目录
什么是BERT
BERT的架构
BERT的预训练任务
小节总结
BERT的特点
BERT和GPT的区别
笔记参考:【2023最新!4个小时带你重新认识【BERT+transformer】,详解self-attention,翻遍全网找不到比它更详细的了!!!】 https://www.bilibili.com/video/BV1JV4y1o7TP/?p=11&share_source=copy_web&vd_source=69ae8a9276e595b2c242a5fcedcd7dcc
原文链接:[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (arxiv.org)
什么是BERT
BERT是2018年10月由Google AI研究院提出的一种预训练模型。
- BERT的全称是Bidirectional Encoder Representation from Transformers。
- BERT在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且在11种不同NLP测试中创出SOTA表现。包括将GLUE基准推高至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7%(绝对改进5.6%),成为NLP发展史上的里程碑式的模型成就。
BERT的架构
总体架构:如下图所示最左边的就是BERT的架构图(图来源于Bing搜索),可以很清楚的看到BERT采用了Transformer Encoder Block进行连接,因此它是一个典型的双向编码模型。

从上面的架构图中可以看到,宏观上BERT分三个主要模块。
- 最底层黄色标记的Embedding模块 ---- 输入层(Embedding)
- 中间层蓝色标记的Transformer模块 ---- 编码层(Tansformer encoder)
- 最上层绿色标记的预微调模块 ---- 输出层
1. Embedding模块
BERT中的该模块是由三种Embedding共同组成,如下图所示(图来源于原文截图)
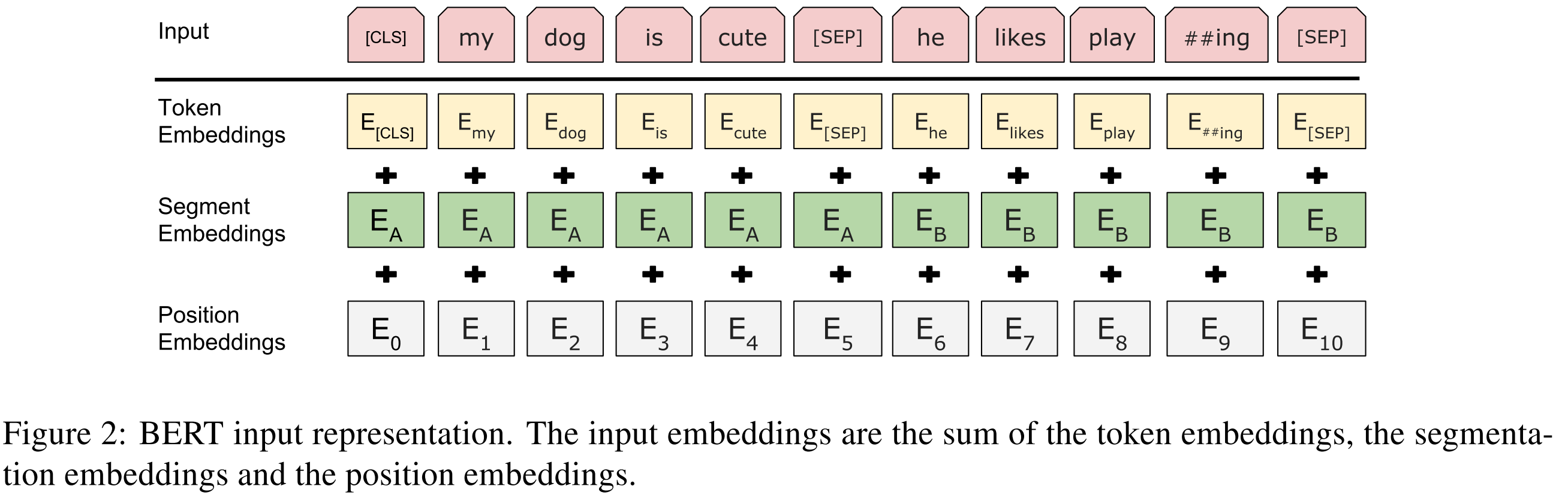
- Token Embeddings 是词嵌入张量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings 是句子分段嵌入张量,是为了服务后续的两个句子为输入的预训练任务
- Position Embeddings 是位置编码张量,此处注意,和传统的Transformer不同,不是三角函数计算的固定位置编码,而是通过学习得出来的,目前最大长度为 512
- 整个Embedding模块的输出张量就是这3个张量的直接加和结果
2. 双向Transformer模块
BERT中只使用了经典Transformer架构中的Encoder部分,完全舍弃了Decoder部分。而两大预训练任务也集中体现在训练Transformer模块中;
Encoder部分使用的是具有强大特征提取能力的Transformer的编码器,其同时具有RNN提取长距离依赖关系的能力和CNN并行计算的能力。这两种能力主要是得益于Transformer-encoder中的self-attention结构,在计算当前词的时候同时利用了它上下文的词使其能提取词之间长距离依赖关系;由于每个词的计算都是独立不互相依赖,所以可以同时并行计算所有词的特征。
3. 预微调模块
经过中间层Transformer的处理后,BERT的最后一层根据任务的不同需求而做不同的调整即可。
比如对于sequence-level的分类任务,BERT直接取第一个[CLS] token 的final hidden state再加一层全连接层后进行softmax来预测最终的标签。
对于不同的任务,微调都集中在预微调模块,几种重要的NLP微调任务架构图展示如下(图来源于原文截图):
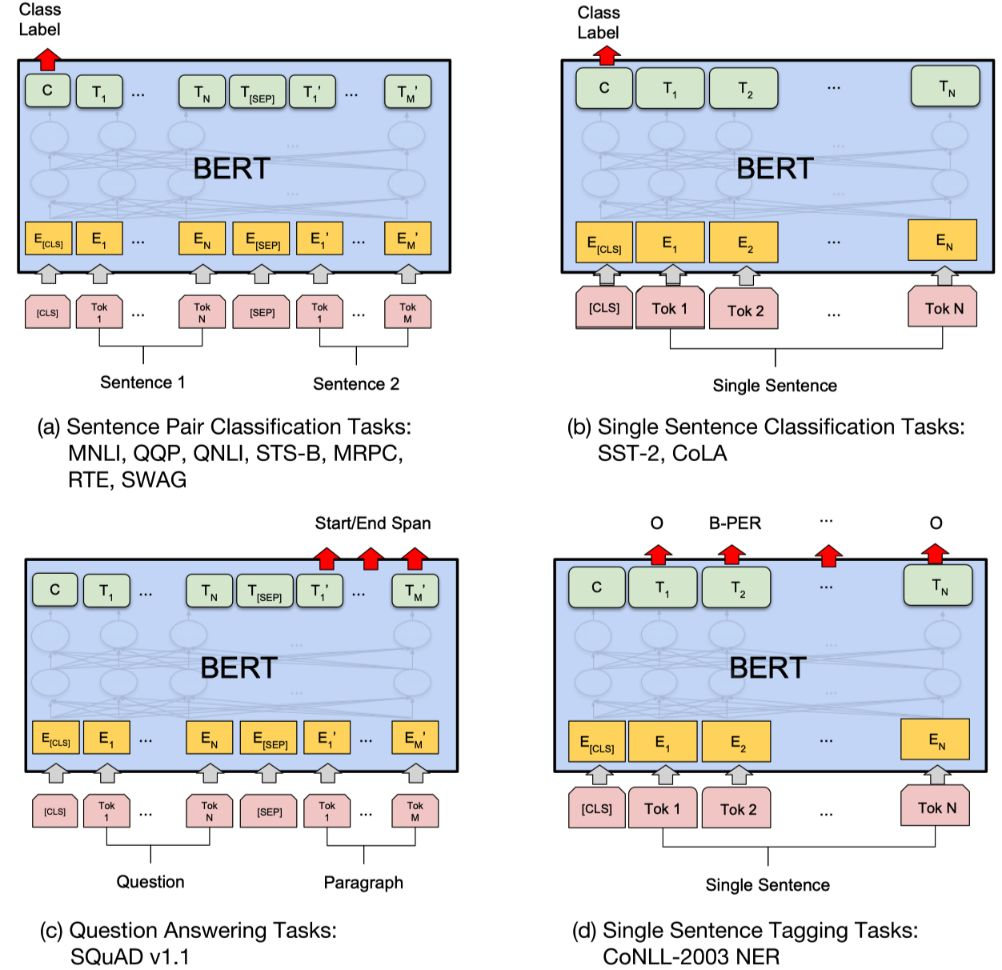
从上图中可以发现,在面对特定任务时,只需要对预微调层进行微调,就可以利用Transformer强大的注意力机制来模拟很多下游任务,并得到SOTA的结果。(句子对关系判断,单文本主题分类,问答任务(QA),单句贴标签(NER))
(a)句对分类
判断两句子之间的关系,如句子语义相似度、句子连贯性判定等,其本质是文本分类。
输入:两句子
输出:句子关系标签
(b)单句子文本分类
判断句子属于哪个类别,如新闻自动分类、问题领域分类等。
输入:一个句子
输出:输出句子类别标签
(c)抽取式问答
给定问答和一段文本,从文本中抽取出问题的答案,如机器阅读理解等。其本质是序列标注。
输入:一个问题,一段文本
输出:答案在文本中的索引
(d)单句子序列标注
给输入句子的每个token打上目标标签,如分词、词性标注、实体识别等。
输入:一段文本
输出:文本中每个token对应的标签
针对google开源的中文BERT模型和源码,对两类任务做微调的用法如下:
序列标注
(1)加载预训练Bert模型
(2)取输出字向量:embedding = bert_model.get_sequence_output()
(3)然后构建后续网络
文本分类
(1)加载预训练BERT模型
(2)取输出句向量:output_layer=bert_model.get_pooled_output()
(3)然后构建后续网络
对于BERT预训练模型的超参数建议如下:
batch size: 16, 32
learning rate (Adam): 5e-5, 3e-5, 2e-5
epochs:3, 4BERT的预训练任务
BERT包含两个预训练任务:
- 任务一:Masked LM(带mask的语言模型训练)
- 任务二:Next Sentence Prediction(句子连贯性判定)
任务一:Masked LM(带mask的语言模型训练)
关于传统的语言模型训练,都是采用 left-to-right,或者 left-to-right + right-to-left 结合的方式,但这种单向方式或者拼接的方式提取特征的能力有限。为此BERT提出一个深度双向表达模型(deep bidirectional representation),即采用MASK任务来训练模型。
在原始练文本中随机的抽取15%的token作为参与MASK任务的对象
在这些被选中的token中,数据生成器并不是把它们全部变成 [MASK],而是有下列3种情况
- 在80%的概率下,用[MASK]标记替换该token,比如 my dog is hairy -> my dog is [MASK]
- 在10%的概率下,用一个随机的单词替换token,比如 my dog is hairy -> my dog is apple
- 在10%的概率下,保持该token不变,比如 my dog is hairy -> my dog is hairy
模型在训练的过程中并不知道它将要预测哪些单词? 哪些单词是原始的样子?哪些单词被遮掩成了[MASK]? 哪些单词被替换成了其他单词?正是在这样一种高度不确定的情况下反倒逼着模型快速学习该token的分布式上下文的语义,尽最大努力学习原始语言说话的样子同时因为原始文本中只有15%的token参与了MASK操作,并不会破坏原语言的表达能力和语言规则。
任务二: Next Sentence Predictipn(下一句话预测任务)
在NLP中有一类重要的问题比如QA(Quention-Answer),NLI(NaturalLanguage Inference)需要模型能够很好的理解两个句子之间的关系,从而需要在模型的训练中引入对应的任务。在BERT中引入的就是Next Sentence Prediction任务,采用的方式是输入句子对(A,B)模型来预测句子B是不是句子A的真实的下一句话。
所有参与任务训练的语句都被选中作为句子A
- 其中50%的B是原始文本中真实跟随A的下一句话 (标记为IsNext,代表正样本)
- 其中50%的B是原始文本中随机抽取的一句话 (标记为NotNext,代表负样本)
在任务二中BERT模型可以在测试集上取得97%-98%的准确率
BERT预训练任务——笔记
任务一:MLM任务(mask的语言模型任务)
随机抽取15%token 作为MASK对象
- 在80%概率下使用MASK替换为token
- 10%的概率,使用随机单词得换token
- 10%的概率,保持token不变
任务二:NSP任务(下一句的预测任务)
- 50%句子是源语句真实的下一句话,标记IsNext 正样本
- 50%句子不是源语句的真实的下一句话,标记NotNext 负样本
小节总结
学习了什么是BERT
- BERT是一个基于Transformer Encoder的预训练语言模型。BERT在11种NLP测试任务中创出SOAT表现
学习了BERT的结构
- 最底层的Embedding模块,包括Token Embeddings,Segment Embeddings, Position Embeddings
- 中间层的Transformer模块,只使用了经典Transformer架构中的Encoder部分
- 最上层的预微调模块,具体根据不同的任务类型来做相应的处理
学习了BERT的两大预训练任务
MLM任务(Masked Language Model),在原始文本中随机抽取15%的token参与任务
- 在80%概率下用[MASK]替换该token
- 在10%概率下,用一个随机的单词替换该token
- 在10%概率下,保持该token不变
NSP任务(Next Sentence Prediction),采用的方式是输入句子对(A,B),模型预测句子B是不是句子A的真实的下一句话
- 其中50%的B是原始文本中真实跟随A的下一句话 (标记为IsNext,代表正样本)
- 其中50%的B是原始文本中随机抽取的一句话 (标记为NotNext,代表负样本)
BERT的特点
(1)真正的双向:使用双向 Transformer,能同时利用当前单词的上下文信息来做特征提取,这与双向RNN分别单独利用当前词的上文信息和下文信息来做特征提取有本质不同,与CNN将上下文信息规定在一个限定大小的窗口内来做特征提取有本质不同;
(2)动态表征:利用单词的上下文信息来做特征提取,根据上下文信息的不同动态调整词向量,解决了word2vec一词多义的问题;
(3)并行运算的能力:Transformer组件内部使用自注意力机制(self-attention),能同时并行提取输入序列中每个词的特征。
(4)易于迁移学习:使用预训练好的BERT,只需加载预训练好的模型作为自己当前任务的词嵌入层,后续针对特定任务构建后续模型结构即可,不需对代码做大量修改或优化。
BERT和GPT的区别
BERT和GPT都是基于Transformer架构的预训练语言模型,但在一些关键方面有所不同。
预训练任务
BERT采用的是Masked Language Model (MLM)和Next Sentence Prediction (NSP) 两个任务。其中,MLM任务是将输入文本中的一部分随机被遮挡掉,然后模型需要根据上下文预测这些遮挡掉的词是什么;NSP任务则是判断两个句子是否是相邻的。这两个任务使得BERT在理解句子内部和句子之间的关系方面都具有很好的表现。
GPT则采用的是单一的预测任务,即语言模型。该模型通过训练预测一个序列中下一个单词的概率分布,从而学习到文本中单词之间的关系。
训练数据
BERT的训练数据来自于网页文本和书籍,因此涵盖了非常广泛的领域和主题。
而GPT则主要采用了新闻和维基百科等文章,使其在学术和知识层面的表现更好。
网络结构
BERT是一个双向的Transformer Encoder,通过自注意力机制来学习句子内部和句子之间的关系。
而GPT是一个单向的Transformer Decoder,仅通过自注意力机制学习句子内部的关系。
应用场景
由于BERT具有双向性和广泛的训练数据,因此在自然语言理解的任务中表现非常出色。而GPT则在生成自然语言的任务中表现更加突出,比如文本摘要、对话生成和机器翻译等方面。
主要区别在于两者要解决的问题不同,BERT(完形填空),GPT(预测未来)。BERT主要用于自然语言理解的任务,而GPT则主要用于生成自然语言的任务。