本篇博文继续整理LLM在搜索推荐领域的应用,往期文章请往博主主页查看更多。
Precise Zero-Shot Dense Retrieval without Relevance Labels
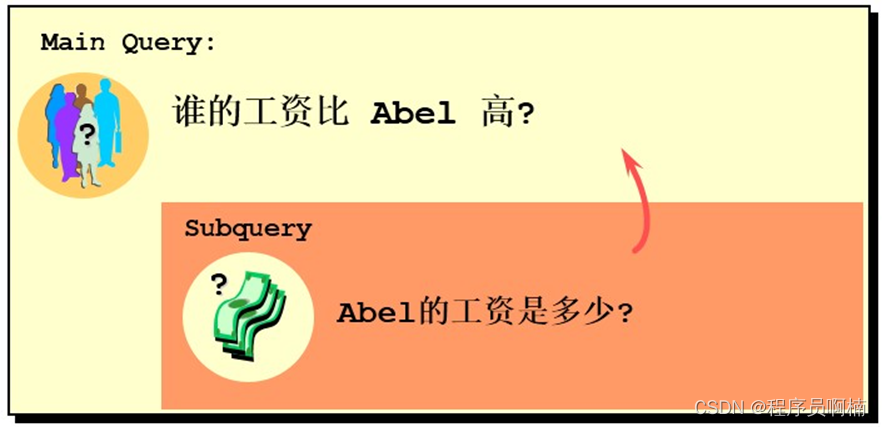
这篇文章主要做zero-shot场景下的稠密检索,通过借助LLM的力量不需要Relevance Labels,开箱即用。作者提出Hypothetical Document Embeddings (HyDE)方法,即“假设”文档嵌入。具体的做法是通过GPT生成虚构的文档,并使用无监督检索器对其进行编码,并在其嵌入空间中进行搜索,从而不需要任何人工标注数据。
s
i
m
(
q
,
d
)
=
<
e
n
c
q
(
q
)
,
e
n
c
d
(
d
)
=
<
v
q
,
v
d
>
>
sim(q,d)=<enc_q(q),enc_d(d)=<v_q,v_d>>
sim(q,d)=<encq(q),encd(d)=<vq,vd>>模型结构如下图所示,HyDE将密集检索分解为两个任务,即 instruction-following的LM生成任务和对比编码器执行的文档相似性任务。

- write a document that answers the question。对于给定一个query,将由InstructGPT生成一个能回答该query的假设文档,即a hypothetical document。
- relevance。然后使用无监督的稠密检索模型(Contriever)把该文档表示为稠密向量。
- 最后基于最近邻从语料库中找到相似的文档即可。
paper:https://arxiv.org/pdf/2212.10496
code:https://github.com/texttron/hyde

UDAPDR: Unsupervised Domain Adaptation via LLM Prompting and Distillation of Rerankers
来自斯坦福和IBM。motivation在于目前很多信息检索任务需要在大型标记数据集上微调,但是此类数据集通常不可用,并且由于领域转移,它们在现实世界应用程序中的实用性可能会迅速降低。因此,作者们提出了一种利用LLM来生成大量合成查询的方法,即先使用昂贵的 LLM 生成少量合成查询,然后创建大量合成查询,最后用这些合成结果进行模型训练精排模型并蒸馏到一个高效的稠密检索模型。这种技术可以提高长尾域中的zero-shot准确性,即使在仅使用 2K 合成查询进行微调的情况下,效果就很好。

具体来说,本文设计了一个两阶段的LLM pipeline,包括一个能力强大且昂贵的LLM,以及一个小且便宜的LLM,用于在zero-shot场景下生成query。
-
Stage 1:使用LLM(text-davinci-002)生成大量的query,如上图,该过程会使用多种提示策略。
-
Stage 2:基于Stage1中生成的查询,与来自目标域T的好/坏结果的合成查询配对,如下图所示。

-
Stage 3:使用生成的query文档对,以in-context learning的形式使用小LLM(FLAN-T5 XXL)更高效地生成query。
-
Stage 4:利用Stage 3的结果,从头训练单个的passage reranker(DeBERTaV3-large),以当作教师教师机来蒸馏。
-
Stage 5:Stage4的领域特定通道通道作为多教师在多教师蒸馏过程中蒸馏到ColBERTv2中。
-
Stage 6:在目标域t的评估集上测试这个自适应域的ColBERTv2检索器。
paper:https://arxiv.org/pdf/2303.00807
code:https://github.com/primeqa/primeqa/