屏幕上写着什么?“李总是个大帅逼!”不对没有叹号,不对李总不是大帅逼,不对,这不是重点,是不是像屏闪动画一样[doge]?
哈哈哈,闲话不多说,我们进入正题~
正题
1.SSE(Server-sent Events)

SSE的概念网上一大堆,不想复制粘贴,把ChatGPT的回答放在这里,重点标好了,我用大白话挑重点再说一遍:
- SSE是基于HTTP的,所以我们可以用http的方式去和服务端建立通信,这样少了一些学习成本(点名websocket java端代码又臭又长!)。
- 它是单向通信:即客户端向服务器建立连接后,服务器持续向客户端疯狂输出,(类似:李雷:“我爱你”,韩梅梅:“我爱你我爱你我爱你。。。
[DONE]-_-!!!”);
这个和websorket不同,websorket是双向通信,(类似:李雷:“我爱你”,韩梅梅:“我爱你”,李雷:“我爱你”,韩梅梅:“我爱你”,[forever~]”) - SSE返回的是事件流类型,事件流中包含标识符、类型、数据、注释,这些都是可选字段,上述案例中的事件流中只有数据,即data,完整的事件流示例如下:
id: 12345 # 标识符
event: update # 类型(值可以随便定义,想写什么写什么)
data: {"message": "Hello, SSE!"} # 数据(数据建议为json格式)
: This is a comment #注释(就是冒号开头)
2.ChatGLM的流式方法
(只描述探讨过程,查阅代码请移步ChatGLM-6B)
大家如果看过ChatGLM的api.py文件,会发现这个http接口中调用的是model.chat(),然后直接将生成的数据组成json返回给前端了。
这明显不是流式输出(起码和我刚才写的那段代码结构不像)。
然后我们再看下web_demo.py文件,这个用过ChatGLM的同学应该熟悉,官方提供的前端交互页面就是这个模块中的,其中用到的技术是Gradio(Gradio是什么东西我没细研究过,我个人认为是个和JSP差不多的视图层技术),重点可以看下Gradio在调用什么——predict()方法,在predict()方法中可以看到model.stream_chat(),不用问,见名知意,这个就是流式方法,而且是for循环迭代,最后yield产出每次迭代的结果,这和刚才我写的案例不谋而合。
好的,我们就用model.stream_chat()做文章,下面直接上代码。
3.ChatGLM之SSE通信
讲解请重点看代码中的注释
from fastapi import FastAPI, Request, Response
from transformers import AutoTokenizer, AutoModel
import uvicorn, json, datetime
import torch
from fastapi.middleware.cors import CORSMiddleware
from sse_starlette.sse import ServerSentEvent, EventSourceResponse
DEVICE = "cuda"
DEVICE_ID = "0"
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE
def torch_gc():
if torch.cuda.is_available():
with torch.cuda.device(CUDA_DEVICE):
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
app = FastAPI()
# 解决跨域问题
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=False,
allow_methods=["*"],
allow_headers=["*"]
)
@app.post("/stream")
async def stream(arg_dict: dict):
global model, tokenizer
async def generate():
prompt = arg_dict["prompt"]
history = arg_dict["history"]
# 仅向模型传入最近五组对话作为上下文,用于多轮对话语境。
# (若不想限制,可直接删去这行)
history = history[-5:]
# 记录上一次迭代后模型输出的文本长度,用于截断下次模型输出的文本,以便事件流逐字逐词输出
size = 0
# for循环调用流式方法
# 每次迭代response都比上一次多一个字或一个词
for response, history in model.stream_chat(tokenizer, prompt, history=history):
# 所以用上次记录的size去截取当前的response
word = response[size:]
# 更新当前response文本长度,用于下次迭代截断
size = len(response)
# 记录时间,不是重点
now = datetime.datetime.now()
time = now.strftime("%Y-%m-%d %H:%M:%S")
# 构造返回体
answer = {
"id": 0,
"time": time,
"text": word
}
# log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(word) + '"'
# print(log)
torch_gc()
# 这里注意,如果只是像ChatGPT一样只返回数据,只需返回一个键为"data",值为字典的字典即可;
#如果还想输出id、event、注释等,请使用ServerSentEvent类来封装,ServerSentEvent类使用有坑,后续补充或者评论区提问。
yield {"data": answer}
# 迭代结束,返回结束标识,用于前端处理
yield {"data": "[DONE]"}
return EventSourceResponse(generate())
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("<这里写模型存放目录>", trust_remote_code=True)
model = AutoModel.from_pretrained("<这里写模型存放目录>", trust_remote_code=True).half().cuda()
model.eval()
# 端口号自行修改
uvicorn.run(app, host='0.0.0.0', port=8011, workers=1)