一、hiveSQL执行顺序
from … where … mapjoin … on … select(筛选有用字段) … group by ||… join … on … select(筛选输出字段) … having … distinct … order by … limit … union/union all
|| 前是map阶段执行,后的reduce阶段执行
以如下hql为例:
select
sum(b.order_amount) sum_amount,
count(a.userkey) count_user
from user_info a
left join user_order b on a.idno=b.idno
where a.idno > '112233'
group by a.idno
having count_user > 1
limit 10;
hql执行顺序如下:
Map 阶段:
1、执行 from,进行表的查找与加载,注意要join的表也要加载进来(MapJoin除外);
2、执行 where,注意: sql 语句中 left join 写在 where 之前的,但是实际执行先执行 where 操作,因为 Hive 会对语句进行优化,如果符合谓词下推规则,将进行谓词下推;
3、如果join的是小表,可以执行 Map join 操作,按照 key 进行表的关联;
4、执行输出列的操作,注意: select 后面只有两个字段(order_amount,userkey),此时 Hive 是否只输出这两个字段呢,当然不是,因为 group by 的是 idno,如果只输出 select 的两个字段,后面 group by 将没有办法对 idno 进行分组,所以此时输出的字段有三个:idno,order_amount,userkey,所以这个select的作用是筛选出需要用到的字段,所以我们在写hql时最好不要用select *;
5、执行 map 端的 group by,此时的分组方式采用的是哈希分组,按照 idno 分组,进行 order_amount 的 sum 操作和 userkey 的 count 操作,最后按照 idno 进行排序(group by 默认会附带排序操作);
Reduce 阶段:
1、执行 reduce 端的 group by,此时的分组方式采用的是合并分组,对 map 端发来的数据按照 idno 进行分组合并,同时进行聚合操作 sum(order_amount)和 count(userkey);
2、执行 select,此时输出的就只有 select 的两个字段:sum(order_amount) as sum_amount,count(userkey) as count_user;
3、执行 having,此时才开始执行 group by 后的 having 操作,对 count_user 进行过滤,注意:因为上一步输出的只有 select 的两个字段了,所以 having 的过滤字段只能是这两个字段;
4、执行 limit,限制输出的行数为 10。
二、HiveSql数据转化过程
以下面sql为例:
hive> SELECT * FROM logs;
OK
a 苹果 5
a 橙子 3
b 烧鸡 1
hive> SELECT * FROM users;
OK
a 23
b 21
hive> SELECT a.uid,a.name,b.age FROM logs a JOIN users b ON (a.uid=b.uid);
a 苹果 23
a 橙子 23
b 烧鸡 21
计算过程:

Map阶段只是拆分key和value。
key这里后面的数字是tag,后面在reduce阶段用来区分来自于那个表的数据。tag是附属在key后面的。那为什么会把a(0)和a(1)汇集在一起了呢,是因为对先对a求了hashcode,设在了HiveKey上,所以同一个key还是在一起的。
reduce阶段主要看它是如何把它合并起来了,从图上可以直观的看到,其实就是把tag=1的内容,都加到tag=0的后面,就是这么简单。
代码实现上,就是先临时用个变量把值存储起来在storage里面, storage(0) = [{a, 苹果}, {a, 橙子}] storage(1) = [{23}],当key变化(如a变为b)或全部结束时,会调用endGroup()方法,把内容合并起来。变成[{a,苹果,23}, {a, 橙子,23}]
通过Explan查看执行过程
hive> explain SELECT a.uid,a.name,b.age FROM logs a JOIN users b ON (a.uid=b.uid);
OK
//语法树
ABSTRACT SYNTAX TREE:
(TOK_QUERY (TOK_FROM (TOK_JOIN (TOK_TABREF (TOK_TABNAME logs) a) (TOK_TABREF (TOK_TABNAME users) b) (= (. (TOK_TABLE_OR_COL a) uid) (. (TOK_TABLE_OR_COL b) uid)))) (TOK_INSERT (TOK_DESTINATION (TOK_DIR TOK_TMP_FILE)) (TOK_SELECT (TOK_SELEXPR (. (TOK_TABLE_OR_COL a) uid)) (TOK_SELEXPR (. (TOK_TABLE_OR_COL a) name)) (TOK_SELEXPR (. (TOK_TABLE_OR_COL b) age)))))
//阶段
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-1
Map Reduce
Alias -> Map Operator Tree: //mapper阶段
a
TableScan //扫描表, 就只是一行一行的传递下去而已
alias: a
Reduce Output Operator //输出给reduce的内容
key expressions: // key啦,这里的key是uid,就是我们写在ON子句那个,你可以试试加多几个条件
expr: uid
type: string
sort order: + //排序
Map-reduce partition columns://分区字段,貌似是和key一样的
expr: uid
type: string
tag: 0 //用来区分这个key是来自哪个表的
value expressions: //reduce用到的value字段
expr: uid
type: string
expr: name
type: string
b
TableScan //扫描表, 就只是一行一行的传递下去而已
alias: b
Reduce Output Operator //输出给reduce的内容
key expressions: //key
expr: uid
type: string
sort order: +
Map-reduce partition columns: //分区字段
expr: uid
type: string
tag: 1 //用来区分这个key是来自哪个表的
value expressions: //值
expr: age
type: int
Reduce Operator Tree: // reduce阶段
Join Operator // JOIN的Operator
condition map:
Inner Join 0 to 1 // 内连接0和1表
condition expressions: // 第0个表有两个字段,分别是uid和name, 第1个表有一个字段age
{VALUE._col0} {VALUE._col1}
{VALUE._col1}
handleSkewJoin: false //是否处理倾斜join,如果是,会分为两个MR任务
outputColumnNames: _col0, _col1, _col6 //输出字段
Select Operator //列裁剪(我们sql写的select字段)
expressions:
expr: _col0
type: string
expr: _col1
type: string
expr: _col6
type: int
outputColumnNames: _col0, _col1, _col2
File Output Operator //把结果输出到文件
compressed: false
GlobalTableId: 0
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Stage: Stage-0
Fetch Operator
limit: -1
三、谓词下推
虽然hive或spark会为我们优化sql,进行谓词下推,但还是要了解并且养成良好的书写习惯
概括:所谓谓词下推,就是将尽可能多的判断更贴近数据源,以使查询时能跳过无关的数据。用在SQL优化上来说,就是先过滤再做聚合等操作
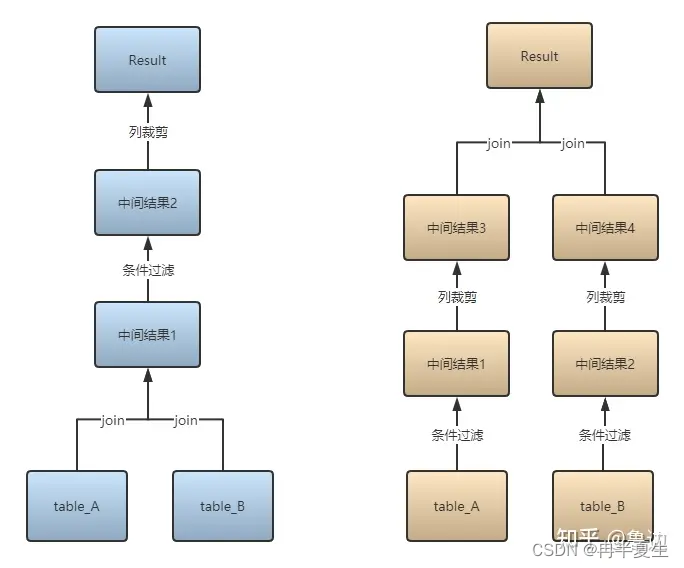
看图和文字有些抽象,举例论证:
就是将这个sql
select count(0)
from A Join B on A.id = B.id
where A.a > 10 and B.b < 100;
转化为:
select count(0)
from (
select id from A where a>10
) A1
Join (
select id from B where b<100
) B1 on A1.id = B1.id;
通过查看执行计划,可以看到,在处理Join操作之前需要首先对A和B执行TableScan操作,然后再进行Join,再执行过滤,最后计算聚合函数返回,但是如果把过滤条件 A.a > 10 和 B.b < 100 分别移到A表的TableScan和B表的TableScan的时候执行,可以大大降低Join操作的输入数据
四、Hive查询操作优化
1、数据清洗
- 读取表时分区过滤,避免全表扫描。
- 数据过滤之后再JOIN。
- 重复使用数据时,避免重复计算,构建中间表,重复使用中间表。
2、数据倾斜
数据倾斜: shuffle之后Key的分布不均导致分配到 Reduce 端的数据不均匀,出现个别 Reduce 的数据过大,执行时间过长而出现的现象。
数据倾斜的表现: 而当其中每一组的数据量过大时,会出现其他组的计算已经完成而这里还没计算完成,其他节点的一直等待这个节点的任务执行完成,所以会看到一直map 100% reduce 99%的情况,大概率是发生了数据倾斜。
容易造成数据倾斜产生的原因:
- 数据业务本身的特性,如某作为key值的字段重复较多
- 小表join大表,join时其中一个表较小,但是key集中分发到某一个或几个Reduce上的数据远高于平均值
- join时,大表与大表关联,但是很多数据没关联上,导致产生了空值
- count(distinct) 时某特殊值过多,导致数据倾斜
- group by 时因为分区不合理导致数据倾斜,如group by 的字段某类值过多导致数据倾斜
总结:让map节点的输出数据更均匀的分布到reduce节点中去,是解决数据倾斜的最终目标。
3、数据倾斜优化
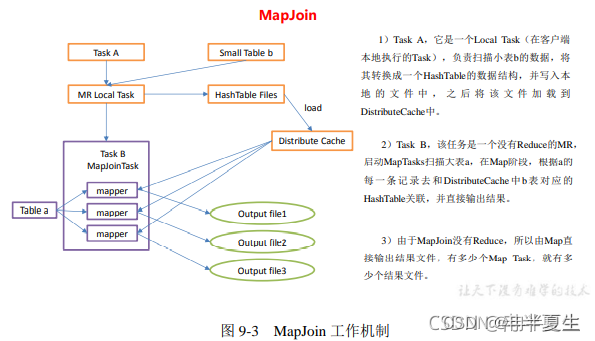
①小表 join 大表解决方案
通过设置
hive.auto.convert.join=true;
hive.mapjoin.smalltable.filesize=25000000; \\25M
该参数能将小表(小于hive.mapjoin.smalltable.filesize该配置的表)先加载在Map端进行Join操作
②大表 join 大表解决方案
(1)空Key过滤:有时可能因为key为空的数据量过多,空值都到一个Reduce端,导致出现数据倾斜,此时我们可以在join之前将Key为空的数据过滤掉。
(2)空Key转换:有时可能某些Key为空,但对应的数据并不是异常数据,此时不能简单的进行过滤,我们可以通过将空Key进行转换,例如将Key转换成一个字符串加上一个随机数:concat(‘Null’ + rand()),就能把倾斜的数据分到不同的reduce上
③count(distinct )大量相同特殊值或数据量较大
当数据量毕竟较大时,count操作中只有一个Reduce,那么这个Reduce就会很难完成任务。此时,可以通过Group By + Count的方式替换
如:
-- 优化前
select count(distinct id) from tablename;
-- 优化后
select count(1) from (select distinct id from tablename) tmp;
select count(1) from (select id from tablename group by id) tmp;
4、join过程中出现数据倾斜产生解决方案
对于join过程来说,如果出现较多的key值为空或异常的记录,或key值分布不均匀,就容易出现数据倾斜,可以通过如下配置
-- 如果是join过程中出现倾斜 应该设置为true
set hive.optimize.skewjoin=true;
-- 这个是join的键对应的记录条数,超过这个值则会进行优化
set hive.skewjoin.key=100000;
由于Hive 在join的时候会将相同的key 在最后都汇聚到同一个Reduce 进行处理 , 所以当Join 操作中某个表中的一些Key 数量远远大于其他,则处理该Key的Reduce 将成为瓶颈 .
如 :
select a.* , b.*
from table_a a
join table_b b on a.id =b.id;
如果table_a中的id数量远多于table_a中的其他id ,则会数据倾斜;
该配置适用范围:

看一下GenMRSkewJoinProcessor.skewJoinEnabled方法的实现:
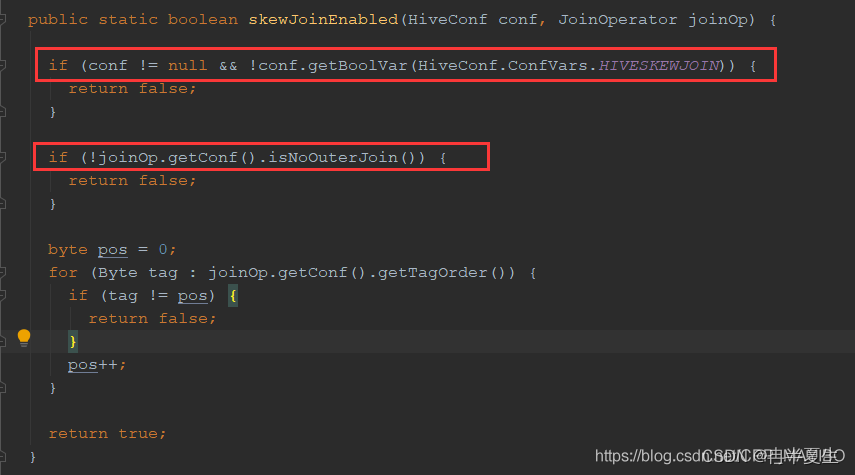
从上面的代码中,可以看到要使用skew join优化,必须满足如下的条件:
1、开启优化特性,也就是hive.optimize.skewjoin配置项必须是true,默认是false
2、不能是outer join,这里的outer join包括:UNION JOIN,LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN 这几种join
5、group by产生数据倾斜
对于group by 过程来说,如果某一个key值有特别的多的记录,其它key值的记录比较少,容易出现数据倾斜,可以通过如下配置
-- 开启map端聚合
set hive.map.aggr=true;
-- 用于设定Map端进行聚合操作的条目数
set hive.groupby.mapaggr.checkinterval=100000;
-- 可以对Key随机化打散,多次聚合,当选项设定为true时,生成的查询计划有两个MapReduce任务
set hive.group.skewindata=true;
控制生成两个MR Job,第一个MR Job Map的输出结果随机分配到Reduce中减少某些key值条数过多某些key条数过小造成的数据倾斜问题。
在第一个 MapReduce 中,map 的输出结果集合会随机分布到 reduce 中, 每个reduce 做部分聚合操作,并输出结果。这样处理的结果是,相同的 Group By Key 有可能分发到不同的reduce中,从而达到负载均衡的目的;
第二个 MapReduce 任务再根据预处理的数据结果按照 Group By Key 分布到 reduce 中(这个过程可以保证相同的 Group By Key 分布到同一个 reduce 中),最后完成最终的聚合操作。