概述
随着大规模语言模型的兴起,自然语言处理领域取得了重大发展。这些创新的模型允许用户通过输入简单的 "提示 "文本来执行各种任务。然而,众所周知,在问题解答(QA)任务中,用户在处理长文本时会面临信息 "丢失 "的问题。
最近,支持超长语境的大规模语言模型已经发布,如 GPT-4 Turbo 和 Claude-2.1,它们分别支持 128k 和 200k 标记的语境窗口。虽然这些大规模语言模型支持长上下文,但当输入提示非常长时,它们的响应质量往往会下降;Liu 等人(2023 年)发现,即使是 16k 标记上下文,如果相关上下文位于文档的中间,也会出现问题。Liu 等人(2023 年)发现,在基于文档的大型语言模型质量保证中,如果相关上下文位于文档中间,即使是 16k 标记上下文,准确率也会明显低于开始和结尾。这种现象被称为"迷失在中间"。
为了解决这个问题,本文提出了一种新的方法–R&R,它结合了 "重新提示 "和 “上下文检索”。这种方法允许在整个文档中重复问题指示,从而有效地提取最相关的信息。其目的是提高 QA 的准确性,以及大型语言模型在长语境中的性能。
论文详细介绍了这一创新方法的工作原理,并提出了在长时间的质量保证任务中减少 "中间丢失 "效应的有效策略。通过实验,论文还展示了 "重新提示 "和 "上下文检索 "在使用大规模语言模型方面的新潜力。这些方法在处理长句时提高了准确性和效率,从而有可能扩大 NLP 技术的应用范围。
技术
本文重点介绍了基于文档的问题解答(QA)任务,并提出了一种使用大规模语言模型的创新方法。
这种方法要求大规模语言模型根据给定文档的上下文回答问题。为此,提示被分为三个部分,以明确说明。首先标记问题及其答案说明,然后标记文档本身。

最后,在大规模语言模型生成答案之前,再次重复指令。这种重复是基于以前的方法,目的是在不丢失文档信息的情况下有效地引导回答。
它还假定文档被分为 “页”。这些页面与文档中的自然分隔符(如段落和句子)相对应,为标准化起见称为页面。<PAGE {p}> . . . </PAGE {p}> 标记,其中 {p} 由相应的页码代替。这种方法允许大规模语言模型更有效地处理整个文档,并精确提取与问题相关的信息。
此外,还引入了一种名为"重新提示"的技术。这种技术旨在减少 "迷失在中间 "现象,即大型语言模型偏向于文档的开头或结尾,或靠近关键指令。在重新提示中,<INSTRUCTIONS_REMINDER> 你的任务是. . . </INSTRUCTIONS_REMINDER> 时,会在 PAGE 块外为文档中的每个指定标记插入一个提醒块,其中包含几乎是逐字记录的原始指令。这有望缩短文档中任何地方的相关信息与说明之间的距离,并提高大规模语言模型中应答的准确性。
此外,还引入了"上下文检索"和分块技术。上下文检索"基于这样一种理念,即从文件中提取与问题相关的信息通常比直接回答问题要简单。这是因为在信息提取过程中,可重复性比准确性更重要。这一过程分两个阶段进行,首先确定与问题最相关的页面,然后使用仅包含这些页面的缩写文档来回答问题。这种方法旨在让大规模语言模型高效处理信息。它还结合了"重新提示"和"上下文检索",以确保在提取文档中间的重要信息时不会遗漏任何内容。具体来说,通过在整个文档中提醒搜索指令,大规模语言模型有助于找到埋藏在中间的相关页面。
分块技术还能将文档划分为非重叠、连续的块,并独立执行"上下文内检索"。这样就能有效地提取最相关的信息,在保持准确性的同时减少 LLM 调用的次数。如果信息块足够大,还可以在信息块内执行"重新提示",从而进一步优化准确性和效率之间的平衡。这样就有可能为更复杂的文档提供更高的性能。
实验和结果
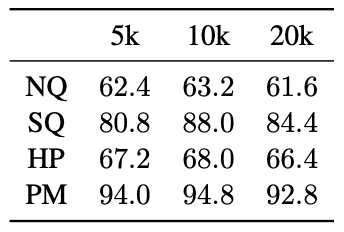
本文研究了 "R&R "在基于文档的问题解答(QA)任务中的有效性。下表总结了每个数据集和长文本方法(不包括分块法)在不同文档长度(d)下获得的模糊匹配分数。往往会提高准确率。
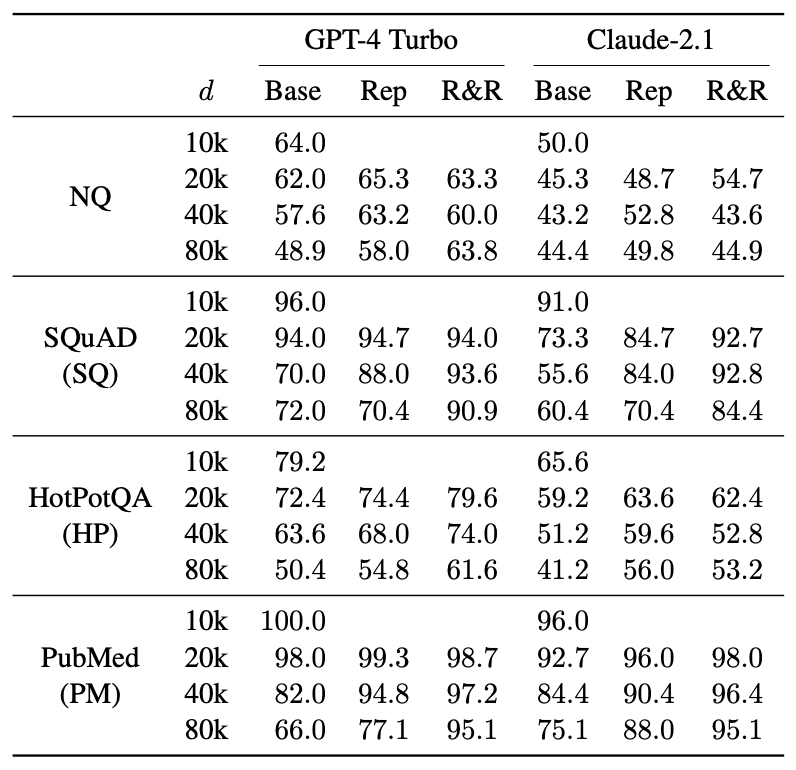
重新提示的额外成本极低,在 d=80k 时比基线多消耗约 1.15%的输入令牌,但在输出令牌方面没有额外成本;R&R 同样在 d=80k 时比基线多消耗约 1.15%的输入令牌,但平均每个样本需要 83 个输出令牌,平均每个样本需要 83 个输出令牌。它需要在 ICR 步骤中额外调用一个大型语言模型,平均每个样本需要 83 个输出词块。与基线和重新提示情况下的 43 个输出词组相比,这个数字偏高。不过,这些结果表明,在基于文档的质量检测中,R&R可以有效扩展大规模语言模型的有效语境范围。
此外,还进行了分块式 ICR 和分块式 R&R(增加了重新提示),以比较较长上下文和重新提示与较短上下文和基于分块的方法的优势。下表显示了每个数据集和每种方法的模糊匹配得分,其中改变了进行 ICR 和 R&R 时的语块大小(c)。
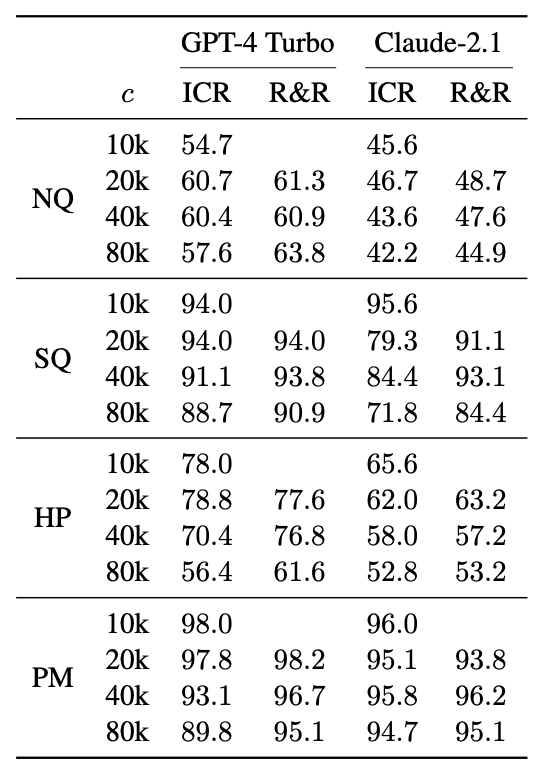
一般来说,对于大多数数据集来说,随着数据块大小的增加,准确率往往会下降,因为额外的填充上下文会降低搜索准确率。不过,有研究表明,重新提示实际上可以使用更大的数据块,随着数据块大小的增加,准确率的损失也会减少。
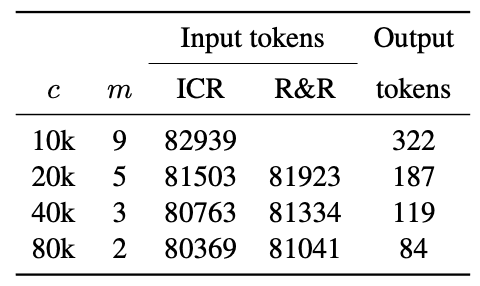
这对准确性/成本的权衡有重要影响。较小的语块需要更多的 LLM 调用(每个语块一次,聚合后进行 QA)、输入标记和输出标记。特别是,输出标记的成本很高,相当于 GPT-4 Turbo 中输入标记价格的三倍,而且大型语言模型的执行时间会随着输出标记的增加而线性增加。因此,有人建议,重新提示可以通过允许更大的语块来减轻这种权衡,从而减少对大型语言模型的调用和输出令牌的需求,同时将准确性的损失降到最低。此外,虽然重新提示本身需要少量额外的输入标记,但这一成本可被大块输入标记的减少所抵消。
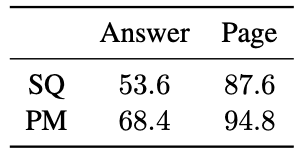
这种上下文内检索(ICR)方法也是基于这样一个假设:从文件中提取最相关的页面比直接回答问题更容易。在前一种情况下,原因是可重复性优先于准确性。我们通过比较直接基于文档的质量保证和 "提取最相关的页面来回答问题 "的任务来验证这一假设。我们将 NQ 排除在实验之外,因为初始页面包含误导性信息;将 HotPotQA 排除在外,因为相关上下文分散在多个页面中。然而,SQuAD 和 PubMed 显示,在文档长度 d = 40k 的示例中,页面提取的准确性明显高于直接回答问题。
关于重试频率,我们验证了每 10k 个标记的选择,并发现这在所有数据集中都能达到最高的 QA 准确率。
关于重新提示的位置,我们测试了这样一个假设:只在紧接着相关上下文之前重新提示可以显著提高准确率。特别是,在文档长度为 d = 40k 的三个数据集中,在标记为包含 "黄金段落 "的 PAGE 块之前插入单个 INSTRUCTIONS_REMINDER 块的方法均匀地优于每 10k 个重复提示的方法。比均匀每 10k 个词组重新提示一次的方法获得了更高的质量保证准确率。这表明,重新提示是通过缩短相关上下文与任务指令之间的距离来发挥作用的。
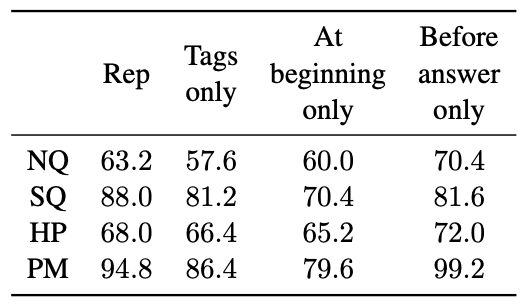
此外,他们还发现,仅仅暗示原始指令的重复提示比原始提示的效果更差。这表明,重要的是,提示不仅要重复,还要缩短问题与相关语境之间的距离。最后,将提示块放在文档开头的重新提示测试结果明显不如原始重新提示。这些结果表明,重新提示不是简单的重复,而是由于特定的策略性位置而产生了效果。
总结
本文开发了一种基于提示的方法 R&R,以探索在基于文档的问题解答(QA)任务中提高大规模语言模型处理长句性能的潜力。研究发现,这种方法在减少"中间丢失 "方面特别有效。此外,还有人认为,重新提示是通过最小化相关上下文与任务指令之间的距离来发挥作用的。
对于提取类型的质量保证任务而言,分块方法提供了坚实的基础,但也有可能以分块的方式进行重复性和再现性分析。即使在这种情况下,我们也发现重新提示是有益的,通过允许使用较大的分块,减少了对大型语言模型的调用次数,最大限度地减少了标记的使用,同时在平衡准确性和成本时限制了准确性损失的 R&R、在准确性至关重要的实际应用中,分块方法的灵活性和成本节约
未来的研究方向多种多样,前景广阔:将 R&R 与其他基于提示的方法相结合可进一步提高性能。还可以考虑 "上下文分块 "等新方法,以进一步优化准确性/成本的权衡。将重新提示法应用于需要对文档有更全面理解的任务(如摘要制作),也可以开辟新的研究领域。最后,虽然这些只是基于提示的方法,但深入了解这些方法的优势和局限性,可以揭示大规模语言模型在处理较长文本时的行为,并为促进进一步改进的架构变革提供提示。
注:
论文地址:https://arxiv.org/abs/2403.05004
源码地址:https://github.com/casetext/r-and-r