目录
🎨1. HTTP 请求
🏰1.1 首行
👑1.2 URL
🚩1.3 Content-Type 和 Content-Length
🍊1.4 User-Agent
🌽1.5 Referer
⚽1.6 Cookie
🍩2. HTTP 响应
🌞2.1 HTTP 响应 首行
🍘3. 如何构造 HTTP 请求?
HTTP,Hyper Text Transfer Protocol ,即超文本传输协议,是一种应用广泛的应用层协议。
我们平时打开一个网站, 就是通过 HTTP 协议来传输数据的。
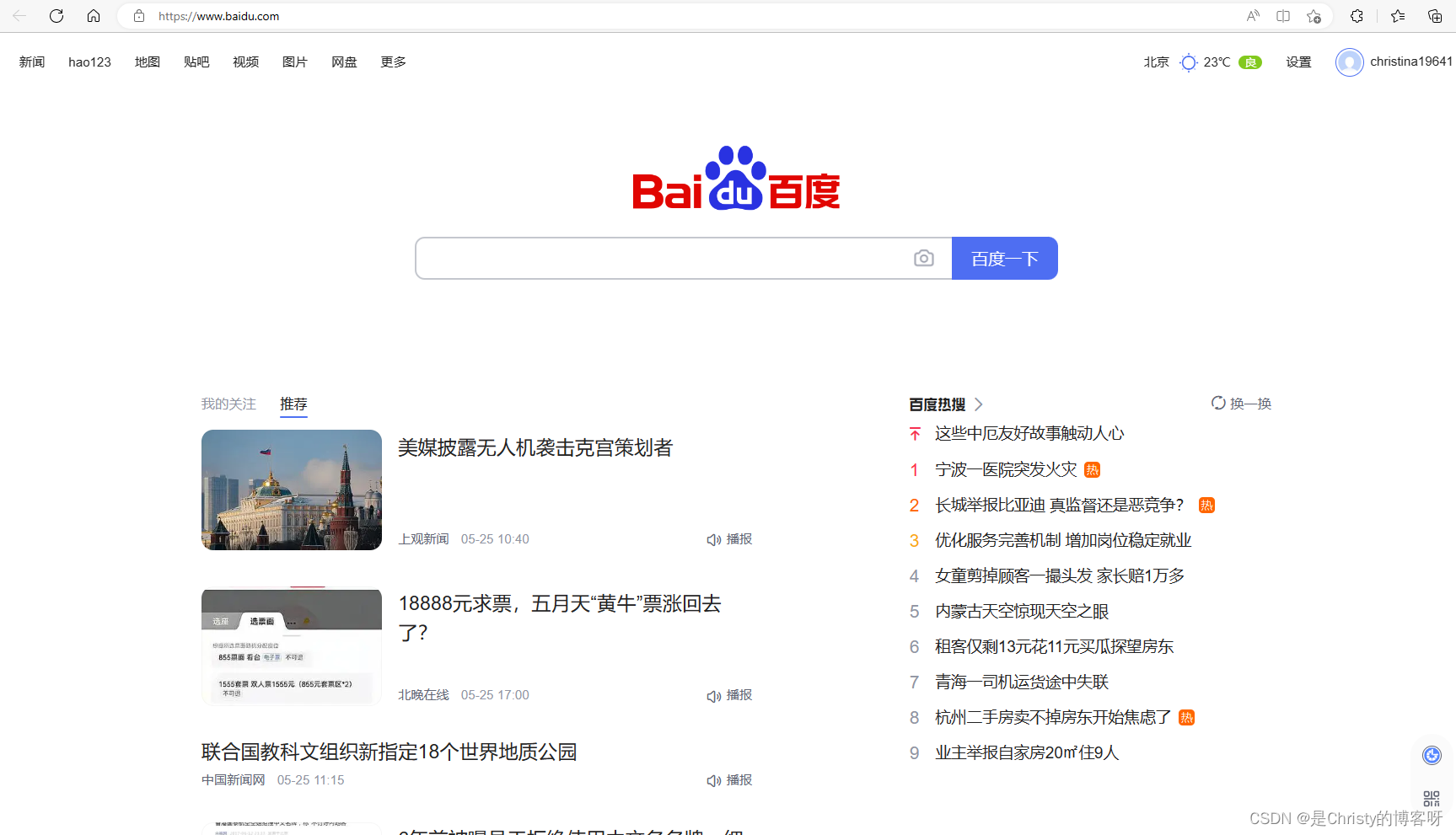
当我们在浏览器中输入一个百度搜索的 "网址" (URL) 时,浏览器就给百度的服务器发送了一个 HTTP 请求,百度的服务器返回了一个 HTTP 响应。这个响应结果被浏览器解析之后,就展示成我们看到的页面内容。(这个过程中浏览器可能会给服务器发送多个 HTTP 请求,服务器会对应返回多个响应,这些响应里就包含了页面 HTML,CSS,JavaScript,图片,字体等信息)。
1. HTTP 请求
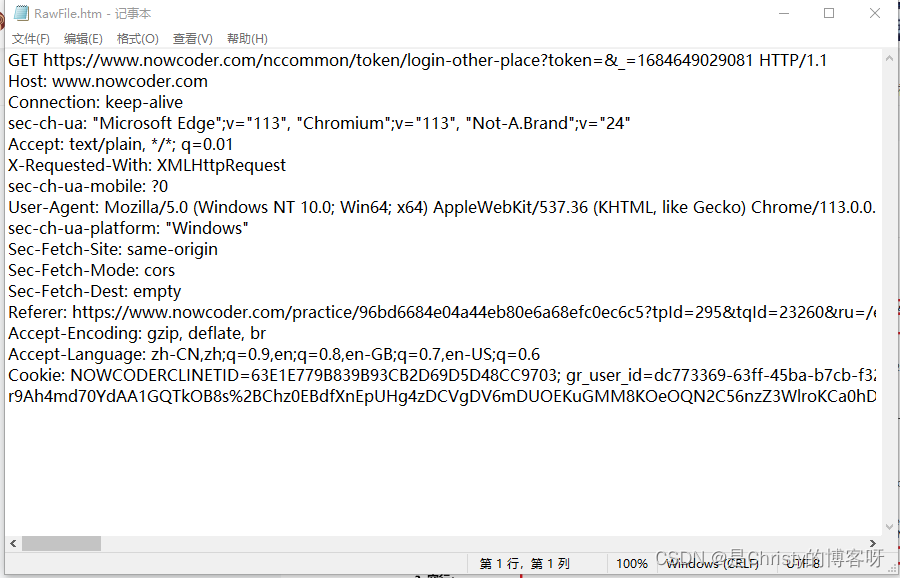
一个 HTTP GET 请求包含以下四个部分:
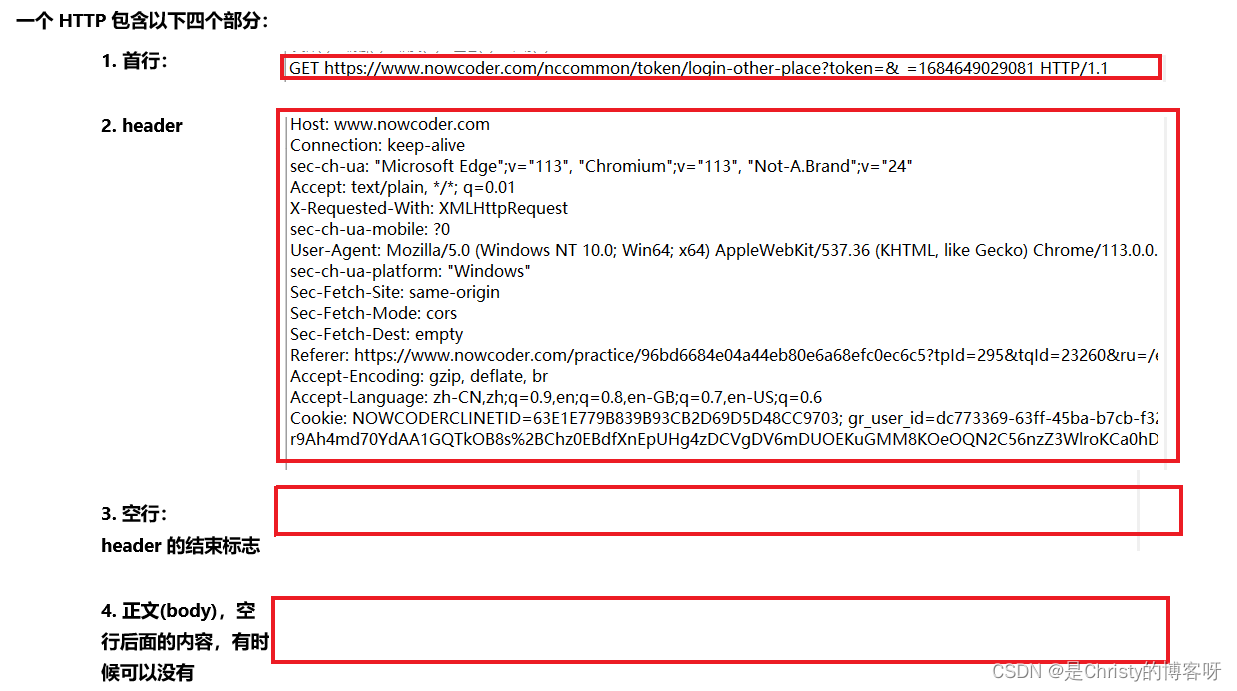
header 内容为键值对结构,每个键值对占一行,键和值之间,使用 冒号+空格 来分割。键值对有 N 行,最后用空行作为结束的标记,空行类似于链表中的 null。
POST 请求:
所有的 HTTP 请求中,GET 请求占了绝大部分,其次是 POST,剩余的为其余方法。
POST 请求,body 一般不为空,而 GET 请求,body一般为空。
POST 和 GET 同为请求,那有什么区别吗?
GET 和 POST 表示不同的语义,HTTP 方法的语义,只是一种建议,程序猿实际使用的时候,不一定非要遵守。对于 body 有没有的问题,也不是上述说的那么绝对。GET 也可能有 body,但非常少见,而 POST 也可以没有 body,也只是比较少见。
那两者之间,到底有什么区别呢?没有本质区别!使用 GET 的场景,替换成 POST 也可以。而使用 POST 的场景,替换成 GET 也行。
但两者在使用习惯上存在区别:
1. GET 习惯上用来表示 “获取一个数据”,POST 用来表示 “提交一个数据”。
2. GET 一般没有 body,需要携带数据,则放到 URL 中。POST 一般有 body。
3. GET 请求通常会设计成幂等,而 POST 则无要求。
在编程中,幂等的理解就是,在数据不变的情况下,一个操作,无论执行多少次,结果都是一样的。幂等在服务器开发中非常关键,设计成幂等之后,请求就可以缓存,后续重复请求可以直接使用,提高了响应速度,节省运算资源。
4. GET 是可缓存的,POST 则不能
5. GET 请求可以被浏览器收藏,而 POST 不能。
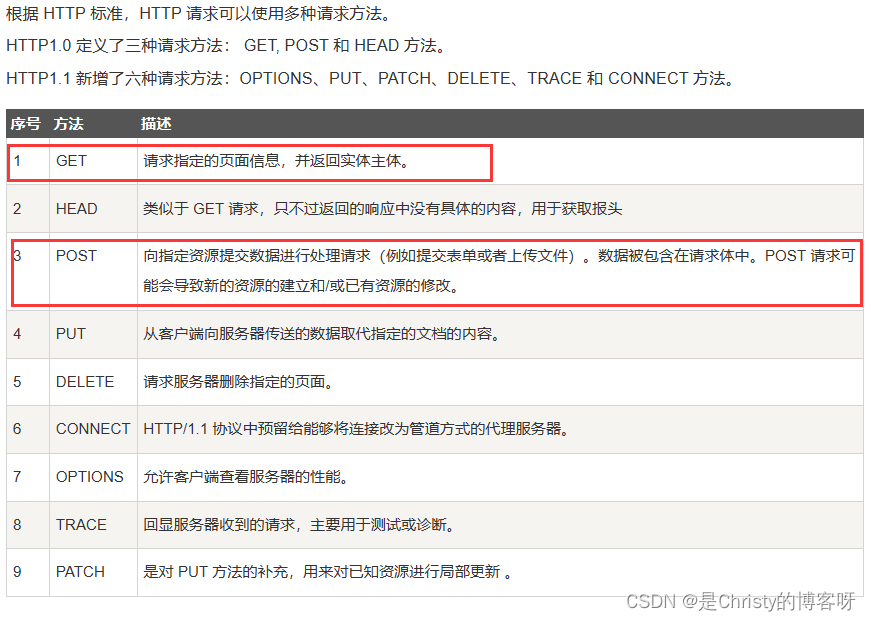
1.1 首行
打开必应搜索,fildder 抓包之后的首行:
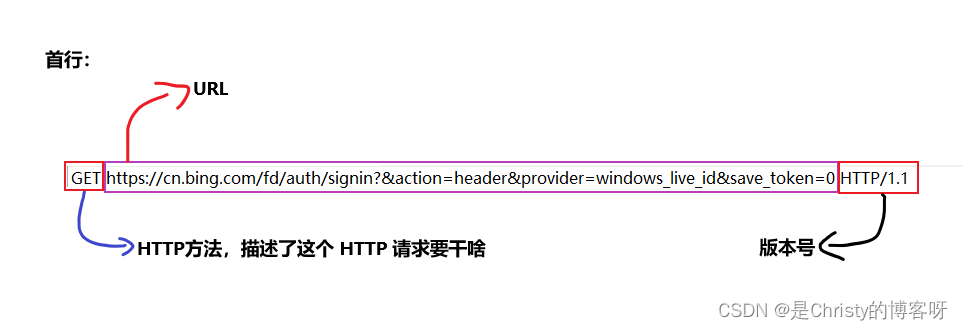
版本号有:
HTTP/1.0
HTTP/1.1
HTTP/2
HTTP/3
HTTP/1.1 是最主流的版本,绝大部分互联网的网站都是用的 1.1。
一般看到的请求大部分是 GET,但在登录时,或是上传文件时,可以看到 POST。
1.2 URL
URL :唯一资源定位符,描述了网络上唯一的一个资源。这个概念并非专属于 HTTP,很多协议都会用到 URL。
URL 的结构大概是这几个部分:


也可以举一个形象一点的例子:

在 URL 中,已经写了当前要访问的服务器是谁,为什么在 Host 中,还要再写一遍呢?
![]()
大多数情况下,Host 中的值和 URL 中的域名是一致的。但如果,当前我们访问的服务器,不是直接访问,而是通过 ”代理“ 来访问的,那么 Host 和 URL 就可能不一样。
1.3 Content-Type 和 Content-Length
Content-Type 描述了 body 的数据格式,Content-Length 描述了 body 的长度(字节)。这两个属性只有那些有 body 的请求才有。如果一个没有 body 的 GET 请求,它的 header 中就没有这两个属性。
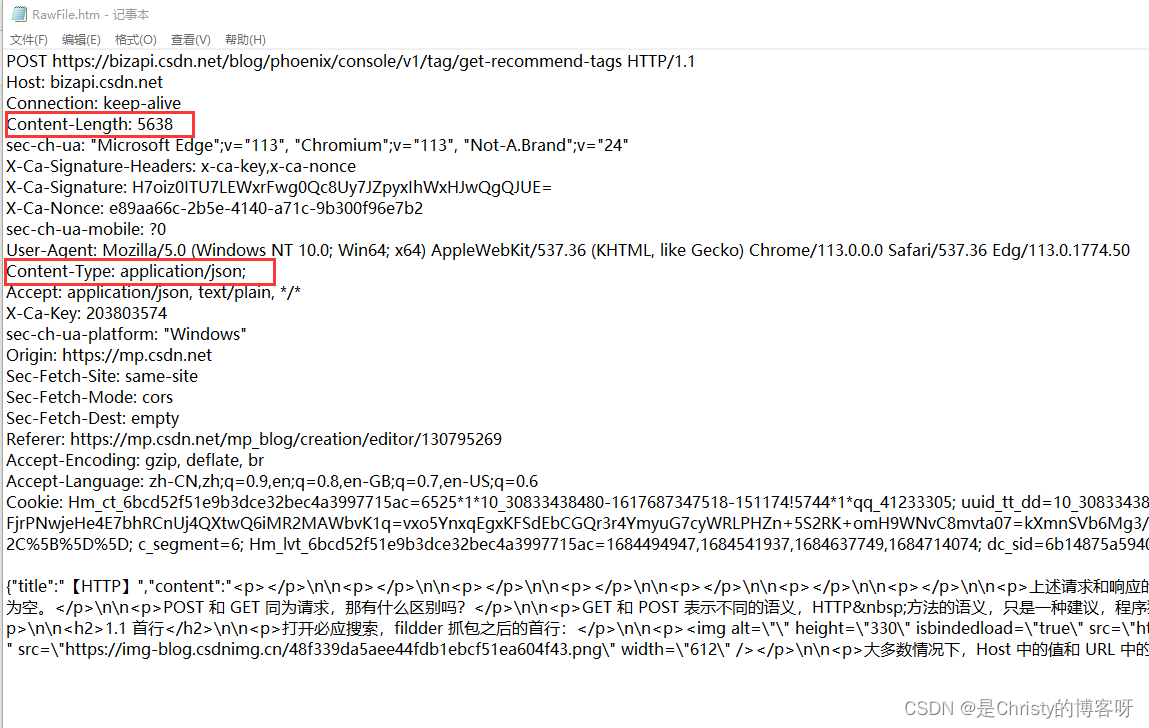
application/json ,表示数据的格式,描述了数据是按照 json 格式来组织的。 json 格式,用
{ } 来表示,里面包含若干键值对,键和值之间,用:分割,而键值对间用,分割。
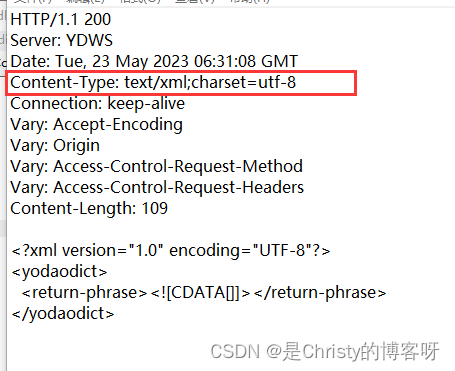
charset = utf-8,表示数据的字符集。
Content-Type 还有其他写法:Content-type: application/x-www-form-urlencoded。
Content-Type 作为请求时,最多只有上述两种写法。
而作为响应,Content-Type 还有以下几种写法:
text/html
text/css
application/javascript
application/json
image/jpg
image/png
......
有了这两个属性之后,浏览器/http 服务器,才能够认识到当前的 body,并正确的进行解析。
1.4 User-Agent
User-Agent,简称 UA。这一属性用来描述用户使用的浏览器版本以及操作系统的版本。

早期浏览器种类繁多,功能参差不齐,于是人们便发明了 User-Agent,这样就可以在请求中,告诉网站服务器,当前的上网设备是什么,这样一来,服务器就可以根据客户端的种类,返回相应的页面了。但随着时间的推移,浏览器发展到如今,相互间的差别越来越小,UA 也没必要区分浏览器类型。现在 UA 的一个重要用途,就是区分用户是手机/PC/平板。
1.5 Referer
Referer,描述了当前这个页面,是从哪个网页跳转过来的。如果直接在地址栏输入 url,此时请求中没有 referer。从收藏夹中点开某个链接,请求里也是没有 referer 的。
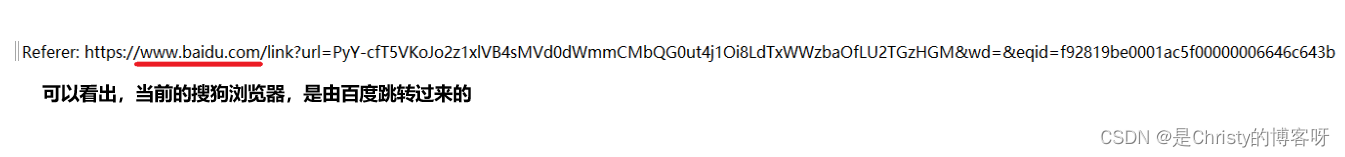
1.6 Cookie
Cookie 也是键值结构,键和值之间使用 = 分割,而键值对之间只用;分割。键值对具体意思,只有这个网站的开发者知道,这里的键值对是程序员自定义的数据,不同网站有不同的键值对,也就有了不同的含义。

Cookie 从服务器中来——当浏览器访问服务器时,服务器会在 HTTP 响应中,通过 Set-Cookie 字段,把 Cookie 的键值对返回给浏览器,浏览器接收这个数据,会在本地存储。
Cookie 再到服务器中去——浏览器在下一次请求时,把 cookie 带回给服务器。cookie 是由服务器来使用的。cookie 在浏览器这边,只能算 ”暂存“。
Cookie 是浏览器本地存储数据的机制,最典型的应用,就是存储用户的身份信息。
Cookie 的作用跟我们去医院看病使用的就诊卡很相似。第一次去医院看病,医院会让你办理就诊卡。办理就诊卡需要你的身份证、电话等信息。不管看什么科,医生见你的第一句话就是,刷一下就诊卡。那是因为,在就诊卡中有一个简单的芯片,存储了一个身份标识。在医院的机子一刷,电脑就会出现你的身份信息,包含姓名,身份证,年龄,性别,以及以往病例,当前开出的诊断,当前开出的药等。身份信息存储在医院的信息系统中。就诊卡就相当于 Cookie!!
2. HTTP 响应
响应可能是经过压缩的,本身是 http 文件,压缩成了二进制,能减少网络传输的数据量,节省带宽。把数据压缩,本质上是用 cpu 资源,换带宽资源。
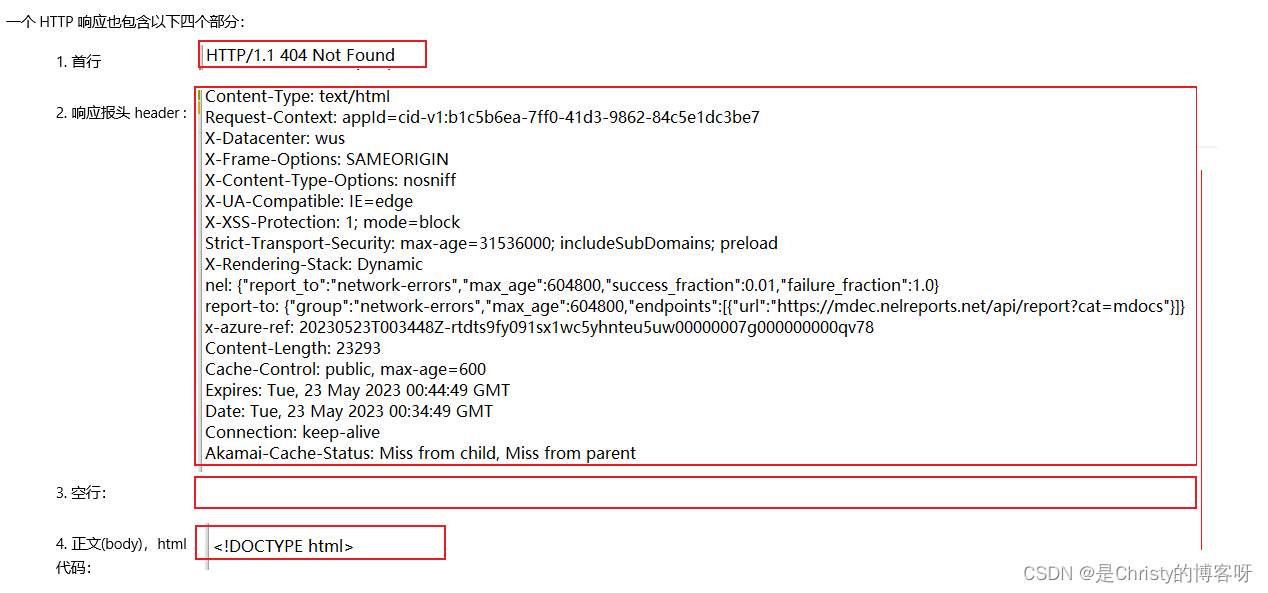
响应中的 body ,不仅包含 html,还包括 css、js、图片、字体等,那些浏览器上显示出来的内容,都是服务器返回的响应,携带的数据交给浏览器。
2.1 HTTP 响应 首行
HTTP 响应首行中,包含版本号以及状态码。
状态码就是数字,用来表示这次请求执行成功还是失败以及失败的原因。HTTP 中提供了很多状态码:

| 类别 | 原因短语 | |
| 1XX | Informational (信息性状态码) | 接收的请求正在处理 |
| 2XX | Success (成功状态码) | 请求正常处理完毕 |
| 3XX | Fedirection (重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error (客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error (服务器错误状态码) | 服务器处理请求出错 |
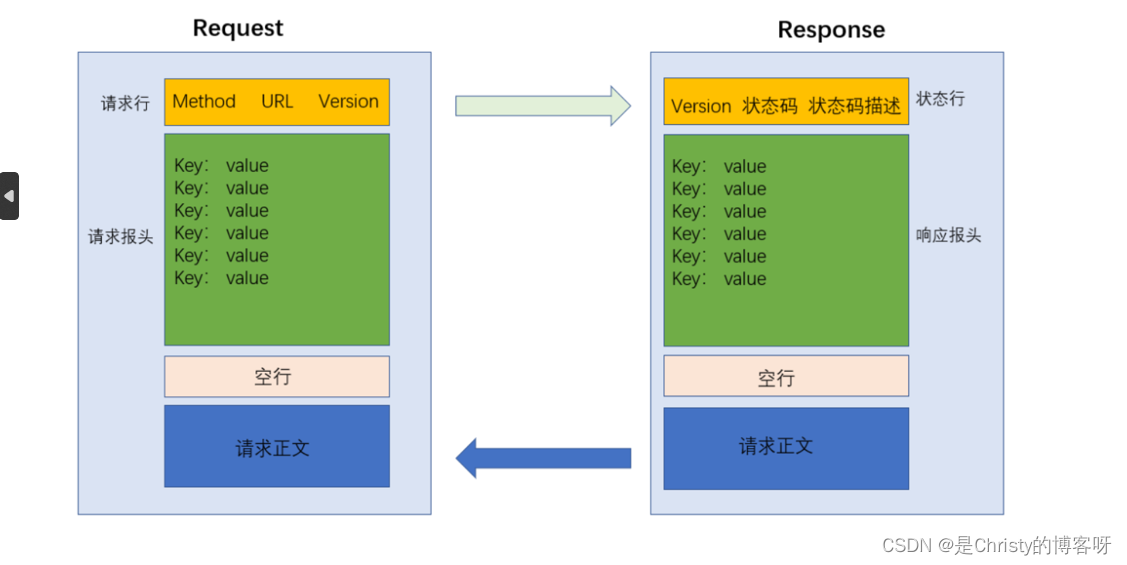
上述请求和响应的格式,可用下图表示:
3. 如何构造 HTTP 请求?
我们可以通过什么方式来构造一个 HTTP 请求?
1. 直接通过浏览器地址栏,输入一个 url,来构造出一个 GET 请求
2. html 中,一些特殊标签,也会触发 GET 请求,如
1) link
2) script
3) img
4) a
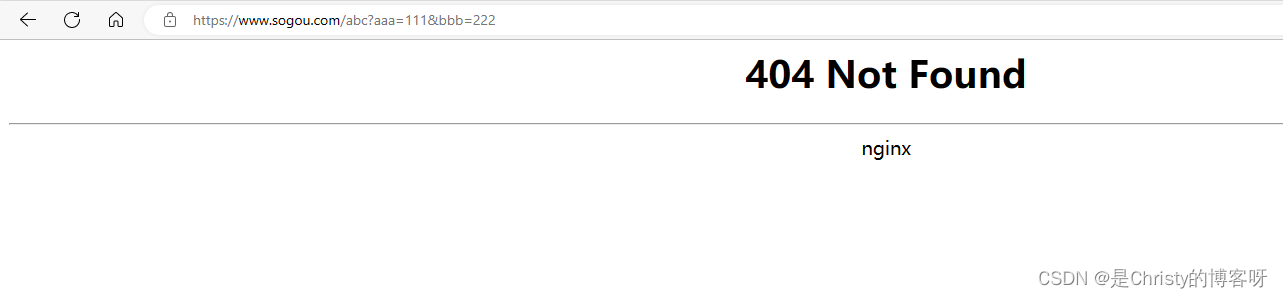
3. form 表单,可以触发 GET 和 POST 请求。
前两种,我们比较熟悉了,下面介绍第三种:
<form action="https://www.sogou.com/abc" method="get">
<input type="text" name="aaa">
<input type="text" name="bbb">
<input type="submit" value="提交">
</form>

<form action="https://www.sogou.com/abc" method="post">
<input type="text" name="aaa">
<input type="text" name="bbb">
<input type="submit" value="提交">
</form>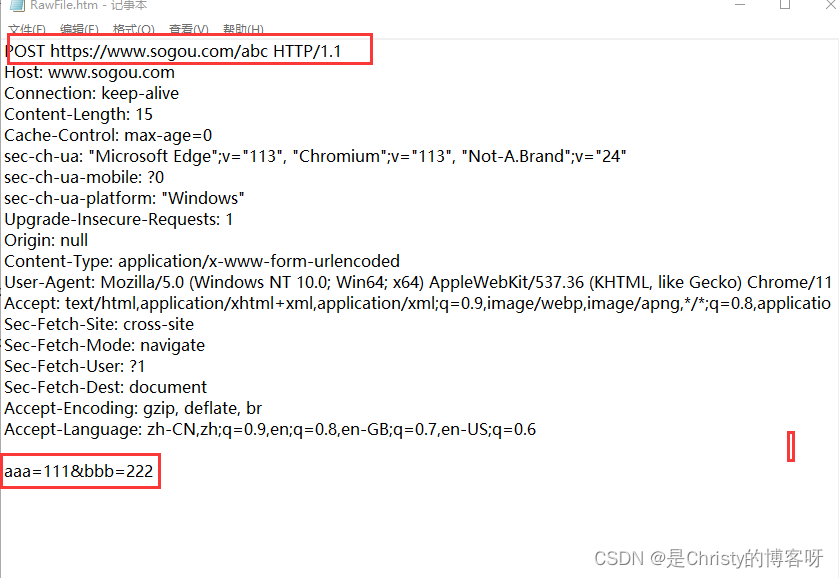
4. Ajax
Asynchronous JavaScript and XML ,缩写 Ajax,即异步的 JavaScript 和 XML 。
异步可能大家不熟悉,可是同步 (synchronized) 呢?在线程那篇文章中介绍的锁概念,它的英语单词也是 synchronized 。在计算机中,一个术语,在不同的场景下会有多种含义。synchronized 在加锁场景下,意味着多线程环境下,同一个资源,被一个线程访问时,其他也想访问的线程只能阻塞等待。只有等到这个线程解锁之后,其他线程才能抢占式访问。它的反义词是,互斥。而在 IO 场景下,synchronized 意味着请求的发起者,自行获取响应。而 Asynchronous 意味着请求的发起者不关心结果,而是由被请求者计算出结果之后,把结果推送给发起者。
XML 位于网络应用层的一种自定义的数据格式,同 html 一样,都是由标签构成的。 区别就在于,html 支持哪些标签,且这些标签具体啥含义,都是标准委员会规定的;而 xml 的标签都是自定义的。
ajax 是前端和后端异步交互的一种方式。推荐使用 jQuery 里面提供的 ajax api。
前端引入第三方库十分方便,可以直接写网络地址。
<script>
jQuery.ajax({
// ajax 可以有以下属性:
// url 当前请求要发给谁
url:"https://www.baidu.com/",
type:"get",
// 请求成功的话,使用回调函数来处理响应
success:function(body){
// 写处理响应的代码
}
});
</script>success 后面是回调函数,会在服务器返回一个正确的响应时,被浏览器自动执行。这个执行过程就是 “异步” 的。
在上述 js 代码中,把请求发出去之后就不管了,继续执行后续代码,直到响应回来了,浏览器会调用上述的 success 回调函数,执行处理响应的逻辑。
<script>
jQuery.ajax({
// ajax 可以有以下属性:
// url 当前请求要发给谁
url:"https://www.baidu.com/",
type:"post",
data:"这是body",
contentType:"text/plain",
// 请求成功的话,使用回调函数来处理响应
success:function(body){
// 写处理响应的代码
console.log(body);
}
});
</script>![]()
这是 ajax 的一个非常典型的问题,跨域问题。举例子:现在运行 ajax 的代码的页面域名为 abc.com,但是 ajax 里的请求,访问的域名是 def.com。两个域名不一样的话,哪怕服务器响应了数据,浏览器还是不能处理,还是要报错。这不是 bug,而是浏览器为了限制安全问题引入的保护机制,防止 a 网站的页面请求 b 网站的数据。
上述构造请求,都是要写代码的,但我们也可以用一些现成的工具,直接构造出 HTTP 请求,比如 postman。