Differentiable augmentation for data-efficient gan training
公众号:EDPJ
目录
0. 摘要
1. 简介
2. 相关工作
3. 方法
3.1 重温数据增强
3.2 GAN 的可鉴别增强
4. 实验
4.1 ImageNet
4.2 FFHQ 和 LSUN-Cat
4.3 CIFAR-10 和 CIFAR-100
4.4 low-shot 生成
4.5 分析
5. 结论
参考
S. 总结
S.1 核心思想
S.2 网络结构
S.3 分析
0. 摘要
鉴于训练数据量有限,生成对抗网络 (GAN) 的性能会严重恶化。 这主要是因为判别器记住了确切的训练集。 为了解决这个问题,我们提出了可鉴别增强 (Differentiable Augmentation,DiffAugment),这是一种通过对真实样本和假样本施加各种类型的可鉴别增强来提高 GAN 数据效率的简单方法。 以前尝试直接增加训练数据来操纵真实图像的分布,收效甚微; DiffAugment 使我们能够对生成的样本采用可鉴别的增强,有效地稳定训练,并导致更好的收敛。 实验证明了我们的方法在各种 GAN 架构和无条件和类条件生成的损失函数上的一致收益。 借助 DiffAugment,我们在 ImageNet 128x128 上实现了 6.80 的最先进 FID,IS 为 100.8,在 FFHQ 和 LSUN 上给定 1,000 张图像的情况下 FID 减少了 2-4 倍。 此外,仅使用 20% 的训练数据,我们就可以在 CIFAR-10 和 CIFAR-100 上达到最佳性能。 最后,我们的方法无需预训练即可仅使用 100 张图像生成高保真图像,同时与现有的迁移学习算法不相上下。
1. 简介

如图 1 所以,只提供给 BigGAN 有限训练数据的情况下,性能严重恶化。
解决这个问题的一种广泛使用的策略是数据增强,它可以在不收集新样本的情况下增加训练数据的多样性。 裁剪、翻转、缩放、颜色抖动和区域 mask(剪切)等变换是视觉模型的常用增强。 然而,将数据增强应用于 GAN 是根本不同的。 如果仅将变换添加到真实图像,则会鼓励生成器匹配增强图像的分布。 因此,输出会受到分布偏移和引入的伪影的影响(例如,被遮盖的区域、不自然的颜色,请参见图 5a)。 或者,我们可以在训练鉴别器时增强真实图像和生成图像; 然而,这会打破生成器和鉴别器之间的微妙平衡,导致收敛性差,因为它们正在优化完全不同的目标(见图 5b)。


为了解决这个问题,我们引入了一种简单但有效的方法 DiffAugment,它对生成器和鉴别器训练的真实图像和假图像应用相同的可鉴别增强。 它使梯度能够通过增强传播回生成器,在不操纵目标分布的情况下对鉴别器进行正则化,并保持训练动态的平衡。 对各种 GAN 架构和数据集的实验一致证明了我们方法的有效性。 使用 DiffAugment,我们改进了 BigGAN,在没有截断技巧的情况下,在 ImageNet 128x128 上实现了 6.80 的 FID 和 100.8 的 IS,并在 FFHQ 和 LSUN 数据集上给定 1,000 张图像的情况下,将 StyleGAN2 基线的 FID 降低了 2-4 倍 。 我们还仅使用 20% 的训练数据在 CIFAR-10 和 CIFAR-100 上匹配了最佳性能(见图 2)。 此外,我们的方法仅需 100 个示例即可生成高质量图像(见图 3)。 在没有任何预训练的情况下,我们使用现有的迁移学习算法获得了具有竞争力的性能,而这些算法过去需要数万张训练图像。
2. 相关工作
GAN 的正则化。GAN 训练通常需要额外的正则化,因为它们非常不稳定。 为了稳定训练动态,研究人员提出了几种技术,包括实例噪声、Jensen-Shannon 正则化、梯度惩罚、谱归一化、对抗防御正则化和一致性正则化。 所有这些正则化技术都隐式或显式地惩罚鉴别器输出在输入的局部区域内的突然变化。 在本文中,我们提供了一个不同的视角,数据增强,我们鼓励判别器在不同类型的增强下表现良好。 在第 4 节中,我们表明我们的方法是对实践中正则化技术的补充。
数据增强。 许多深度学习模型采用保留标签的转换来减少过度拟合:例如颜色抖动、区域 mask、翻转、旋转、裁剪、数据混合以及局部和仿射失真。 最近,AutoML 已被用于探索给定数据集和任务的自适应增强策略。 然而,将数据增强应用于生成模型(例如 GAN)仍然是一个悬而未决的问题。 与标签对输入变换不变的分类器训练不同,生成模型的目标是学习数据分布本身。 直接应用增强将不可避免地改变分布。 我们提出了一个简单的策略来规避上述问题。
3. 方法
生成对抗网络 (GAN) 旨在通过生成器 G 和鉴别器 D 对目标数据集的分布进行建模。生成器 G 将通常从高斯分布中提取的输入隐向量 z 映射到其输出 G(z)。 鉴别器 D 学习将生成的样本 G(z) 与真实观察值 x 区分开来。 标准的 GANs 训练算法交替优化判别器的损失 L_D 和生成器的损失 L_G 给定损失函数 f_D 和 f_G:

在这里,可以使用不同的损失函数,例如非饱和损失,其中 f_D (x) = f_G (x) = log (1 + e^x),以及hinge 损失,其中 f_D (x ) = max(0 , 1 + x) 和 f_G (x) = x。
尽管为更好的 GAN 架构和损失函数做出了广泛的持续努力,但一个基本的挑战仍然存在:鉴别器倾向于在训练过程中记住观察结果。 过度拟合的鉴别器会惩罚除确切训练数据点之外的任何生成样本,由于泛化能力差而提供无信息的梯度,并且通常会导致训练不稳定。
挑战:判别器过度拟合。 在这里,我们分析了 BigGAN 在 CIFAR-10 上具有不同数据量的性能。 如图 1 所示,即使给定 100% 的数据,鉴别器的训练和验证精度之间的差距也在不断增加,这表明鉴别器只是简单地记住了训练图像。 正如 Brock 等人所观察到的,这不仅发生在有限的数据上,而且发生在大规模的 ImageNet 数据集上。BigGAN 采用了谱归一化,这是一种广泛用于生成器和鉴别器架构的正则化技术,但仍然存在严重的过度拟合问题。
3.1 重温数据增强
数据增强是许多识别任务中减少过度拟合的常用策略——它具有不可替代的作用,也可以与其他正则化技术结合应用:例如权重衰减。 我们已经证明鉴别器存在与二元分类器类似的过度拟合问题。 然而,与鉴别器的显式正则化相比,GAN 文献中很少使用数据增强。 事实上,最近的一项工作观察到直接将数据增强应用于 GAN 并不能改善基线。 因此,我们想问以下问题:是什么阻止我们简单地将数据增强应用于 GAN? 为什么增强 GAN 不如增强分类器有效?
仅增强真实图像(Augment reals only)。 增强 GAN 最直接的方法是直接将增强 T 应用于真实图像 x,我们称之为“仅增强真实图像”:

然而,仅增强真实图像偏离了生成建模的初衷,因为模型现在正在学习 T(x) 而不是 x 的不同数据分布。 这可以防止我们应用任何显着改变真实图像分布的增强。 满足这个要求的选择,虽然强烈依赖于具体的数据集,但在大多数情况下只能是水平翻转。 我们发现应用随机水平翻转确实会适度提高性能,并且我们在所有实验中都使用它来使我们的基线更强。 我们在表 1 中定量地和图 5a 中定性地展示了执行更强增强的副作用。正如预期的那样,该模型学会了产生不需要的颜色和几何失真(例如,不自然的颜色、切口孔),正如这些增强所引入的那样,导致性能明显变差(参见表 1 中的“Augment reals only”)。


仅增强 D。 以前,“Augment reals only”对真实样本应用单边增强,因此只有当生成的分布与操纵的真实分布匹配时才能实现收敛。 从判别器的角度来看,当我们更新 D 时,可能很想增强真实样本和假样本:

这里,相同的函数 T 应用于真实样本 x 和假样本 G(z)。 如果生成器成功地对 x 的分布进行建模,则 T(G(z)) 和 T(x) 以及 G(z) 和 x 对于鉴别器应该是无法区分的。 然而,这种策略会导致更糟糕的结果(参见表 1 中的“Augment D only”)。 图 5b 绘制了应用了平移的“Augment D only”的训练动态。 尽管 D 以高于 90% 的准确率对增强图像(T(G(z)) 和 T(x))进行了完美分类,但它无法识别 G(z),生成的图像没有增强,准确率低于 10%。 结果,生成器完全通过 G(z) 欺骗了判别器,无法从判别器那里获得有用的信息。 这表明任何打破生成器 G 和鉴别器 D 之间微妙平衡的尝试都容易失败。
3.2 GAN 的可鉴别增强
“Augment reals only” 的失败促使我们对真实样本和假样本进行增强,而“Augment D only” 的失败警告我们生成器不应忽略增强样本。 因此,要通过增强样本将梯度传播到 G,增强 T 必须是可鉴别的,如图 4 所示。我们将此称为可鉴别增强 (DiffAugment):
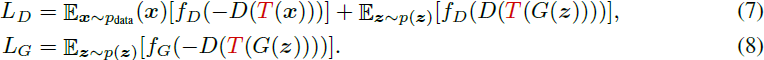
请注意,T 必须是相同的(随机)函数,但在图 4 所示的三个位置不一定是相同的随机变换。我们在整篇论文中使用三种简单的转换选择及其组合来证明 DiffAugment 的有效性:平移(在图像大小的 [ -1/8 , 1/8] 内,用零填充),Cutout(用图像大小的一半的随机正方形 mask)和颜色(包括在 [ -0.5 , 0.5] 内的随机亮度,对比度在 [0.5 ,1.5] 内,饱和度在 [0 , 2] 内)。 如表 1 所示,BigGAN 可以使用简单的平移(Translation)策略进行改进,并使用 Cutout 和 Translation 的组合进一步提升; 当 Color 组合使用时,它对最强策略也具有鲁棒性。

图 6 分析,更强的 DiffAugment 策略通常以较低的训练精度为代价保持较高的判别器验证精度,缓解过拟合问题,最终实现更好的收敛。
4. 实验
4.1 ImageNet

我们在 128x128 分辨率的 ImageNet 数据集上遵循性能最佳的模型 BigGAN。 此外,我们通过随机水平翻转来增强真实图像,据我们所知产生了 BigGAN 的最佳重现(FID:我们的 7.6 对比原始论文中的 8.7)。 我们对所有数据百分比设置使用简单的平移 DiffAugment。 在表 2 中,我们的方法取得了显着的进步,尤其是在 25% 的数据设置下,其中基线模型经历了早期崩溃,并在 100% 的数据可用的情况下推进了最先进的 FID 和 IS。
4.2 FFHQ 和 LSUN-Cat

我们进一步在 FFHQ 肖像数据集和 LSUN-Cat 数据集上以 256x256 分辨率对 StyleGAN2 进行了实验。 我们研究了不同的有限数据设置,可用的训练图像有 1k、5k、10k 和 30k。 我们将最强的 Color + Translation + Cutout DiffAugment 应用于所有 StyleGAN2 基线,而没有任何超参数更改。 真实图像还通过 StyleGAN2 中普遍应用的随机水平翻转进行了增强。 结果如表 3 所示。在所有数据百分比设置下,我们的性能提升都相当可观。 此外,使用 DiffAugment 中使用的固定策略,我们的性能与 ADA 相当,ADA 是基于自适应增强策略的并发工作。
4.3 CIFAR-10 和 CIFAR-100

我们在类条件 BigGAN 和 CR-BigGAN 以及无条件 StyleGAN2 模型上进行实验。 为了公平比较,我们还为所有基线增加了随机水平翻转的真实图像。 基线模型已经采用了先进的正则化技术,包括谱归一化 、一致性正则化 和 R1 正则化; 然而,在 10% 的数据设置下,它们都没有取得令人满意的结果。 对于 DiffAugment,我们对 BigGAN 模型采用 Translation + Cutout,对具有 100% 数据的 StyleGAN2 采用 Color + Cutout,对具有 10% 或 20% 数据的 StyleGAN2 采用 Color + Translation + Cutout。 如表 4 中总结的那样,我们的方法独立于基线架构、正则化和损失函数(BigGAN 中的 hinge 损失和 StyleGAN2 中的非饱和损失)改进了所有基线,而没有任何超参数更改。 我们建议读者参考 IS 完整表格的补充材料。 改进是相当可观的,尤其是在可用数据有限的情况下。 据我们所知,这是 CIFAR-10 和 CIFAR-100 在所有 10%、20% 和 100% 数据设置下的类条件生成和无条件生成的最新技术水平。
4.4 low-shot 生成
对于特定的人、物体或地标,收集大规模数据集通常是乏味的,甚至是完全不可能的。 为了解决这个问题,研究人员最近在图像生成的设置中利用了 few-shot 学习。 Wang 等人使用微调来迁移在外部大规模数据集上预训练的模型的知识。 几项工作建议仅微调模型的一部分。 下面,我们表明我们的方法不仅在不使用外部数据集或模型的情况下产生有竞争力的结果,而且与现有的迁移学习方法正交。


我们使用与 Mo 等人相同的代码库复制最近的迁移学习算法。基于来自 FFHQ 人脸数据集的预训练 StyleGAN 模型,在他们的数据集(AnimalFace 有 160 只猫和 389 只狗)上。 为了进一步证明数据效率,我们收集了 100 次拍摄的 Obama、grumpy cat 和 panda 数据集,并在每个数据集上仅使用 100 张图像训练 StyleGAN2 模型,而没有进行预训练。 对于 DiffAugment,我们对 StyleGAN2 采用 Color + Translation + Cutout,对原始微调算法 TransferGAN 和冻结鉴别器的前几层的 FreezeD 采用 Color + Cutout。 表 5 显示 DiffAugment 在所有数据集上独立于训练算法实现了一致的增益。 在没有任何预训练的情况下,我们仍然取得了与需要数万张图像的现有迁移学习算法相当的结果,但在 100 张照片的 Obama 数据集上是个例外,其中对人脸进行预训练显然可以带来更好的泛化。 请参见图 3 和补充材料以进行定性比较。 虽然可能有人担心生成器可能会过度拟合微小的数据集(即生成相同的训练图像),但图 7 表明我们的方法通过样式空间中的线性插值几乎没有过度拟合; 请参考补充材料中的最近邻测试。
4.5 分析
下面,我们研究更小的模型或更强的正则化是否会同样减少过度拟合,以及 DiffAugment 是否仍然有帮助。 最后,我们分析了 DiffAugment 的其他选择。

模型大小很重要吗?我们通过逐渐将 G 和 D 的通道数量减半来降低 BigGAN 的模型容量。如图 8a 所示,当使用完整模型时,基线在 CIFAR-10 上严重过度拟合,训练数据为 10%,并且在 1/4 通道达到最小 FID 29.02 。 然而,我们的方法在所有模型容量上都超过了它。 在 1/4 通道的情况下,我们的模型实现了 21.57 的明显更好的 FID,而随着模型变大,差距单调增加。 我们建议读者参阅补充材料的 IS 图。
更强的正则化很重要吗? 由于 StyleGAN2 采用 R1 正则化来稳定训练,我们将其强度从 γ= 0.1 增加到高达 10^4,并在图 8b 中绘制 FID 曲线。 虽然我们最初发现 γ= 0.1 在 100% 数据设置下效果最好,但选择 γ= 10^3 在 10% 数据设置下将其性能从 34.05 提高到 26.87。 当 γ= 10^4 时,在 750k 次迭代内,我们仅在 440k 次迭代时观察到最小 FID 为 29.14,此后性能下降。 然而,它的最佳 FID 仍然比我们的差 1.8 倍(默认 γ= 0.1)。 这表明与显式正则化鉴别器相比,DiffAugment 更有效。

DiffAugment 的选择很重要吗? 我们研究了图 9 中 DiffAugment 的其他选择,包括随机 90 度旋转(-90°、0°、90°,每个旋转概率为 1/3)、高斯噪声(标准差为 0.1)和一般涉及双线性插值的几何变换,例如双线性平移(在 [-0.25,0.25] 内)、双线性缩放(在 [0.75,1.25] 内)、双线性旋转(在 [-30°,30°] 内) ]), 和双线性剪切 (在 [-0.25,0.25] 内)。 虽然所有这些策略始终优于基线,但我们发现 Color + Translation + Cutout DiffAugment 特别有效。 简单性还使其更易于部署。
5. 结论
我们提出了用于数据高效 GAN 训练的 DiffAugment。DiffAugment 揭示了有价值的观察结果,即增强真实样本和假样本可以有效防止鉴别器过度拟合,并且增强对于训练生成器和鉴别器必须是同时可鉴别的。广泛的实验一致地证明了它在多个数据集(ImageNet、CIFAR、FFHQ、LSUN 和 100-shot 数据集)中使用不同网络架构(StyleGAN2 和 BigGAN)、监督设置和目标函数的优势。 当可用数据有限时,我们的方法特别有效。
更广泛的影响。在本文中,我们从数据效率的角度研究 GAN,旨在使更多人(例如,视觉艺术家和新手用户)和无法访问大量数据的研究领域能够访问生成模型。 在现实场景中,可能有多种原因导致可用数据量有限,例如罕见事件、隐私问题和历史视觉数据。 DiffAugment 提供了一种有前途的方法来缓解上述问题并使每个人都更容易获得 AI。
参考
Zhao S, Liu Z, Lin J, et al. Differentiable augmentation for data-efficient gan training[J]. Advances in Neural Information Processing Systems, 2020, 33: 7559-7570.
S. 总结
S.1 核心思想
本文是对自适应鉴别器增强(adaptive discriminator augmentation,ADA)一文中提出的、用于提升数据有限时 GAN 的性能的、可鉴别数据增强(Differentiable Augmentation,DiffAugment)的进一步研究(消融实验)。结果表明,需要同时对真实数据、生成数据以及生成器进行增强。
S.2 网络结构

DiffAugment 网络结构如上图所示。
- 固定 G,鉴别器学习对变换后真实数据有高鉴别分数,对生成数据有低鉴别分数。
- 固定 D,生成器学习生成经过变换后能骗过鉴别器的图像。
变换 T 必须是相同的(随机)函数,但在上图所示的三个位置不一定是相同的随机变换(例如,平移、剪切、颜色变换)。
S.3 分析
如果只增强真实数据,则生成器学习到的分布式是经过变换的真实图像分布。
如果只增强鉴别器(增强真实数据和生成数据),则生成器学习到的是生成未经变换的的数据来骗过鉴别器。这会打破生成器与鉴别器的平衡,导致收敛性差,从而使性能恶化,因为它们正在优化完全不同的目标。
因此,需要同时对真实数据、生成数据以及生成器进行增强。