系列文章目录
Linux 内核设计与实现
深入理解 Linux 内核(一)
深入理解 Linux 内核(二)
Linux 设备驱动程序(一)
Linux 设备驱动程序(二)
Linux 设备驱动程序(三)
Linux设备驱动开发详解
深入理解Linux虚拟内存管理
文章目录
- 系列文章目录
- 第1章 简介
- 第2章 描述物理内存
- 2.1 节点
- 2.2 管理区
- 2.2.1 管理区极值
- 2.2.2 计算管理区大小
- 2.2.3 管理区等待队列表
- 2.3 管理区初始化
- 2.4 初始化mem_map
- 2.5 页面
- 2.6 页面映射到管理区
- 2.7 高端内存
- 2.8 Linux2.6版本 中有哪些新特性
- 二、补充配置
- 1、空格
- 2、文字颜色
- 3、文字大小
- 4、字体
第1章 简介
- 开始启程
- 管理源码
- 浏览代码
- 阅读代码
- 提交补丁
第2章 描述物理内存
Linux 适用于广泛的体系结构,因此需要用一种与体系结构无关的方式来描述内存。本章描述了用于记录影响 VM 行为的内存簇、页面和标志位的结构。
在 VM 中首要的普遍概念就是非一致内存访问(NUMA)。对大型机器而言,内存会分成许多簇,依据簇与处理器 “距离” 的不同,访问不同的簇会有不同的代价。比如,可能把内存的一个簇指派给每个处理器,或者某个簇和设备卡很近,很适合内存直接访问(DMA),那么就指派给该设备。
每个簇都被认为是一个节点,在 Linux 中的 struct pg_data_t 体现了这一概念,既便在一致内存访问(UMA)体系结构中亦是如此。该结构通常用 pg_data_t 来引用。系统中的每个节点链接到一个以 NULL 结尾的 pgdat_list 链表中,而其中的每个节点利用 pg_data_t node_next 字段链接到下一个节点。对于像 PC 这种采用 UMA 结构的机器,只使用了一个称作 contig_page_data 的静态 pg_data_t 结构。在 2.1 节中会对节点作进一步的讨论。
struct pg_data_t 在内存中,每个节点被分成很多的称为管理区(zone)的块,用于表示内存中的某个范围。不要混淆管理区和基于管理区的分配器,因为两者是完全不相关的。一个管理区由一个 struct zone_struct 描述,并被定义为 zone_t ,且每个管理区的类型都是 ZONE_DMA,ZONE_NORMAL 或者 ZONE_HIGHMEM 中的一种。不同的管理区类型适合不同类型的用途。ZONE_DMA 指低端范围的物理内存,某些工业标准体系结构(ISA)设备需要用到它。
ZONE_NORMAL 部分的内存由内核直接映射到线性地址空间的较高部分,在 4.1 节会进一步讨论。ZONE_HIGHMEM 是系统中预留的可用内存空间,不被内核直接映射。
对于 x86 机器,管理区的示例如下:
- ZONE_DMA 内存的首部 16 MB;
- ZONE_NORMAL 16 MB~896MB;
- ZONE_HIGHMEM 896 MB~末尾(128M)。
许多内核操作只有通过 ZONE_NORMAL 才能完成,因此 ZONE_NORMAL 是影响系统性能最为重要的管理区。这些管理区会在 2.2 节讨论。系统的内存划分成大小确定的许多块,这些块也称为页面帧。每个物理页面帧由一个 struct page 描述,所有的结构都存储在一个全局 mem_map 数组中,该数组通常存放在 ZONE_NORMAL 的首部,或者就在小内存系统中为装入内核映象而预留的区域之后。2.4 节讨论了 struct page 的细 节问题,在 3.7 节将讨论全局 mem_map 数组的细节问题。在图 2.1 中解释了所有这些结构之间的基本关系。
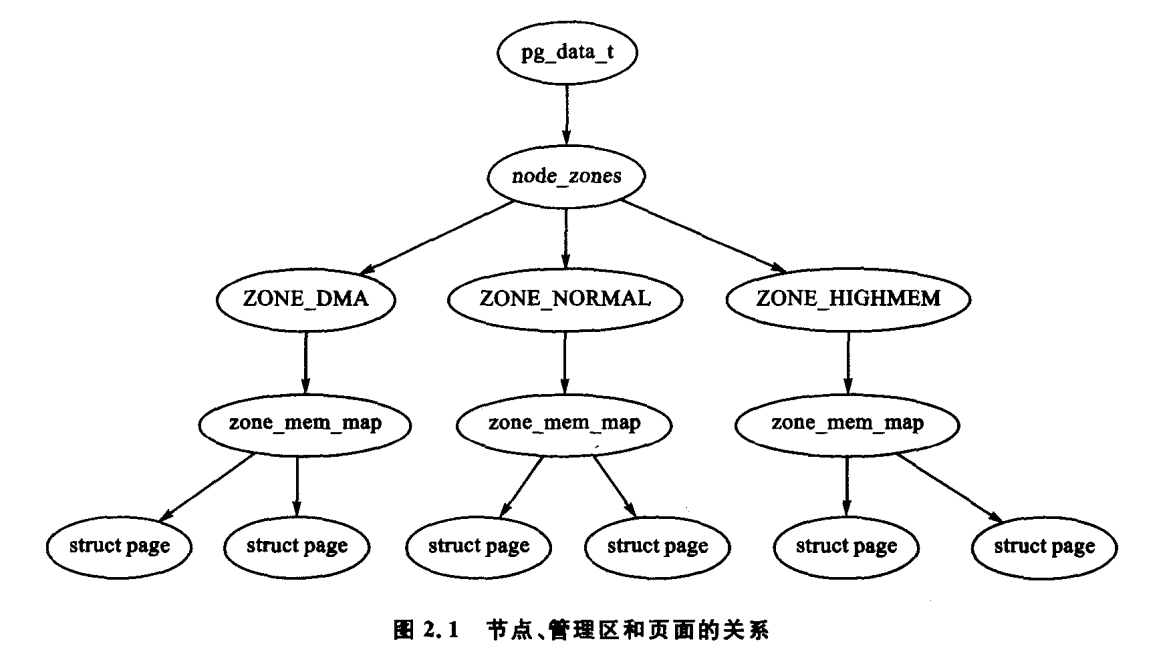
由于能够被内核直接访问的内存空间(ZONE_NORMAL)大小有限,所以 Linux 提出高端内存的概念,它将会在 2.7 节中进一步讨论。这一章讨论在引入高端内存管理以前,节点、管理区和页面如何工作。
2.1 节点
正如前面所提到的,内存中的每个节点都由 pg_data_t 描述,而 pg_data_t 由 struct pglist_data 定义而来。在分配一个页面时,Linux 采用节点局部分配的策略,从最靠近运行中的 CPU 的节点分配内存。由于进程往往是在同一个 CPU 上运行,因此从当前节点得到的内存很可能被用到。结构体在 <linux/mmzone.h> 文件中声明如下所示:
#define ZONE_DMA 0
#define ZONE_NORMAL 1
#define ZONE_HIGHMEM 2
#define MAX_NR_ZONES 3
typedef struct pglist_data {
zone_t node_zones[MAX_NR_ZONES];
zonelist_t node_zonelists[GFP_ZONE MASK + 1];
struct page *node_mem_map;
unsigned long *valid_addr_bitmap;
struct bootmem_data *bdata;
unsigned long node_start_paddr;
unsigned long node_start_mapnr;
unsigned long node_size;
int node_id;
struct pglist_data *node_next;
} pg_data_t;
现在我们简要地介绍每个字段。
- node_zones:
该节点所在管理区为 ZONE_HIGHMEM,ZONE_NORMAL 和 ZONE_DMA。 - node_zonelists:
它按分配时的管理区顺序排列。在调用 free_area_init_core() 时,通过 mm/page_alloc.c 文件中的 build_zonelists() 建立顺序。如果在 ZONE_HIGHMEM 中分配失败,就有可能还原成 ZONE_NORMAL 或 ZONE_DMA。 - nr_zones:
表示该节点中的管理区数目,在 1 到 3 之间。并不是所有的节点都有 3 个管理区。例如,一个 CPU 簇就可能没有 ZONE_DMA。 - node_mem_map:
指 struct page 数组中的第一个页面,代表该节点中的每个物理帧。它被放置在全局 mem_map 数组中。 - valid_addr_bitmap:
一张描述内存节点中 “空洞” 的位图,因为并没有实际的内存空间存在。事实上,它只在 Sparc 和 Sparc64 体系结构中使用,而在任何其他体系结构中可以忽略掉这种情况。 - bdata:
指向内存引导程序,在第 5 章中有介绍。 - node_start_paddr:
节点的起始物理地址。无符号长整型并不是最佳选择,因为它会在 ia32 上被物理地址拓(PAE)以及一些 PowerPC 上的变量如 PPC440GP 拆散。PAE 在第 2.7 节有讨论。一种更好的解决方法是用页面帧号(PFN)记录该节点的起始物理地址。一个 PFN 仅是一个简单的物理内存索引,以页面大小为基础的单位计算。物理地址的 PFN 一般定义为(page_phys_addr >> PAGE_SHIFT)。 - node_start_mapnr:
它指出该节点在全局 mem_map 中的页面偏移。在 free_area_init_core() 中,通过计算 mem_map 与该节点的局部 mem_map 中称为 Imem_map 之间的页面数,从而得到页面偏移。 - node_size:
这个管理区中的页面总数。 - node_id:
节点的 ID 号(NID),从 0 开始。 - node_next:
指向下一个节点,该链表以 NULL 结束。
所有节点都由一个称为 pgdat_list 的链表维护。这些节点都放在该链表中,均由函数 init_bootmem_core() 初始化节点,在 5.3 节会描述该函数。截至最新的 2.4 内核( >2.4.18 ),对该链表操作的代码段基本上如下所示:
pg_data_t * pgdat;
pgdat = pgdat_list;
do {
/* do something with pgdata_t */
} while((pgdat = pgdat->node_next));
在最新的内核版本中,有一个宏 for_each_pgdat() ,它一般定义成一个 for 循环,以提高代码的可读性。
2.2 管理区
每个管理区由一个 struct zone_struct 描述。 zone_struct 用于跟踪诸如页面使用情况统计数,空闲区域信息和锁信息等。在 <linux/mmzone.h> 中它的声明如下所示:
typedef struct zone_struct {
/*
* Commonly accessed fields:
*/
spinlock_t lock;
unsigned long offset;
unsigned long free_pages;
unsigned long inactive_clean_pages;
unsigned long inactive_dirty_pages;
unsigned long pages_min, pages_low, pages_high;
/*
* free areas of different sizes
*/
struct list_head inactive_clean_list;
free_area_t free_area[MAX_ORDER];
/*
* rarely used fields:
*/
char *name;
unsigned long size;
/*
* Discontig memory support fields.
*/
struct pglist_data *zone_pgdat;
unsigned long zone_start_paddr;
unsigned long zone_start_mapnr;
struct page *zone_mem_map;
} zone_t;
下面是对该结构的每个字段的简要解释。
- lock:
并行访问时保护该管理区的自旋锁。 - free_pages:
该管理区中空闲页面的总数。 - pages_min,pages_low,pages_high:
这些都是管理区极值,在下一节中会讲到这些极值。 - need_balance:
该标志位通知页面换出 kswapd 平衡该管理区。当可用页面的数量达到管理区极值的某一个值时,就需要平衡该管理区了。极值会在下一节讨论。 - free_area:
空闲区域位图,由伙伴分配器使用。 - wait_table:
- 等待队列的哈希表,该等待队列由等待页面释放的进程组成。这对 wait_on_page() 和 unlock_page() 非常重要。虽然所有的进程都可以以在一个队列中等待,但这可能会导致所有等待进程在被唤醒后,都去竞争依旧被锁的页面。大量的进程像这样去尝试竞争一个共享资源,有时被称为惊群效应。等待队列表会在 2.2.3 小节作进一步的讨论。
- wait_table_size:
该哈希表的大小,它是 2 的幕。 - wait_table_shift:
定义为一个 long 型所对应的位数减去上述表大小的二进制对数。 - zone_pgdat:
指向父 pg_data_t。 - zone_mem_map:
涉及的管理区在全局 mem_map 中的第一页。 - zone_start_paddr:
同 node_start_paddr。 - zone_start_mapnr:
同 node_start_mapnr。 - name:
该管理区的字符串名字,“DMA”,“Normal” 或者 “HighMem”。 - size:
该管理区的大小,以页面数计算。
2.2.1 管理区极值
当系统中的可用内存很少时,守护程序 kswapd 被唤醒开始释放页面(见第 10 章)。如果内存压力很大,进程会同步地释放内存,有时候这种情况被引用为 direct-reclaim 路径。影响页面换出行为的参数与 FreeBSD[McK96] 和 Solaris[MM01] 中所用的参数类似。
每个管理区都有三个极值,分别称为 pages_low,pages_min 和 pages_high,这些极值用于跟踪一个管理区承受了多大的压力。它们之间的关系如图 2.2 所示。pages_min 的页面数量在内存初始化阶段由函数 free_area_init_core() 计算出来,并且是基于页面的管理区大小的一个比率。计算值初始化为 ZoneSizeInPages/128。它所能取最小值是 20 页(在 x86 上是 80KB),而可能的最大值是 255 页(在 x86 上是 1 MB)。
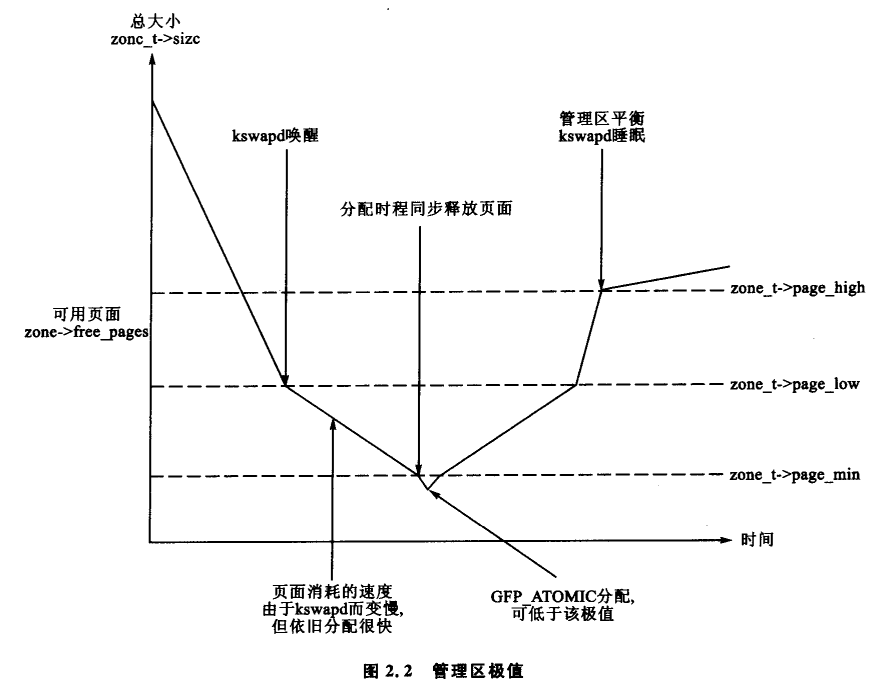
每个极值在表示内存不足时的行为都互不相同。
- pages_low:
在空闲页面数达到 pages_low 时,伙伴分配器就会唤醒 kswapd 释放页面。与之对应的是 Solaris 中的 lotsfree 和 FreeBSD 中的 freemin。pages_low 的默认值是 pages_min 的两倍。 - pages_min:
当达到 pages_min 时,分配器会以同步方式启动 kswapd,有时候这种情况被引用为 direct-reclaim 路径。在 Solaris 中没有与之等效的参数,最接近的是 desfree 或 min-free,这两个参数决定了页面换出扫描程序被唤醒的频率。 - pages_high:
kswpad 被唤醒并开始释放页面后,在 pages_high 个页面被释放以前,是不会认为该管理区已经 “平衡” 的。当达到这个极值后,kswapd 就再次睡眠。在 Solaris 中,它被称为 lotsfree,在 BSD 中,它被称为 free_target。 pages_high 的默认值是 pages_min 的三倍。
在任何操作系统中,无论调用什么样的页面换出参数,它们的含义都是相同的。它们都用于决定页面换出守护程序或页面换出进程释放页面的频繁程度。
2.2.2 计算管理区大小
每个管理区的大小在 setup_memory() 中计算出来,如图 2.3 所示。
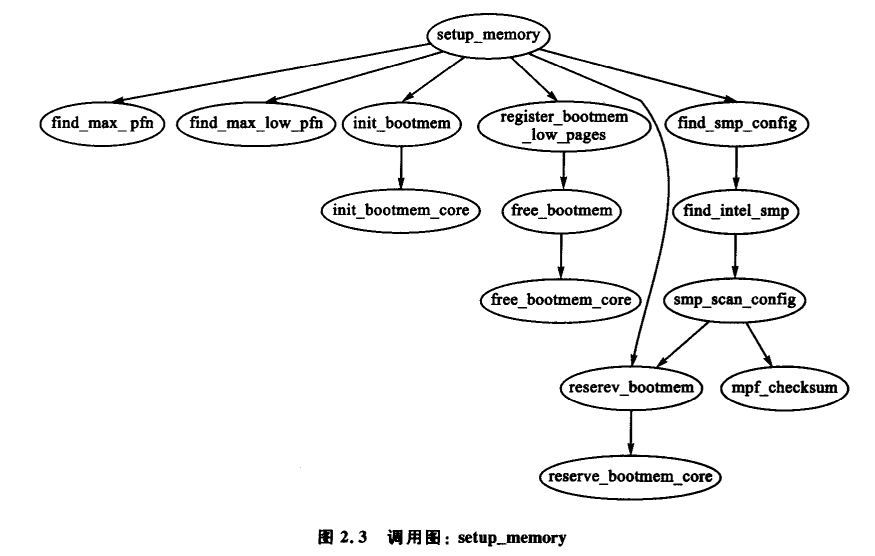
PFN 物理内存映射,以页面计算的偏移量。系统中第一个可用的 PFN(min_low_pfn) 分配在被导入的内核映象末尾 _end 后的第一个页面位置。其值作为一个文件范围变量存储在 mm/bootmem.c 文件中,与引导内存分配器配套使用。
系统中的最后一个页面帧的 max_pfn 如何计算完全与体系结构相关。在 x86 的情况下,通过函数 find_max_pfn() 计算出 ZONE_NORMAL 管理区的结束位置值 max_low_pfn。这一块管理区是可以被内核直接访问的物理内存,并通过 PAGE_OFFSET 标记了内核/用户空间之间划分的线性地址空间。这个值与其他的一些值,都存储在 mm/bootmem.c 文件中。在内存很少的机器上,max_pfn 的值等于 max_low_pfn。
通过 min_low_pfn,max_low_pfn 和 max_pfn 这三个变量,系统可以直接计算出高端内存的起始位置和结束位置,表示文件范围的变量 highstart_pfn 和 highend_pfn 存储在 arch/i286/mm/init.c 文件中。这些值接着被物理页面分配器用来初始化高端内存页面,见 5.6 节。
2.2.3 管理区等待队列表
当页面需要进行 I/O 操作时,比如页面换入或页面换出,I/O 必须被锁住以防止访问不一致的数据。使用这些页面的进程必须在 I/O 能访问前,通过调用 wait_on_page() 被添加到一个等待队列中。当 I/O 完成后,页面通过 UnlockPage() 解锁,然后等待队列上的每个进程都将被唤醒。理论上每个页面都应有一个等待队列,但是系统这样会花费大量的内存存放如此
多分散的队列。Linux 的解决办法是将等待队列存储在 zone_t 中。基本进程如图 2.4 所示。
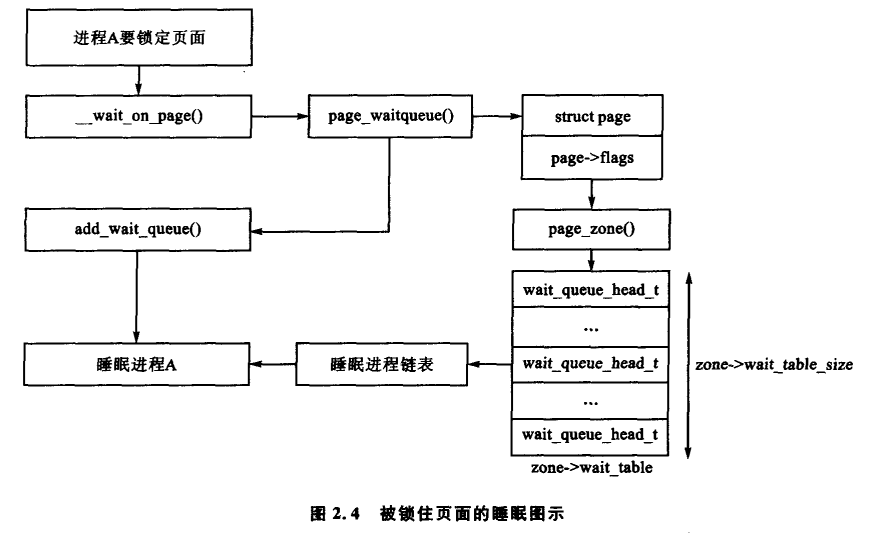
在管理区中只有一个等待队列是有可能的,但是这意味着等待该管理区中任何一个页面的所有进程在页面解锁时都将被唤醒。这会引起惊群效应的问题。Linux 的解决办法是将等待队列的哈希表存储在 zone_wait_table 中。在发生哈希冲突时,虽然进程也有可能会被无缘无故地唤醒,但冲突不会再发生得如此频繁了。
该表在 free_area_init_core() 时就被初始化了。它的大小通过 wait_table_size() 计算,并存储在 zone_t->wait_table_size 中。 等待队列最多有 4096 个。而小一点的队列的大小是 NoPages/PAGE_PER_WAITQUEUE 个队列数和 2 的幂次方的最小值,其中 NoPages 是该管理区中的页面数,PAGE_PER_WAITQUEUE 被定义为 256,即表的大小由如下等式计算出的整数部分表示:
w a i t _ t a b l e _ s i z e = l o g 2 ( N o P a g e s × 2 P A G E _ P E R _ W A I T Q U E U E − 1 ) wait\_table\_size = log_2(\frac{NoPages×2}{PAGE\_PER\_WAITQUEUE}-1) wait_table_size=log2(PAGE_PER_WAITQUEUENoPages×2−1)
zone_t->wait_table_shift 字段通过将一个页面地址的比特数右移以返回其在表中的索引而计算出来。函数 page_waitqueue() 用于返回某管理区中一个页面对应的等待队列。它一般采用基于已经被哈希的 struct page 的虚拟地址的乘积哈希算法。
page_waitqueue 一般需要用 GOLDEN_RATIO_PRIME 乘以该地址,并将结果 zone_t→wait_table_shift 的比特数右移以得到其生哈希表中的索引结果。GOLDEN_RATIO_PRIME [Lev00] 是在系统中最接近所能表达的最大整数的 golden ratio[Knu68] 的最大素数。
2.3 管理区初始化
管理区的初始化在内核页表通过函数 paging_init() 完全建立起来以后进行。页面表的初
始化在 3.6 节会涉及。可以肯定地说,不同的系统执行这个任务虽然不一样,但它们的目标都
是相同的:应当传递什么样的参数给 UMA 结构中的 free_area_init()或者 NUMA 结构中的
free_area_init_node()。UMA 惟一需要得到的参数是 zones_size。参数的完整列表如下。
nid:被初始化管理区中节点的逻辑标识符,NodeID。
pgdat:节点中被初始化的 pa_data_t。在 UMA 结构里为 contig_page_data。
pmap:被 free_area_init_core()函数用于设置指向分配给节点的局部 lmem_map 数组的
指针 UMA 结构中,它往往被忽略掉,因为 NUMA 将 mem_map 处理为起始于 PAGE_OFF-
SET 的虚拟数组。而在 UMA 中,该指针指向全局 mem_map 变量,目前还有 mem_map,都在
UMA 中被初始化。
zones_sizes:一个包含每个管理区大小的数组,管理区大小以页面为单位计算。
zone_start_paddr:第一个管理区的起始物理地址。
zone_holes:一个包含管理区中所有内存空洞大小的数组。
核心函数 free_area_init_core()用于向每个 zone_t 填充相关的信息,并为节点分配 mem_
map 数组。释放管理区中的哪些页面的信息在这里并不考虑。这些信息直到引导内存分配
器使用完之后才可能知道,这将在第 5 章进行讨论。
2.4 初始化mem_map
mem_map 区域在系统启动时会被创建成下列两种方式中的某一种。在 NUMA 系统中,
全局 mem_map 被处理为一个起始于 PAGE_OFFSET 的虚拟数组。free_area_init_nodeO函
22 深入理解 Linux6 虚拟内存管理
数在系统中被每一个活 动节点所调用,在节点被初始化的时候分配数组的一部分。而在
UMA 系统中,free_area_init()使用 contig_page_data 作为节点,并将全局 mem_map 作为该
节点的局部 mem_map。在图 2.5 中显示了这两个函数的调用图。
核心函数 free_area_init_core()为已经初始化过的节点分配局部 lmem_map。而该数组
的内存通过引导内存分配器中的 alloc_bootmem_node()(见第 5 章)分配得到。在 UMA 结构
中,新分配的内存变成了全局的 mem_map,但是这和 NUMA 中的还是稍有不不同的。
NUMA 结构 中,分 配 给 lmem_map 的 内 存 在它们自己的内存节点中。全局 mem_map 从
未被明确地分配过,取而代之的是被处理成起始于 PAGE_OFFSET 的虚拟数组。局部映射
的地址存储在 pg_data_t→node_mem_map 中,也存在于虚拟 mem_map 中。对节点中的每个。
管理区而言,虚拟 mem_map 中表示管理区的地址存储在 zone_t→zone_mem_map 中。余下
的节点都将 mem_map 作为真实的数组,因为其中只有有效的管理区会被节点所使用。
2.5 页面
系统中的每个物理页面都有一个相关联的 struct page 用以记录该页面的状态。在内核
2.2 版本[BC00]中,该结构类似它在 System V 中的等价物,就像 unix 中的其他分支一样,该
结构经常变动。它在 linux/mm.h 中声明如下:
下面是对该结构中的各个字段的简要介绍。
list:页面可能属于多个列表,此字段用作该列表的首部。例如,映射中的页面将属于
address_space 所记录的 3 个循环链表中的一个。这 3 个链表是 clean_pages,dirty_pages 以
及 locked_pages。在 slab 分配器中,该字段存储有指向管理页面的 slab 和高速缓存结构的指
针。它也用于链接空闲页面的块。
mapping:如果文件或设备已经映射到内存,它们的索引节点会有一个相关联的 address_
space。如果这个页面属于这个文件,则该字段会指向这个 address_space。如果页面是置名
的,且设置了 mapping,则 address_space 就是交换地址空间的 swapper_space。
index:这个字段有两个用途,它的意义与该页面的状态有关。如果页面是文件映射的一
部分,它就是页面在文件中的偏移。如果页面是交换高速缓存的一部部分,它就是在交换地址
空间中(swapper_space)address_space 的偏移量。。此外,如果包含含页面的块被释放以提供给
一个特殊的进程,那么被释放的块的顺序(被释放页面的 2 的幕)存放在 index 中。这在函数_
free_pages_ok(中设置。
next_hash:属于一个文件映射并被散列到索引节点及偏移中的页面。该字段将共享相
同的哈希桶的页面链接在一起。
count:页面被引引用的数目。如果 count 减到 0,它就会被释放。当页面被多个进程使用
到,或者被内核用到的时候,count 就会增大。
flags:这些标志位用于描述页面的状态。所有这些标志位在<linux/mm.h>中声明,并
在表 2.1 中列出。有许多已定义的宏用于测试、清空和设置这些标志位,已在表 2.2 中列出。
其中最为有用的标志位是 SetPageUptodate(),如果在设置该位之前已经定义,那么它会调用。
体系结构相关的函数 arch_set_page_uptodate()。
Iru:根据页面替换策略,可能被交换出内存的页面要么会存放于 page_alloc.c 中所声明
的 active_list 中,要么存放于 inactive_list 中。这是最近最少使用(LRU)链表的链表首部。这
两个链表的细节将在第 10 章讨论。
pprev_hash:是对 next_hash 的补充,使得哈希链表可以以双向链表工作。
buffers:如果一个页面有相关的块设备缓冲区,该字段就用于跟踪 buffer_head。如果匿
名页面有一个后援交换文件,那么由进程映射的该置名页面t有一个相关的 buffer_head。这
个缓冲区是必不可少的,因为页 面 必须 与 后援存储器中的文件系统定义的块同步。
virtual:通常情况下,只有来自 ZONE NORMAL 的页面才由内核直接映射。为了定位。
ZONE_ HIGHMEM 中的页面,kmap()用于为内核映射页面。这些在第 9 章有进一步的讨论,
但只有一定数量的页面会被映射到。当某个页面被映射时,这就是它的虚拟地址。
类型 mem_map_t 是对 struct page 的类型定义,因此在 mem_map 数组中可以很容易就
引用它。
2.6 页面映射到管理区
在最近的 2.4.18 版本的内核中,struct page 存储有一个指向对应管理区的指针 page一
zone。该指针在后来被认为是一种浪费,因为如果有成千上万的这样的 struct page 存在,那
么即使是很小的指针也会消耗大量的内存空间。在更新后的内核版本中,已经删除了该 zone。
字段,取 而代之的是 page→flags 的最高 ZONE_SHIFT(在 x86 下是 8 位)位,该 ZONE_
SHIFT 位记录该页面所属的管理区。首先,建立管理区的 zone_table。在 linux/page_alloc.c
中它的声明如下:
33 zone_t * zone_table[MAX_NR_ZONES MAX_NR_NODES];
34 EXPORT_SYMBOL(zone_table);
MAX_NR_ZONES 是一个节点中所能容纳的管理区的最大数,如 3 个。
MAX_NR_NODES 是可以存在的节点的最大数。函数 EXPORT_SYMBEL())使得zone_
table 可以被载入模块访问。该表处理起来就像一个多维数组。在函数 free_area_init_core()
中,一个节点中的所有页面都会初始化。首先它设置该表的值
733 zone_table[nid * MAX_NR_ZONES + j] = zone;
其中,nid 是节点 ID,是管理区索引号,zone 是结构 zone_t。对每个页面,函数 set_page_
zone()的调用方式如下所示:
788
set_page_zone(page, nid * MAX_NR_ZONES + j);
其中,参数 page 是管理区 被设置了的页面。因此,zone_table 中的索 引被显 式 地存储在页
面中。
2.7 高端内存
由于内核(ZONE_NORMAL)中可用地址空间是有限的,所以 Linux 内核已经支持了高
端内存的概念。高端内存的两个國值都存在于 32 位 x86 系统中,分 别是 4 GB 和 64 GB。
GB 的限制与 32 位物理地址定位的内存容量有关。为了访问 1 GB 和 4 GB 之间的内存,内
核通过 kmap()将高端内存的页面临时映射成 ZONE_ NORMAL。这一点会在第 9 章深入
讨论。
第二个 64 GB 的限制与物理地址扩展(PAE)有关,物理地址扩展是 Intel 发明的用于允。
许 32 位系 统 使用 RAM 的。它 使用 了 附加的 4 位 来定位内存 中的地 址,实 现 了 216 字 节
(64 GB)内存的定位。
在理论上,物理地址扩展(PAE)允许处理器寻址到 64 GB,但实际上,Linux 中的进程仍。
然不能访问如此大的 RAM,因为虚拟地址空间仍然是 4 GB。这就导致一些试图用 malloc()))
函数分配所有 RAM 的用户感到失望。
其次,地址扩展空间(PAE)不允许内核自身拥有大量可用的 RAM。用于描述页面的
struct page 仍然需要 44 字节,并且用到了 ZONE_ NORMAL 中的内核虚拟地址空间。这意
味着,为了描述 1 GB 的内存,需要大约 11 MB 的内核内存。同理,为了描述 16 GB 的内存则
需要耗费 176 MB 的内存,这将对 ZONE_ NORMAL 产生非常大的压力。在不考虑其他的数
据结构而使用 ZONE_ NORMAL 时,情况看起来还不太槽糕。在最坏的情况下,甚至像页面
表项(PTE)之类的很小的数据结构也需要大约 16 MB。所以在 x86 机器上的 Linux 的可用物
理内存实际被限制为 16 GB。如果确实需要访问更多的内存,我的建议一般是直接去买一台
64 位机器。
2.8 Linux2.6版本 中有哪些新特性
节 点
大致看去,内存如何被描述好像没有多大的变化似的,但是表面上细微的变化实际上涉及
的面却相当广。节点描述器 pg_data_t 增加了如下新的字段。
node_start_pfn:替换了 node_start_paddr 字段。惟一的一个差异便是新的字段是一个。
PFN,而不是一个物理地址。之所以变更是因为 PAE 体系结构可以访问比 32 位更多的内存,
因此大于 4 GB 的节点用原来的字段是访问不到的。
kswapd_wait:为 kswapd 新添加的等待入列链表。在 2.4 里面,页面交换守护程序有一
个全局等待队列。而在 2.6 里面,每个节点都有一个 kswapdN,其中 N 是节点的标识符,而每
个 kswapd 都有其自己的等待队列对应该字段。
node_size:字段被移除了,取而代之的是两个新字段。之所以如此变更是因为认识到节
点中会有空洞的存在,空洞是指地址后面其实没有真正存在的物理内存。
node_present_pages:节点中所有物理页面的总数 。
node_spanned_pages:通过节点访问的所有区域,包括任何可能存在的空洞。
管理区
初始看来,两个版本中的管理区也是有很大差异的。它们不再被称为 zone_t,取而代之被
简单地引用为 struct zone。第二个主要的不同是 LRU 链表。正如我们在第 10 章中看到的,
2.4 的内核有一个全局的页面链表,决定了被释放页面或进行换出页面的顺序。这些链表目
前被存储在 struct zone 中。相关的字段如下所示。
lru_lock:该 管理区 中 LRU 链表 的 自 旋锁。在 2.4 里面,它是个被称为 pagemap_lru_
lock 的全局锁。
active_list:该管理区中的活动链表。这个链表和第 10 章中描述的一样,但它现在不再。
是全局的,而是每个管理区一个了。
inactive_list:该管理区中 的 非 活 动链表 。在 2.4 中,它是全局的。
refill_counter:是从 active_list 链表上一次性移除的页面的数量,而且只有在页面替换时
才考虑它。
nr_active active_list:链表上的页面数量。
nr_inactive inactive_list:链表上的页面数量。
all_unreclaimable:当页面换出守护程序第二次扫描整个管理区里的所有页面时,依旧无
法释放掉足够的页面,该字段置为 1。
pages_scanned:自最后一次大量页面被回收以来,被扫描过的页面数量。在 2.6 里面,页
面被一次性释放掉,而不是单独地释放某个页面,在 2.4 里面采取的是后者。
pressure:权衡该管理区的扫描粒度。它是个衰退的均值,影页面扫描器回收页面时的
工作强度。
其其他 3 个字段是新加进去的,但它们和管理区的尺度是有关系的。如下所示。
zone_start_pfn:管 理 区 中 PFN 的 起 始 位 置 。 它 取 代 了 2. 4 中 的 zone_start_paddr 和
zone_start_mapnr。
spanned_pages:该管理区范围内页面的数量,包括某些体系结构中存在的内存空洞。
present _ pages :管 理 区 中 实 际 存 在 的 页 面 的 数 量 。 对 一 些 体 系 结 构 而 言 ,其 值 和
spanned_ pages 是一样的。
另外一个新加的是 struct per_cpu_pageset,用于维护每个 CPU 上的一系列页面,以减少
自旋锁的争夺。zone→pageset 字段是一个关于 struct per_cpu_pageset 的 NR_CPU 大小的
数组,其中 NR_CPU 是系统中可以编译的 CPU 数量上限。而 per-cpu 结构会在本节的最后
部分作更进一步的讨论。
最后一个新加入 struct zone 的便是结构中零填充。在 2.6 内核 VM 的开发过程中,逐步
认识到一些自旋锁会竞争得非常厉害,很难被获取。因为大家都知道有些锁总是成对地被获
取,同时又必须保证它们使用不同的高速缓冲行,这是一种很普遍的缓冲编程技巧[Sea00]。
该填充管理区在 struct zone 中由 ZONE_PADDING()宏 标 记,并 被用 于 保 证 zone→lock,
zone→lru_lock,以及 zone→pageset 字段使用不同的高速缓冲行。
页 面
最值得注意的变更就是该字段的顺序被改变了,因此相关联的项目看起来都使用了同一个。高速缓冲行。该字段除了新加了两个特性以外,本质上还是一样的。第-个特性就是采用了一
个新的联合来创建 PTE 链。PTE 和页表管理相关联的会在第 3 章的结尾处进行讨论。另外一
个特性便是添加了 page private 字段,它包括了映射中详实的私有信息。比如,当页面是一个缓
冲区页面时,该字段被用于存储一个指向 buffer_head 的指针。这意味着 page buffers 字段也被
移除掉了。最后一个重要的变更是 page→virtual 对高端内存的支持不再必要,只有在特定的体
系结构需要时才会考虑它的存在。如何支持高端内存将在第 9 章进一步讨论。
Per-CPU 上的页面链表
在 2.4 里面,只有一个子系统会积极地尝试为任何对象维护 per-cpu 上的链表,而这个子
系统就是 slab 分配器,在第 8 章会进行讨论。在 2.6 里面,这个概念则更为普遍一些,存在一
个关于活动页面和不活动页面的正式概念。
在<linux/mmzone.h>文件中声明的 struct per_cpu_pageset 具有一个字段,该字段是一
个具有两个 per_cpu_pages 类型的元素的数组。该数组中 第 0 位 的元 素是为 活 动页 面 预 留
的,而另一个元素则是为非活动页面预留的,其中活动页面和非活动页面决定了高速缓存中的
页面的活跃状态。如果知道了页面不会马上被引用,比如 I/O 预读中,那么它们就会被置为
非活动页面。
struct per_cpu_pages维护了链表中目前已有的一系列页面,高极值和低极值决定了何时
填充该集合或者释放一批页面,变量决定了一个块当中应当分配多少个页面,并最后决定在页
面前的实际链表中分配多少个页面。
为建立每个 CPU 的链表,需要有一个计算每个 CPU 上有多少页面的方法。struct page_
state 具有一系列计算的变量,比如 pgalloc 字段,用于跟踪 分 配给 当前 CPU 的 页面数量;而
pswpin 字段,用于跟踪读进交换的页面数量。该结构在<linux/page-flags. h>文件中作了详
细的注解。函数 mod_page_stateO用于为运行中的 CPU 更新 page_state 字段,另外其还提供
了辅助的三个宏,分别调用 inc_page_state(),dec_page_stateO)和 sub_page_stateO)。
二、补充配置
1、空格
  为“全角空格”
  为“全角空格”
为“不换行空格”
2、文字颜色
浅红色文字:<font color="#dd0000">浅红色文字:</font><br />
深红色文字:<font color="#660000">深红色文字</font><br />
浅绿色文字:<font color="#00dd00">浅绿色文字</font><br />
深绿色文字:<font color="#006600">深绿色文字</font><br />
浅蓝色文字:<font color="#0000dd">浅蓝色文字</font><br />
深蓝色文字:<font color="#000066">深蓝色文字</font><br />
浅黄色文字:<font color="#dddd00">浅黄色文字</font><br />
深黄色文字:<font color="#666600">深黄色文字</font><br />
浅青色文字:<font color="#00dddd">浅青色文字</font><br />
深青色文字:<font color="#006666">深青色文字</font><br />
浅紫色文字:<font color="#dd00dd">浅紫色文字</font><br />
深紫色文字:<font color="#660066">深紫色文字</font><br />
3、文字大小
size为1:<font size="1">size为1</font><br />
size为2:<font size="2">size为2</font><br />
size为3:<font size="3">size为3</font><br />
size为4:<font size="4">size为4</font><br />
size为10:<font size="10">size为10</font><br />
4、字体
<font face="黑体">我是黑体字</font>
<font face="宋体">我是宋体字</font>
<font face="微软雅黑">我是微软雅黑字</font>
<font face="fantasy">我是fantasy字</font>
<font face="Helvetica">我是Helvetica字</font>