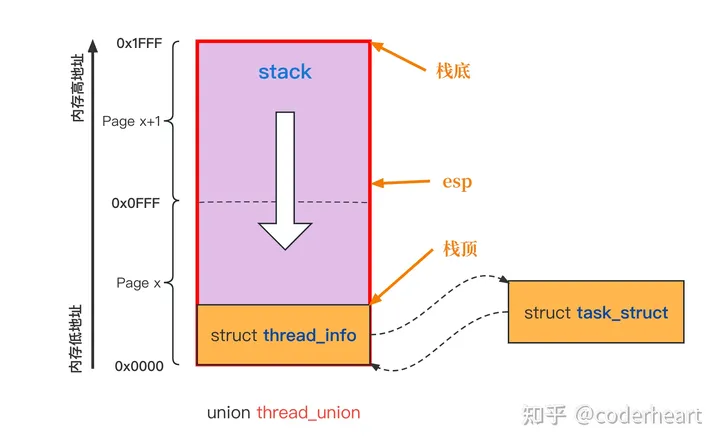
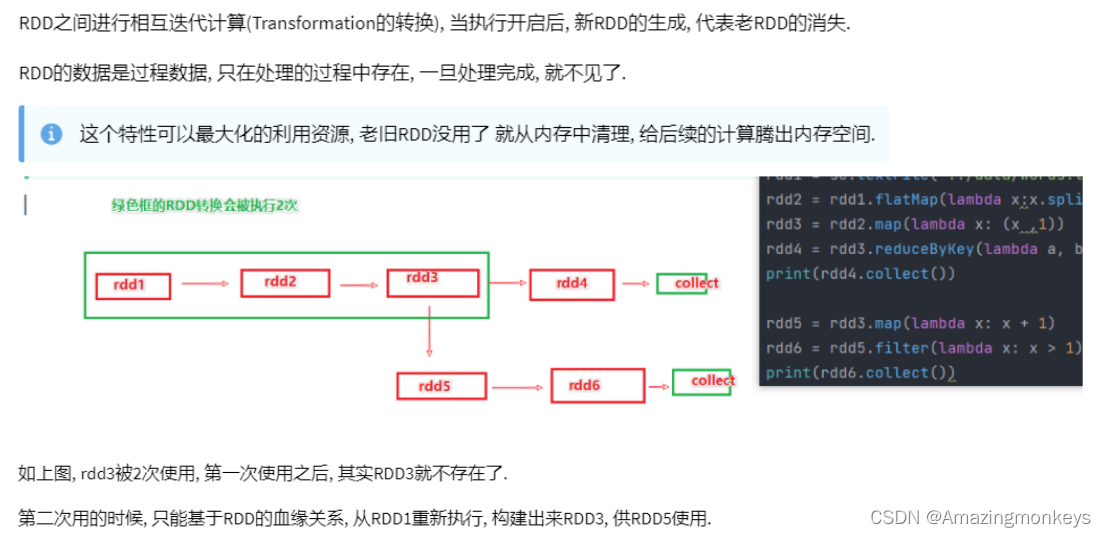
RDD 的数据是过程数据
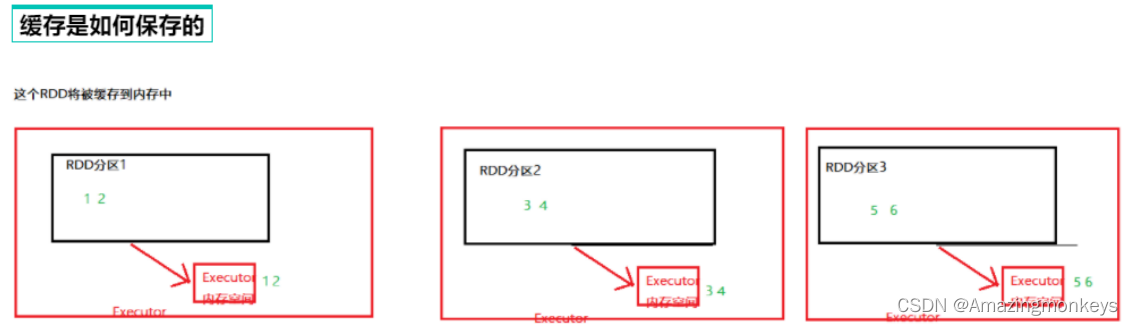
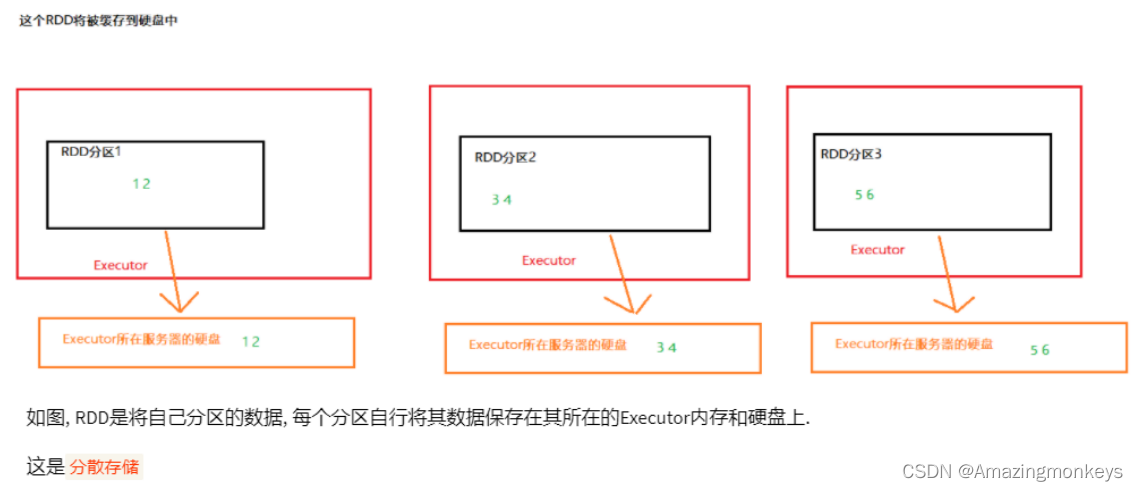
RDD 的缓存

# coding:utf8
import time
from pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevel
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd1 = sc.textFile("../data/input/words.txt")
rdd2 = rdd1.flatMap(lambda x: x.split(" "))
rdd3 = rdd2.map(lambda x: (x, 1))
# 缓存到内存中
rdd3.cache()
# 先放内存,如果不够则放硬盘,2份副本
rdd3.persist(StorageLevel.MEMORY_AND_DISK_2)
rdd4 = rdd3.reduceByKey(lambda a, b: a + b)
print(rdd4.collect())
rdd5 = rdd3.groupByKey()
rdd6 = rdd5.mapValues(lambda x: sum(x))
print(rdd6.collect())
# 清理缓存
rdd3.unpersist()
time.sleep(100000)

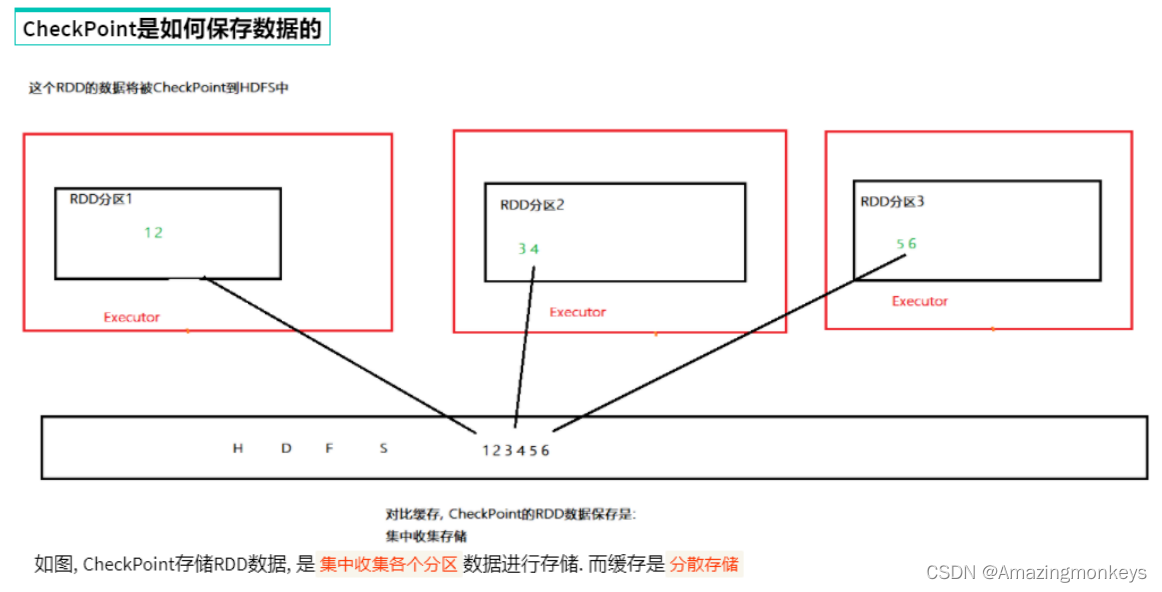
RDD 的CheckPoint

# coding:utf8
import time
from pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevel
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 1. 告知spark, 开启CheckPoint功能
sc.setCheckpointDir("hdfs://node1:8020/output/ckp")
rdd1 = sc.textFile("../data/input/words.txt")
rdd2 = rdd1.flatMap(lambda x: x.split(" "))
rdd3 = rdd2.map(lambda x: (x, 1))
# 调用checkpoint API 保存数据即可
rdd3.checkpoint()
rdd4 = rdd3.reduceByKey(lambda a, b: a + b)
print(rdd4.collect())
rdd5 = rdd3.groupByKey()
rdd6 = rdd5.mapValues(lambda x: sum(x))
print(rdd6.collect())
rdd3.unpersist()
time.sleep(100000)
Cache和Checkpoint区别
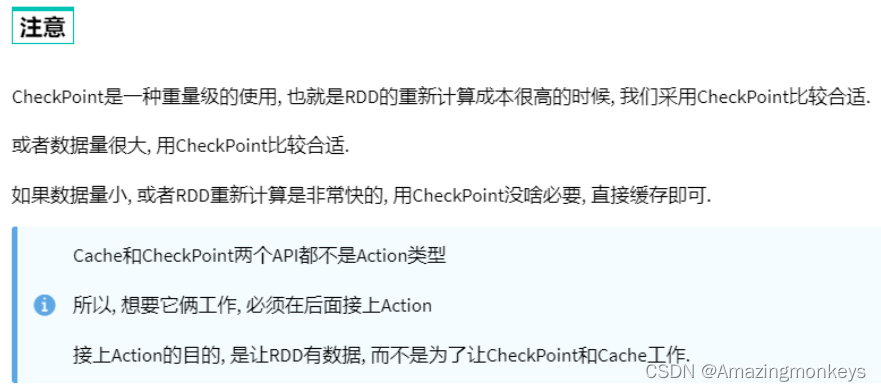
Cache是轻量化保存RDD数据,可存储在内存和硬盘,是分散存储,设计上数据是不安全的(保留RDD血缘关系)。
CheckPoint是重量级保存RDD数据,是集中存储,只能存储在硬盘(HDFS)上,设计上是安全的(不保留RDD血缘关系)。
Cache 和 CheckPoint的性能对比?
Cache性能更好,因为是分散存储,各个Executor并行执行,效率高,可以保存到内存中(占内存),更快。
CheckPoint比较慢,因为是集中存储,涉及到网络IO,但是存储到HDFS上更加安全(多副本) 。
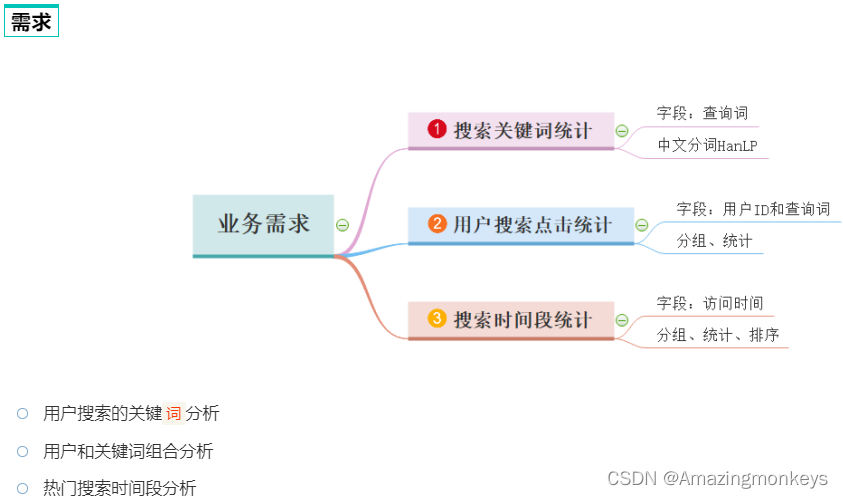
案例练习:搜索引擎日志分析


# coding:utf8
# 导入Spark的相关包
import time
from pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevel
from defs import context_jieba, filter_words, append_words, extract_user_and_word
from operator import add
if __name__ == '__main__':
# 0. 初始化执行环境 构建SparkContext对象
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 1. 读取数据文件
file_rdd = sc.textFile("hdfs://node1:8020/input/SogouQ.txt")
# 2. 对数据进行切分 \t
split_rdd = file_rdd.map(lambda x: x.split("\t"))
# 3. 因为要做多个需求, split_rdd 作为基础的rdd 会被多次使用.
split_rdd.persist(StorageLevel.DISK_ONLY)
# TODO: 需求1: 用户搜索的关键`词`分析
# 主要分析热点词
# 将所有的搜索内容取出
# print(split_rdd.takeSample(True, 3))
context_rdd = split_rdd.map(lambda x: x[2])
# 对搜索的内容进行分词分析
words_rdd = context_rdd.flatMap(context_jieba)
# print(words_rdd.collect())
# 院校 帮 -> 院校帮
# 博学 谷 -> 博学谷
# 传智播 客 -> 传智播客
filtered_rdd = words_rdd.filter(filter_words)
# 将关键词转换: 传智播 -> 传智播客
final_words_rdd = filtered_rdd.map(append_words)
# 对单词进行 分组 聚合 排序 求出前5名
result1 = final_words_rdd.reduceByKey(lambda a, b: a + b).\
sortBy(lambda x: x[1], ascending=False, numPartitions=1).\
take(5)
print("需求1结果: ", result1)
# TODO: 需求2: 用户和关键词组合分析
# 1, 我喜欢传智播客
# 1+我 1+喜欢 1+传智播客
user_content_rdd = split_rdd.map(lambda x: (x[1], x[2]))
# 对用户的搜索内容进行分词, 分词后和用户ID再次组合
user_word_with_one_rdd = user_content_rdd.flatMap(extract_user_and_word)
# 对内容进行 分组 聚合 排序 求前5
result2 = user_word_with_one_rdd.reduceByKey(lambda a, b: a + b).\
sortBy(lambda x: x[1], ascending=False, numPartitions=1).\
take(5)
print("需求2结果: ", result2)
# TODO: 需求3: 热门搜索时间段分析
# 取出来所有的时间
time_rdd = split_rdd.map(lambda x: x[0])
# 对时间进行处理, 只保留小时精度即可
hour_with_one_rdd = time_rdd.map(lambda x: (x.split(":")[0], 1))
# 分组 聚合 排序
result3 = hour_with_one_rdd.reduceByKey(add).\
sortBy(lambda x: x[1], ascending=False, numPartitions=1).\
collect()
print("需求3结果: ", result3)
time.sleep(100000)
import jieba
def context_jieba(data):
"""通过jieba分词工具 进行分词操作"""
seg = jieba.cut_for_search(data)
l = list()
for word in seg:
l.append(word)
return l
def filter_words(data):
"""过滤不要的 谷 \ 帮 \ 客"""
return data not in ['谷', '帮', '客']
def append_words(data):
"""修订某些关键词的内容"""
if data == '传智播': data = '传智播客'
if data == '院校': data = '院校帮'
if data == '博学': data = '博学谷'
return (data, 1)
def extract_user_and_word(data):
"""传入数据是 元组 (1, 我喜欢传智播客)"""
user_id = data[0]
content = data[1]
# 对content进行分词
words = context_jieba(content)
return_list = list()
for word in words:
# 不要忘记过滤 \谷 \ 帮 \ 客
if filter_words(word):
return_list.append((user_id + "_" + append_words(word)[0], 1))
return return_list提交到集群运行
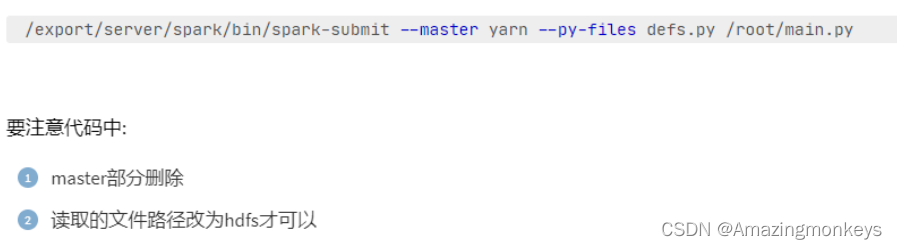
 为什么要在全部的服务器安装jieba库?
为什么要在全部的服务器安装jieba库?
因为YARN是集群运行,Executor可以在所有服务器上执行,所以每个服务器都需要有jieba库提供支撑。
如何尽量提高任务计算的资源?
计算CPU核心和内存量,通过--executor-memory 指定executor内存,通过--executor-cores 指定
executor的核心数,通过--num-executors 指定总executor数量。