🐱作者:一只大喵咪1201
🐱专栏:《C++学习》
🔥格言:你只管努力,剩下的交给时间!

异常
- 🥮异常
- 🍢自定义异常体系
- 🍢C++标准库的异常体系
- 🍢异常的优缺点
- 🥮总结
🥮异常
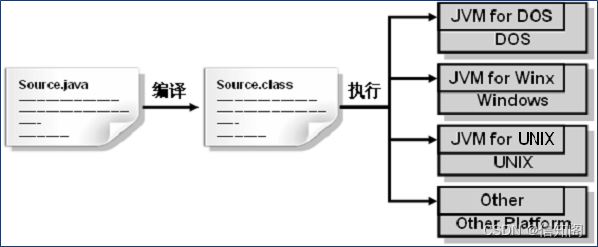
C语言传统处理错误的方式:
- 终止程序
比如空指针解引用,除0等异常发生时,程序会直接终止,但是这种方式对于用户来说难以接受,会导致整个进程挂掉。
- 返回错误码
比如打开文件,还有Linux中创建线程等C函数接口,调用后会返回一个返回值,如果发生错误会将错误码返回并放入到全局的errno中。
程序员需要自己去查找对应的错误,非常不直观。
C++异常概念:
- 异常也是一种处理错误的方式。
当一个函数发生异常后,就会将错误抛出,让该函数的直接或间接的调用者处理这个错误。
- throw:当问题出现时,程序会抛出一个异常,通过throw关键字完成。
- catch:在想要处理异常的地方,通过catch关键字捕获异常,然后执行相应的代码,可以有多个catch进行捕获。
- try:try块中的代码激活的异常才会被抛出,后面跟着的一个或者多个catch块才能捕获该异常。

写一个函数用来执行两个数相除,当除0时抛异常。
- throw抛出的异常必须是一个对象,可以是自定义类型的对象,也可以是内置类型的对象。

try块中的代码抛出异常,catch块捕获异常并处理。
- catch捕获异常时,会根据()中的"形参"匹配抛出对象的类型。
- 如果没有合适的catch匹配,"形参"为(…)的catch就会捕获抛出的异常。
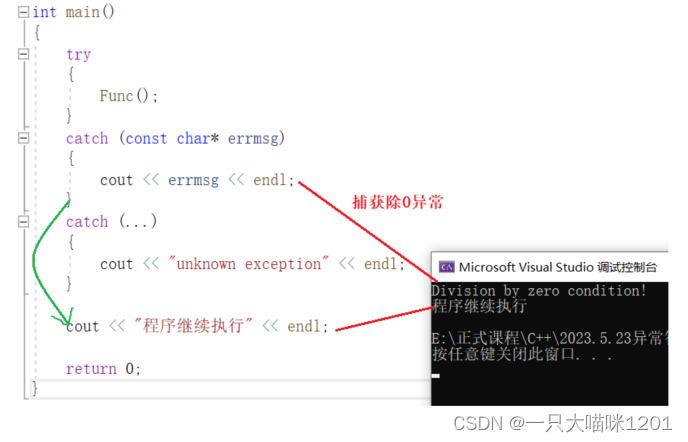
try块中抛出异常后,只有一个catch块会捕获异常,也只执行一个catch块代码,执行完后跳过所有catch块继续执行。
异常的抛出和匹配原则:
- 异常是通过抛出对象而引发的,该对象的类型决定了应该激活哪个catch的处理代码。
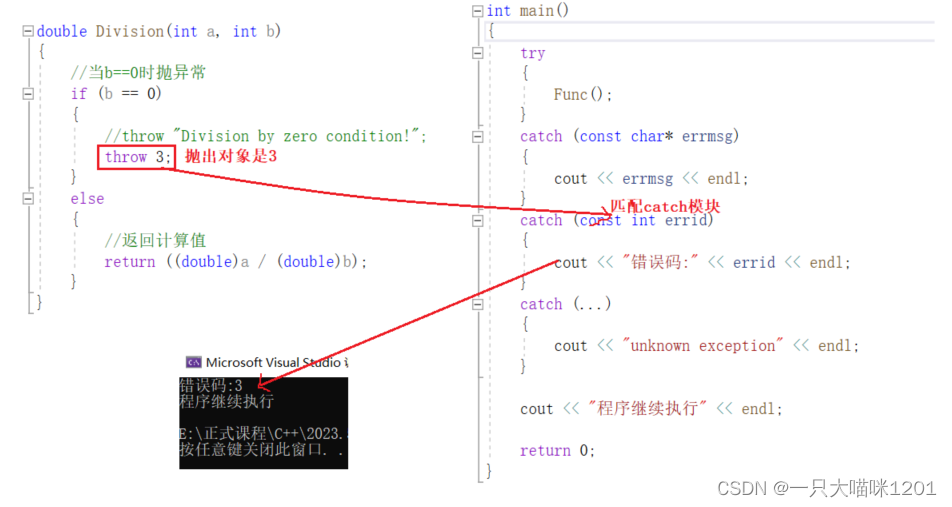
发生除0错误时,抛出的异常改成int类型对象。
- 抛出的异常只匹配了catch(const int errid)块,如上图所示。
- 被选中的处理代码(catch)是调用链中与抛出对象类型匹配且离抛出异常位置最近的那一个。
调用链:
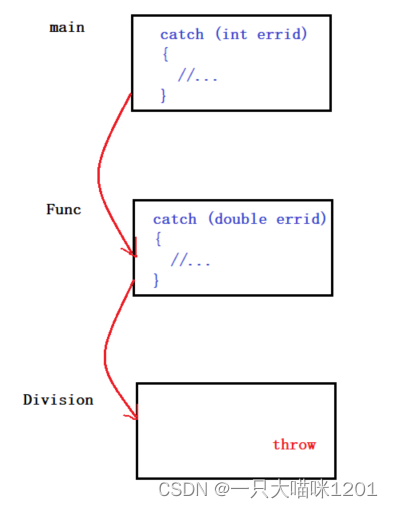
仍然是前面的代码,调用链是:
- main() → Func() → Division()。
所谓调用链就是函数栈帧创建的先后顺序,main函数的栈帧最先创建,然后调用Func函数并创建栈帧,再调用Division函数并传教函数栈帧。
- 在main函数中和Func函数中都有catch模块。
- 在Division中抛异常。
- Func中的catch距离抛异常的栈帧最近,但是并不匹配。
- 继续去上一层栈帧中(main函数)中匹配,main中的catch与抛出的异常类型相匹配。
catch可以写在任何一个抛出异常的当前或者上层栈帧中,当异常抛出以后,编译器会从离异常最近的栈帧中去匹配,匹配到了就执行处理代码,然后继续执行该栈帧catch后的代码。
- 不能匹配的栈帧就被直接销毁了,它后面的代码不会执行。
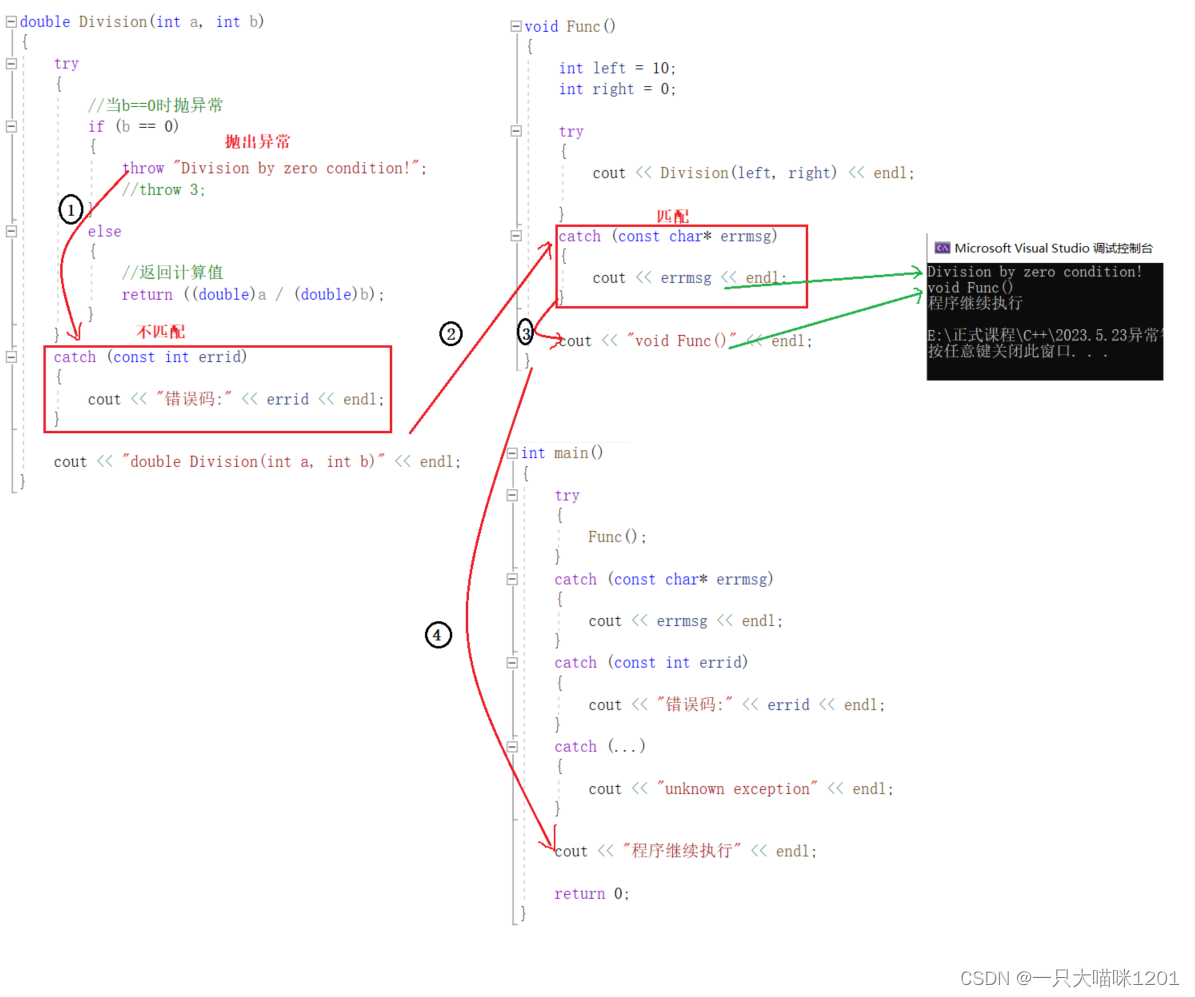
如上图所示代码:
- Division抛出异常,当前栈帧中的catch不匹配,直接跳出该函数栈帧,并销毁,所以后面的语句没有执行,如上图序号1所示。
- Division的上层Func栈帧中的catch与异常类型匹配,执行处理代码,如上图序号2所示,之后接着该栈帧catch后的代码执行,所以后面的语句执行了,如上图序号3所示。
- Func执行完毕后,栈帧销毁,再跳到main函数栈帧,由于异常已经捕获过了,所以直接跳过所有catch,执行后面的语句,如上图序号4所示。
catch和抛出异常不匹配时,会导致执行流乱跳。
- catch(…)可以捕获任意类型的异常,问题是不知道异常错误是什么
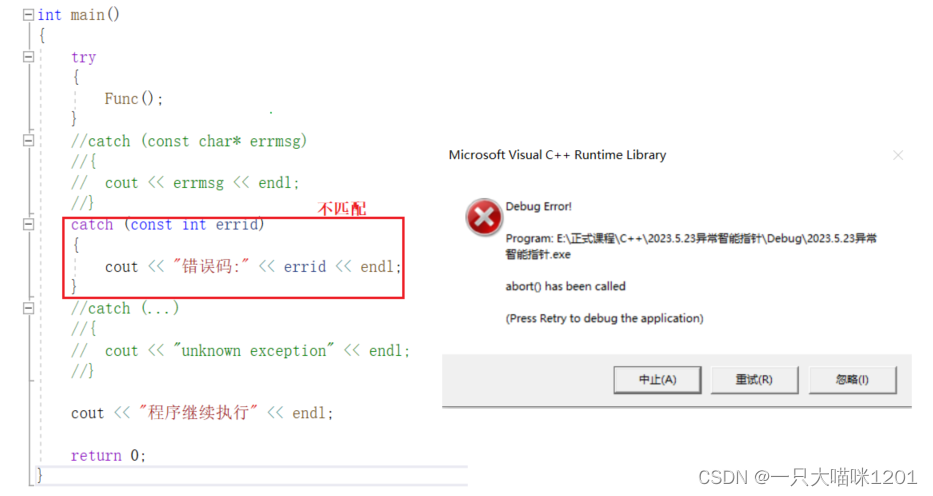
当抛出异常所有栈帧中的catch都无法匹配时,程序会直接报错并结束。
- 所以在main函数中要写一个catch(…)用来捕获所有异常。
当有匹配的catch时就不会匹配catch(…),只有具体的catch都不匹配时,才会匹配这个万能捕获。
- 但是并不知道这个捕获的异常是什么。
- 抛出异常对象后,会生成一个异常对象的拷贝,这是一个临时对象,临时对象会在被catch以后销毁(类似于函数的传值返回)。
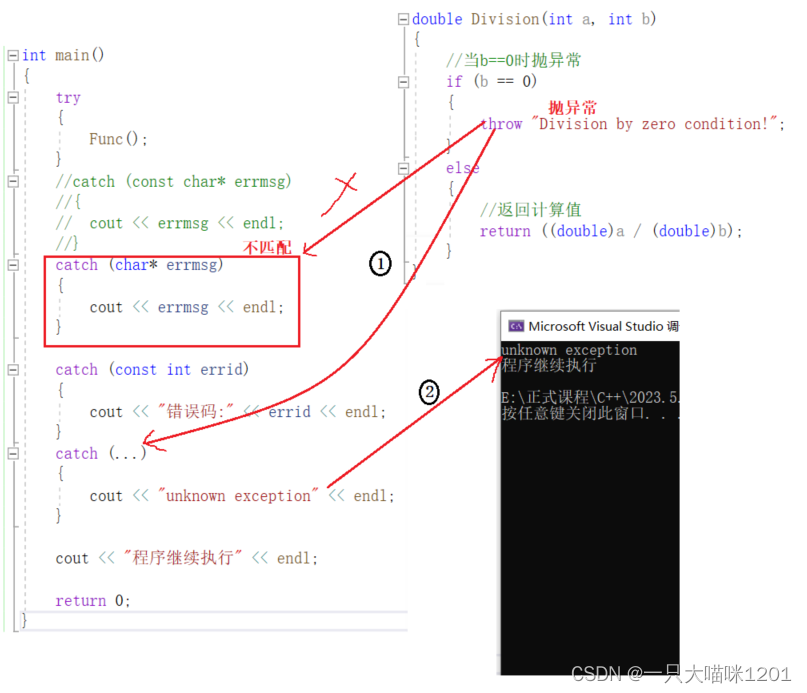
- Division抛出异常对象是“Division by zero condition”。
- main中catch(char* errmsg)没有匹配(如上图序号1所示),而是匹配了cach(…),如上图序号2所示。
- 抛出的异常对象是一个临时对象,类型是const char*类型。
- mian中的catch(char*)是char*类型,如果接收会导致权限放大,所以没有匹配。
说明:临时对象具有常性。
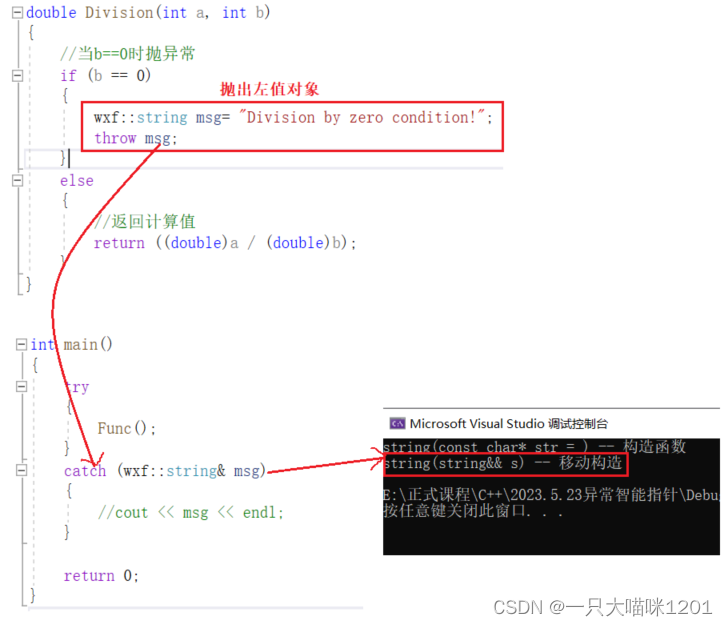
- 异常抛出一个左值对象,使用我们之前自己实现的string。
- catch捕获了这个对象,调用的是移动构造。
虽然抛出的是一个左值,但是这个左值是一个临时对象,在Division栈帧销毁的时候左值也会销毁。但是string中有移动构造,在main中捕获该对象时,直接进行了资源转移。
由于移动构造的存在,所以没有进行临时拷贝,如果没有移动构造,抛出的对象是会被拷贝一份的。
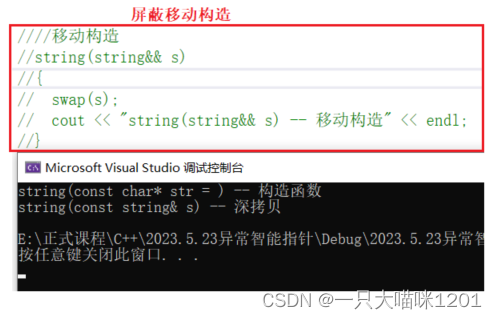
将string中的移动构造屏蔽以后,抛出的异常对象被拷贝了一份,所以调用了拷贝构造函数进行了深拷贝。
异常的重新抛出:

如上图代码所示,Division抛出异常后,在Func栈帧中捕获该异常。
- 但是我们想让所有异常在main函数中统一处理,比如记录日志等操作。
- 在Func中的catch中重新抛出捕获到的异常。
- throw后什么也不加表示重新抛出异常。
此时在Func中的catch都不用可以去匹配异常类型,凡是异常都捕获,然后重新抛出,让main函数中的catch再去匹配并进行相应处理。
异常安全和规范:
- 最好不要在构造函数中抛出异常,否则可能会导致对象不完整或者没有完全初始化。
- 最好不要在析构函数中抛出异常,否则可能导致资源泄漏。
在C++中异常经常会导致资源泄漏,比如在new和delete中抛出了异常,导致内存泄漏等等。
尤其是调用非常复杂的时候,后面写程序的人使用了前面程序的接口,但是并不知道前面程序的接口会抛异常,或者是抛什么异常,此时后面的程序员就无法处理抛出的异常,就可能导致资源泄漏等问题。
为了减少因为异常而导致的资源泄漏等问题,C++委员会提出了一套建议性规范:
- 在函数的后面接throw(类型),列出这个函数可能抛出的所有异常类型。
void func() throw(A, B, C, D);
表示这个函数会抛出A/B/C/D中的某种异常。
- 函数的后面接throw(),表示这个函数不抛异常。
void* operator delete(std::size_t size, void* ptr) throw();
表示这个函数不会抛异常。
-
若无异常接口声明,则此函数可能抛出任何类型的异常。
-
这个规范出发点是好的,可以让我们明确会抛出什么异常,进行相应的处理。
-
但是这个形式非常繁琐,throw(异常类型),有些异常类型是非常复杂的,为了写这个可能发生的异常类型,需要花费更多代价。
所以这个建议性的规范很少有人在用,因为它只是一个建议,所以不使用也不会报错。
为了让异常声明更加简洁,C++11对此做出了相应的改进:
- 在不会抛出异常的函数后加关键字:noexcept。
thread() noexcept;
thread(thread&& x) noexcept;
上面代码表示这个两个函数不会抛出异常。这样一来确实简洁了许多,只是在会抛异常的函数中,需要我们自己搞明白会抛什么异常。
- 之前的异常接口声明苦的是写程序的人,造福的是看程序的人。
- C++11中的noexcept苦的是看程序的人,造福的是写程序的人。
🍢自定义异常体系
实际使用中很多公司都会自定义自己的异常体系进行规范的异常管理,因为一个项目中如果大家随意抛异常,那么外层的调用者基本就没办法玩了,所以实际中都会定义一套继承的规范体系。这样大家抛出的都是继承的派生类对象,捕获一个基类就可以了。
- 实际中可以抛出异常的派生类对象,使用基类捕获。
这也是继承和多态的一个重要应用。

创建一个异常的基类,如上图所示,包含异常信息和异常编号两个成员。
- 打印异常信息的成员函数使用虚函数。

SQL模块也创建一个类用来表示异常信息,该类是一个派生类。只有一个派生成员,用来表示属于SQL的信息。
- 派生类中对打印异常信息的虚函数进行了重写,打印SQL的异常信息。

cache模块也创建一个类用来表示异常信息,该类是一个派生类,没有自己的成员。
-
派生类中对打印异常信息的虚函数进行了重写,打印Cache的异常信息。
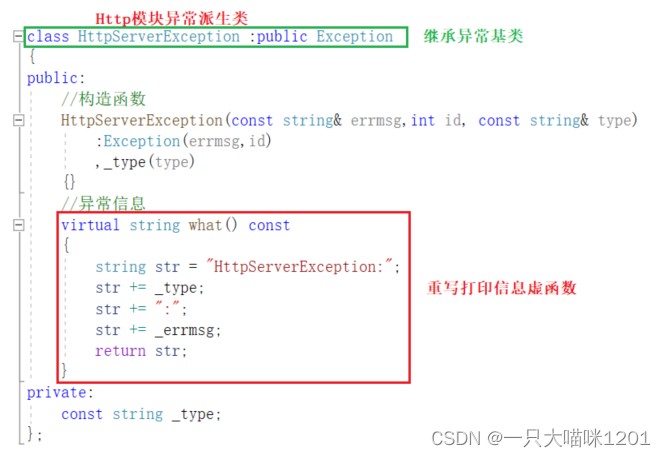
Http模块也创建一个描述异常的类,该类也是一个派生类,和SQL模块继承同一个基类,也只有一个成员,用来表示Http模块的异常信息。 -
同样也对打印异常信息的虚函数进行了重写。
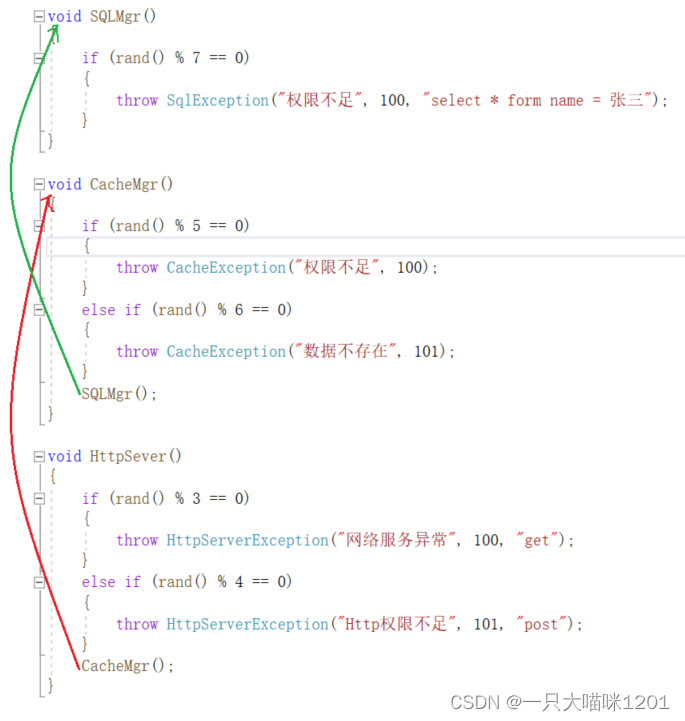
- 在HttpSever函数中,随机抛异常,异常对象是HttpSeverException类型的对象。
- 在CacheMgr函数中,随机抛异常,异常对象是CacheException类型的对象。
- 在SQPMgr函数中,随机抛异常,异常对象是SqlSeverException类型的对象。
抛出的异常是不同类型的对象,但是它们都是派生类,继承基类Exception。
当某个函数中抛出异常以后,后面的代码就不再执行了,直接去匹配相应的catch,当前栈帧中匹配不到就跳到上一层栈帧中去匹配。
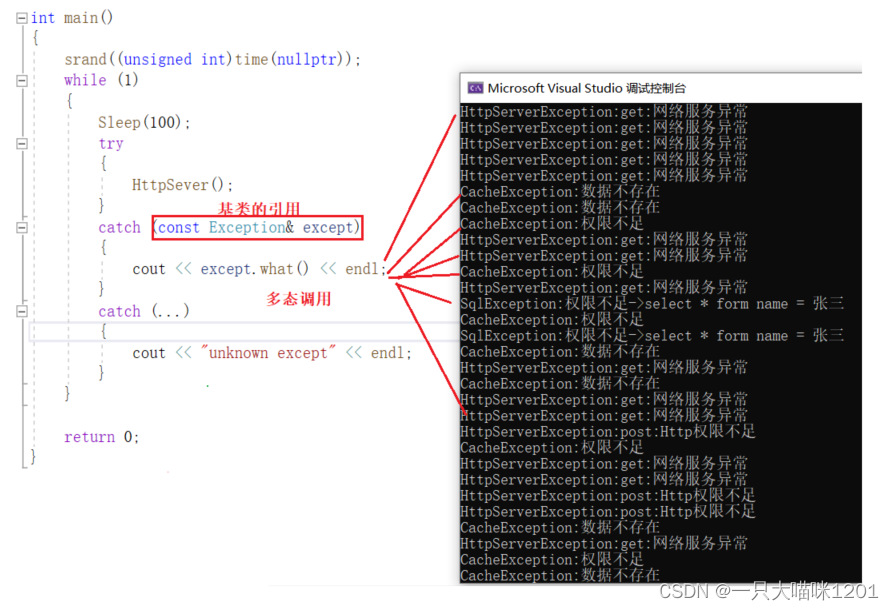
在main函数中,将try块和catch块放在死循环中,每隔0.1s执行一次。
- catch的类型是const Exception&,这是基类的引用。
catch的类型和所有抛出的异常对象都不是一个类型,但是它是所有异常对象基类的引用。
- 此时就实现了多态,调用的只是基类Exception中的成员函数what(),但是执行的逻辑就是派生类中what()的逻辑。
从这里也可以看出异常存在的意义:
拿我们经常使用的微信来举例,当网络不好的时候,消息就会发不出去,此时程序就会抛一个异常,表示当前网络状态不佳。
如果这个异常没有捕获,而且按照C语言对错误的处理方式,此时微信就崩了,直接退出。
采用C++的异常处理机制,会将抛出的这个异常捕获,然后进行处理,比如尝试多次发送等等操作。重点是微信程序不会退出,仍然可以继续运行。
- 在实际应用中,很多情况下我们是不希望程序产生异常就让它结束的,而是让它继续运行,并且将异常处理。
🍢C++标准库的异常体系
C++标准库采用的就是抛派生类对象异常,捕获基类对象的方式,也是利用了继承和多态。
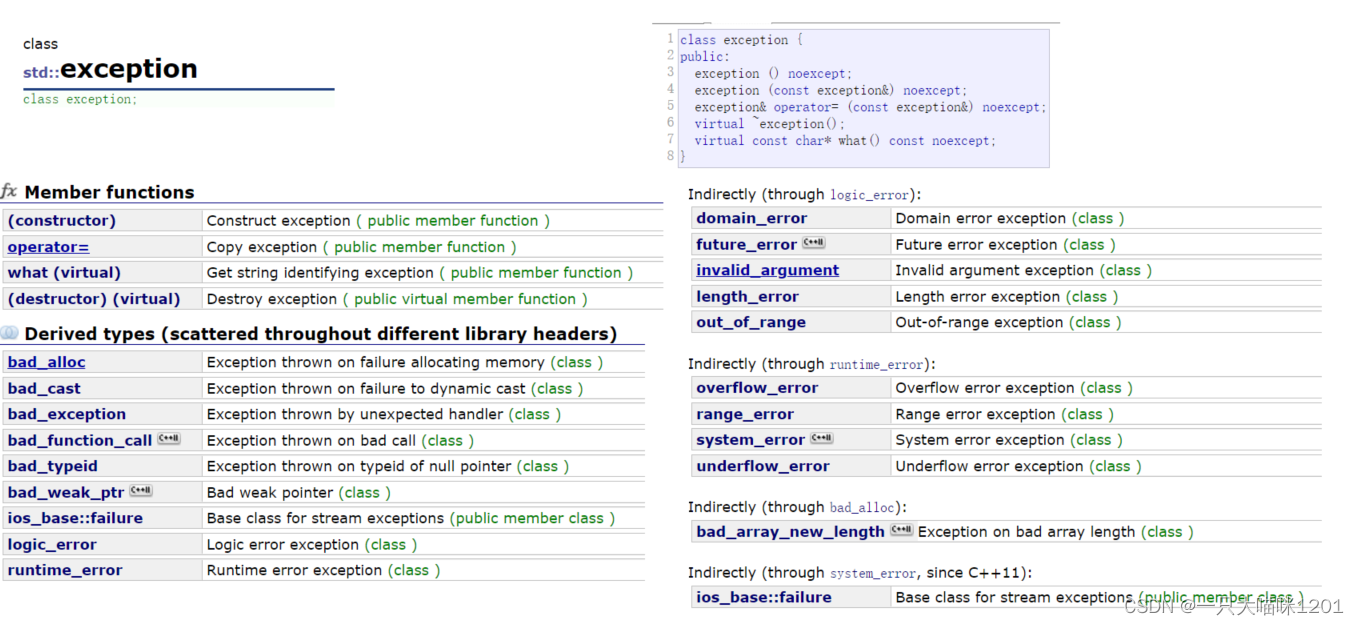
上图所示是C++11标准异常库中部分内容。它的体系结构如下图:
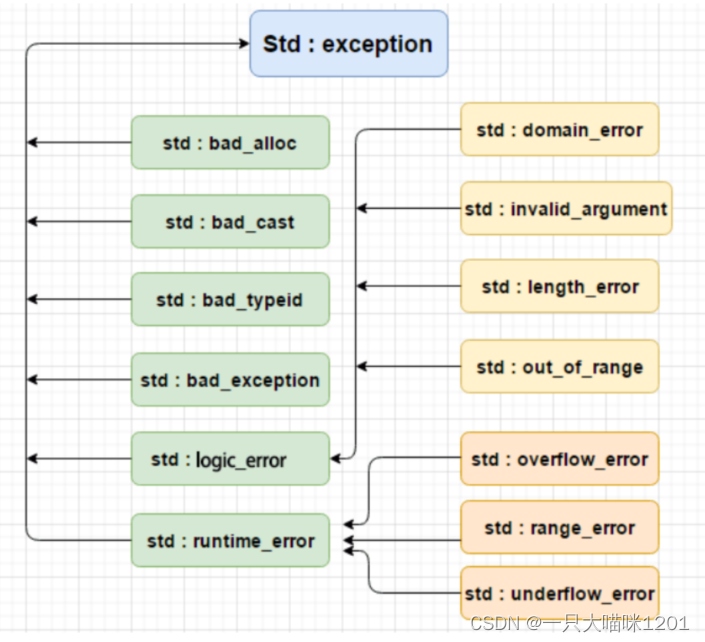
各种类型的异常都是在基类的基础上派生出来的,甚至是派生再派生的。
异常类型说明:
| 异常 | 描述 |
|---|---|
| std::exception | 该异常是所有标准C++异常的父类 |
| std::bad_alloc | 该异常通常由new抛出,表示内存申请失败 |
| std::invaild_argument | 当使用了无效的参数时,会抛出该异常 |
| std::out_of_range | 该异常有类方法抛出,如operator[],表示越界 |
| std::range_error | 当存储超出范围的值时,会抛出该异常 |
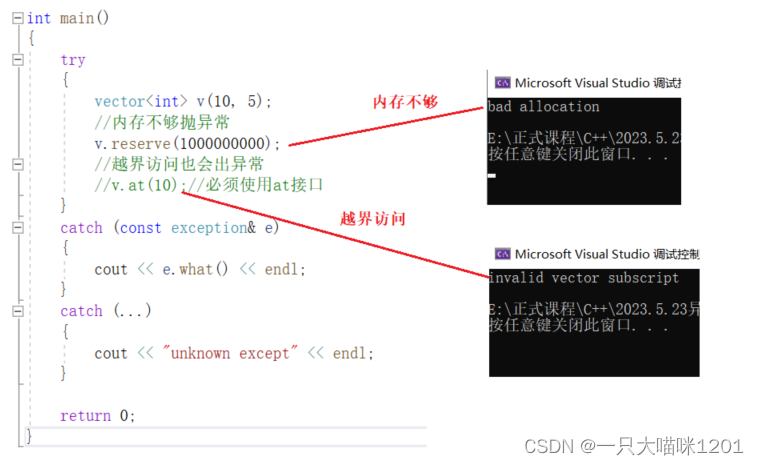
如上图所示,创建一个vector,查看内存不足和越界访问两种异常信息。
- 内存不足,无法开辟那么多空间时,异常信息是bad allocation。
- 越界访问,超出了开辟空间时,异常信息是invalid vector subscript。
可以看到,C++标准库中,也是通过捕获基类对象来打印各种派生类的异常信息的,但是它的设计并不够好,信息表达不清楚等等问题,所以实际中很多公司都会像上面一样自定义一套异常继承体系。
🍢异常的优缺点
C++异常优点:
- 异常对象定义好了,相比错误码的方式可以清晰准确的展示出错误的各种信息,甚至可以包含堆栈调用的信息,这样可以帮助更好的定位程序的bug。
- 返回错误码的传统方式有个很大的问题就是,在函数调用链中,深层的函数返回了错误,那么我们得层层返回错误,最外层才能拿到错误,而C++异常会直接销毁栈帧去异常的上一层匹配catch。
- 很多的第三方库都包含异常,比如boost、gtest、gmock等等常用的库,那么我们使用它们也需要使用异常。
- 部分函数使用异常更好处理,比如构造函数没有返回值,不方便使用错误码方式处理。比如T& operator这样的函数,如果pos越界了只能使用异常或者终止程序处理,没办法通过返回值表示错误。
C++异常缺点:
- 异常会导致程序的执行流乱跳,并且非常的混乱,并且是运行时出错抛异常就会乱跳。这会导致我们跟踪调试时以及分析程序时,比较困难。
- 异常会有一些性能的开销。当然在现代硬件速度很快的情况下,这个影响基本忽略不计。
- C++没有垃圾回收机制,资源需要自己管理。有了异常非常容易导致内存泄漏、死锁等异常安全问题。这个需要使用RAII来处理资源的管理问题。
- C++标准库的异常体系定义得不好,导致大家各自定义各自的异常体系,非常的混乱。
🥮总结
异常总体而言,利大于弊,所以工程中我们还是鼓励使用异常的。另外其他的语言基本都是用异常处理错误,这也可以看出这是大势所趋。