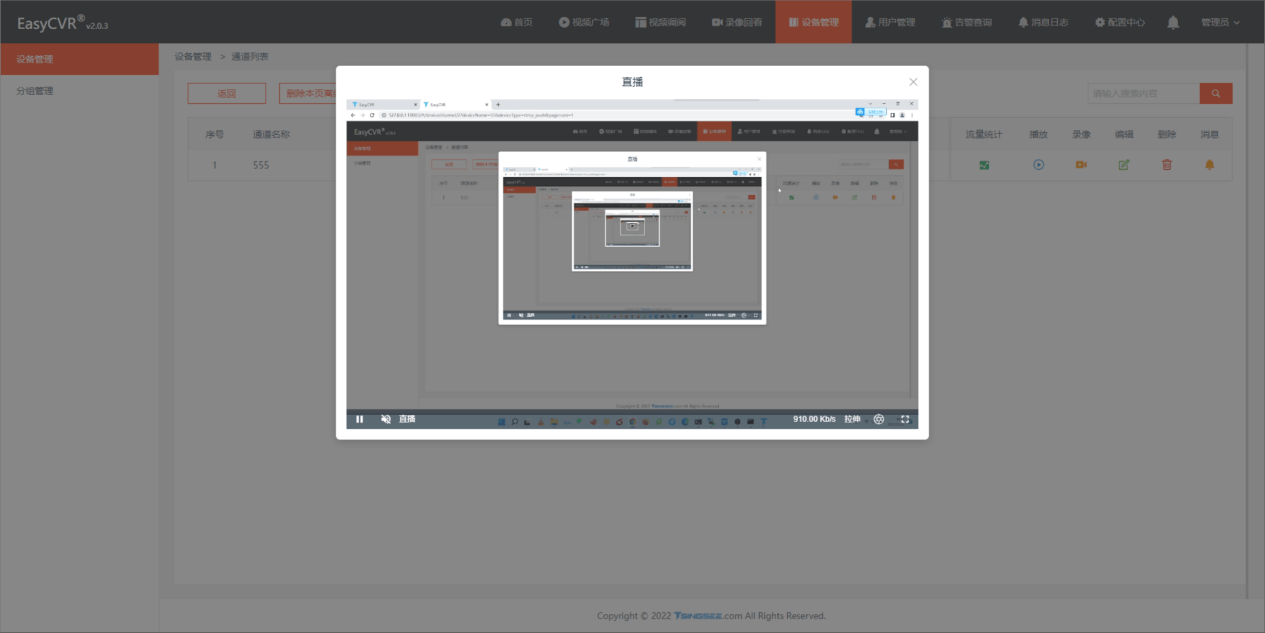
YOLOv3模型为苹果开发者官网提供的图形识别对象的CoreML模型,可识别80种对象,并给识别出的对象在图形中的位置和大小。
我们可以直接在官网下载该模型:
机器学习 - 模型 - Apple Developer
然后直接将模型拖入工程中(使用的是xcode14.3),xcode会自动根据模型生成对应的工具类YOLOv3,该类文件不可修改。在工程中我们可以查看模型的信息:
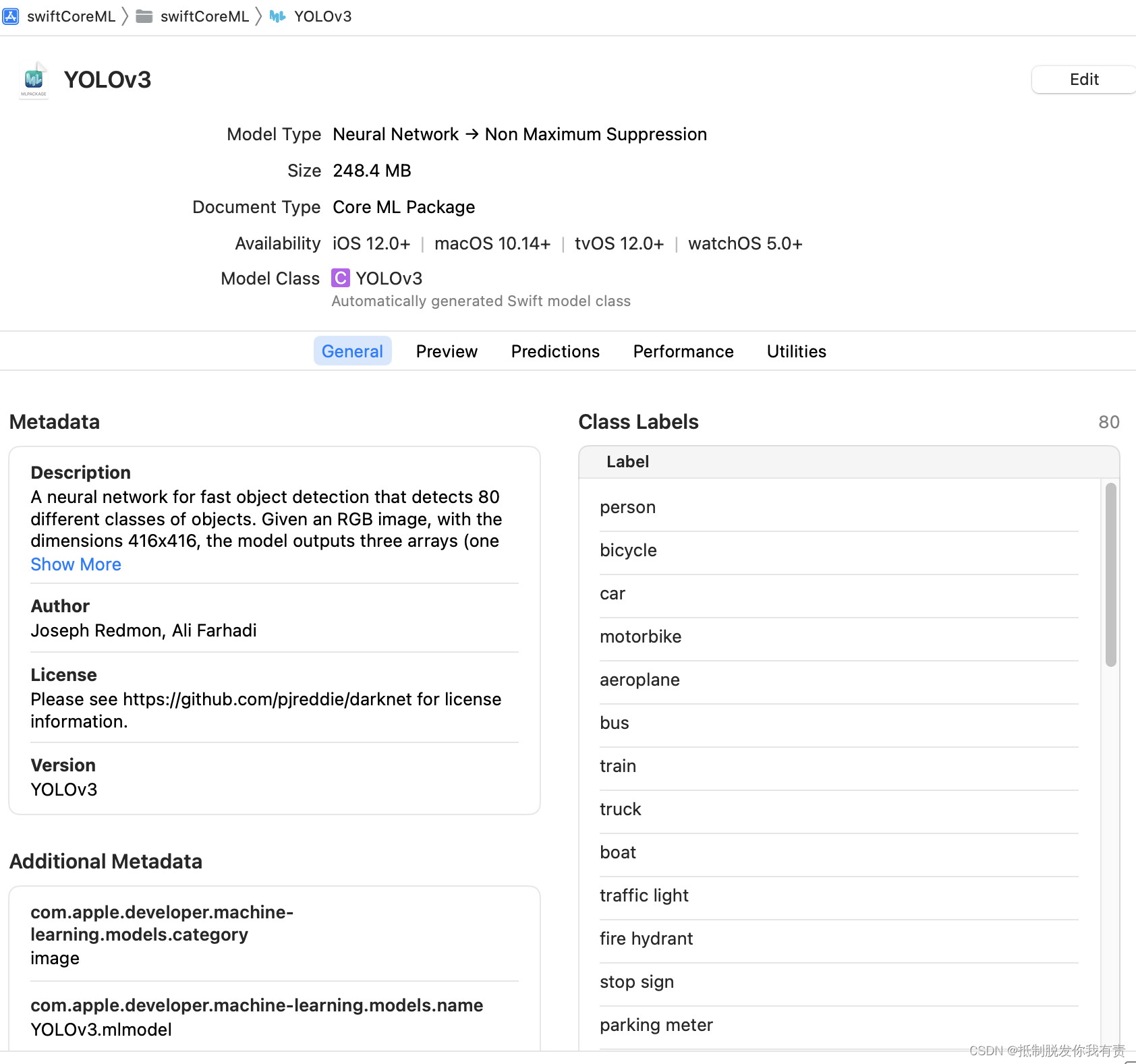
我们可以点击该浏览页面中的Model Class查看自动生成YOLOv3工具类。在浏览页面中我们看到下方有几个tab选择,重点的tab介绍:
General:模型的描述信息,重要的是Class Label,这个清单中列出了可识别的80种对象名称。
Preview:直接体验模型的预测效果,感兴趣可在该tab下拖入图片进行预览。
Prediction:描述了模型的输入输出信息。
接下来,我们可以在工程中使用该模型进行预测了,demo代码如下(YOLOv3类无需import):
do {
let config:MLModelConfiguration = MLModelConfiguration()
let model:YOLOv3! = try YOLOv3(configuration: config)
if model != nil {
//为了方便,我直接拿了asset中的照片
let image:UIImage? = UIImage(named: "IMG_0096")
if image != nil {
let input:YOLOv3Input = try YOLOv3Input(imageWith: image!.cgImage!)
let outPut:YOLOv3Output = try! model.prediction(input: input)
print("识别成功")
print(outPut.coordinates.count)
}else{
print("图片读取失败")
}
}else{
print("模型初始化失败")
}
}catch{
print(error)
}
代码中涉及三个类:
YOLOv3:模型类,其实例也可以理解为模型本身。
YOLOv3Input:输入对象。
YOLOv3Output:识别结果输出对象。
代码中,outPut对象包含了所有的识别数据,coordinates属性值代表识别出的物体对象的坐标和大小数据,confidence属性值代表识别出的物体对象的概率值。
coordinates:元素为包含4个double值的数组,每个double值依次代表识别出的物体在图片中的相对坐标和宽高:
- x:识别对象的中心点距离图片左侧的像素相对图片宽度像素的比例;
- y:识别对象的中心点距离图片顶部的像素相对图片宽度像素的比例;
- w:识别对象的宽度相对图片宽度的比例;
- h:识别对象的高度相对图片高度的比例;
confidence:元素为包含80个double值的数组,每个double值依次代表识别出的物体属于80种对象分类的概率。
在经过艰难的查找后,始终无法通过api获取80种对象分类名称的值,只能通过模型浏览看到,最后在控制台找到对应的属性,但是无法通过YOLOv3对象获取,控制台中打印出的80种对象分类名称:
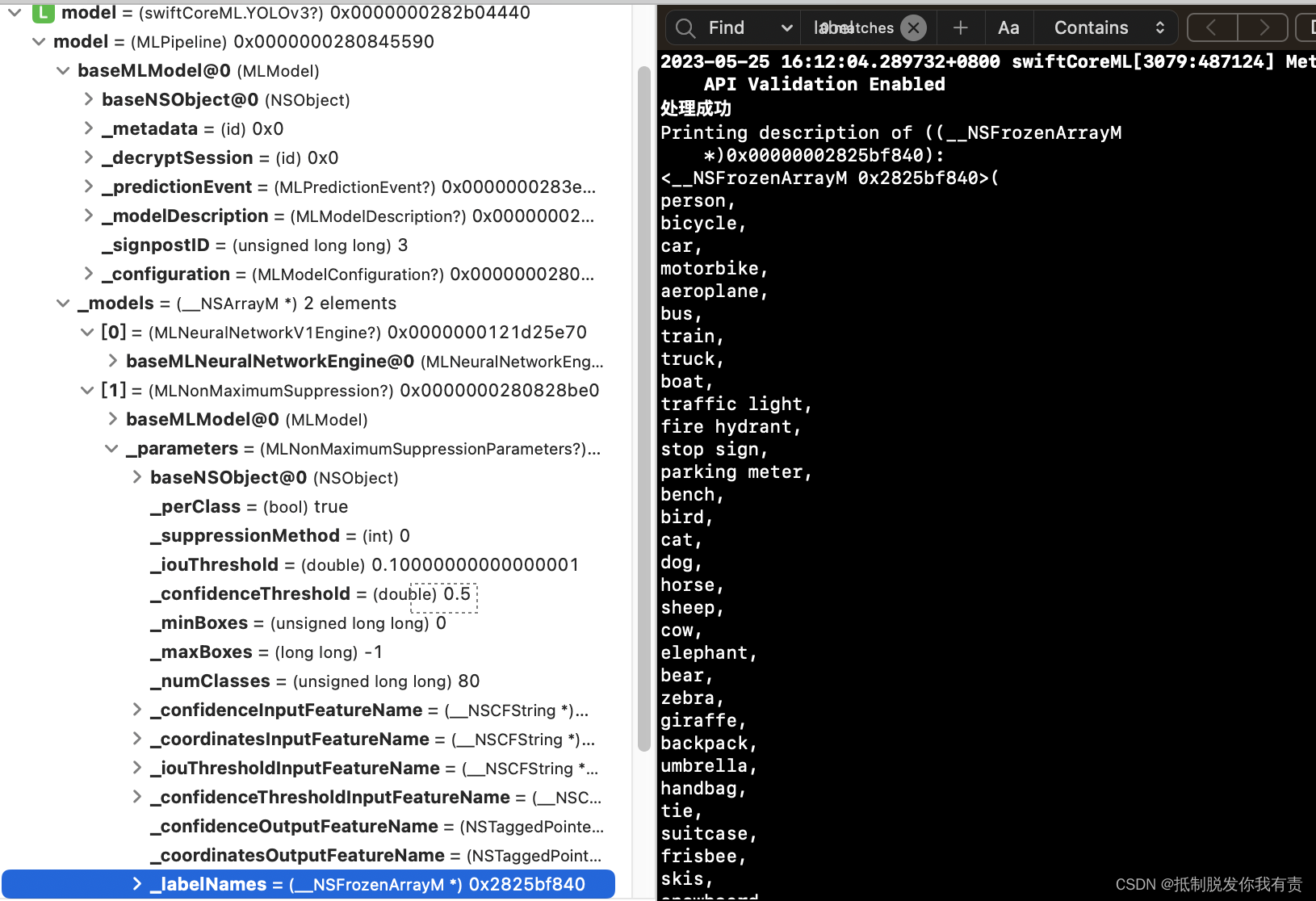
如果后续找到友好方式获取Class Label的方式再补上。